-
Notifications
You must be signed in to change notification settings - Fork 71
October 5, 2016
This meeting is a hybrid teleconference and IRC chat. Anyone is welcome to join. Here is the info:
- Time: 1:00pm Eastern Daylight Time US (UTC-4)
- Dial-in Number: (641) 715-3570
- Participant Code: 304589#
- International numbers: Conference Call Information
- Web Access: https://www.freeconferencecallhd.com/wp-content/themes/responsive/flashphone/flash-phone.php
- IRC:
- Join the #islandora chat room via Freenode Web IRC (enter a unique nick)
- Or point your IRC client to #islandora on irc.freenode.net
- Nick Ruest
- Danny Lamb
- Bryan Brown
- Mark Cooper
- Jared Whiklo 🌟
- Marcus Barnes
- Don Richards
- Natkeeran Ledchumykanthan
- Ed Fugikawa
- Deoyani Nandrekar Heinis
- Aaron Coburn
- Chair for next two meetings
Prune AlpacaShearing an Alpaca- Add OCR Service
- MVP Discussion
- Solr version
- ... (feel free to add agenda items)
-
Chair
Assume this will be Danny, but does anyone want to chair?
Danny will chair, and send out the meeting highlights to both lists.
Also if there is something you would like to discuss, please add it to a future agenda.
-
Pruning Alpaca - https://github.com/Islandora-CLAW/CLAW/issues/387
Trying to get ready for API-X. Prune the stuff we don't need, and add in new requirements. Also adding some of Amherst College's (Aaron's) work. Clearing the path to start working on future services. Removed stuff we used to execute PHP in Camel. We can get it back, but it doesn't look like that is part of the plan.
Now that Salmon is removed from Alpaca, we are going to remove the root karaf resource/gradle build so both of these services can reference.
We moved from Maven to Gradle for Alpaca, and we will do that in Salmon but should we do that first.
Pushing SNAPSHOT artifacts to Sonatype (https://github.com/Islandora-CLAW/CLAW/issues/363)
To avoid building all the artifacts you want to test. Especially for API-X stuff
-
OCR Service - https://github.com/Islandora-CLAW/CLAW/issues/389
This will be an API-X service, but getting the API well defined is the key.
Would this do PDF OCR? No that would be a separate service. That uses
ghostScriptorpdftotext.It will do some sort of check to determine what services are available (through API-X) to that type.
Suggesting we start with the OCR service as that is the one we are going to write. Amherst already has an image service in place, so this would be very similar but use tesseract.
FITS Web Service produces XML, so once FITS produces its output we need to map the contents to RDF. Which still needs to be implemented.
Basic workflow : File comes in check what you can do, go off and do those things, but then what do you do with the results of these API-X services.
For things like generating FITS XML, you wouldn't necessarily want to perform these actions automatically. You could end up in a loop.
ie. Generate FITS XML on a binary, add to Fedora as a binary, which generates FITS XML on the binary....
I thought we would need to filter on certain types, to allow use of the JMS queue but could result in infinite loops (as above).
There are lots of issues that could occur and become obvious as you implement, we will hold these discussions to the Github tickets.
TODO: Add desires for the OCR service API on the ticket.
-
MVP - https://docs.google.com/document/d/19Jn9o-QFM-maBNjLu-heRh95Gnw65kL4fzq_iO-BajI/edit?usp=sharing
Now publicly available, are there specific items that anyone would like to discuss with regard to the MVP.
Giving people time to comment on the document and the specifics.
Future sprints will then be created from the MVP document.
CLAW lessons on the CLAW homepage will help to get you started with the requirements.
This whole stack is very complex and encompasses many different languages. Trying to understand the entire thing could be overwhelming. So instead starting from a desired feature or a common language, perhaps getting a full understanding of Linked Data, RDF and the Semantic Web.
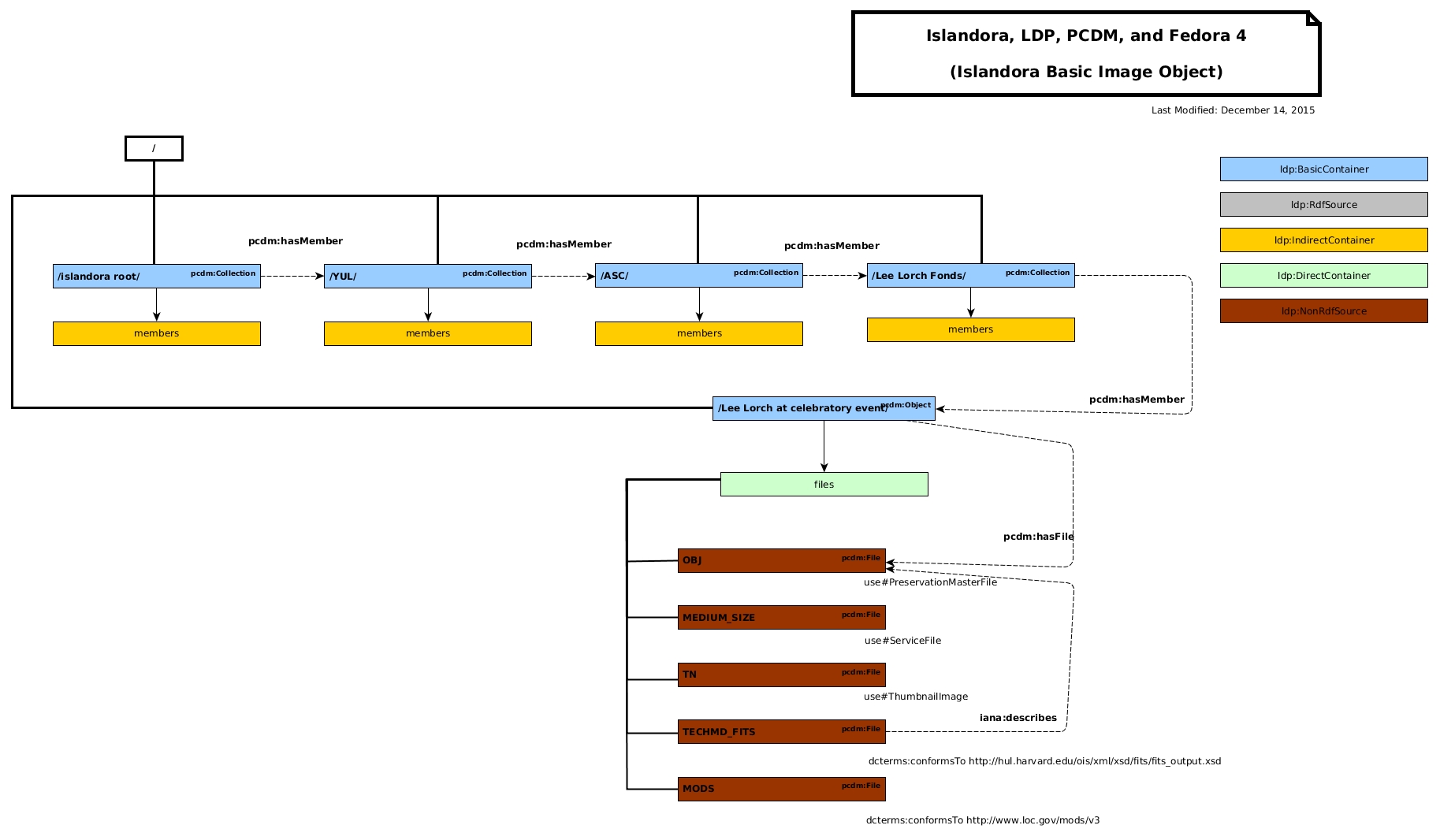
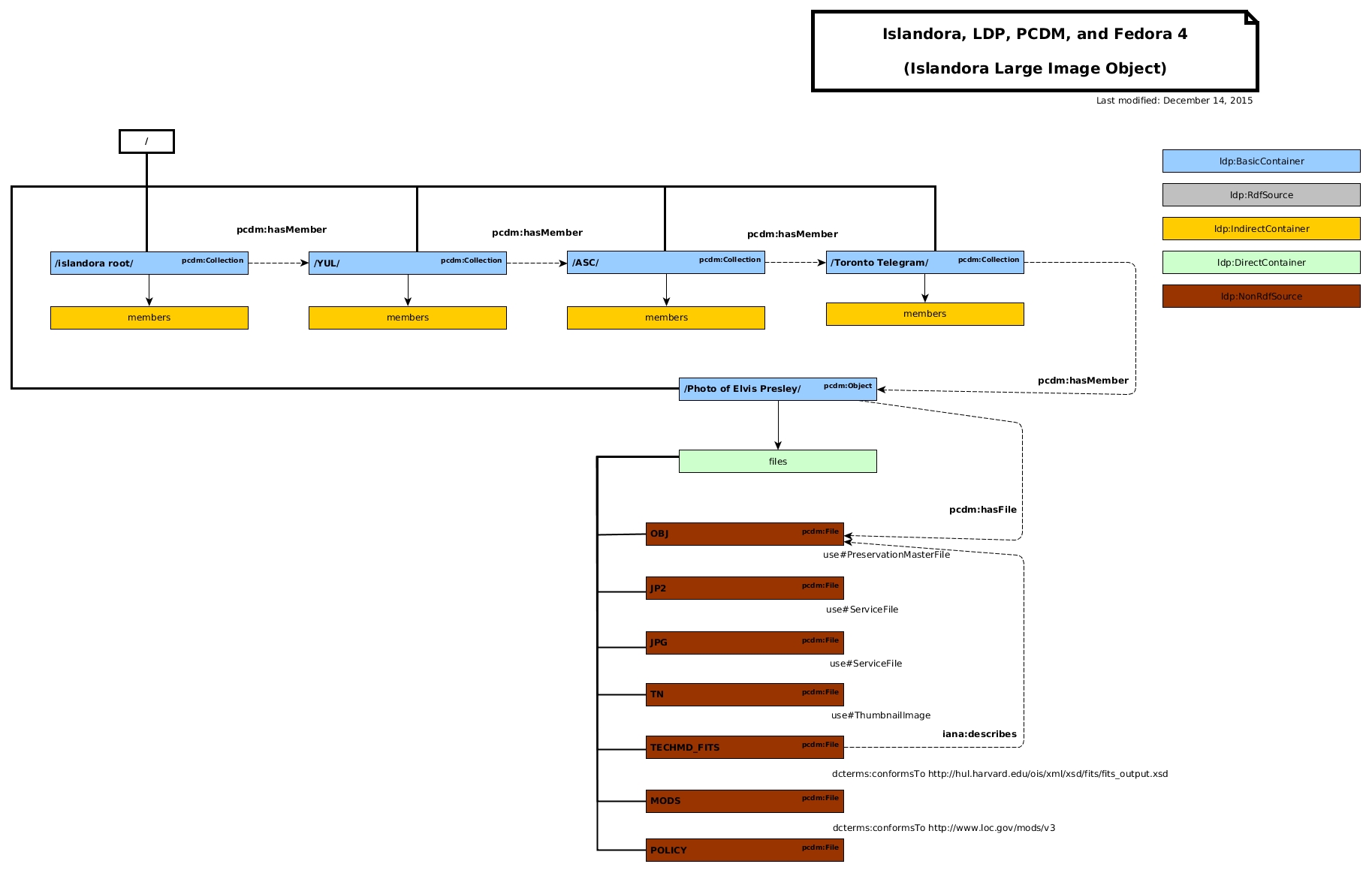
UI/UX will take awhile to sort out. This was an example, and does not contain all of the possible descriptive metadata. Perhaps Danny will generate a new screenshot with more of that content. But you will get a set of metadata when you create a new object and it would hold it there. The binaries would be attached to that top-level RDF Source object.
All entities will be separate Fedora Resources and Collections will also have descriptive metadata on them.
Do we have documentation on the Drupal modules? No, this hasn't been broken down in the MVP. Trying to remain higher level.
If you are looking for is more information on the Drupal side of things, we can add some documentation on those ideas. Trying to remain vague to allow the scoping of each module/service to exist separate from the MVP to reduce the size of the document.
Stack is huge and intimidating, can be difficult to understand.
Example data modeling diagrams:
-
Solr Version - https://github.com/Islandora-CLAW/CLAW/issues/379
Discussion tabled to next meeting.
{kind=link}
{kind=link}
You may be looking for the islandora-community wiki · new to islandora? · community calendar · interest groups · roadmap