Reorder render sets, refactor bevy_sprite to take advantage#9236
Conversation
|
Example |
2 similar comments
|
Example |
|
Example |
|
Had to add an additional check in |
 superdump
left a comment
superdump
left a comment
There was a problem hiding this comment.
Mostly looks OK to me. The approach with UI to do batching in Queue looks at first glance like it would break if other plugins queued anything to the TransparentUi render phase such that those items should be sorted between.
Other than that I'd like to see some benchmarks and either decide that performance is good enough that more performance improvements can be made in a follow-up PR to save on blocking merge of this PR, or that more work is needed.
|
On my M1 Max, this PR drops |
|
I first made a branch that:
After that
Some time passed and I wanted to try changing the way the sprite rendering worked, to instead put per-instance data into a GpuArrayBuffer, and then look it up using an instance index calculated from a specially-crafted index buffer where the low 2 bits are the x and y offsets of the quad (00 is bottom left, 01 bottom right, 10 top left, 11 top right) and the high bits contain the instance index. I got this working but it was still quite a bit slower than main.
In profiles in Xcode I thought I had seen a lot of cache misses, and so I had one more idea to try - get rid of the GpuArrayBuffer of per-instance data, put it in an instance-rate vertex buffer instead, and use an index buffer with just 6 vertices. This had been claimed to be slower than generating a larger index buffer but on the M1 Max...
I tested on my 5900HS 0 mobile RTX 3080 as well, not as big a boost there: So, I propose that this PR be rebased, reviewed, and merged. And that I make a separate PR with this change to using an instance buffer. @james-j-obrien Oh, one more thing I noted when moving to the instance-rate vertex buffer: it uses a |




Co-authored-by: Robert Swain <robert.swain@gmail.com>
…ure is not yet available
5a614ae to
ec0e7a7
Compare
|
Example |
|
Fixed the UI implementation to match that of |
|
Can we rename PrepareBuffers to PrepareResources or something more generic? |
| /// The copy of [`apply_deferred`] that runs between [`PrepareResources`](RenderSet::PrepareResources) and ['PrepareBindgroups'](RenderSet::PrepareBindgroups). | ||
| PrepareResourcesFlush, | ||
| /// A sub-set within Prepare for constructing bindgroups, or other data that relies on buffers. | ||
| PrepareBindgroups, |
There was a problem hiding this comment.
As the wgpu/bevy types are camelCased as BindGroup, I think this should do the same, everywhere. Just commenting this one time.
| PrepareBindgroups, | |
| PrepareBindGroups, |
There was a problem hiding this comment.
I've fixed the this instance, the only other example in the repo is the LineGizmoUniformBindgroup. I could update that as well but it seems sort of tangential to the purpose of this PR.
|
The new SVG is looking good! :) It feels like it makes more sense. |
 robtfm
left a comment
robtfm
left a comment
There was a problem hiding this comment.
looks good to me. i tested a number of examples and didn't see any issues. couple of minor points but happy to approve as is.
 JMS55
left a comment
JMS55
left a comment
There was a problem hiding this comment.
An absolutely amazing and foundational PR :). This resolves my long standing complaint of "why the heck are we making bind groups in a stage (system set? is that the official term now?) called queue?". Thanks so much for doing this!
| self.per_object_binding_dynamic_offset, | ||
| Reverse(FloatOrd(self.distance)), | ||
| ) | ||
| Reverse(FloatOrd(self.distance)) |
There was a problem hiding this comment.
Shouldn't we sort by pipeline here? Unrelated to this PR really, though.
There was a problem hiding this comment.
I'll do that separately. :)
| for item in &self.items { | ||
| let draw_function = draw_functions.get_mut(item.draw_function()).unwrap(); | ||
| draw_function.draw(world, render_pass, view, item); | ||
| let mut index = 0; |
There was a problem hiding this comment.
Curious what the assembly looks like for this block.
There was a problem hiding this comment.
Here's some annotated output from just the main render loop: render.txt
And here's the full asm for the function: render_full.txt
(had to use txt files as github complains about .asm)
There is an extra branch for the zero case but we won't be taking that the majority of the time.
There was a problem hiding this comment.
Thanks. Don't think it's a huge problem then. Branch predictor probably handles it fine.
superdump
left a comment
There was a problem hiding this comment.
@james-j-obrien - let's get this merged! Please update to main and ping me on Discord so I can click the button. :)
# Objective - Supercedes #8872 - Improve sprite rendering performance after the regression in #9236 ## Solution - Use an instance-rate vertex buffer to store per-instance data. - Store color, UV offset and scale, and a transform per instance. - Convert Sprite rect, custom_size, anchor, and flip_x/_y to an affine 3x4 matrix and store the transpose of that in the per-instance data. This is similar to how MeshUniform uses transpose affine matrices. - Use a special index buffer that has batches of 6 indices referencing 4 vertices. The lower 2 bits indicate the x and y of a quad such that the corners are: ``` 10 11 00 01 ``` UVs are implicit but get modified by UV offset and scale The remaining upper bits contain the instance index. ## Benchmarks I will compare versus `main` before #9236 because the results should be as good as or faster than that. Running `bevymark -- 10000 16` on an M1 Max with `main` at `e8b38925` in yellow, this PR in red: 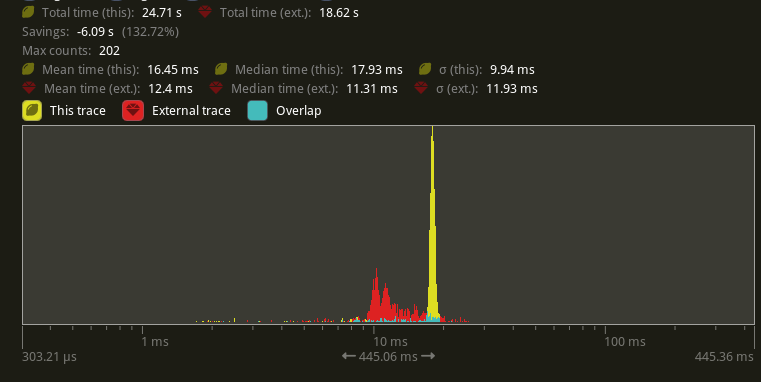 Looking at the median frame times, that's a 37% reduction from before. --- ## Changelog - Changed: Improved sprite rendering performance by leveraging an instance-rate vertex buffer. --------- Co-authored-by: Giacomo Stevanato <giaco.stevanato@gmail.com>
# Objective - since #9236 queue_mesh_bind_group has been renamed to prepare_mesh_bind_group,but the comment referring to it has not been updated. .
# Objective - Supercedes bevyengine#8872 - Improve sprite rendering performance after the regression in bevyengine#9236 ## Solution - Use an instance-rate vertex buffer to store per-instance data. - Store color, UV offset and scale, and a transform per instance. - Convert Sprite rect, custom_size, anchor, and flip_x/_y to an affine 3x4 matrix and store the transpose of that in the per-instance data. This is similar to how MeshUniform uses transpose affine matrices. - Use a special index buffer that has batches of 6 indices referencing 4 vertices. The lower 2 bits indicate the x and y of a quad such that the corners are: ``` 10 11 00 01 ``` UVs are implicit but get modified by UV offset and scale The remaining upper bits contain the instance index. ## Benchmarks I will compare versus `main` before bevyengine#9236 because the results should be as good as or faster than that. Running `bevymark -- 10000 16` on an M1 Max with `main` at `e8b38925` in yellow, this PR in red:  Looking at the median frame times, that's a 37% reduction from before. --- ## Changelog - Changed: Improved sprite rendering performance by leveraging an instance-rate vertex buffer. --------- Co-authored-by: Giacomo Stevanato <giaco.stevanato@gmail.com>
This is a continuation of this PR: #8062
Objective
bevy_spriteandbevy_uito take advantage of the new orderingSolution
Move
PrepareandPrepareFlushafterPhaseSortFlushAdd a
PrepareAssetsset that runs in parallel with other systems and sets in the render schedule.PrepareAssetssetAdd
ManageViewsandManageViewsFlushsets betweenExtractCommandsand QueueMove
queue_mesh*_bind_groupto the Prepare stageprepare_PrepareResourcesset insidePrepareprepare_..._bind_groupsystems into aPrepareBindGroupset afterPrepareResourcesMove
prepare_lightsto theManageViewssetprepare_lightscreates views and this must happen beforeQueueRemove
BatchedPhaseItemReplace
batch_rangewithbatch_sizerepresenting how many items to skip after rendering the item or to skip the item entirely ifbatch_sizeis 0.queue_spriteshas been split intoqueue_spritesfor queueing phase items andprepare_spritesfor batching after thePhaseSortPhaseItems are still inserted inqueue_spritesSpriteBatchcomponents on the first entity of each batch, containing a range of vertex indices. The associatedPhaseItem'sbatch_sizeis updated appropriately.SpriteBatchitems are then drawn skipping over the other items in the batch based on the value inbatch_sizeA very similar refactor was performed on
bevy_uiChangelog
Changed:
bevy_spriteandbevy_uito take advantage of the reordering.Migration Guide
PrepareAssetse.g.prepare_assets<Mesh>RenderPhases continues to be done inQueuee.g.queue_spritesPrepareResources, e.g.prepare_prepass_textures,prepare_mesh_uniformsPrepareBindGroupse.g.prepare_mesh_bind_groupPreparewhere the order of the phase items is known e.g.prepare_spritesNext Steps
[sprite at z 0, mesh at z 0, sprite at z 0]preventing batching.