[Do Not Merge] buffer: Remove buffer_fmt field #3179
Conversation
This value is unused in whole source code, so it only makes code more messy. Signed-off-by: Karol Trzcinski <karolx.trzcinski@linux.intel.com>
97754c5 to
fb04ed1
Compare
|
Hmm, why the "[Do Not Merge]" in summary? This seems good to go and is a good test case for the relaxed ABI process in the sense that when kernel upgrades to 3.17 ABI, the header needs to be updated then. |
|
@lgirdwood can we go forward with this PR ? |
|
SOFCI TEST |
That doesn't seem quite right to me. We want to have bytes in a buffer, plus metadata that tells us what to do with the buffer. Strong-typing the buffer type isn't too good. Are we also going to have BUFFER_IEF61937 as well? That seems like the wrong direction to me. |
|
@plbossart @lgirdwood it is yet not clear to me if compressed buffers have anything special wrt PCM buffer, I think there are just bytes passed around. Maybe this is useful for DAIs? Would be nice to understand what was the original purpose of this field. I'm not very fond of removing it just right now. |
Yeah, this is the sort of meta-data that needs to be passed all the way to the DAIs. This may also be used by processing elements in case they do channel-based processing that is more efficient when non-interleaved. |
|
@dbaluta I'bve only come across SOF_IPC_BUFFER_NONINTERLEAVED data once, but it's part of the ALSA spec so was carried forward into IPC. |
Well my point is that 'COMPRESSED" means nothing. Most of the uses of the 'compressed API' are actually for PCM data for wake-on-voice. We use the compressed stream for probe extraction, again with PCM data muxed in a custom way. Likewise the SPDIF support relies on compressed data formatted to meet the PCM bitrate and transmitted as PCM, but on that PCM you don't want to do ANY volume control for example. That's why I prefer a 'byte buffer' that just contains bytes. what to do with the buffer needs to come from metadata, a 'compressed' flag provides at the same time too much and too little information. |
|
@plbossart @lgirdwood @ktrzcinx Lets reach a conclusion here. My proposal is not to remove this field until we have the compress implementation ready. At that point we can say for sure that this field can be removed. |
Ok, lets close now and we can reopen once we know the compressed implementation. @ktrzcinx @dbaluta this will need to be on your radars. |
|
@ktrzcinx @lgirdwood One notable difference between PCM buffers and COMPR bufffers is their params and the way buffer size is computed. A pipeline will look like this:
I'm having trouble figuring out who will drive the data copying because compr buffer size and PCM buffer size are most likely very different. |
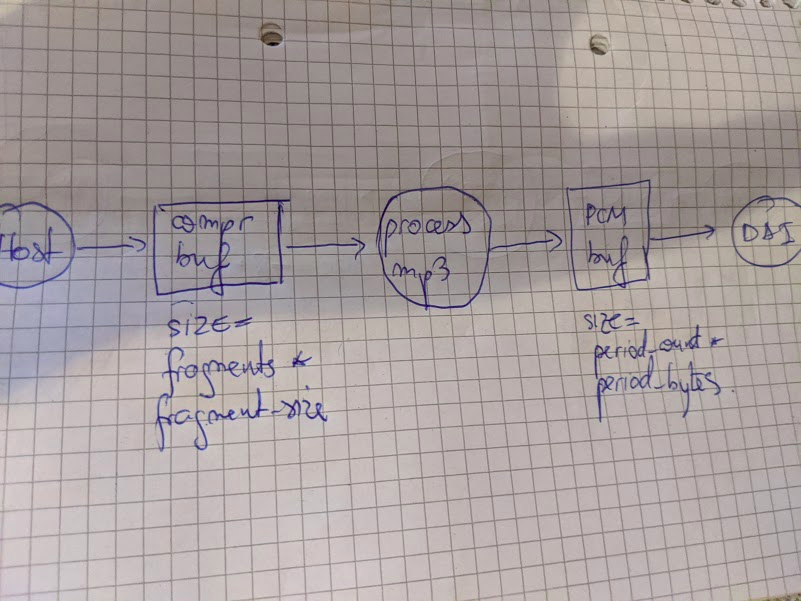
|
@dbaluta The DAI will still do the scheduling, but maybe the host component can have some sort of hysteresis to not attempt copying unless you need like 25% of the buffer (otherwise it will keep attempting to keep the buffer full even though you exhaust it in several seconds or however long it is). |
|
@paulstelian97 I'm thinking initially to use timer based scheduling. Important things to consider here is how do you choose period length here so that we avoid:
Important thing to notice is that Process component can return 'NOT ENOUGH DATA' this means we need to find a way to quickly feed more data. |
|
Well we still need to ensure the DAI is scheduled often enough based on the size of the DMA buffer. And you can't skip the host component without special provisions when scheduling the DAI so either you make huge buffers for the DAI (which will cause latency issues and instability) or schedule the pipeline more often. I would like a way to have two pipelines that are scheduled differently and one feeds into the other. One of them has the host component and its buffer and is scheduled more rarely, the other has the DAI component and the decoder and is scheduled often. |
|
I like the idea of having two pipelines, in this way we could easily solve the fact that they need to be scheduled differently. Current SOF implementation assume some fixed endpoints, like Host and DAI. How would we connect our pseudo-pipelines now? |
|
We gotta figure out how multiple pipeline setups work. I think we can look at any topology with a mixer or a mux in it. |
|
@dbaluta @paulstelian97 yes, there are 2 options for scheduling - the DAI or timer. I would imagine that downstream (PCM data) of the decoder will work as it does today. The upstream parts of the decoder (e.g. MP3) will only process data when the downstream PCM buffer has enough free space for the next uncompressed fragment (and this should be reflected in buffer size that connects decoder to downstream). |
Agreed, the flag makes sense. We also have another issue for implementing that. The decoder algorithm needs to be explicitly told when the stream is stopping and we're getting the last data. Given the variable rate decoder we cannot exactly know for certain that the data is truly over, do we? Our intent is a low power solution in which a good chunk of input buffer is taken from host RAM, then the host RAM can be suspended for a while (many seconds, as in 20 seconds or more) while the DSP decodes and plays back the decoded data without waking up the host. Given my current understanding of the Host component I'm not sure how that will work either. |
Maybe another flag for host.c that says "wake up host by sending IPC when my source buffer watermark is X bytes or lower" ? |
Still need to figure out, although maybe the ALSA interface itself isn't perfect and when we will implement ALSA Compress we might add a few extra changes. Needs some thought still.
That sounds good, although I'm actually talking about the buffer in SOF. We want to really decode from that buffer without waking up the host (i.e. not even doing Host DMA transfers) for a while. The DRAM itself can get suspended (clocks turned off) in that sleep state. |
|
@paulstelian97 Lets not discuss now about Low Power Audio. This will complicate the discussion. We need to concentrate on the basic usecase: For now, we have the following topology: We will be using timer driven pipeline because it is easier to visualize the flow (not sure if DAI driven pipeline even works). Things to clarify & initial assumptions:
Buffers sizes are fixed by the decoder library and cannot be changed at runtime (maybe only at initialization time). PROCESS component during decoding MIGHT signal that its input buffer data is not enough, and can return Now, because of this, in our pipeline we can encounter the following scenario:
I think with proper buffer sizes this can work just fine, assuming the fact that passing over a buffer without consume/producing any data is not a concern. |
|
@paulstelian97 for the compressed API, you have the drain and partial-drain/next track mechanism to deal with the last parts of the stream. |
This value is unused in whole source code.
Signed-off-by: Karol Trzcinski karolx.trzcinski@linux.intel.com