CUDA-accelerated robotics algorithms (C++/CUDA), based on PythonRobotics and CppRobotics plus differentiable extensions.
Same algorithm on CPU and GPU — GPU enables orders of magnitude more particles / samples / rays:
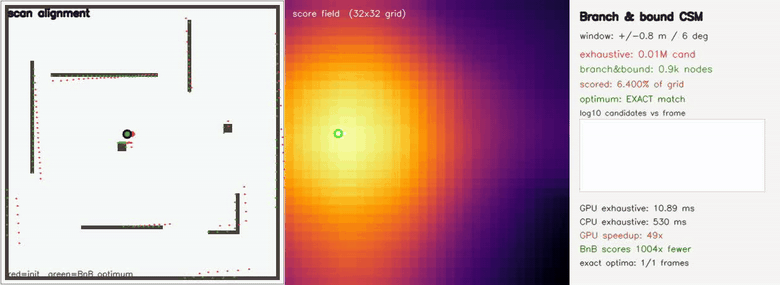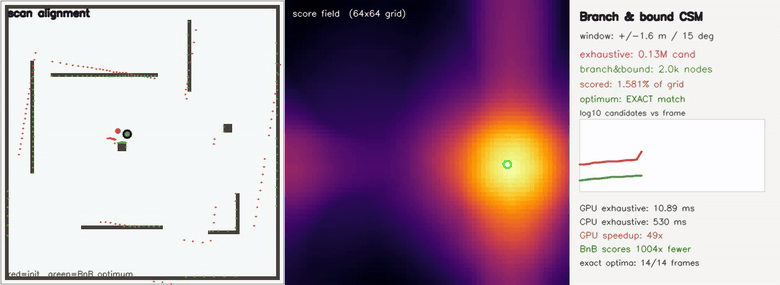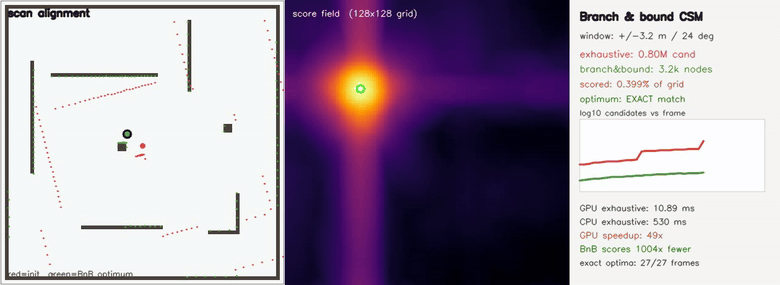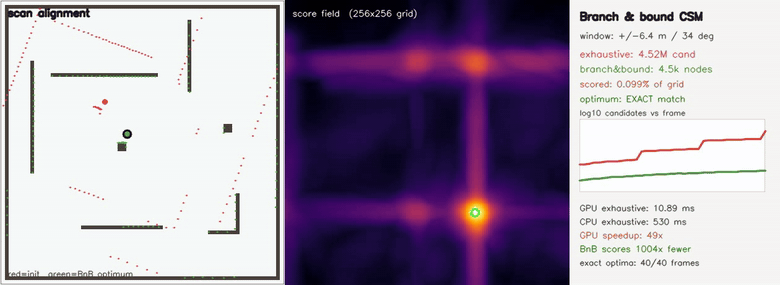
| Branch-and-bound loop-closure SLAM: B&B searches a 4.5M-cell relpose window scoring 957x fewer candidates than brute force, identical relpose on 51/51 attempts, lap closed 2.18 m → 0.20 m | Branch-and-bound CSM: the EXACT global optimum scoring 1004x fewer candidates than exhaustive search (Cartographer-style multi-resolution bound) |
 |
 |
| CSM submap SLAM: fusing several sparse scans into a submap recovers 48/52 loops (ATE 0.18 m) where single-scan matching gets only 17/52 (0.38 m) | CSM loop-closure SLAM: loops detected by scan matching (no ground truth), dead-reckoning ATE 2.03 m → 0.17 m |
 |
 |
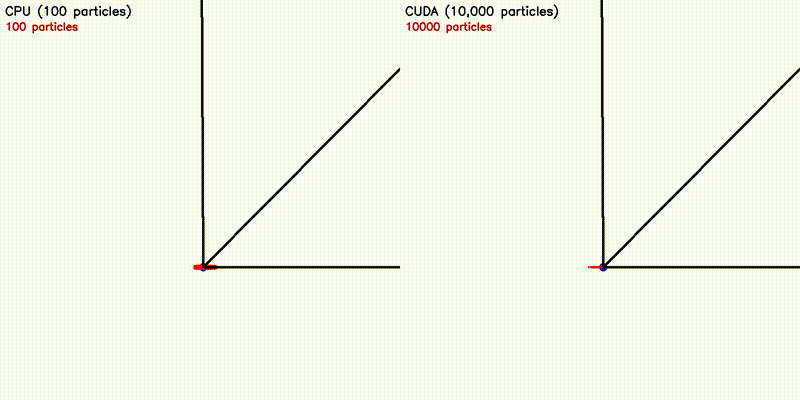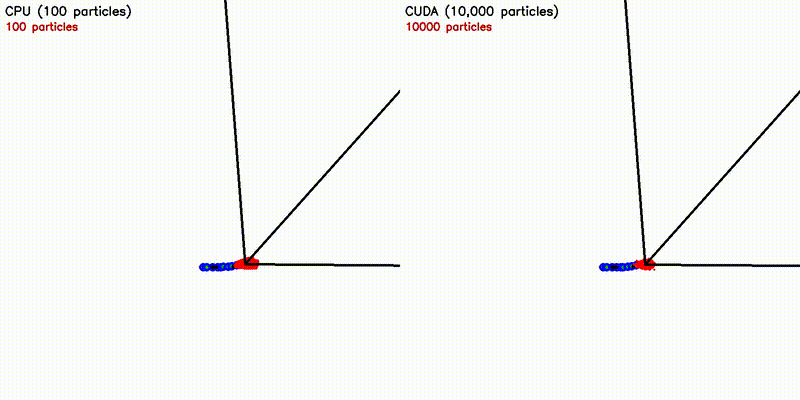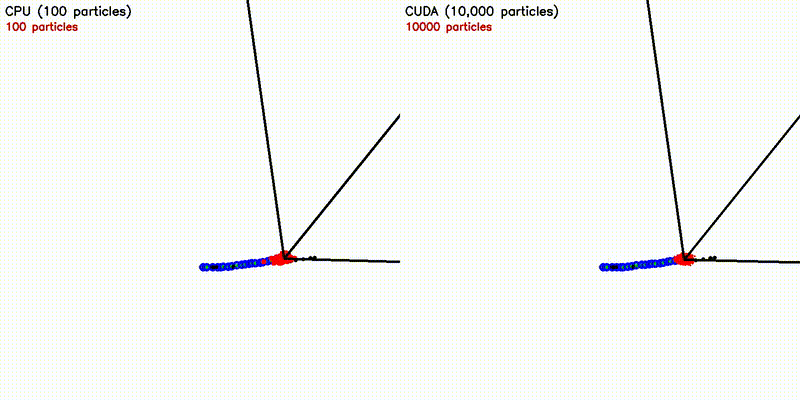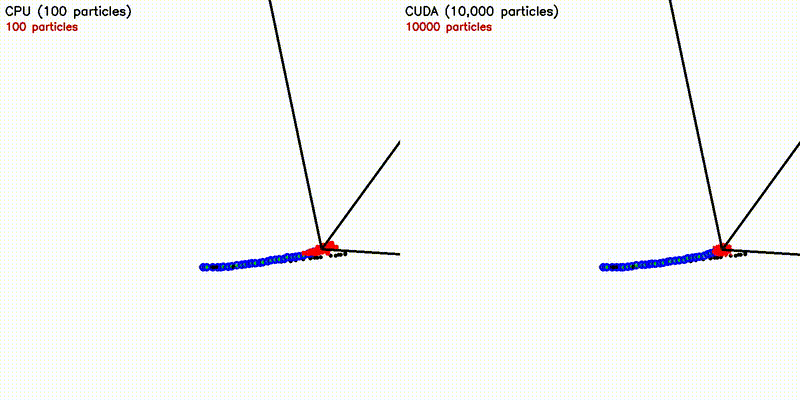
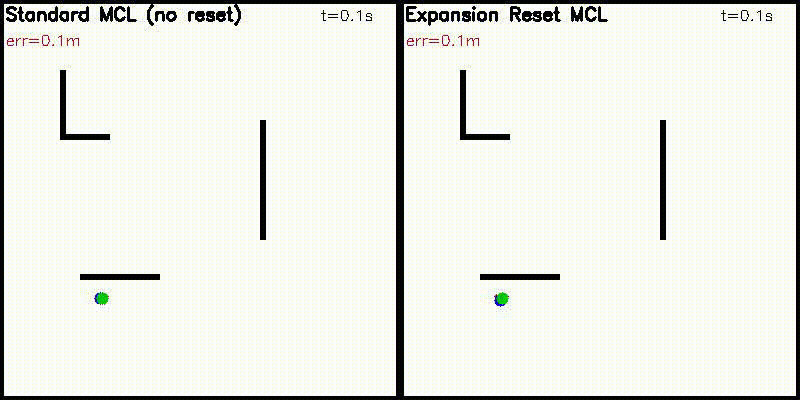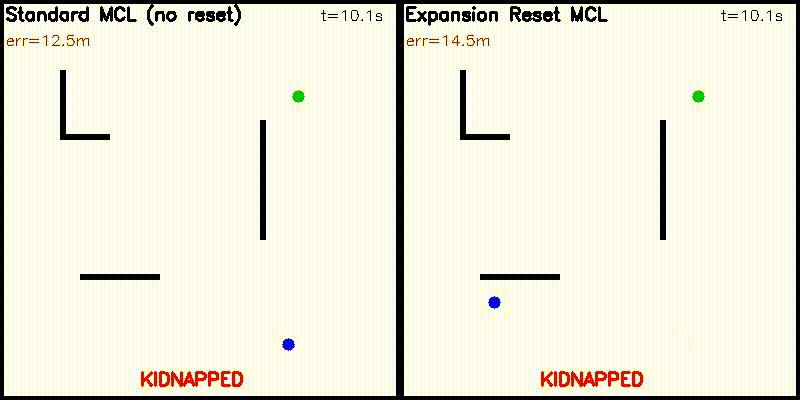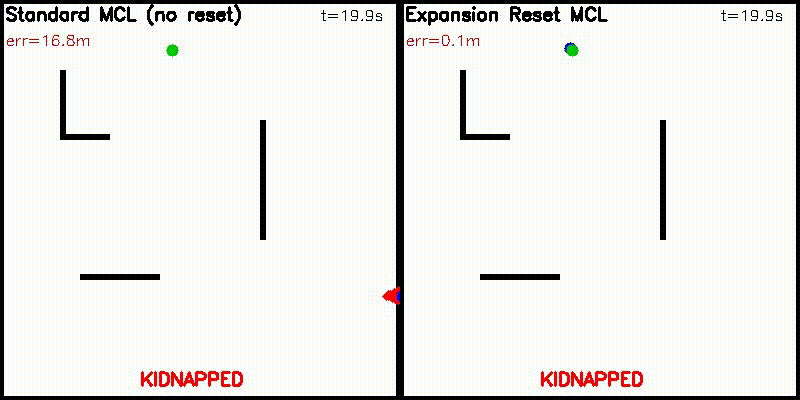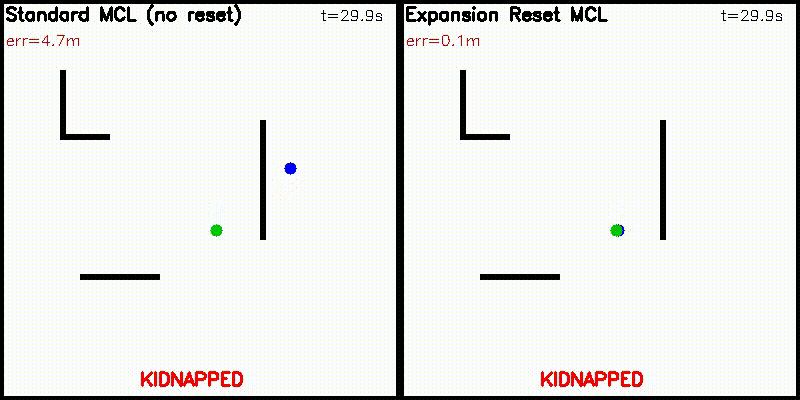
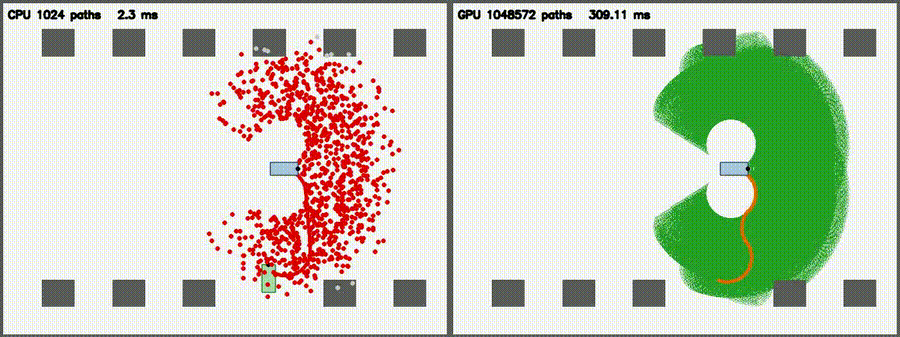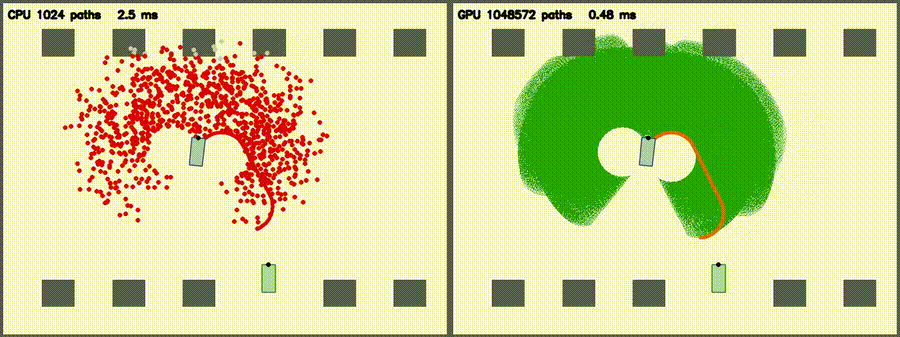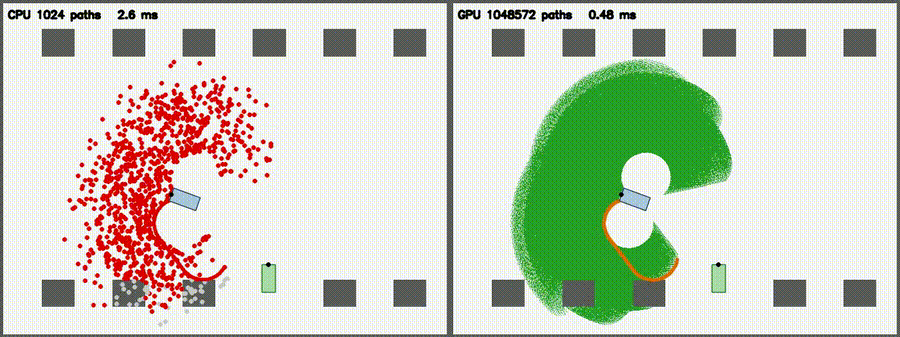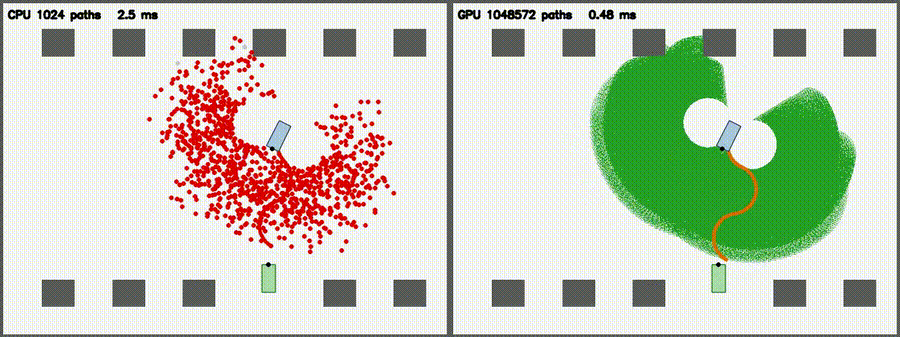
| Particle Filter: CPU 100 vs CUDA 10,000 | Expansion Reset MCL: kidnap recovery (10,000 particles) |
 |
 |
| MegaParticles-style Stein MCL: 1M range particles, hidden kidnap recovery | GPU Global Localization MCL: sensor-reset kidnap recovery (32,768 particles) |
 |
 |
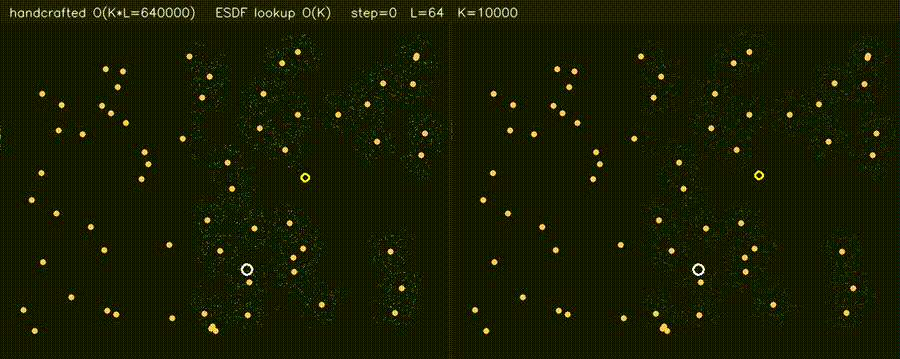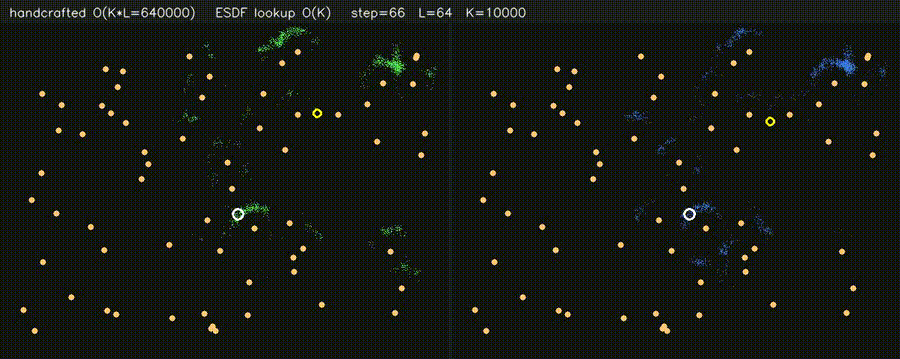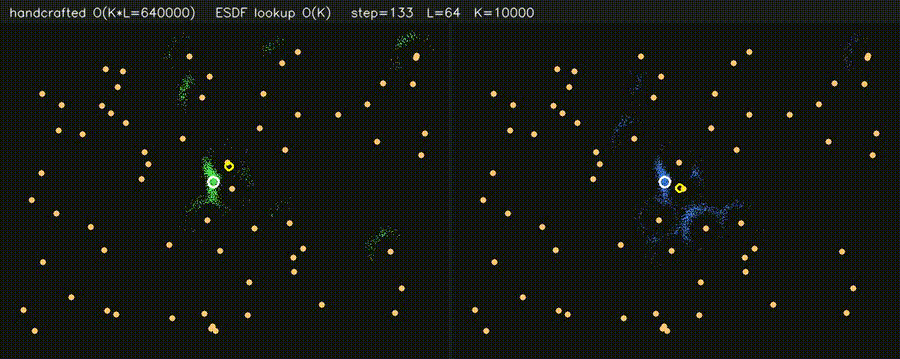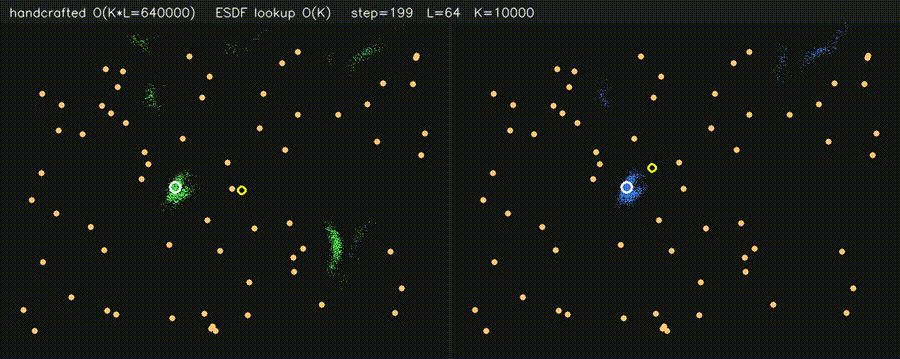
| PF + ESDF observation lookup (10,000 particles) | Multi-Robot: CPU 5 vs CUDA 500 |
 |
 |
| DWA: CPU 50 vs CUDA 50,000 samples | 3D LiDAR Sim: CPU 16x512 vs CUDA 64x2048 rays |
 |
 |
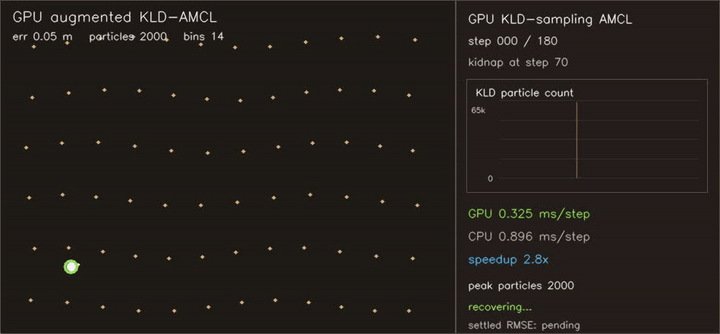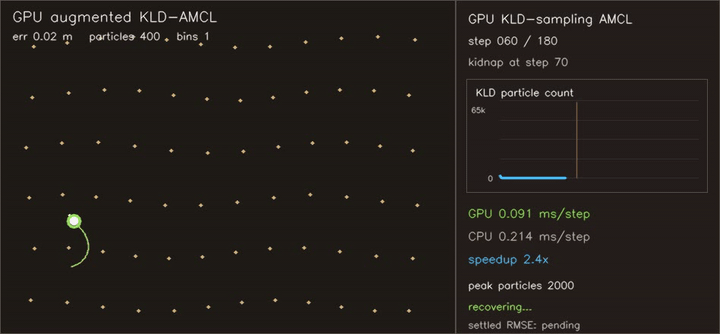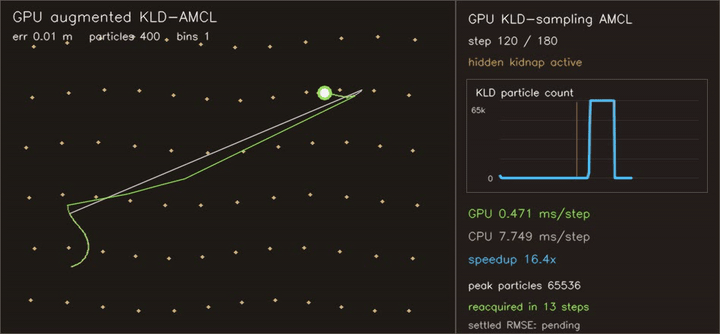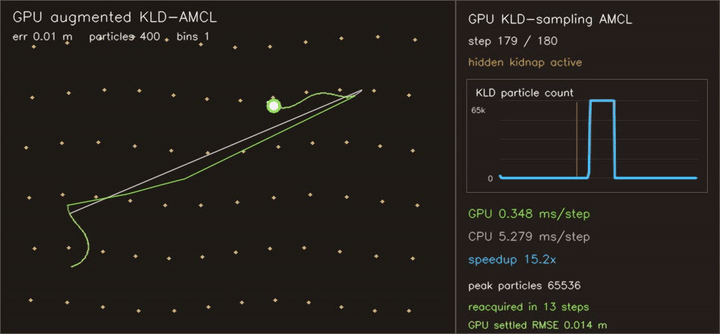
| Reeds-Shepp Fan: 1M candidate paths / frame | Augmented KLD-AMCL: adaptive 400→65,536 particles, kidnap recovery |
 |
 |
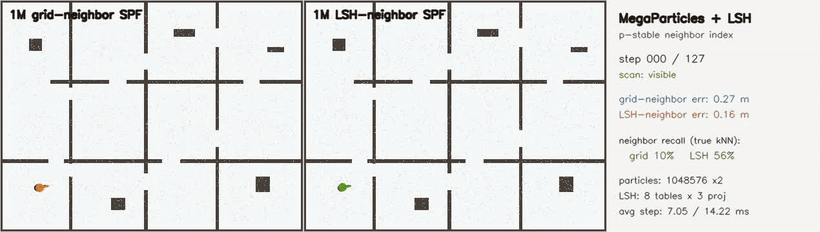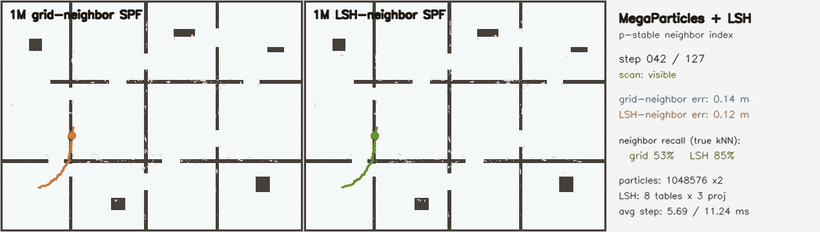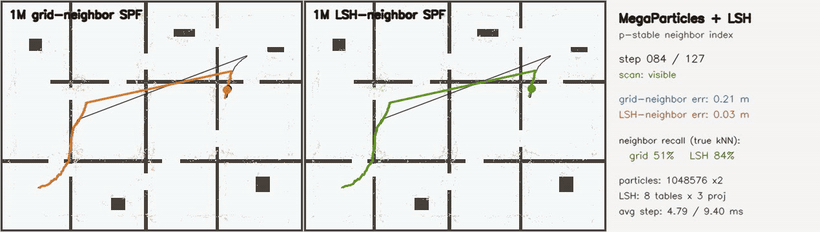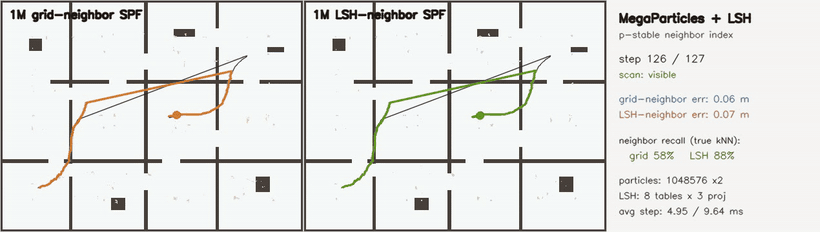
| MegaParticles + explicit p-stable LSH neighbor index: fixed grid 58% vs LSH 88% neighbor recall (1M particles) | MegaParticles 6-DoF: 1M SE(3) particles, hidden-kidnap relocalization (LSH neighbor consensus) |
 |
 |
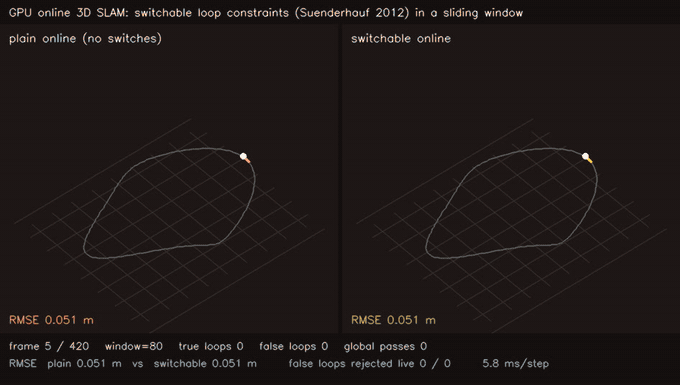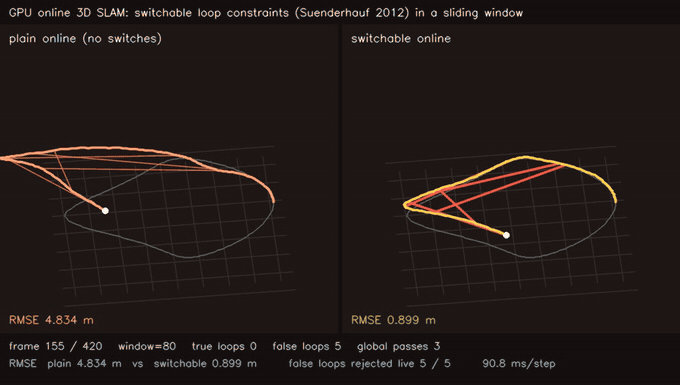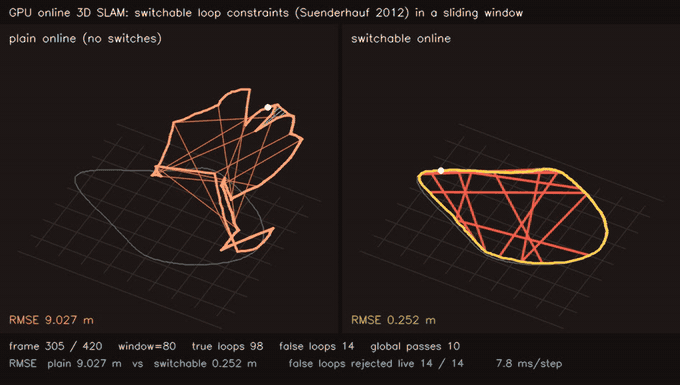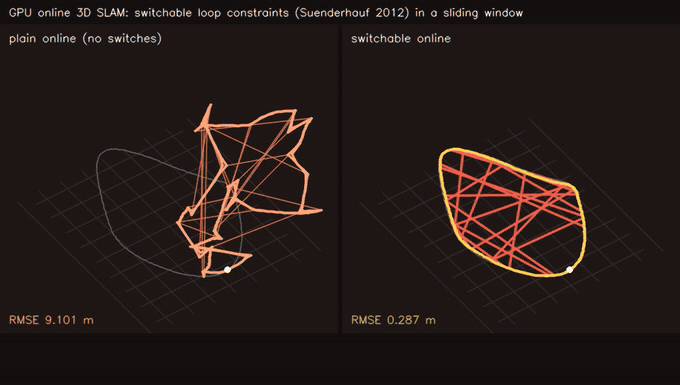
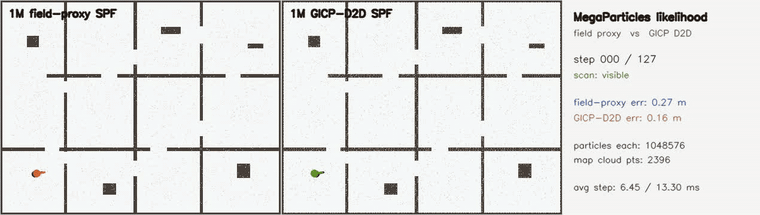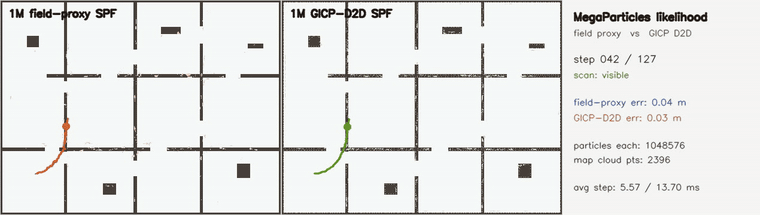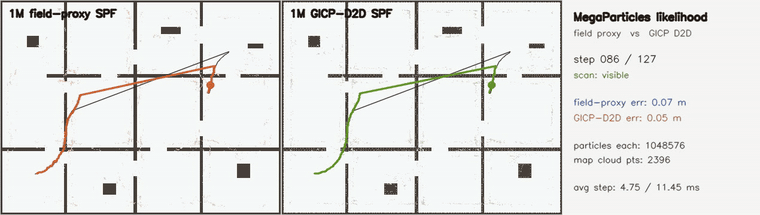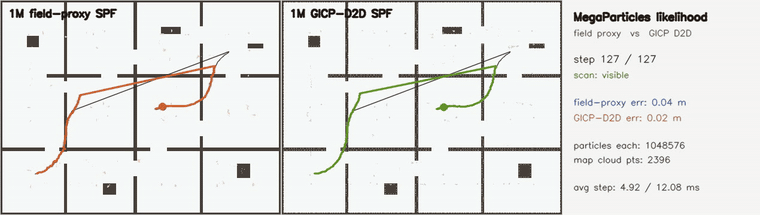
| Online 3D SLAM with switchable loop constraints: false loops rejected live (plain 9.10 m vs switchable 0.29 m, 21/21 rejected) | MegaParticles GICP D2D likelihood: surface-aware scoring halves error vs field proxy (1M particles) |
 |
 |
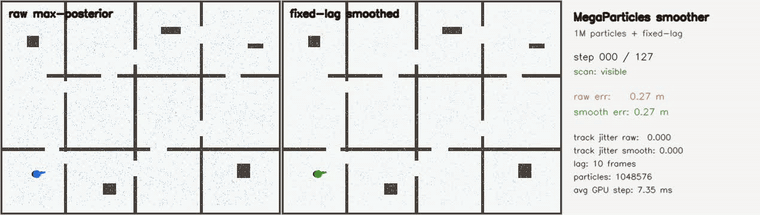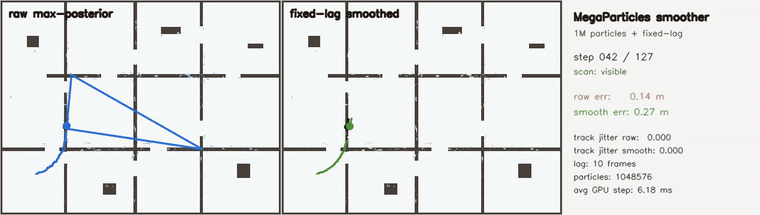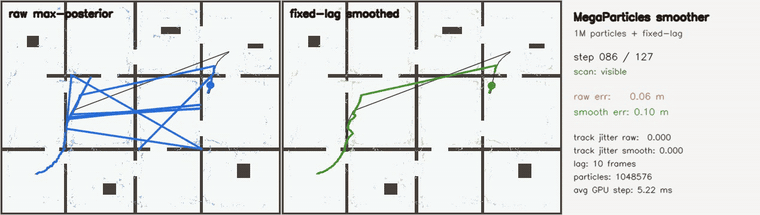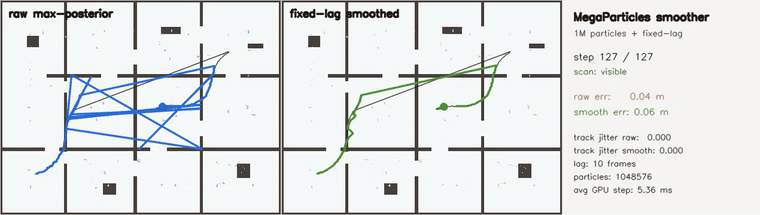
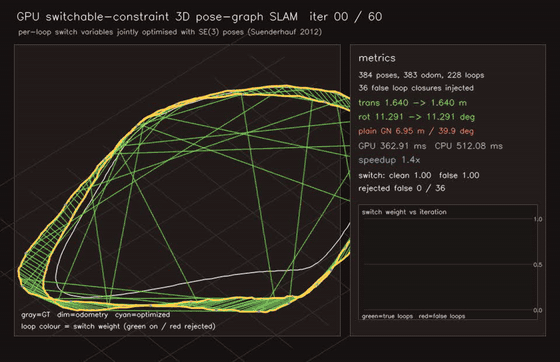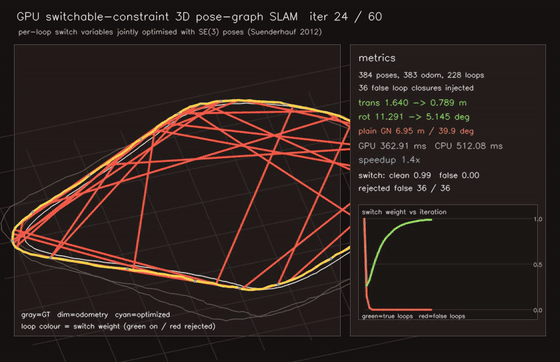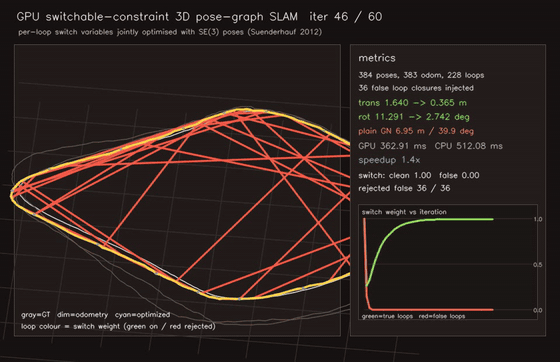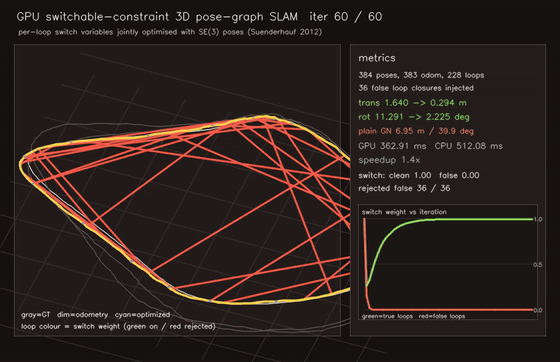
| MegaParticles trajectory smoother: robust fixed-lag cuts representative jitter ~70x and rejects spurious-mode flips (1M particles) | Switchable-constraint 3D pose-graph SLAM: 36/36 false loops rejected (plain 6.95 m vs switched 0.28 m) |
 |
 |
| CSM loop-closure SLAM: loops detected by scan matching (no ground truth), dead-reckoning ATE 2.03 m → 0.17 m, 49 loops accepted / 3 rejected | Correlative scan matching: exhaustive global alignment, 2.1M candidate poses/frame, recovers offsets where the local matcher fails (490x vs CPU) |
|
 |
| Capability | Demo | GPU scale | Headline |
|---|---|---|---|
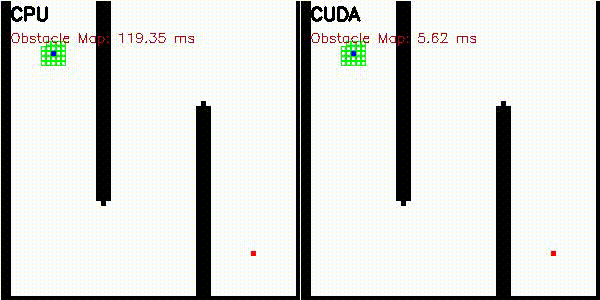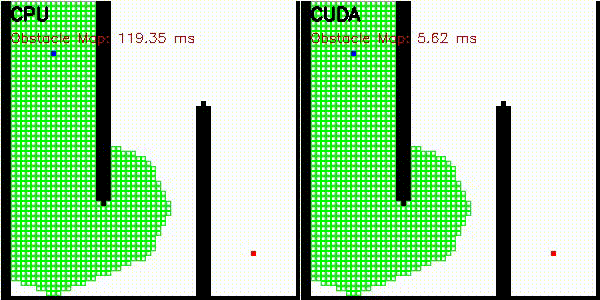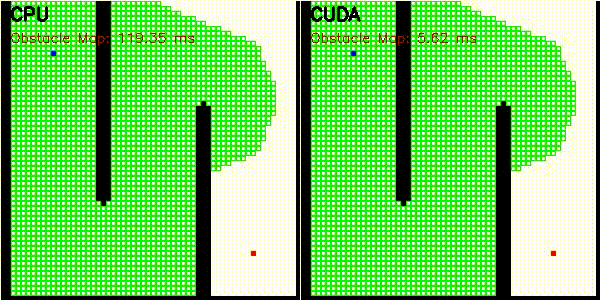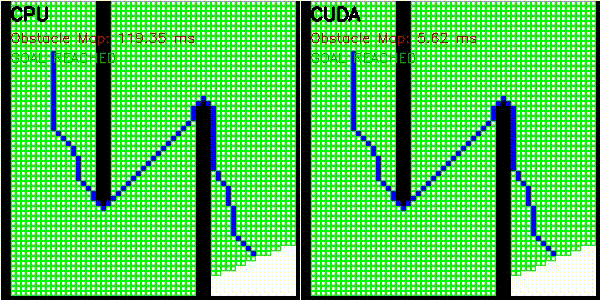
| Occupancy grid | comparison_occupancy_grid |
256x256 | log-odds raycast |
| Collision check | comparison_collision_check |
1M segments/scan | 1,277x per candidate |
| Scan matching | comparison_icp, comparison_ndt, gpu_ndt_3d_multires, gicp, gpu_correlative_scan_matching, gpu_branch_and_bound_csm |
10K+ points / 2.1M candidate poses | parallel correspondences; exhaustive global CSM recovers large offsets (44/44) where a local field matcher fails (5/44), 487x vs CPU; branch-and-bound over a GPU multi-resolution bound returns the IDENTICAL optimum scoring up to 1004x fewer candidates (40/40 frames exact) |
| Pose-graph SLAM | gpu_pose_graph_slam, gpu_pose_graph_slam_3d, gpu_pose_graph_slam_3d_robust, gpu_pose_graph_slam_3d_switchable, gpu_online_slam, gpu_online_slam_3d_switchable, gpu_csm_loop_closure_slam, gpu_csm_submap_slam, gpu_bnb_loop_closure_slam |
2D 200 poses / 3D 384-420 poses | robust 3D rejects 36/36 false loops, 6.95→0.28 m; switchable constraints learn per-loop switches jointly with poses, 6.95→0.29 m; online 3D switchable rejects false loops live in a sliding window, plain 9.10 m → switchable 0.29 m (21/21 rejected); CSM loop-closure SLAM detects loops from scan data (no GT), ATE 2.03→0.17 m, 49 accepted / 3 rejected; submap front-end fuses sparse scans → 48/52 loops (0.18 m) vs single-scan 17/52 (0.38 m); branch-and-bound loop search scores 957x fewer candidates than brute force over a 4.5M-cell window, identical relpose 51/51, ATE 2.18→0.20 m |
| Particle filter | comparison_pf, gpu_global_localization_mcl, gpu_megaparticles_stein_mcl, gpu_megaparticles_lsh, gpu_megaparticles_6dof, gpu_megaparticles_gicp_mcl, gpu_megaparticles_smoother, gpu_kld_amcl, diff_pf, diff_pf_mlp |
10K-1M particles | MegaParticles-style range SPF: 14.61 m bootstrap vs 0.097 m recovery; explicit p-stable LSH neighbor index lifts neighbor recall 58%→88%; 6-DoF SE(3) relocalization recovers a hidden kidnap to 0.22 m / 1.9 deg (LSH neighbor consensus); surface-aware GICP D2D likelihood halves post-kidnap error vs the field proxy (0.099→0.064 m); a robust fixed-lag smoother over the representative state cuts in-track jitter ~70x (RMSE 5.4→0.25 m) and rejects spurious-mode flips; KLD-AMCL adapts 400→65,536 particles, 15.2x vs CPU |
| RRT family | comparison_rrt*, comparison_rrtstar_rewire |
1M paths / 200K nodes | 5,000x per-path; 62x rewire |
| Crowd / swarm | gpu_crowd_swarm |
10,000 boids with uniform-grid neighbours | 105x vs CPU |
| Graph policy control | gpu_gnn_swarm_controller, gpu_gat_traversability_policy |
2048 agents / 3072 terrain nodes x 3 heads | 2.88 ms/control; 99.4x GAT policy |
| Assignment / tracking | gpu_hungarian_assignment, gpu_assignment_tracking |
512 x 64x64 assignment / 128 tracking scenes | 158x Hungarian; 14.0x tracking |
| Interaction graph risk | gpu_interaction_graph_risk, gpu_interaction_graph_neural_mppi, gpu_multiagent_graph_neural_mppi, gpu_priority_graph_neural_mppi, gpu_intent_graph_neural_mppi, gpu_belief_risk_graph_mppi, gpu_best_response_graph_mppi, gpu_iterative_game_graph_mppi, gpu_noregret_game_graph_mppi, gpu_safe_noregret_game_graph_mppi, gpu_learned_safety_dual_graph_mppi, gpu_trainable_safety_dual_graph_mppi, gpu_planner_showdown_benchmark, gpu_planner_falsifier_benchmark |
2048 agents x 10 message passes / 48-agent graph x 4 passes / 48 robots x 768 MPPI rollouts / 719K scenario falsifier scan | 76.3x risk propagation; interaction-aware MPPI reduces social risk 19.7%; multi-agent graph MPPI cuts cross-route collisions 518 -> 261; priority arbitration cuts 261 -> 245; intent beliefs cut 518 -> 216; belief CVaR cuts collision tail risk 31.6%; best-response game cuts collisions 518 -> 171; damped fictitious play cuts collisions 518 -> 154; regret matching cuts collisions 518 -> 150; safety-constrained no-regret cuts collisions 518 -> 136 and CVaR 43.34 -> 37.93; learned safety-dual prior keeps reach 48/48 with collisions 518 -> 140 and residual 16.53%; trainable safety-dual prior trains 1152 labels and reaches collisions 132 / CVaR 37.10; scenario-conditioned pressure showdown reaches 0 collisions, CVaR 21.61, residual 4.90%, 13.05 ms; adversarial falsifier scans 719,712 scenarios and finds 12/12 no-pressure failures while learned repair passes |
| Risk-aware planning | gpu_reciprocal_risk_planner, gpu_interaction_graph_neural_mppi, gpu_multiagent_graph_neural_mppi, gpu_priority_graph_neural_mppi, gpu_intent_graph_neural_mppi, gpu_belief_risk_graph_mppi, gpu_best_response_graph_mppi, gpu_iterative_game_graph_mppi, gpu_noregret_game_graph_mppi, gpu_safe_noregret_game_graph_mppi, gpu_learned_safety_dual_graph_mppi, gpu_trainable_safety_dual_graph_mppi, gpu_planner_showdown_benchmark, gpu_planner_falsifier_benchmark |
1024 agents x 9 actions x H=16 / 32768 social-risk MPPI rollouts / 48 robot coordinated, priority, intent-aware, CVaR belief, best-response, iterative game, no-regret, safe no-regret, learned/trainable safety-dual, showdown MPPI, and adversarial falsifier | 4.05 ms/plan; 311.5x reciprocal risk; 4140.9x interaction-graph MPPI; 3139.6x multi-agent graph MPPI; 292.9x intent graph MPPI; 3132.6x best-response graph MPPI; 3181.3x iterative game graph MPPI; 2960.6x no-regret graph MPPI; 3043.4x safe no-regret graph MPPI; 3075.5x learned safety-dual prior graph MPPI; 3013.1x trainable safety-dual prior graph MPPI; 2977.5x planner showdown benchmark; 70.7x adversarial falsifier scan |
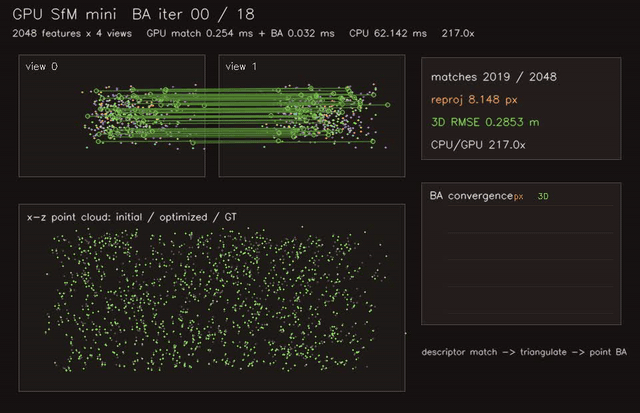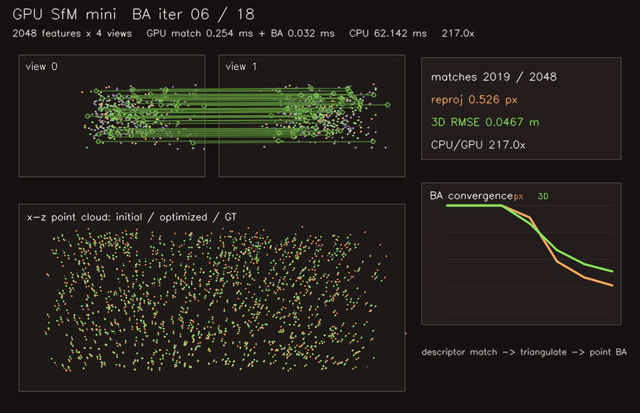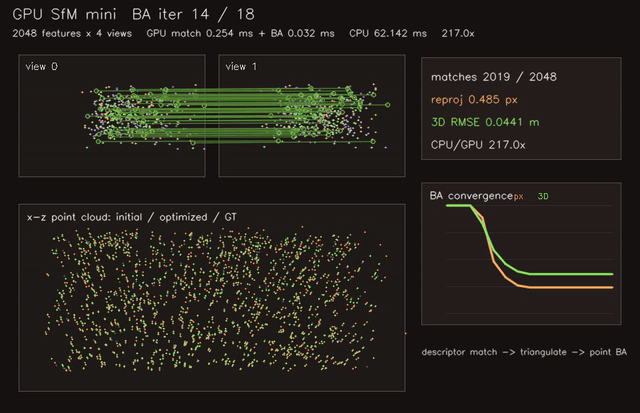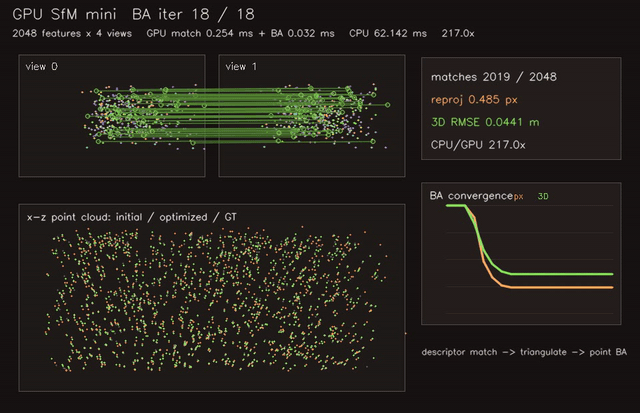
| SfM / multi-view | gpu_sfm_mini |
2048 features x 4 views | 217.0x match + BA vs CPU |
| Sparse linear solvers | gpu_pcg_solver |
262K unknowns / 1.31M CSR nnz | 13.4x Jacobi-PCG vs CPU |
| Clustering / graph ML | gpu_em_gmm, gpu_spectral_clustering, gpu_label_propagation, gpu_label_propagation_traversability, gpu_graph_crf_traversability |
262K GMM points / 3K graph nodes | 90.2x EM; 193x spectral; 123x propagation; 106x CRF |
| Black-box optimization | gpu_cma_es |
3 x 32,768 candidates x 10D | 1,254x objective eval |
| Monte Carlo planning | gpu_mcts_planner |
64 scenes x 4096 rollouts x 48 horizon | 712x vs CPU |
| Learning-based planning | gpu_diffusion_planner, gpu_diffusion_policy, gpu_diff_value_iteration_traversability, gpu_neural_astar_traversability, gpu_anytime_neural_astar_traversability, gpu_multigoal_neural_astar_traversability, gpu_spatiotemporal_neural_astar_traversability, gpu_experience_graph_neural_planner, gpu_graph_guided_neural_mppi, gpu_kinodynamic_graph_neural_mppi, gpu_multiagent_graph_neural_mppi, gpu_priority_graph_neural_mppi, gpu_intent_graph_neural_mppi, gpu_belief_risk_graph_mppi, gpu_best_response_graph_mppi, gpu_iterative_game_graph_mppi, gpu_noregret_game_graph_mppi, gpu_safe_noregret_game_graph_mppi, gpu_learned_safety_dual_graph_mppi, gpu_trainable_safety_dual_graph_mppi, gpu_planner_showdown_benchmark, gpu_planner_falsifier_benchmark |
512 x 64 trajectories / 192x128 soft VI / 64x neural A* / 1536-node graph / 32768 MPPI rollouts / 48 robot graph MPPI / 719K adversarial scenario scan | analytic score -> BC denoising policy; 747.4x learned-cost VI; 153.1x batched neural A*; 278.5x experience-graph A*; 1320.1x graph-guided MPPI; 100% top-1 intent MPPI; belief-space CVaR tail-risk MPPI; graph-neural best-response, damped fictitious-play, no-regret, safety-constrained no-regret, learned safety-dual prior, trainable safety-dual prior, target-gated planner showdown MPPI, and adversarial falsifier repair gate |
| Voxel map (3D) | comparison_voxel_map |
256x256x32 | 58x per ray |
| ESDF (2D/3D) | comparison_esdf, comparison_esdf_3d |
640K cells / 1.05M voxels | 53,404x / 86,613x |
| LiDAR sim | comparison_lidar_sim, comparison_lidar3d_sim, comparison_lidar3d_realistic |
1M 2D / 131K 3D rays | + 5 physical effects (realistic) |
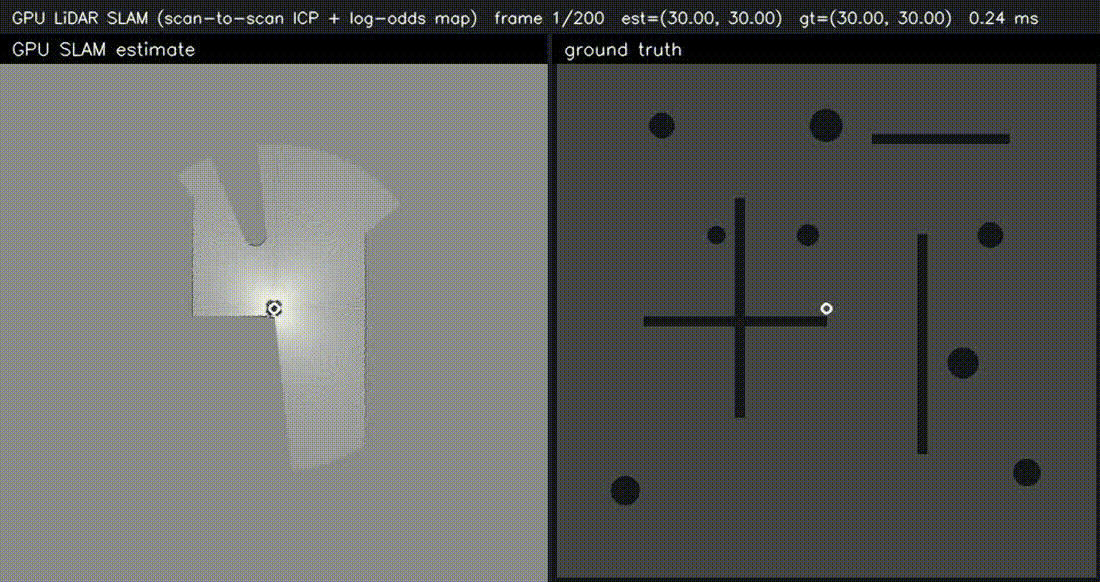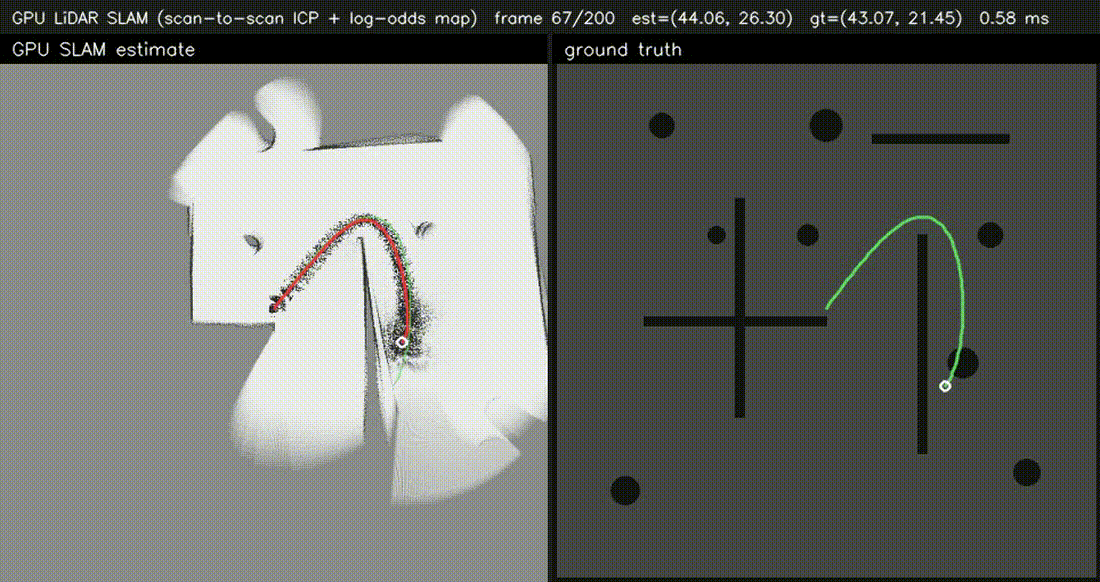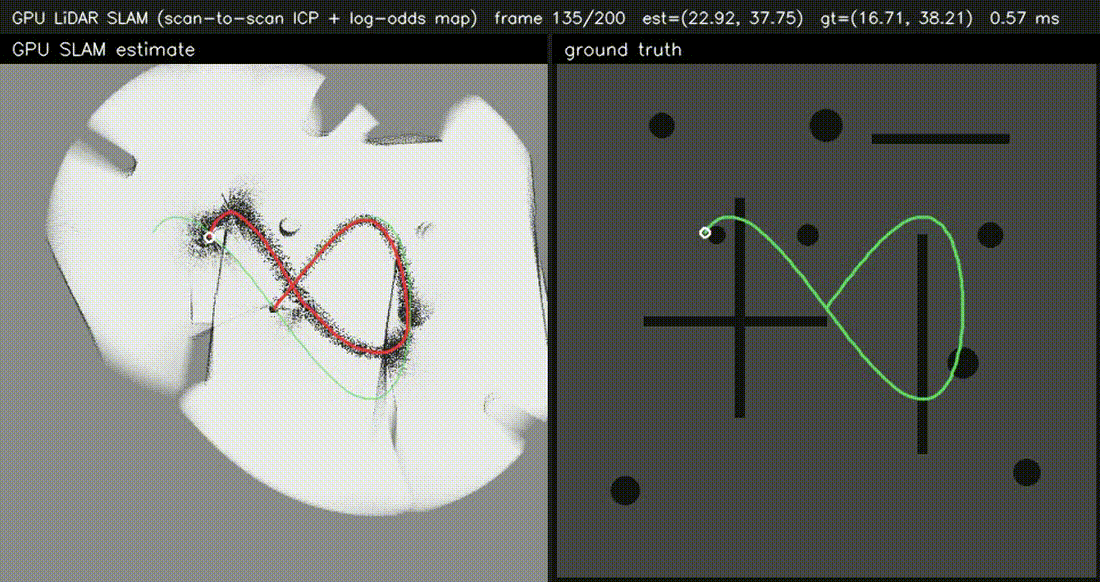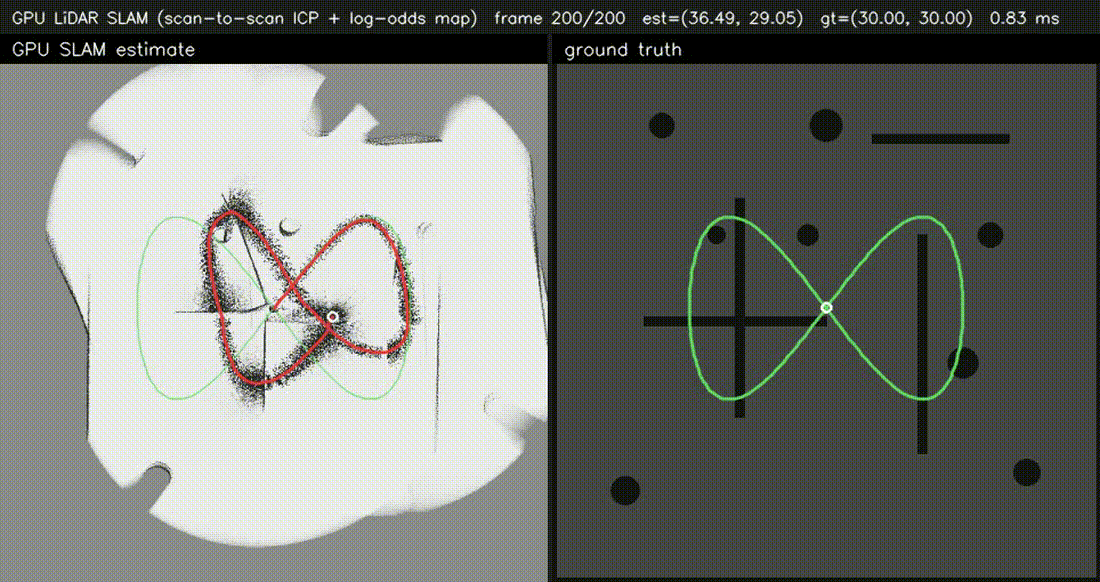
| GPU Bundle Adjustment (1000 poses × 8000 LM, 60k obs, 0.5 ms/iter) | GPU LiDAR SLAM frontend (scan-to-scan ICP, 0.68 ms/frame) |
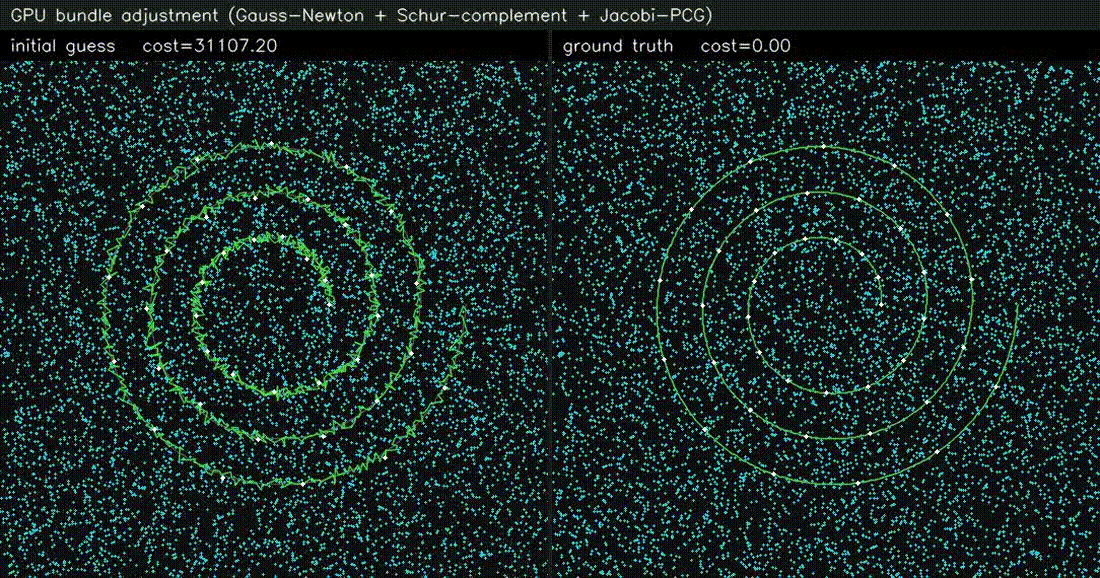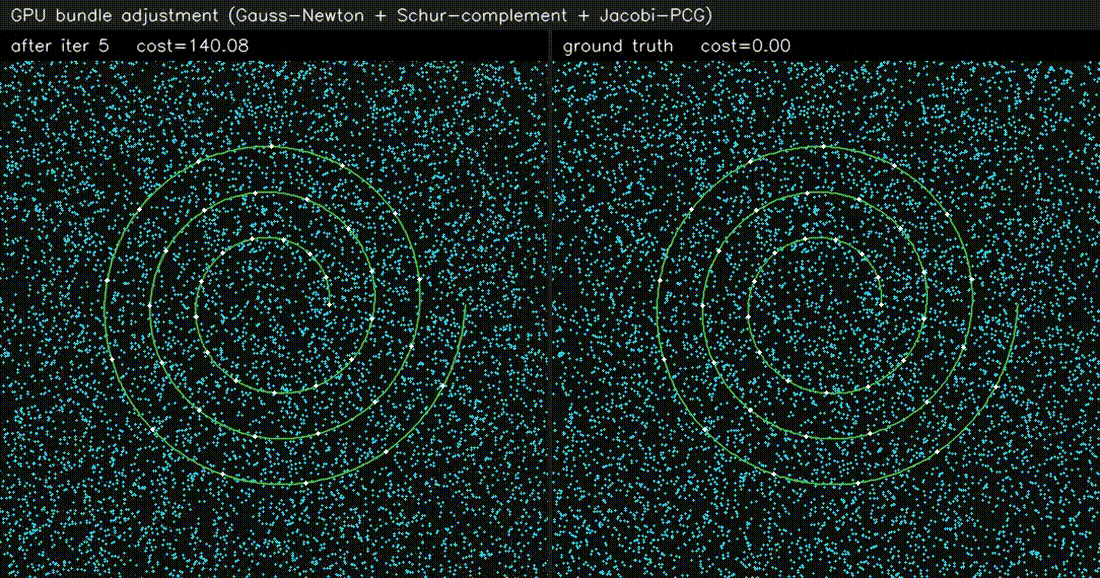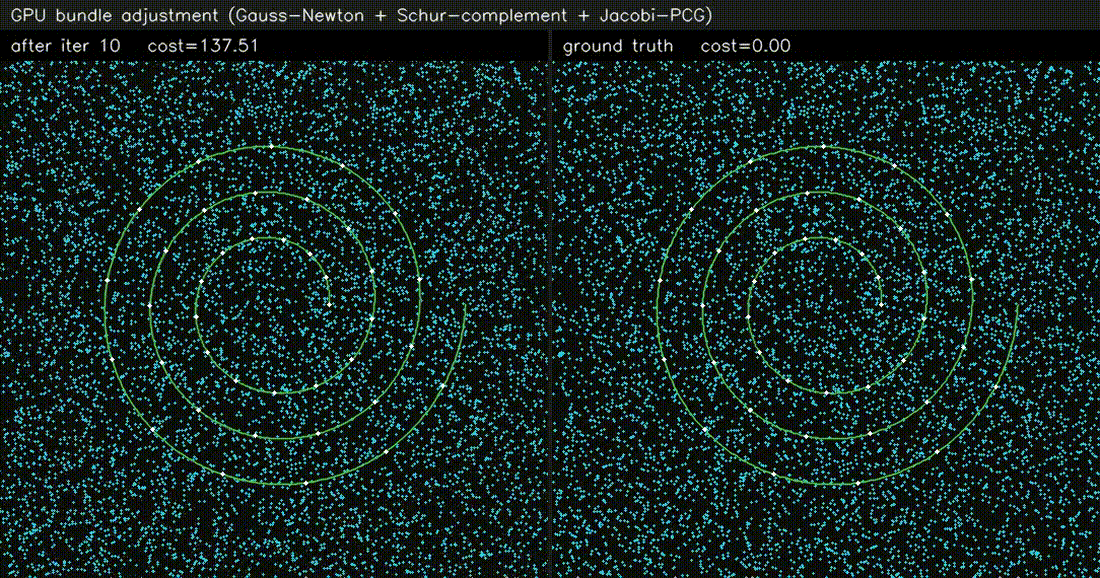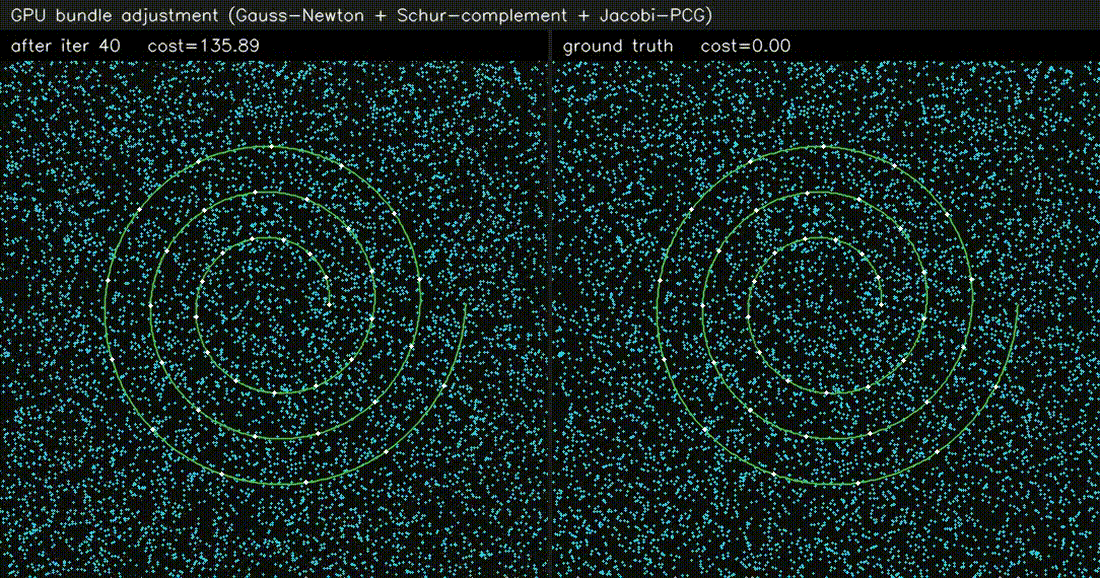 |
 |
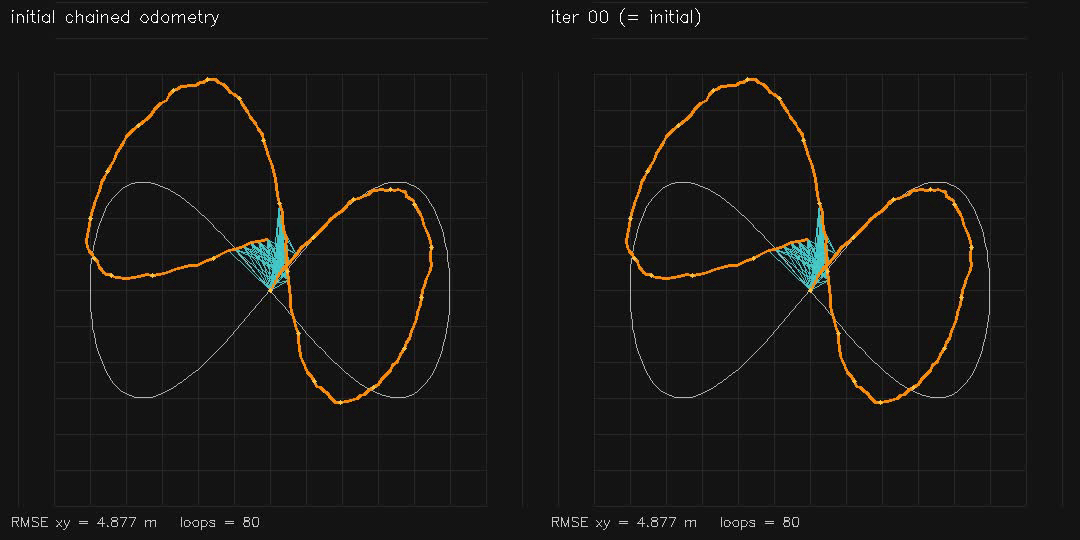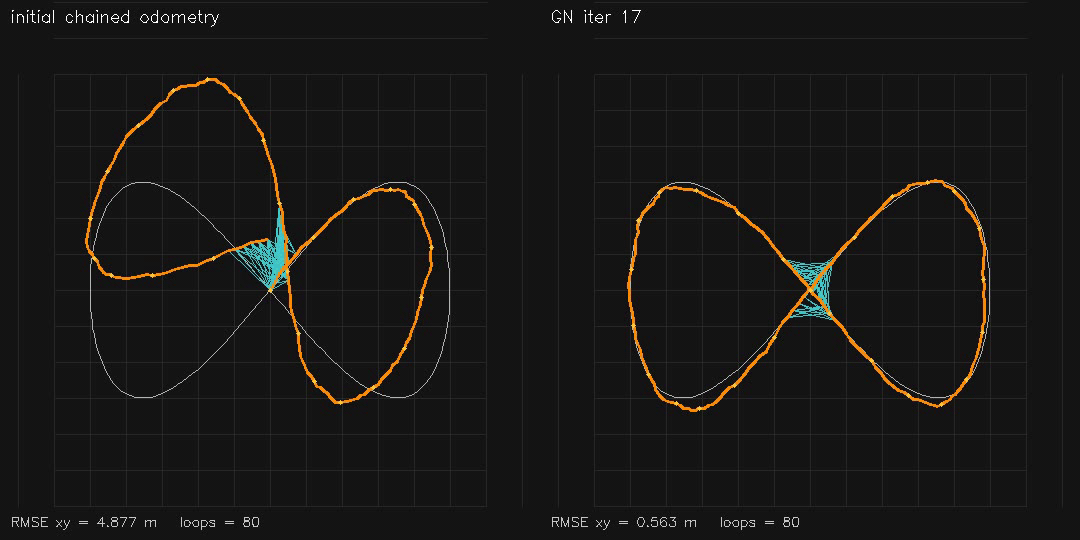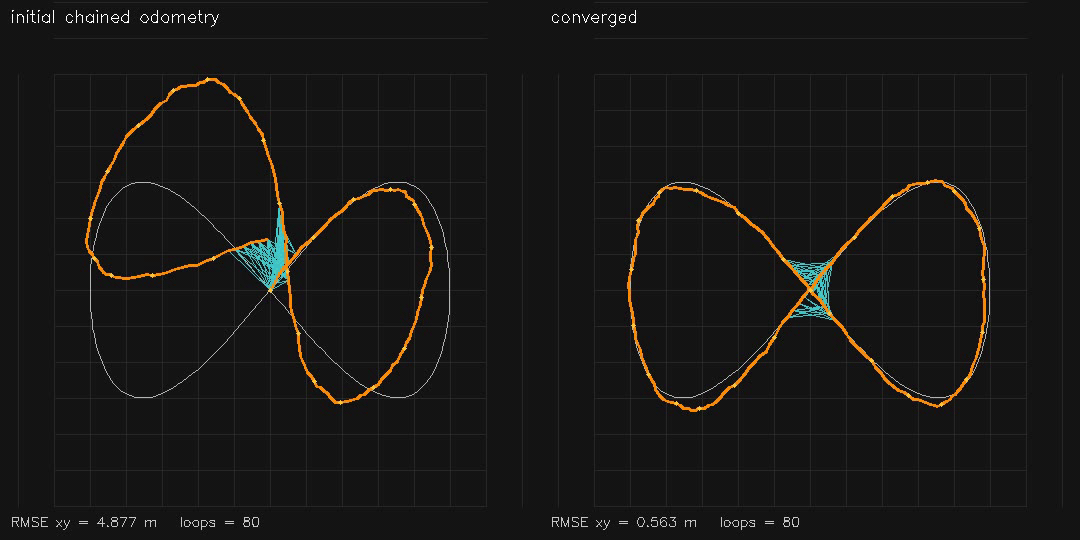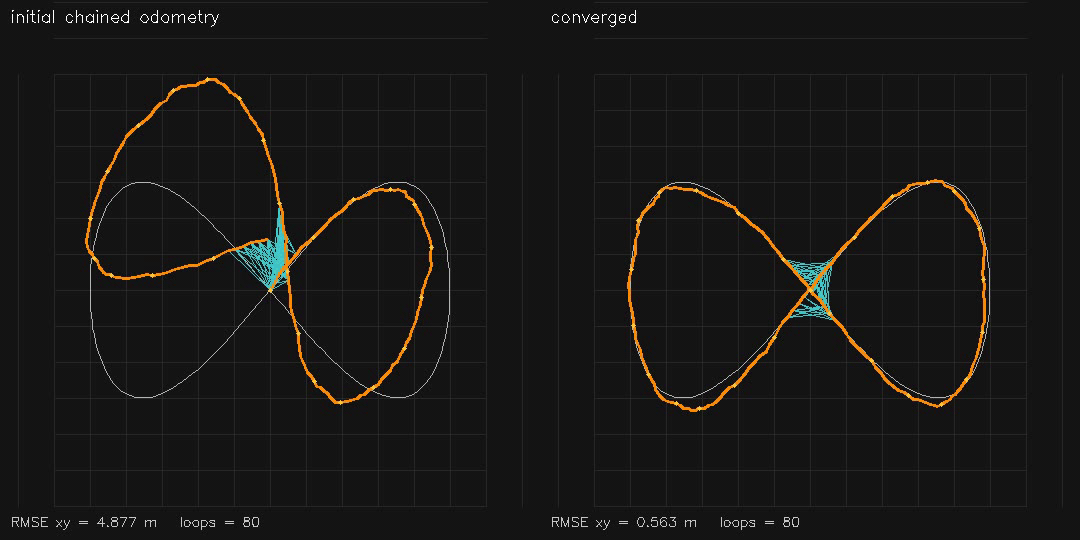
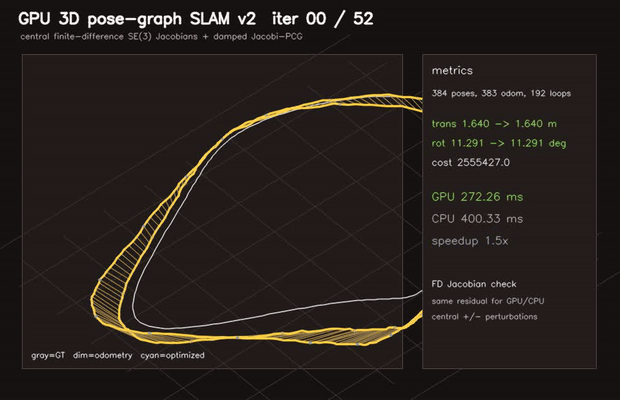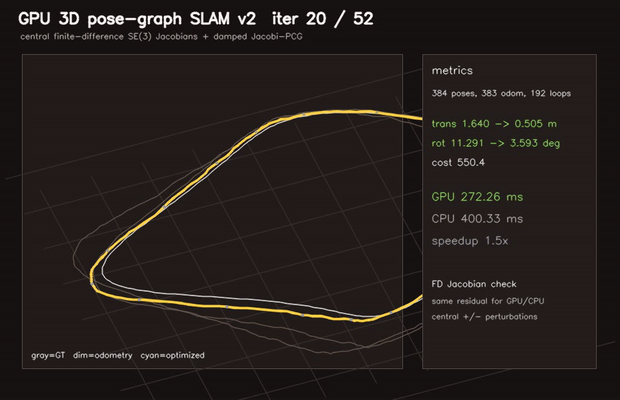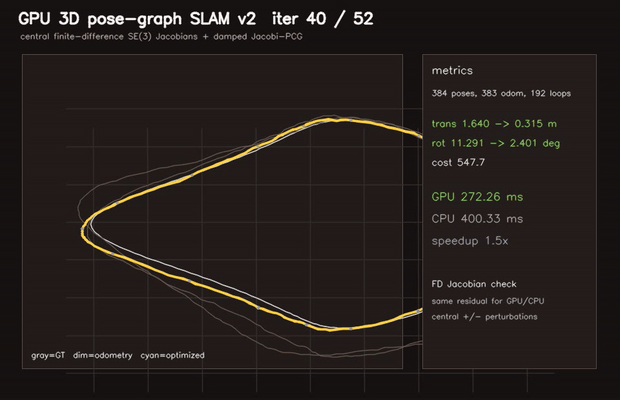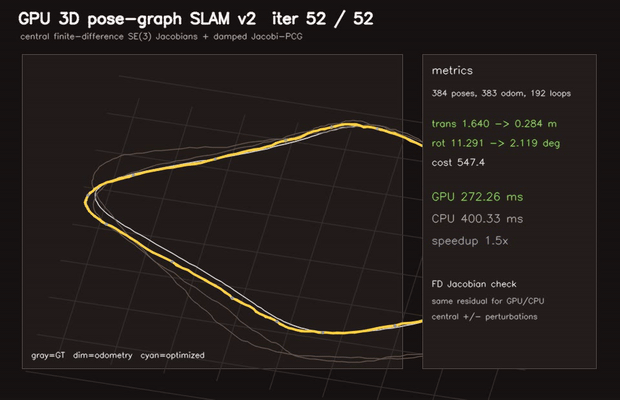
| GPU Pose-Graph SLAM backend (2D GN+Jacobi-PCG, RMSE 4.88→0.56 m) | GPU 3D Pose-Graph SLAM v2 (384 poses, finite-difference SE(3) Jacobians, RMSE 1.64→0.28 m) |
 |
 |
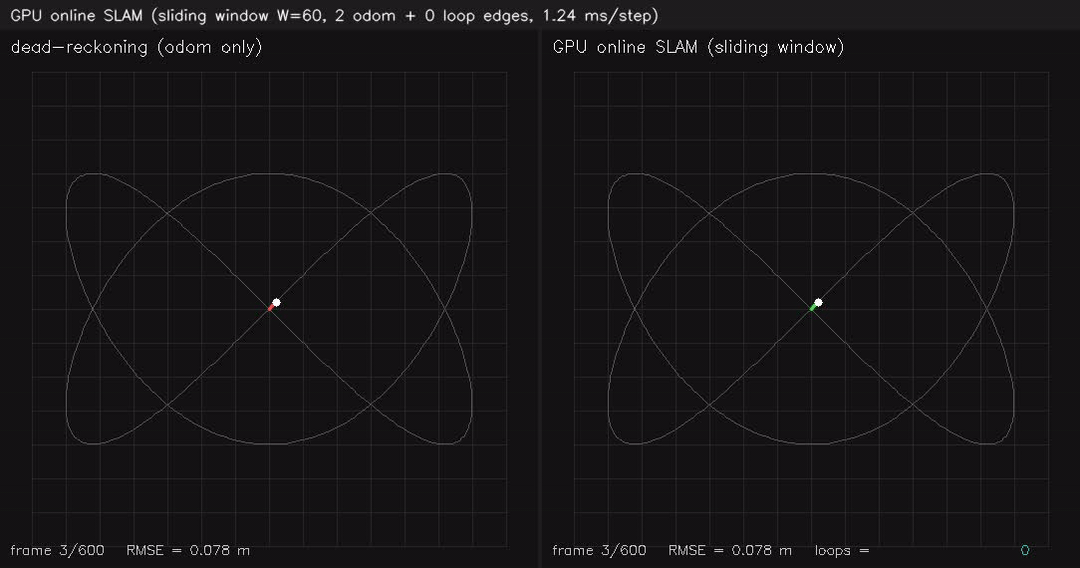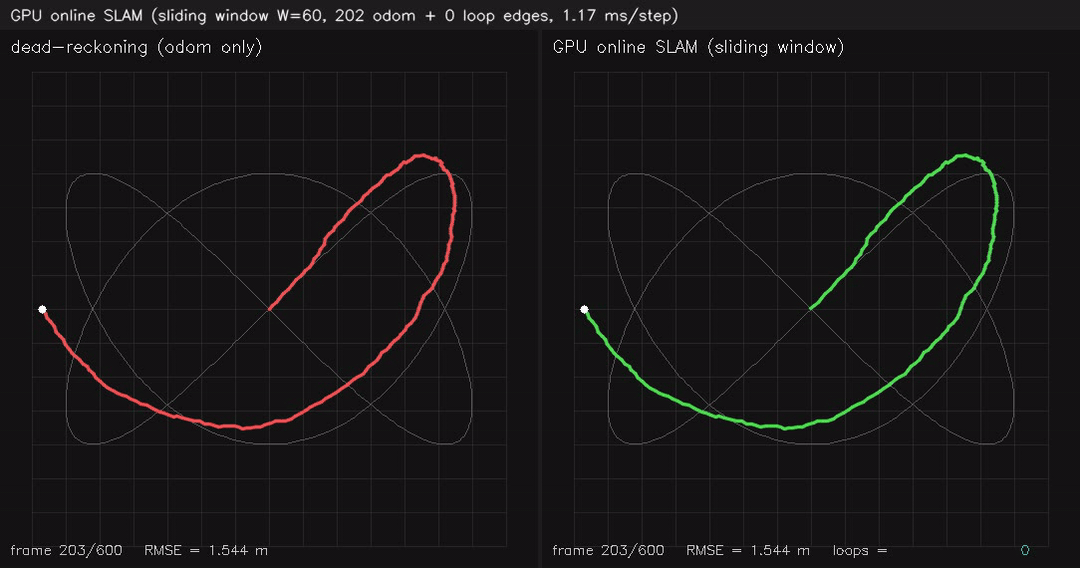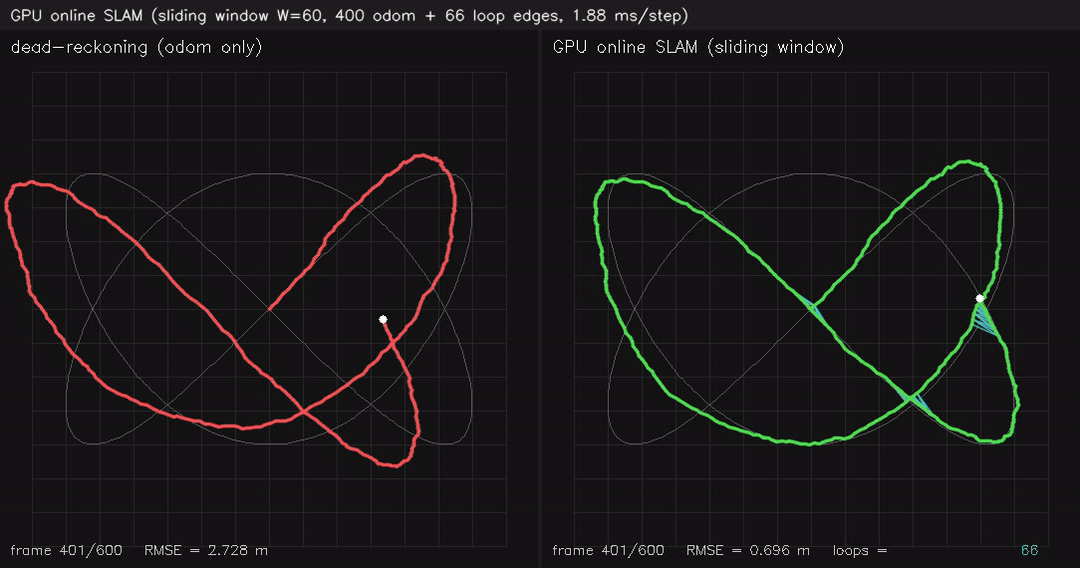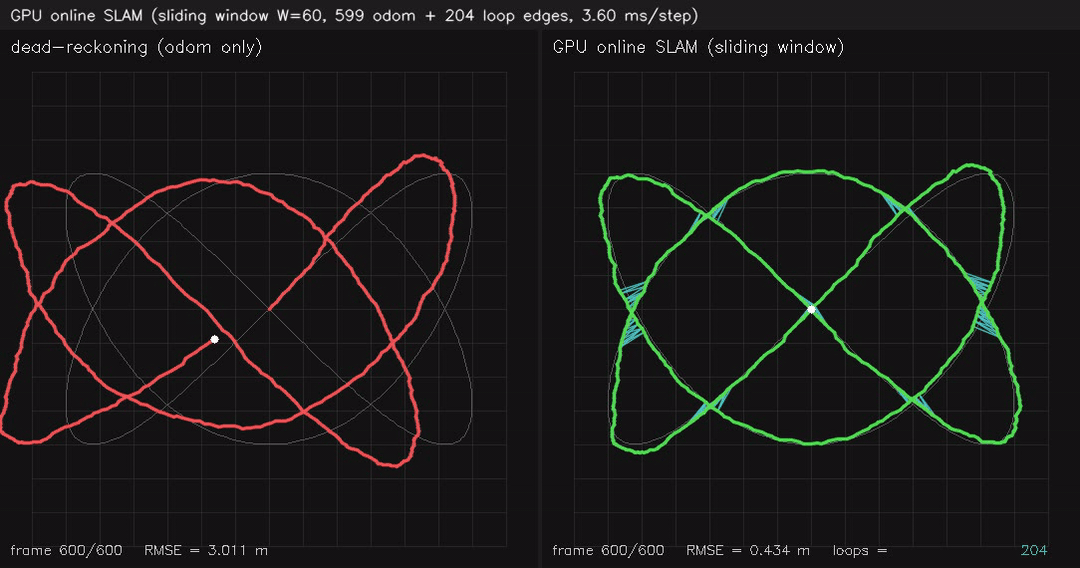
| GPU robust 3D Pose-Graph SLAM (36 false loops, switch gate rejects 36/36, plain 6.95 m → robust 0.28 m) | GPU online SLAM (sliding-window W=60 + iSAM-style global pass on loop, 1.7 ms/step, 3.0 → 0.4 m RMSE) |
 |
 |
| GPU NeRF-style volumetric renderer (720×480, 128 samples/ray, 0.83 ms/frame) | GPU SfM mini (2048 features × 4 views, descriptor match + triangulate + point BA, 217.0x vs CPU) |
 |
 |
| GPU 3D Gaussian Splatting renderer (~1k Gaussians, 0.94 ms/frame) | GPU switchable-constraint 3D Pose-Graph SLAM (per-loop switch variables optimised jointly with SE(3) poses, 36/36 false loops rejected, plain 6.95 m → switchable 0.29 m) |
 |
|
| GPU online 3D SLAM with switchable loop constraints (sliding-window SE(3) + live switch update, false loops rejected as they stream in, plain 9.10 m → switchable 0.29 m, 21/21 rejected) | GPU CSM loop-closure SLAM (loops DETECTED by exhaustive scan matching, not GT; 1.4M candidate relposes/attempt, dead-reckoning ATE 2.03 m → SLAM 0.17 m, 49 accepted / 3 rejected, 630x vs CPU) |
|
|
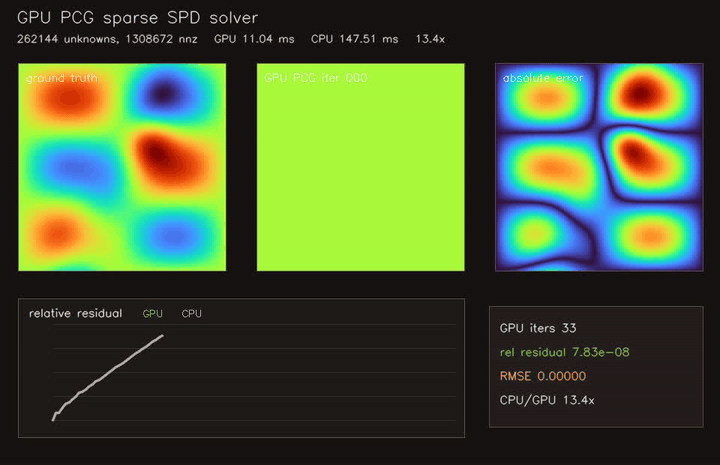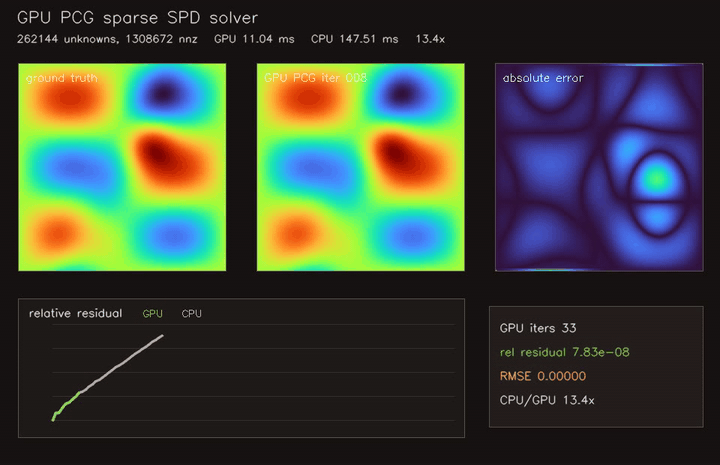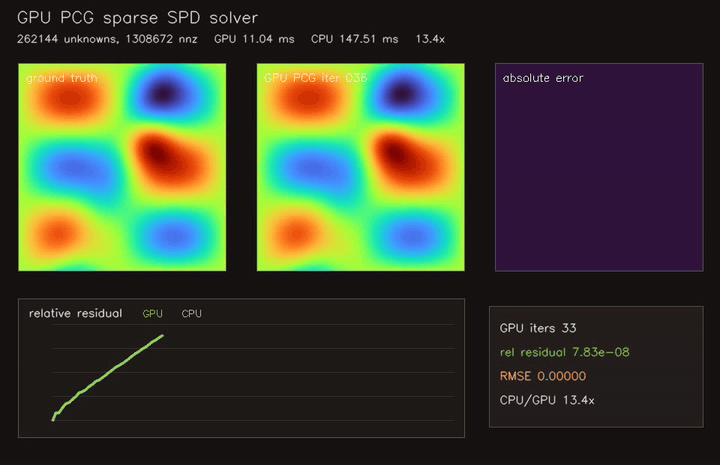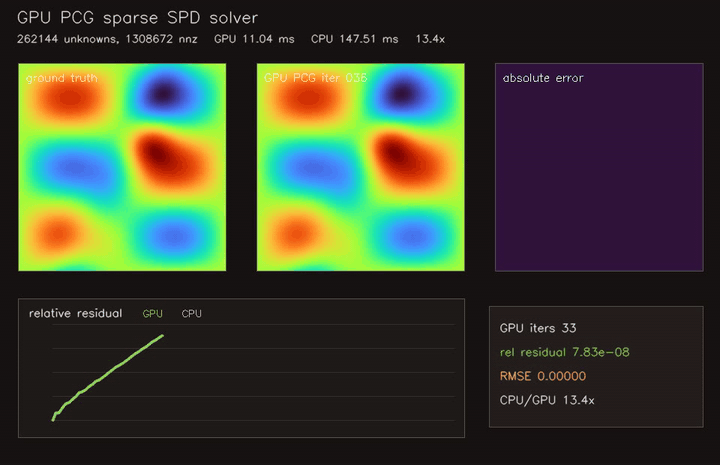
| GPU Jacobi-PCG sparse SPD solver (262K unknowns, 1.31M CSR nnz, 33 iterations, 13.4x vs CPU) | |
 |
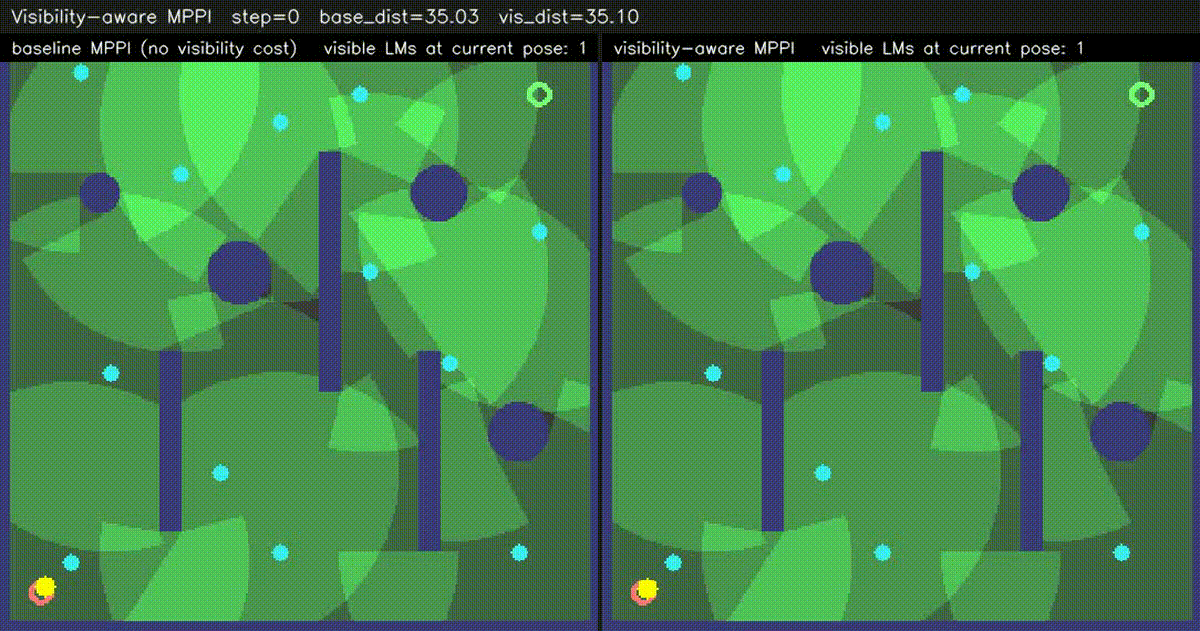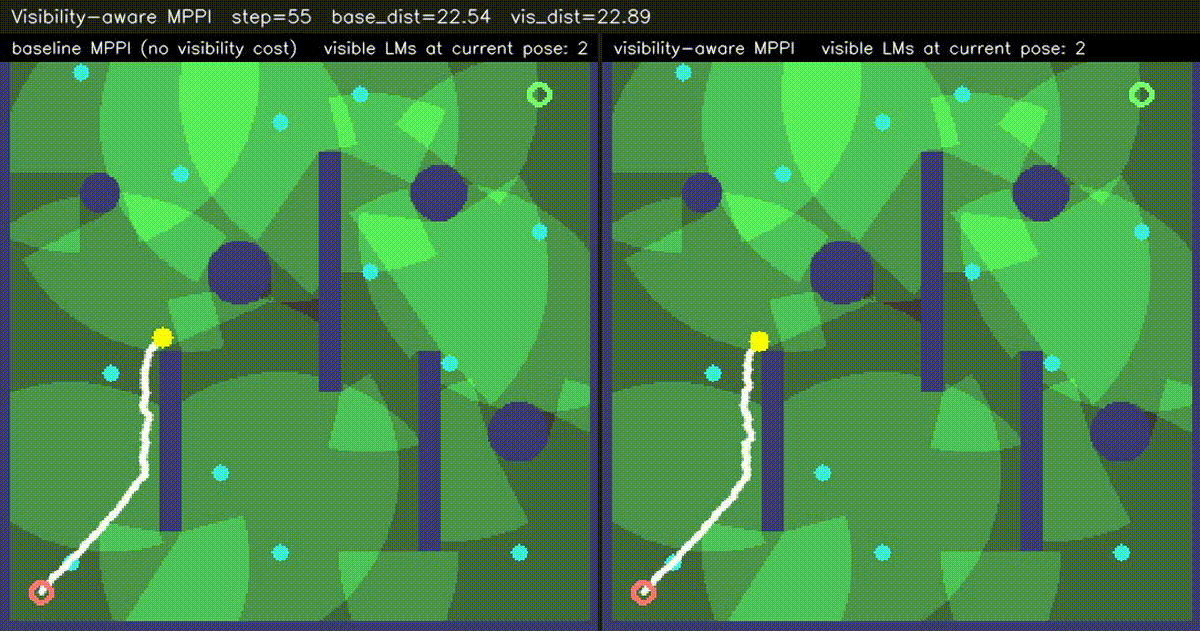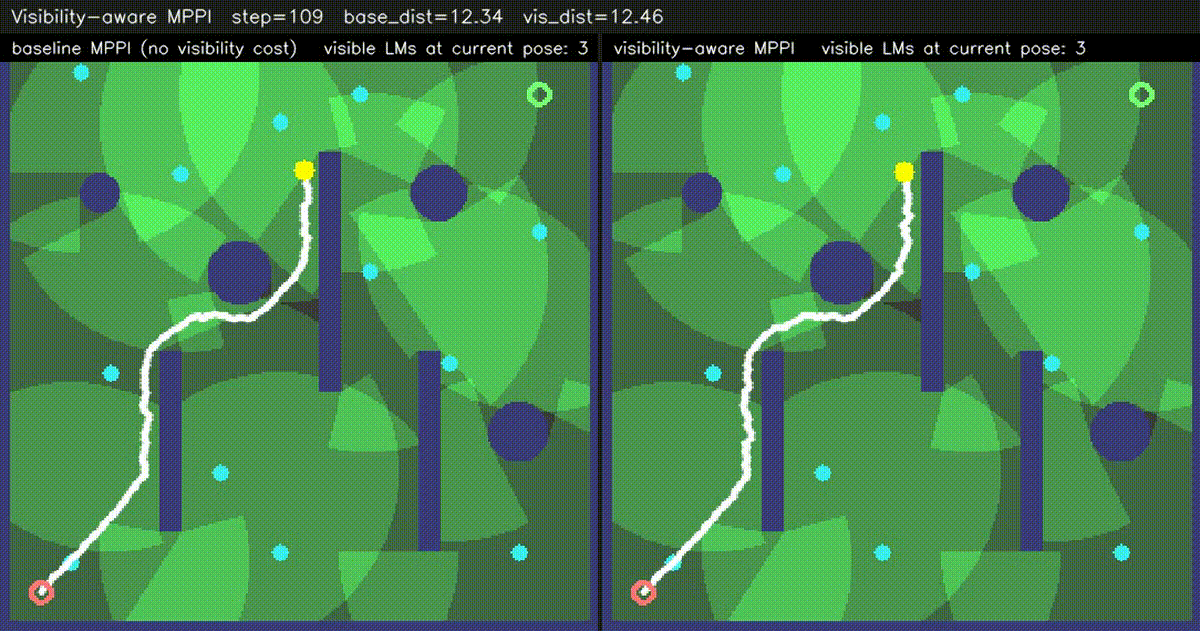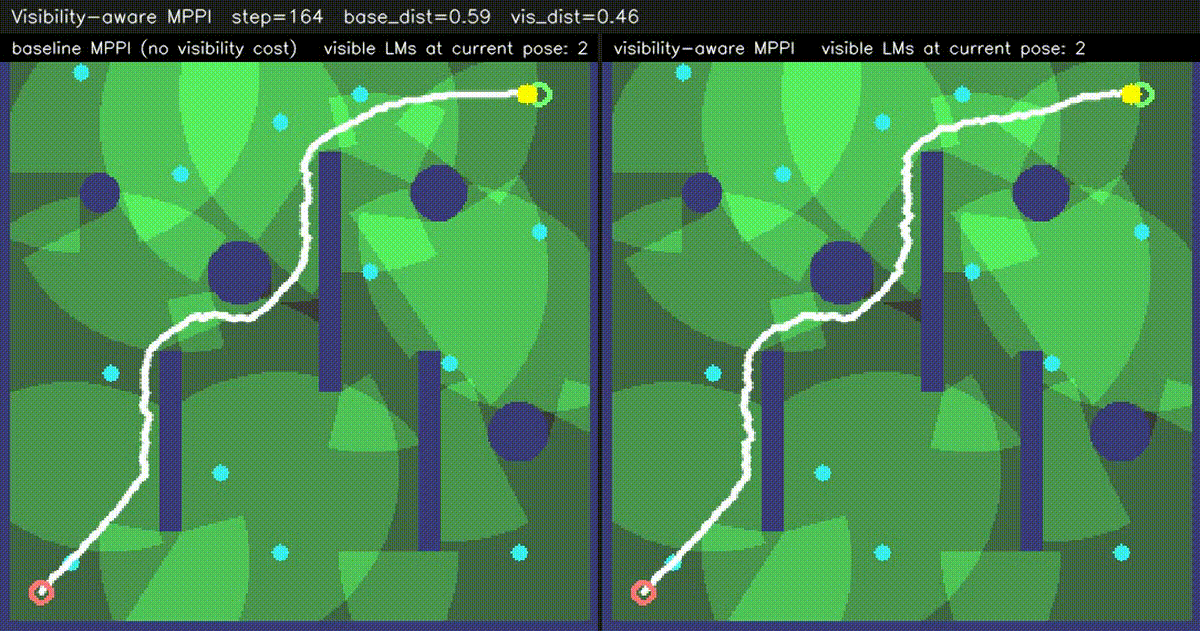
| Visibility-aware MPPI (baseline vs −W·V(x,y) visibility) | ESDF-MPPI (JFA ESDF + bilinear lookup cost) |
 |
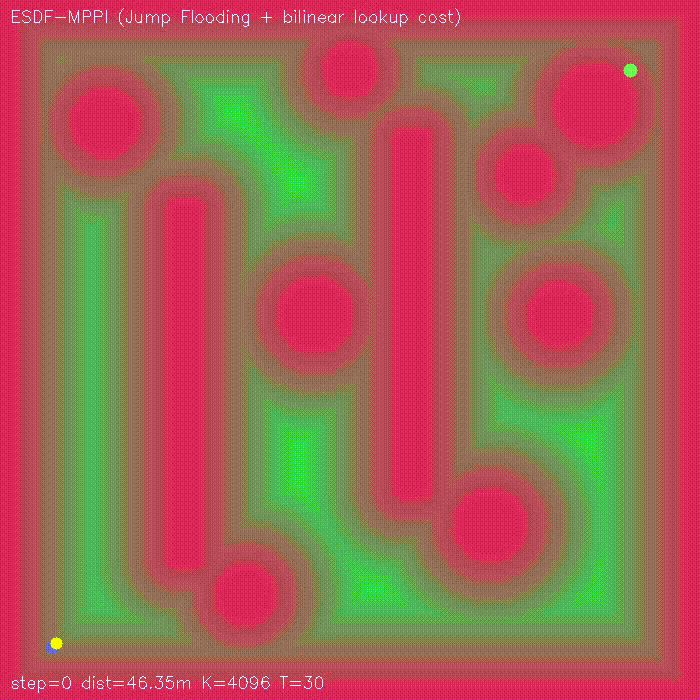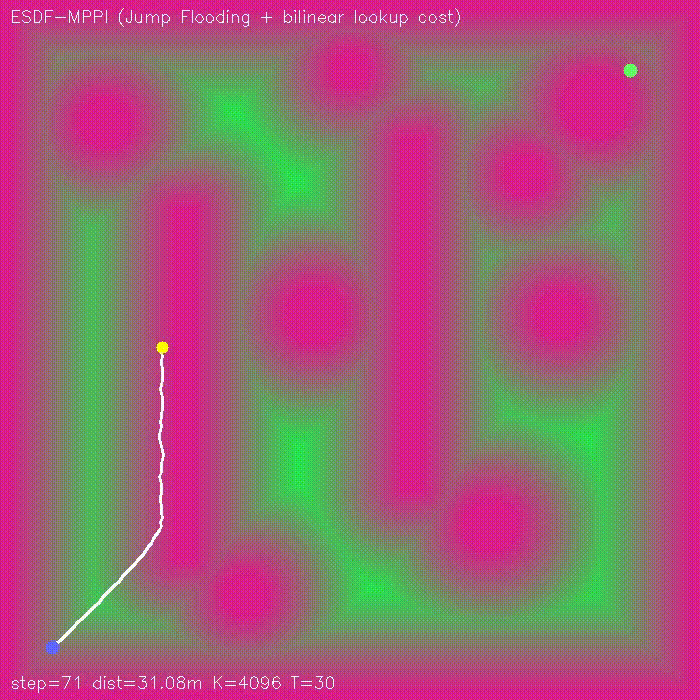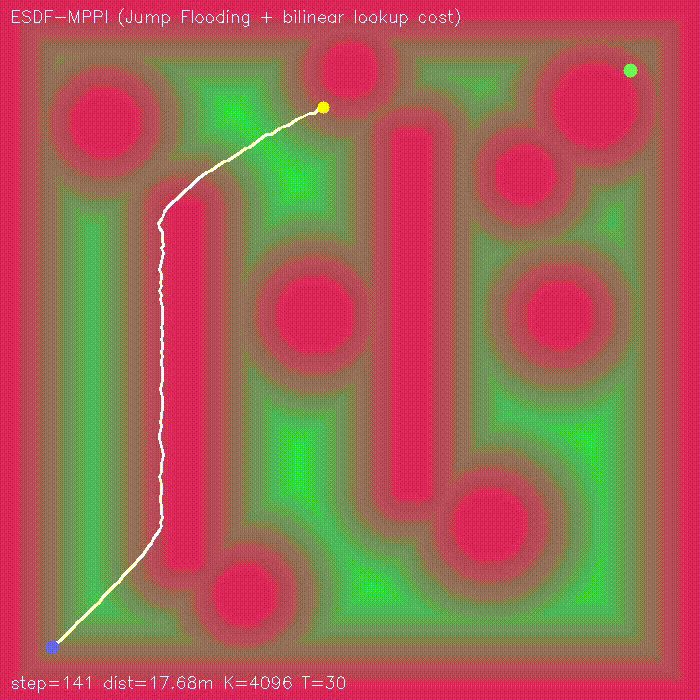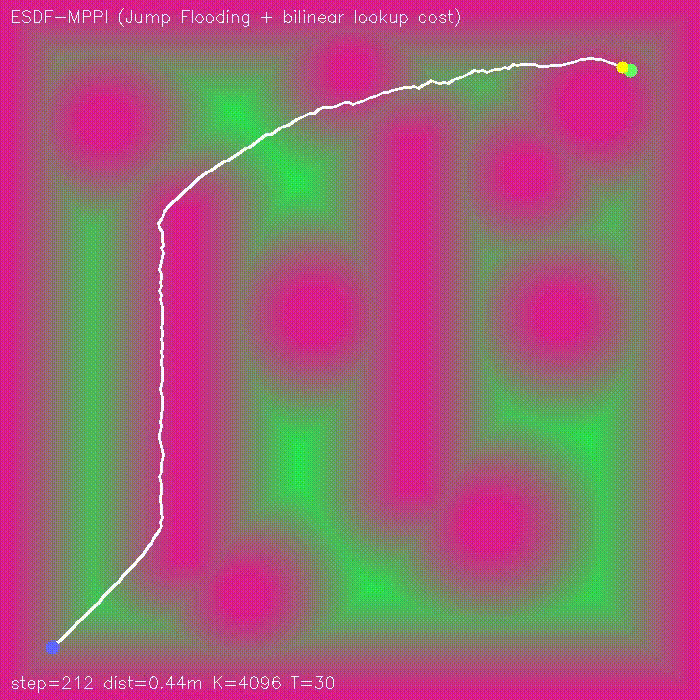 |
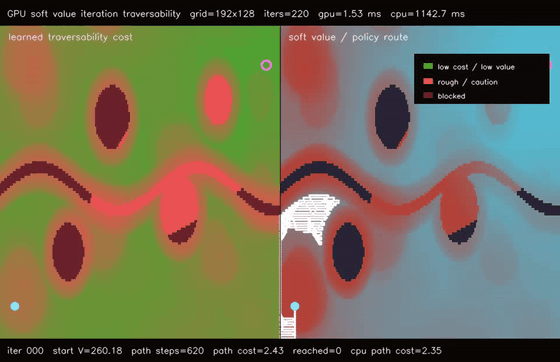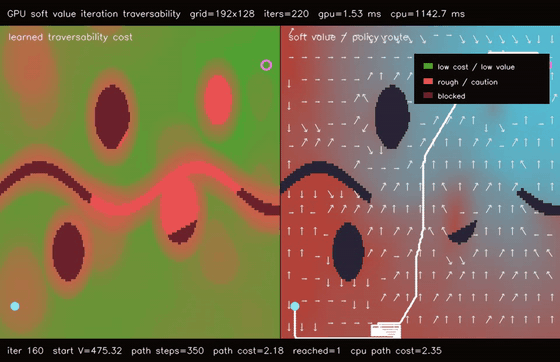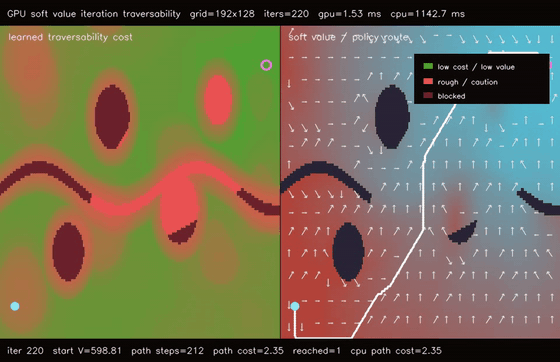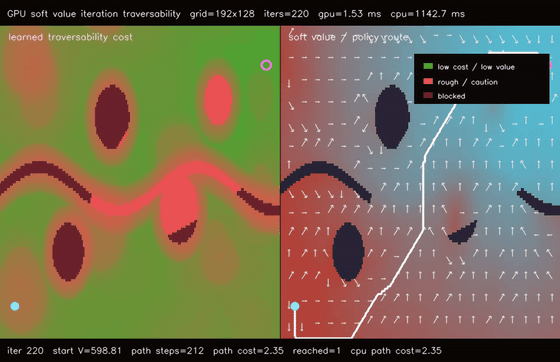
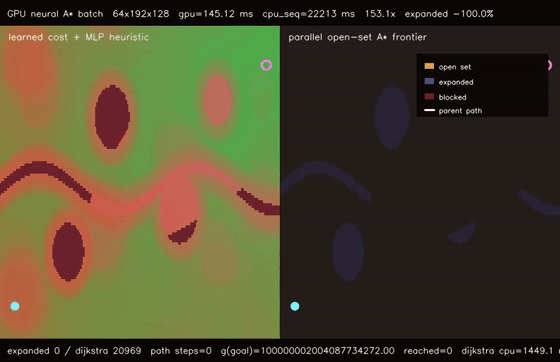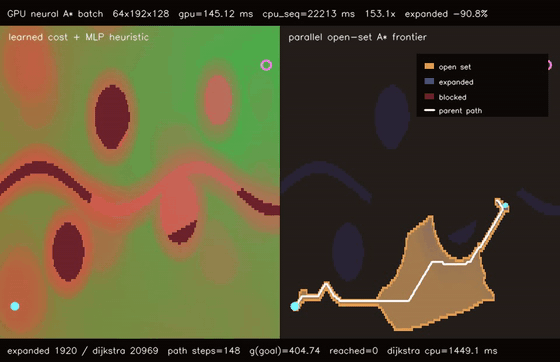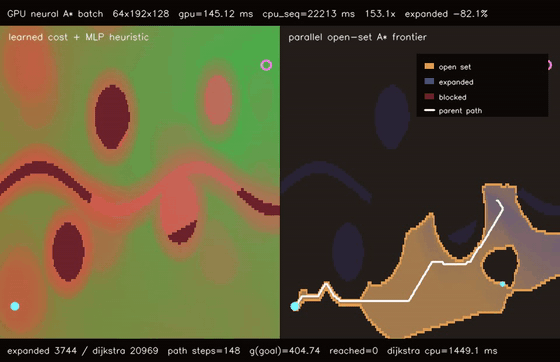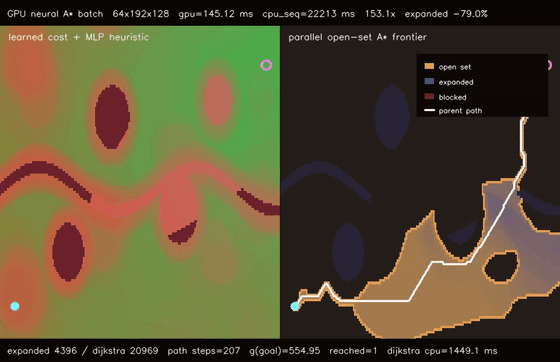
| GPU differentiable value iteration traversability (192x128 learned cost, 220 soft Bellman iters, 747.4x vs CPU) | GPU neural A traversability (64 × 192x128 queries, 79.0% fewer expansions, 153.1x vs CPU)* |
 |
 |
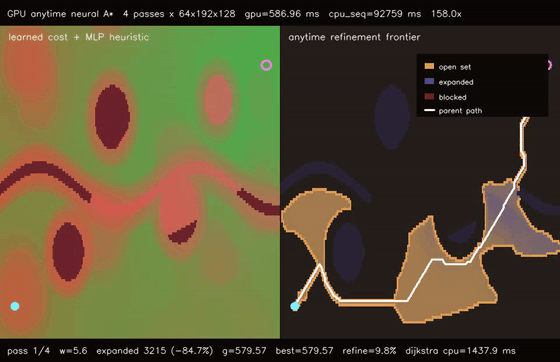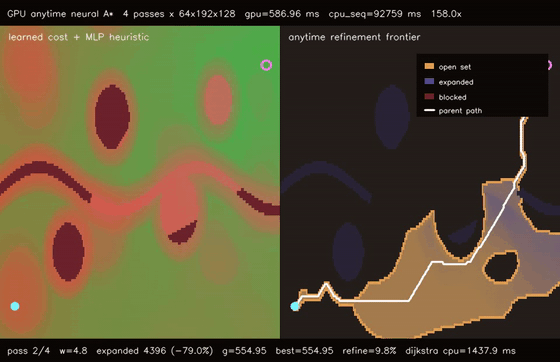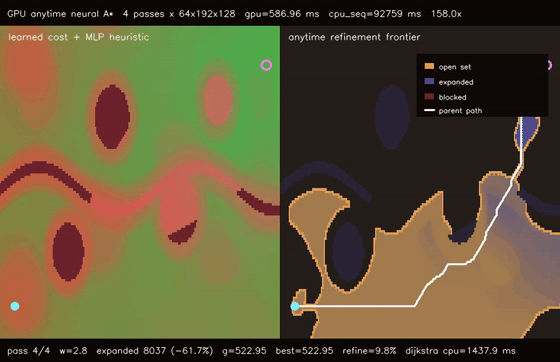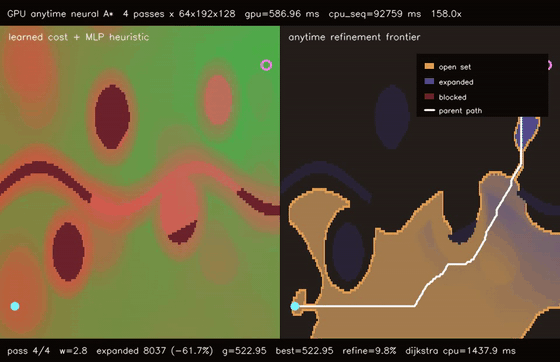
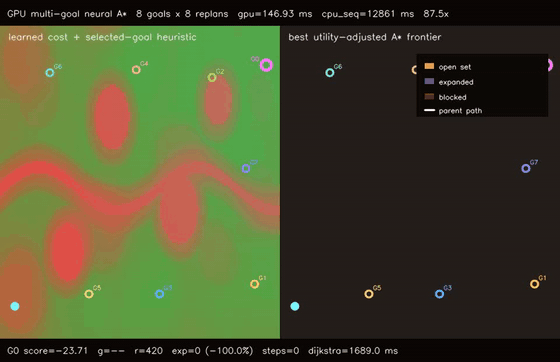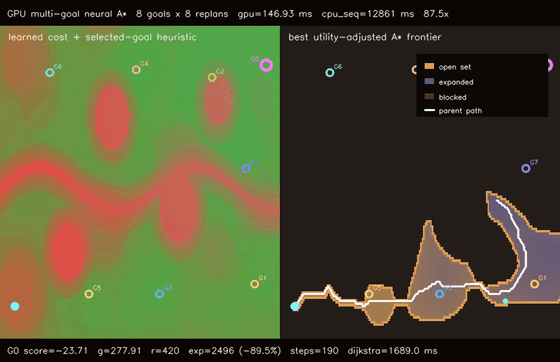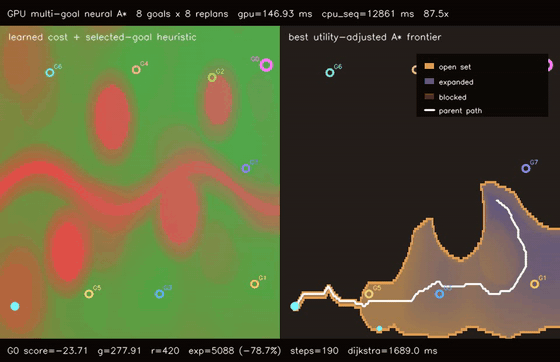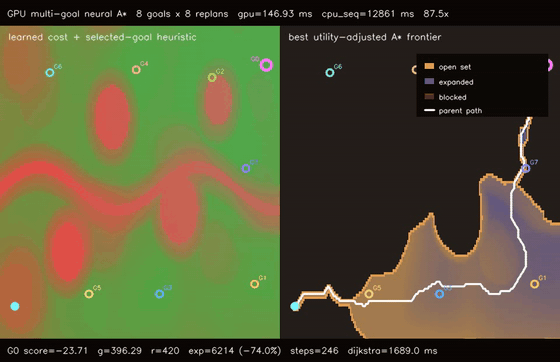
| GPU anytime neural A traversability (4-pass heuristic annealing, 9.8% path-cost refinement, 158.0x vs CPU)* | GPU multi-goal neural A traversability (8 candidate goals × 8 replans, utility-selected G0, 87.5x vs CPU)* |
 |
 |
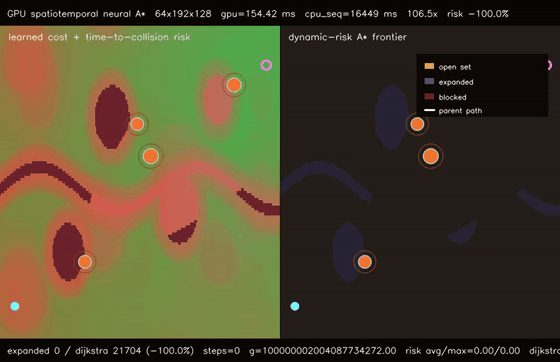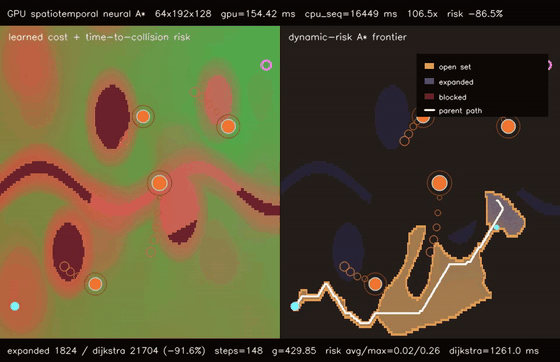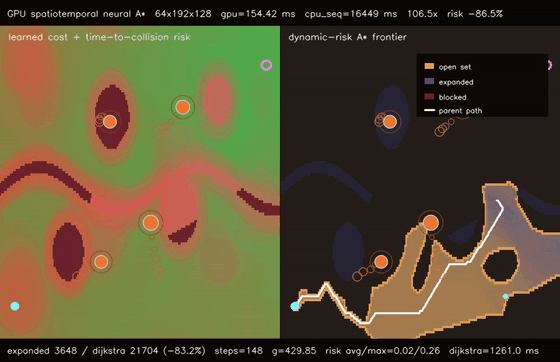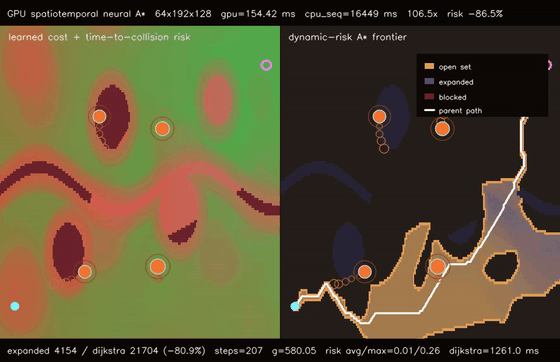
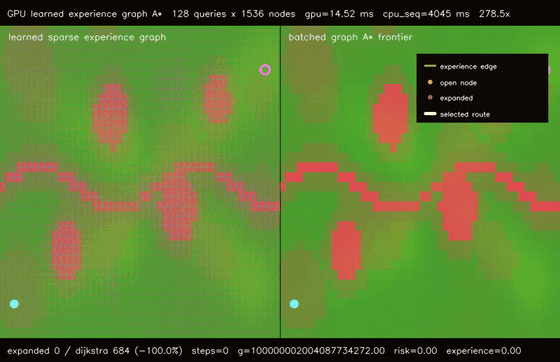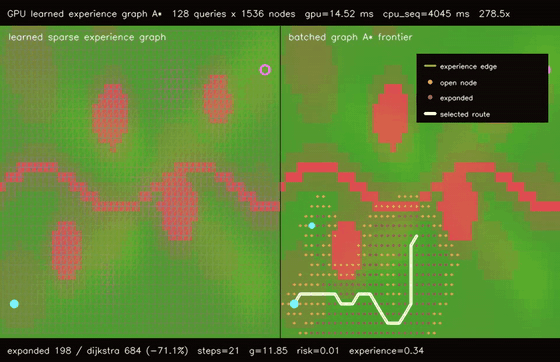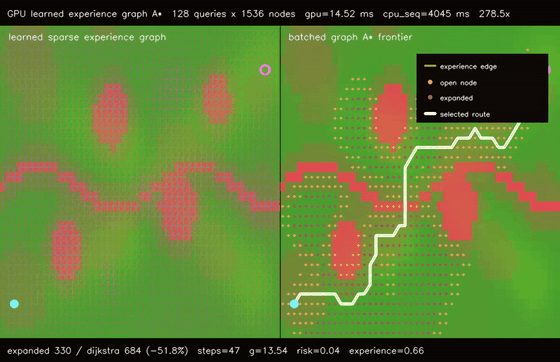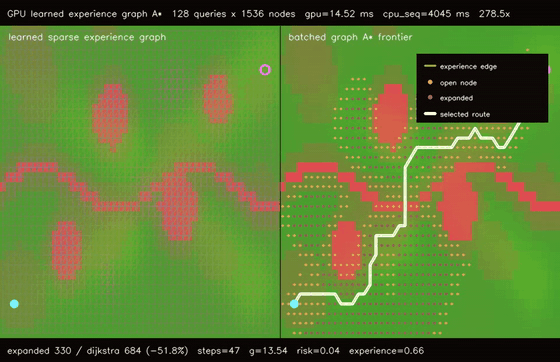
| GPU spatiotemporal neural A traversability (moving obstacle risk, max risk 1.94 -> 0.26, 106.5x vs CPU)* | GPU learned experience graph planner (128 × 1536-node graph A, 51.8% fewer expansions, 278.5x vs CPU)* |
 |
 |
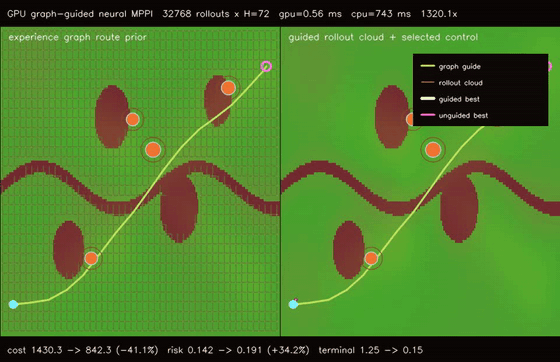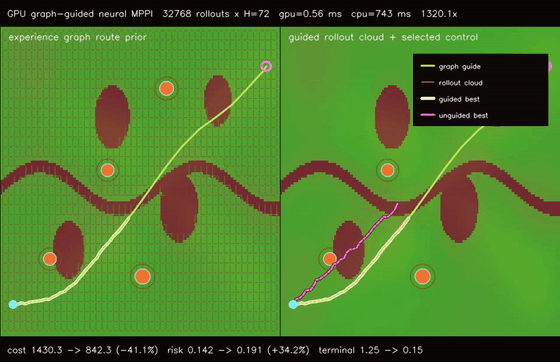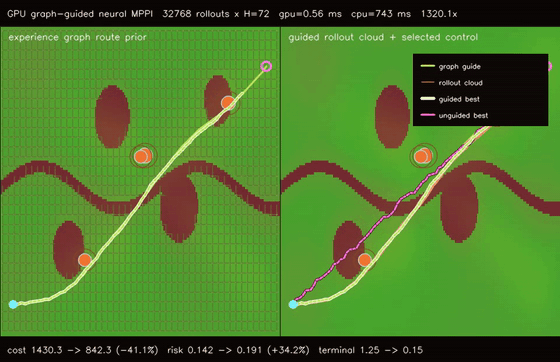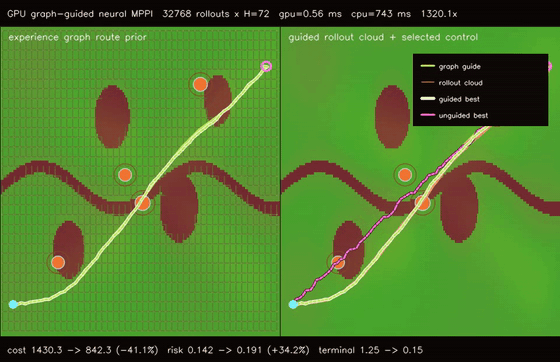
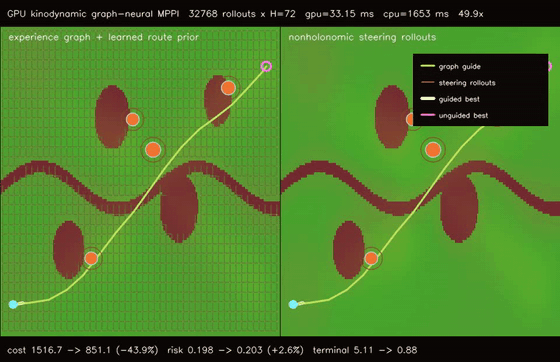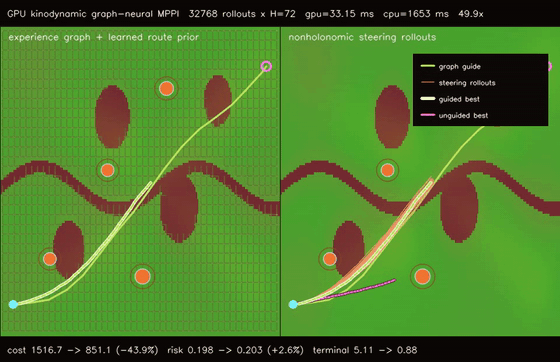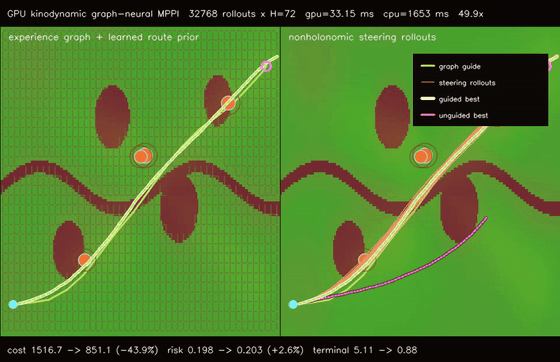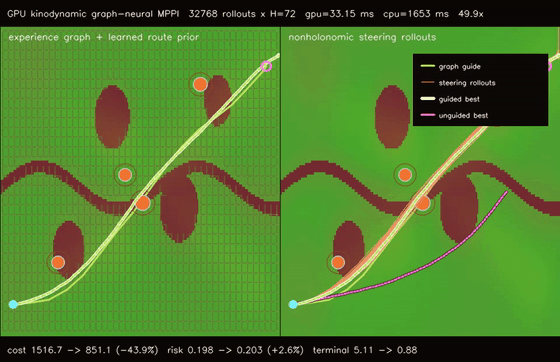
| GPU graph-guided neural MPPI (32768 rollouts × H=72, cost 1430.31 -> 842.35, terminal 1.25 -> 0.15, 1320.1x vs CPU) | GPU kinodynamic graph-neural MPPI (32768 nonholonomic rollouts × H=72, cost 1516.74 -> 851.11, terminal 5.11 -> 0.88, 49.9x vs CPU) |
 |
 |
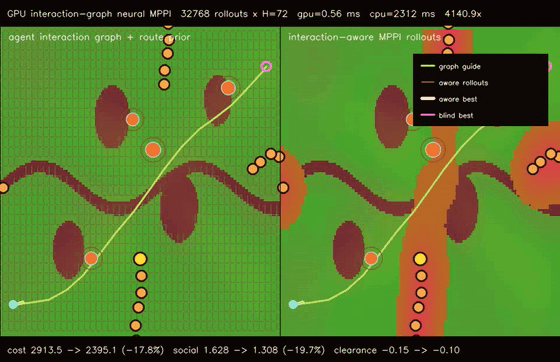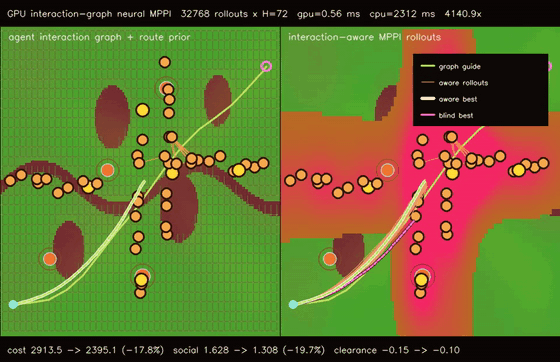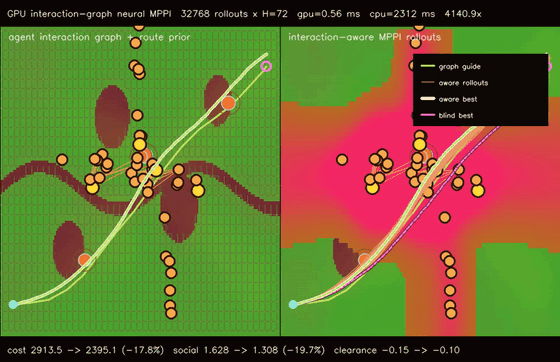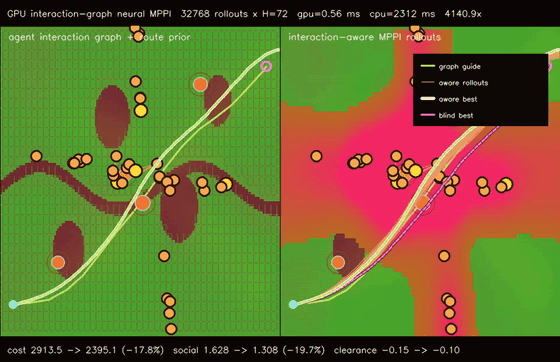
| GPU interaction-graph neural MPPI (48-agent message-passing social risk + 32768 rollouts, social risk 1.628 -> 1.308, 4140.9x vs CPU) | GPU multi-agent graph-neural MPPI (48 robots × 768 rollouts × H=72, cross-route collisions 518 -> 261, social risk 3.544 -> 2.588, 3139.6x vs CPU) |
 |
 |
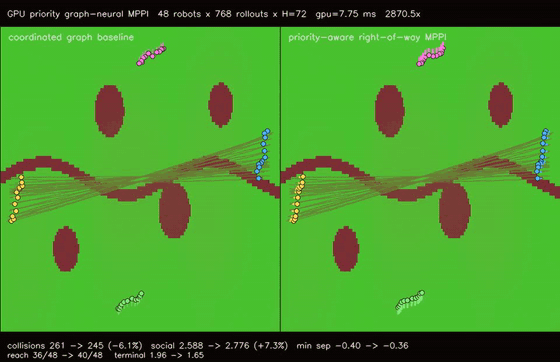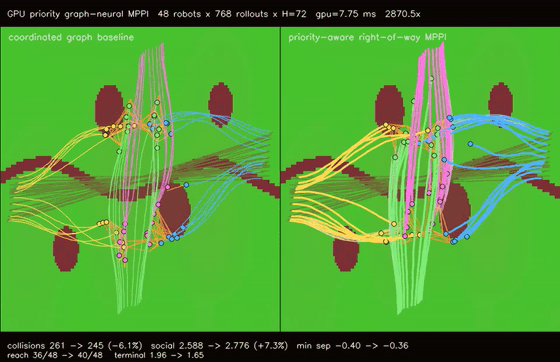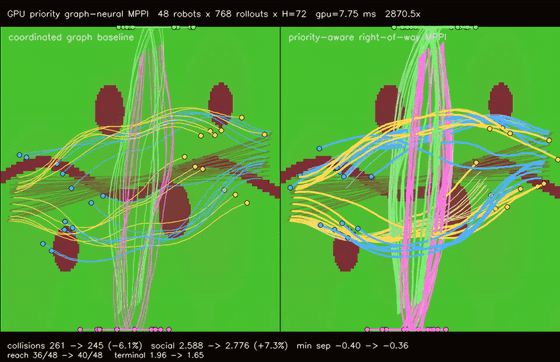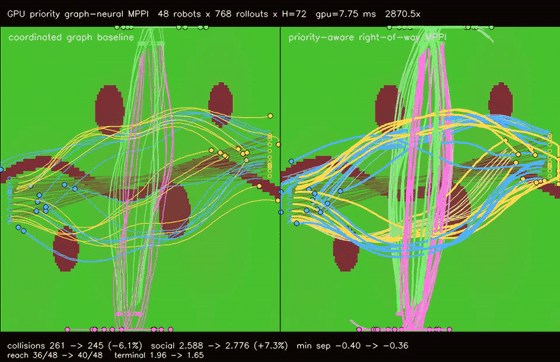
| GPU priority graph-neural MPPI (right-of-way arbitration, collisions 261 -> 245, reach 36/48 -> 40/48, 2870.5x vs CPU) | GPU Multi-Robot Planner (200 robots, parallel BF distance fields) |
 |
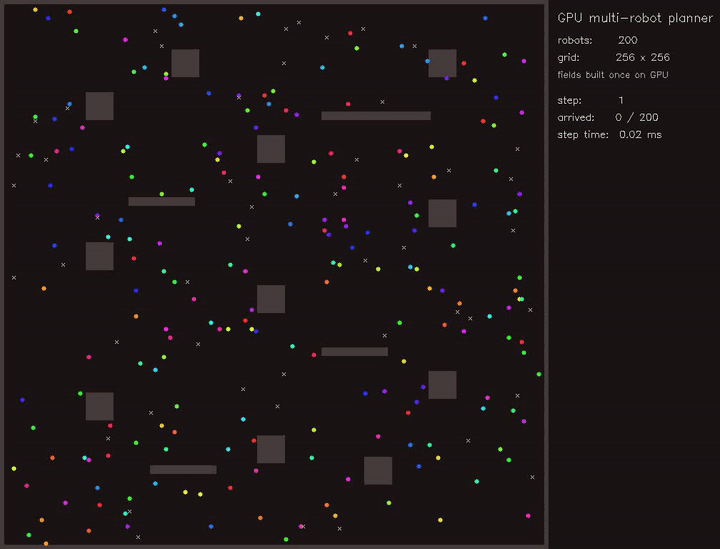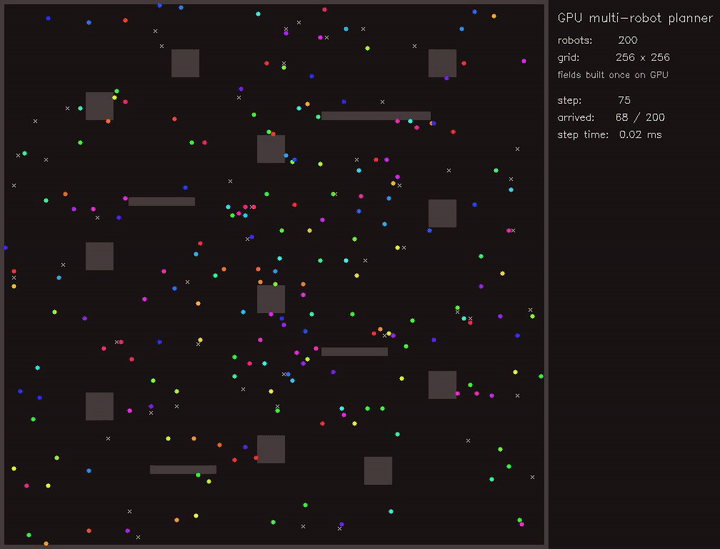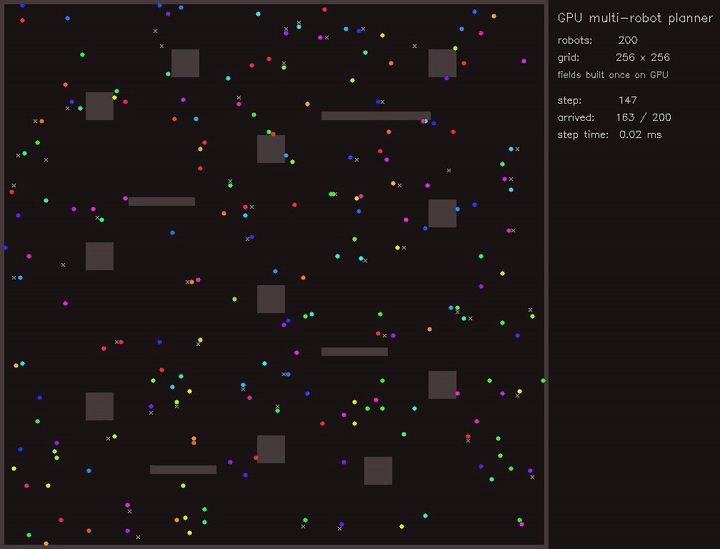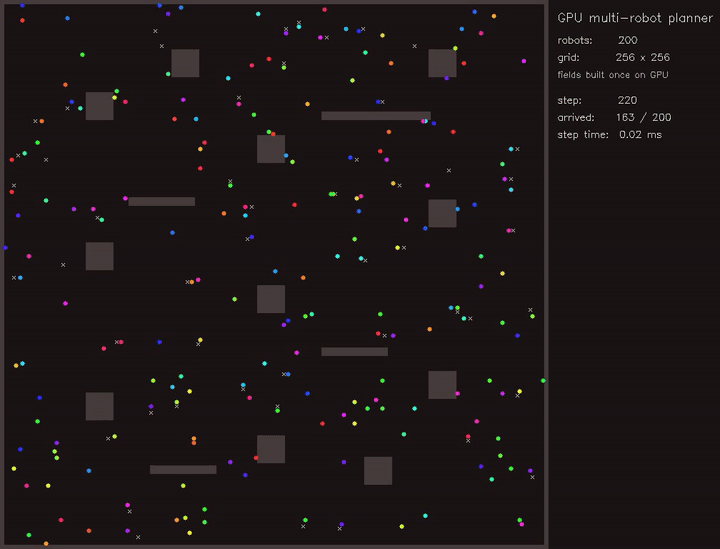 |
| GPU intent graph-neural MPPI (100% top-1 intent belief, collisions 518 -> 216, social risk 3.519 -> 2.897, 292.9x vs CPU) | Massive Collision Check (1M segments, 1,277x) |
 |
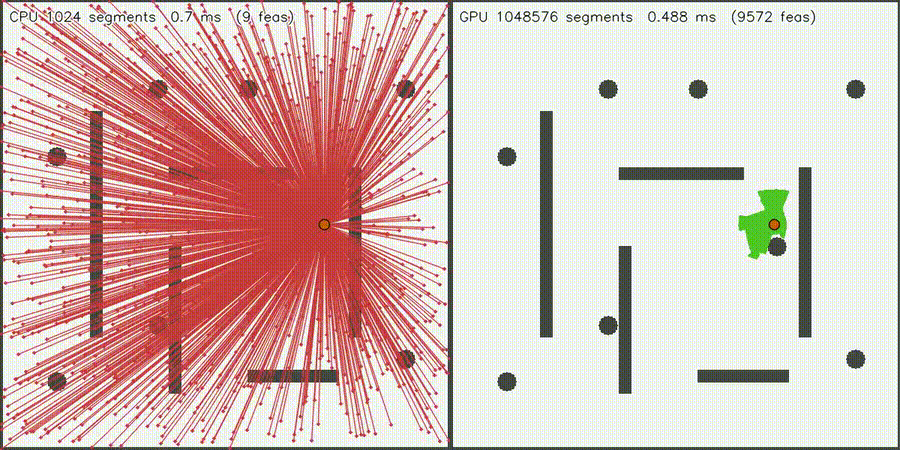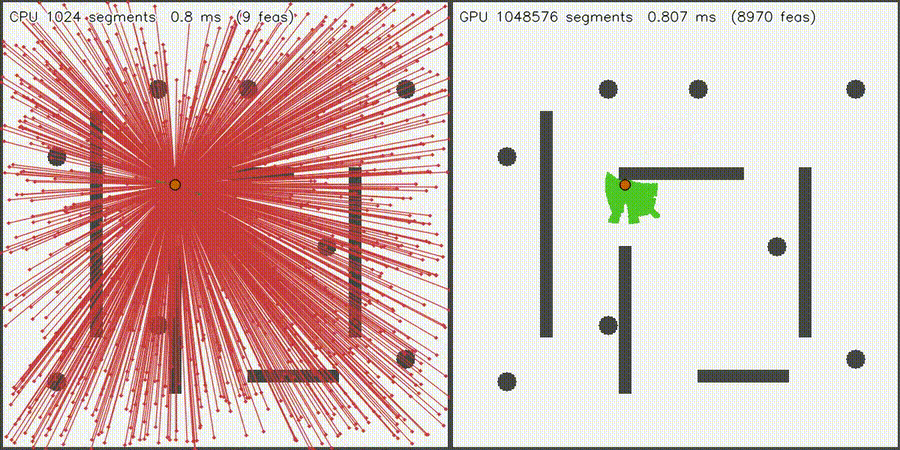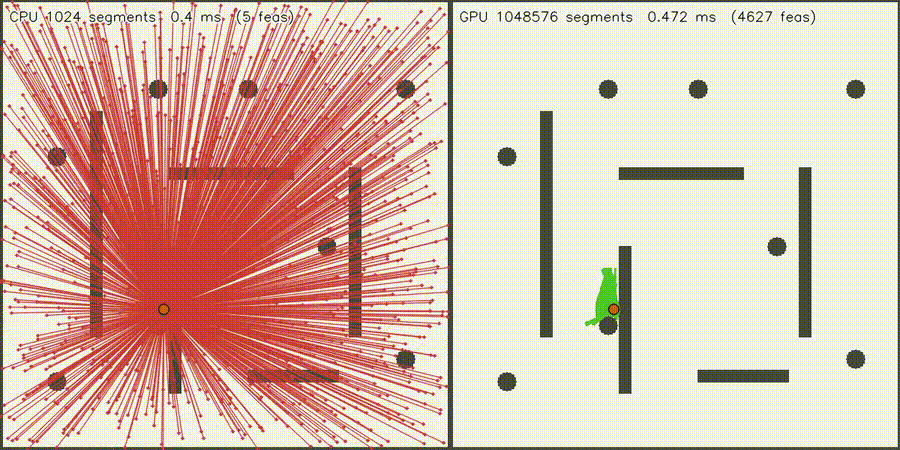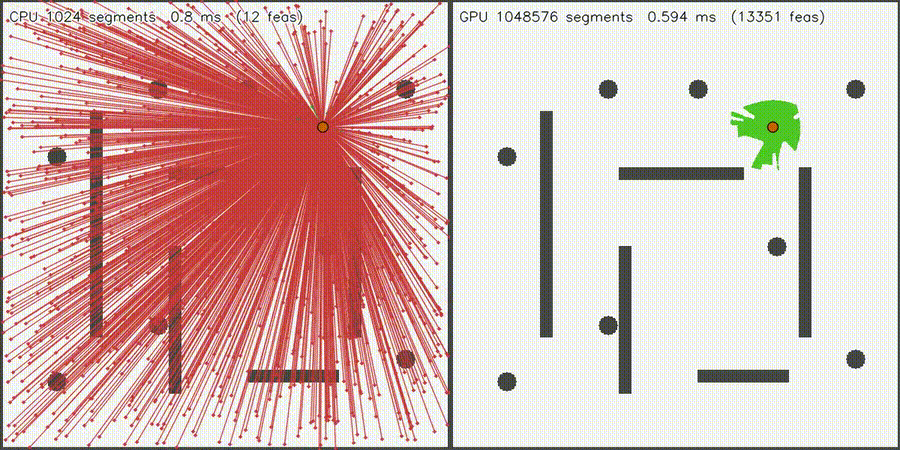 |
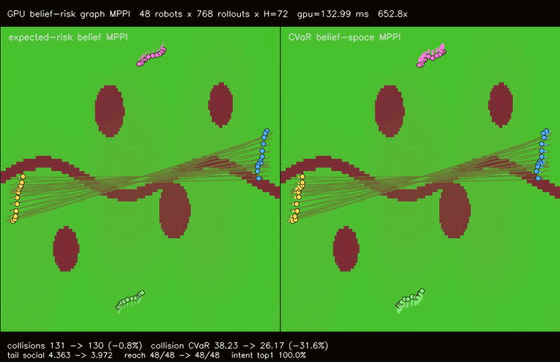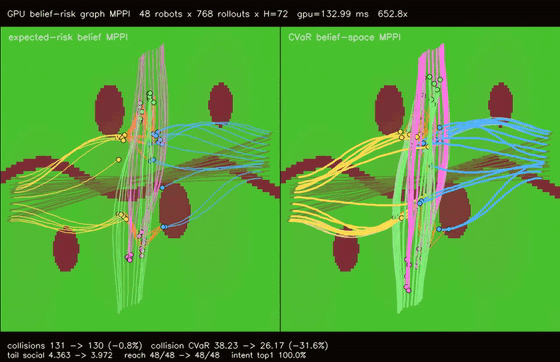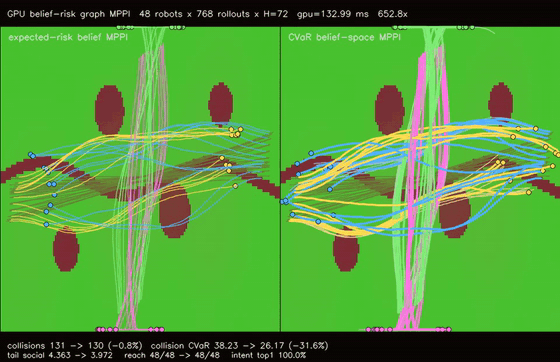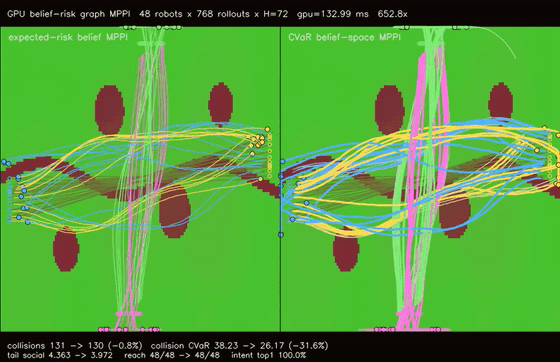
| GPU belief-risk graph MPPI (intent-belief CVaR, collision tail risk 38.23 -> 26.17, tail social risk 4.363 -> 3.972, 652.8x vs CPU) | |
 |
|
| GPU best-response graph MPPI (trajectory-game response, collisions 518 -> 171, collision CVaR 105.43 -> 35.00, unilateral gain 25.69%, 3132.6x vs CPU) | |
 |
|
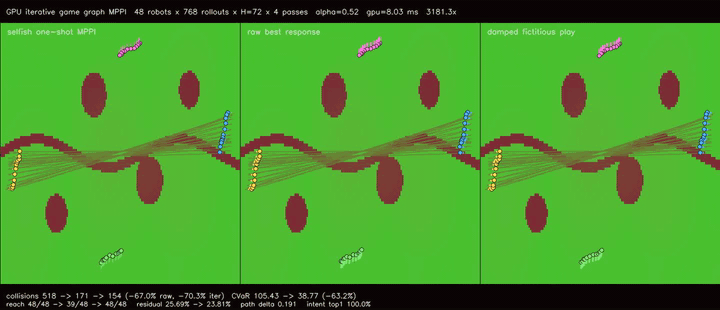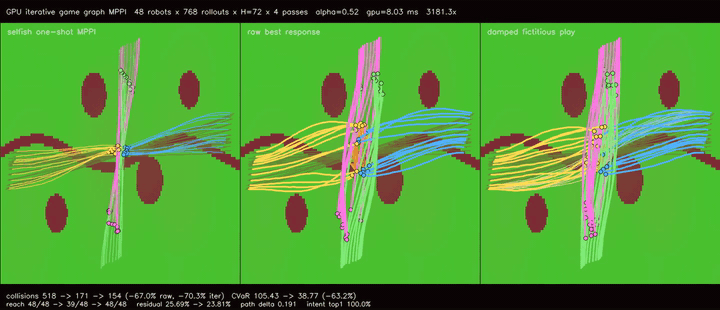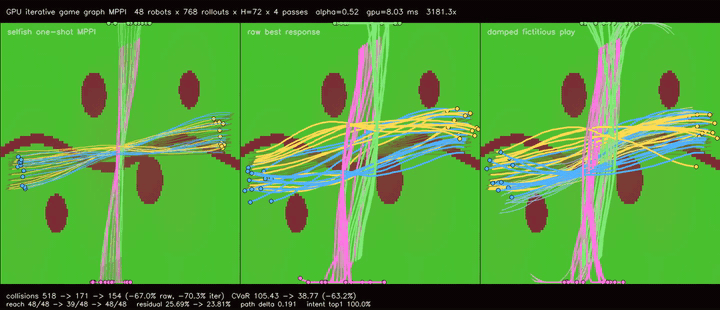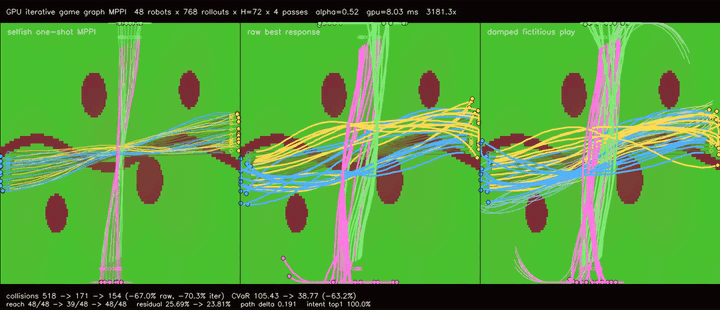
| GPU iterative game graph MPPI (damped fictitious play, collisions 518 -> 154, reach 48/48 -> 39/48 -> 48/48, residual 25.69% -> 23.81%, 3181.3x vs CPU) | |
 |
|
| GPU no-regret game graph MPPI (regret-matched mixing, collisions 518 -> 150, reach 48/48 -> 39/48 -> 48/48, residual 25.69% -> 13.58%, 2960.6x vs CPU) | |
 |
|
| GPU safe no-regret game graph MPPI (CVaR-constrained regret matching, collisions 518 -> 136, collision CVaR 43.34 -> 37.93, reach 48/48, 3043.4x vs CPU) | |
 |
|
| GPU learned safety-dual prior graph MPPI (fixed-weight dual prior, collisions 518 -> 140, collision CVaR 43.34 -> 39.54, residual 16.53%, 3075.5x vs CPU) | |
 |
|
| GPU trainable safety-dual prior graph MPPI (tiny MLP trained on 1152 synthetic graph-risk labels, loss 0.21104 -> 0.00178, collisions 518 -> 132, collision CVaR 43.34 -> 37.10, 3013.1x vs CPU) | |
 |
|
| GPU planner showdown benchmark (ORCA-like / priority / no-regret / trainable safety-dual; scenario-conditioned target pass: 48/48 reach, 0 collisions, CVaR 21.61, residual 4.90%, 13.05 ms) | |
 |
|
| Massive RRT Rewire (CPU 2K vs CUDA 200K nodes)* | 3D ESDF (32³ CPU vs 128²×64 CUDA, 86,613x) |
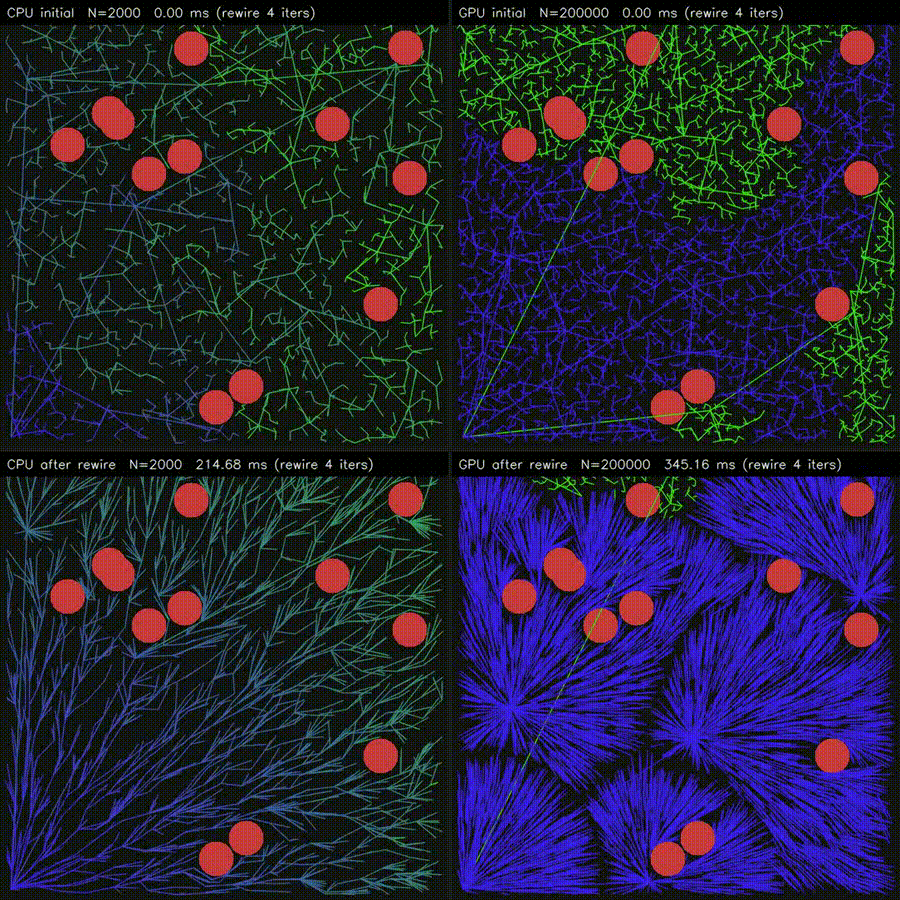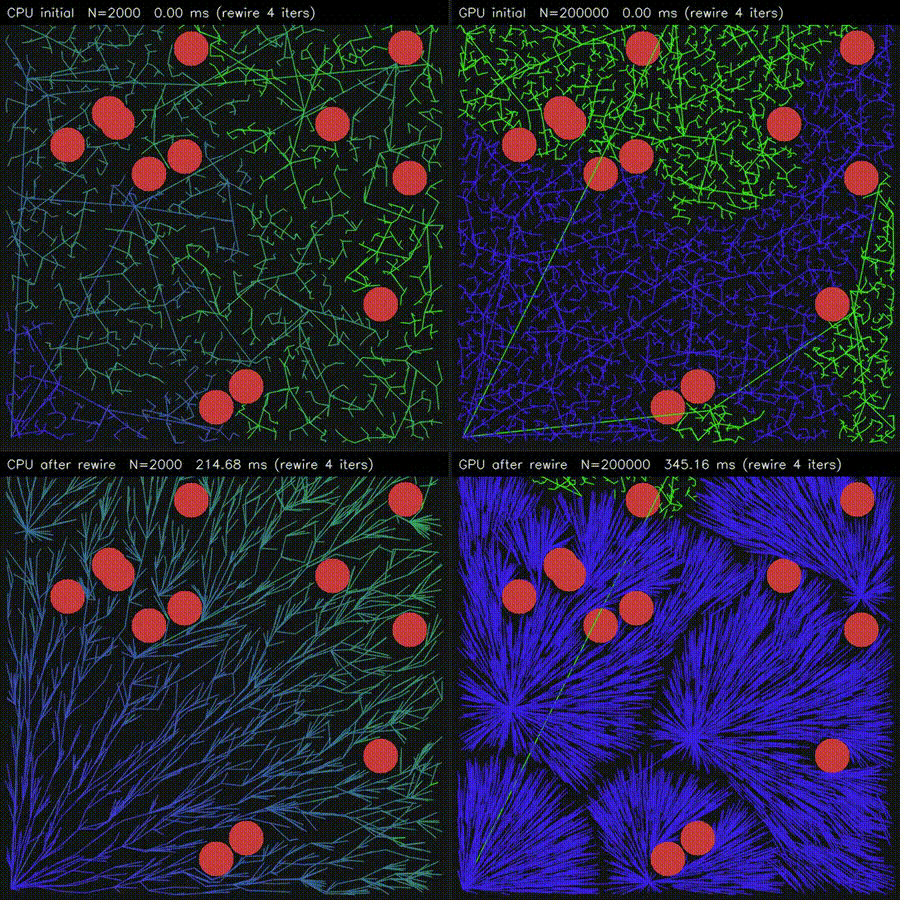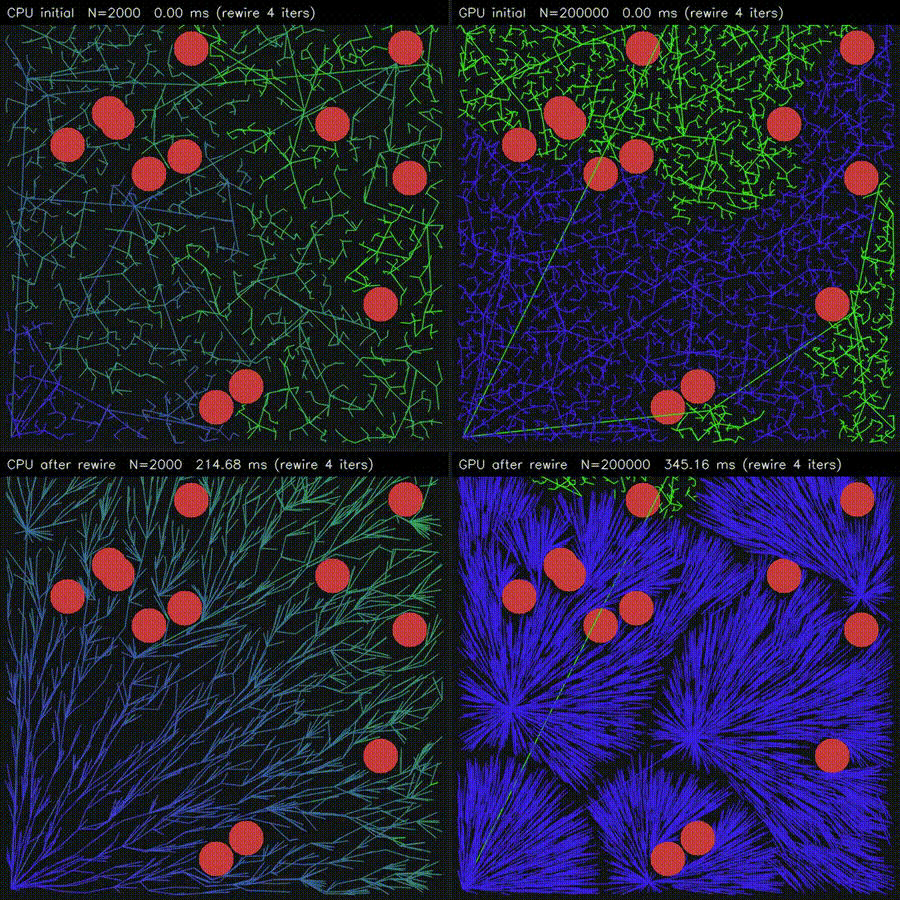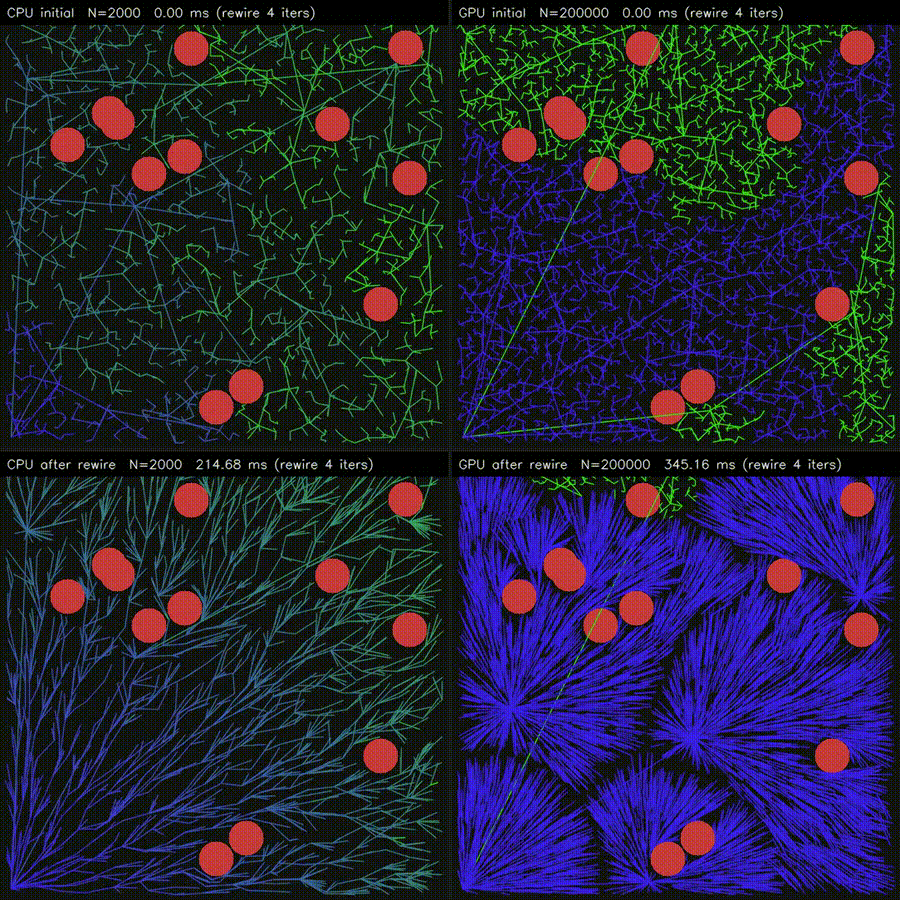 |
 |
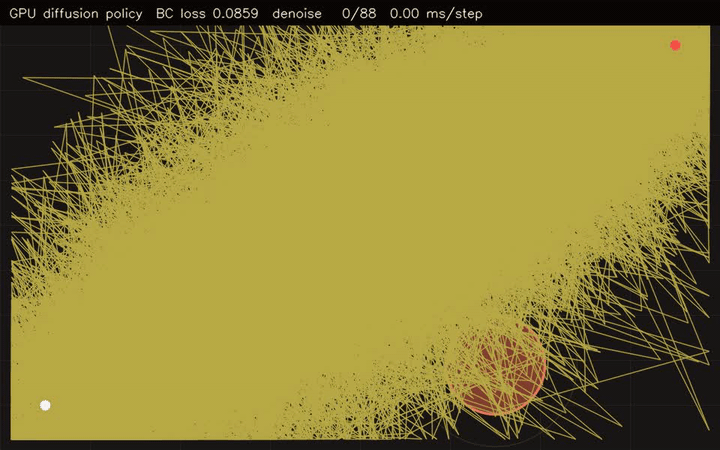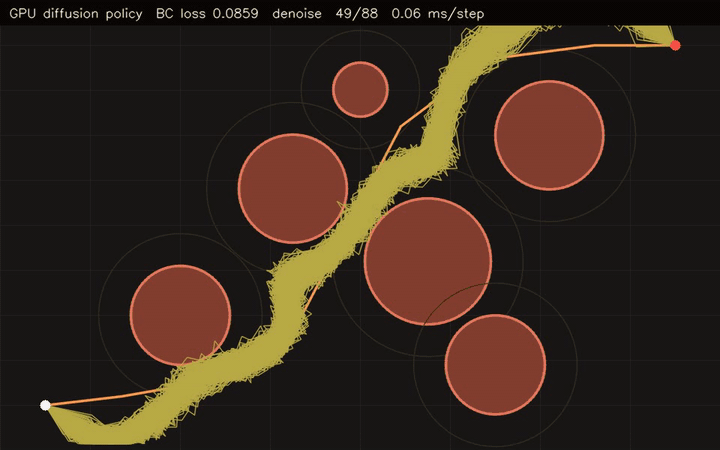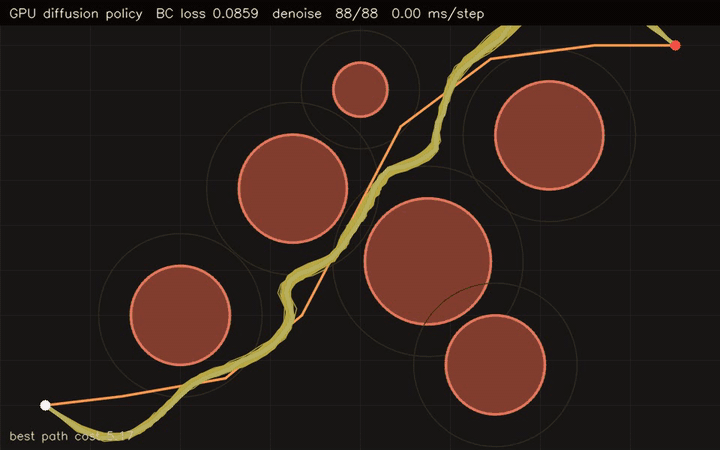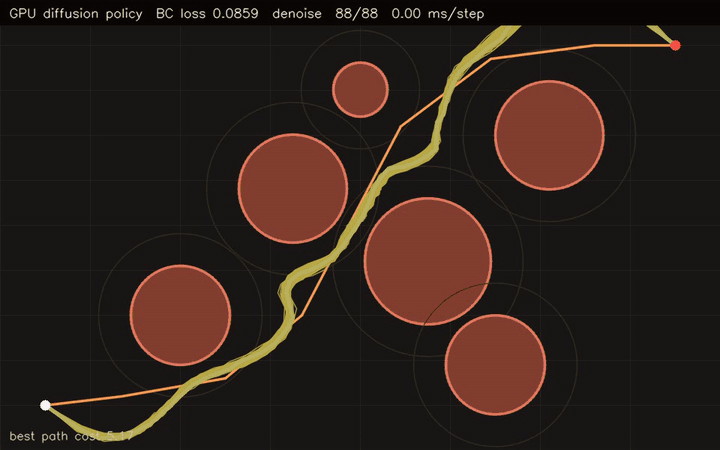
| GPU diffusion policy (768-sample BC MLP prior + diffusion refinement, 512×64 paths) | GPU diffusion planner (512 trajectories × 64 waypoints, 120 Langevin steps, 0.03 ms/step) |
 |
 |
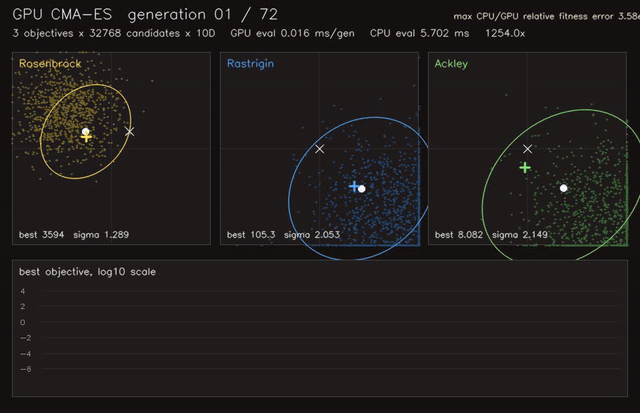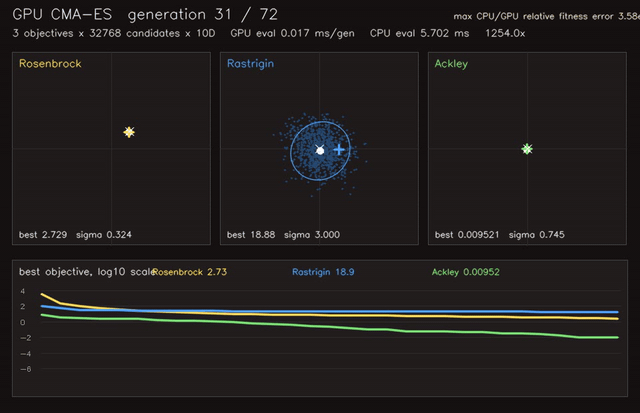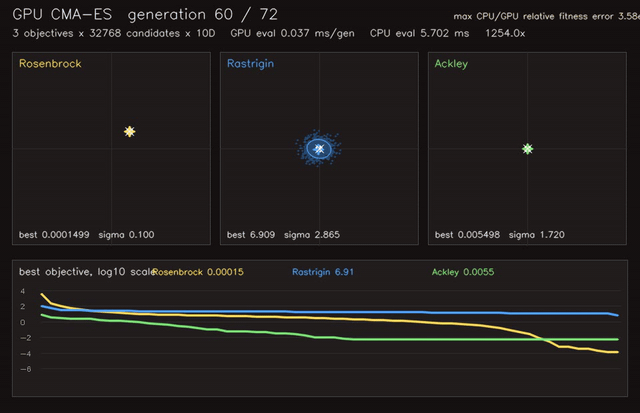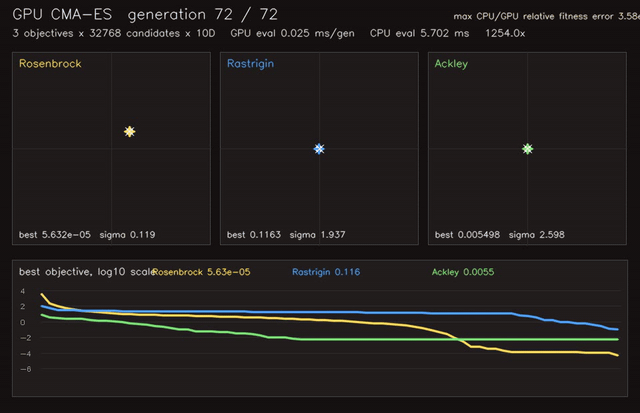
| GPU Hungarian-class assignment (512 × 64x64 dense assignments, 0.082 ms/batch, 158x vs CPU Hungarian) | GPU CMA-ES black-box optimization (3 x 32,768 candidates x 10D, 0.025 ms/generation eval, 1,254x objective eval) |
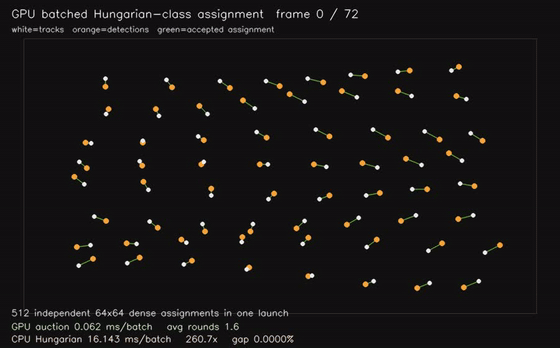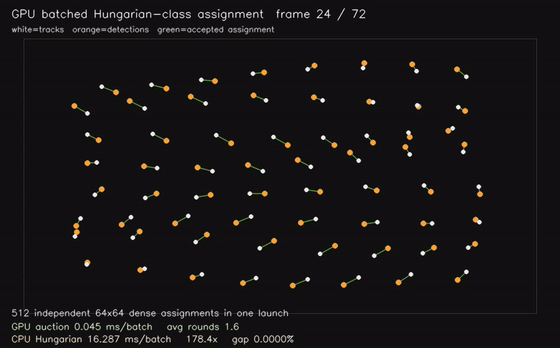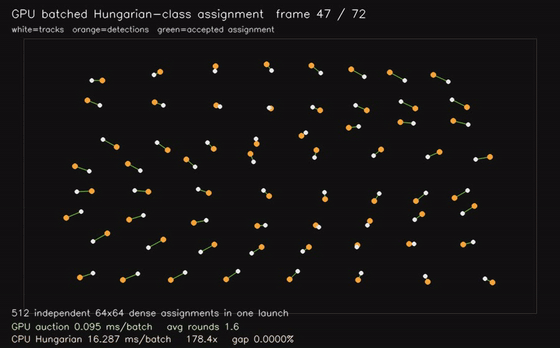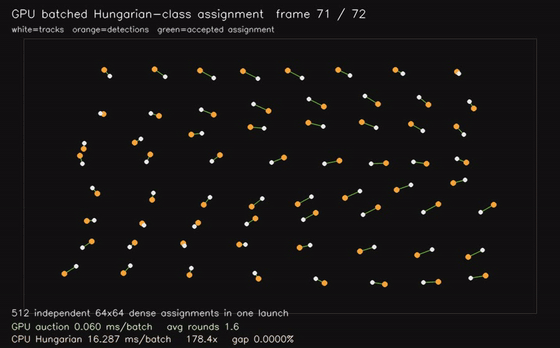 |
 |
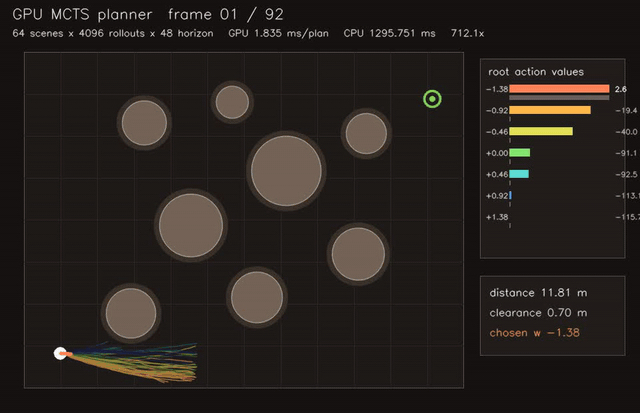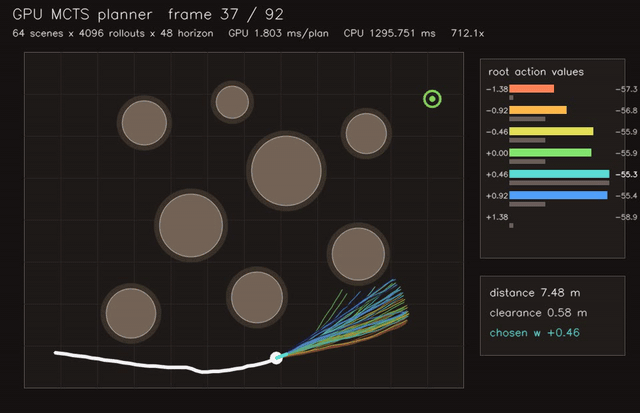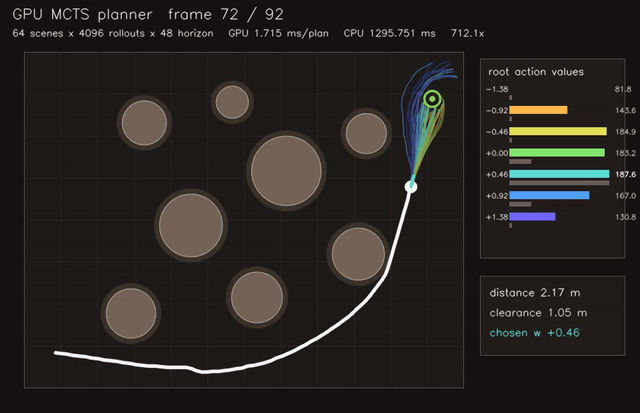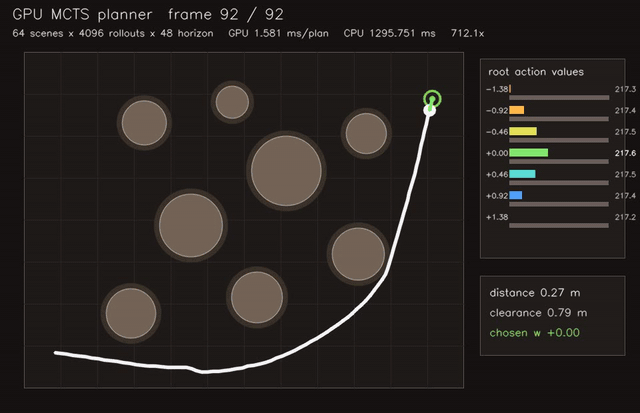
| GPU MCTS planner (64 scenes x 4096 rollouts x 48 horizon, 1.8 ms/plan, 712x vs CPU) | GPU assignment tracking (128 scenes × 48 tracks × 72 detections, gated clutter/miss association, 0.093 ms/update, 14.0x vs CPU) |
 |
|
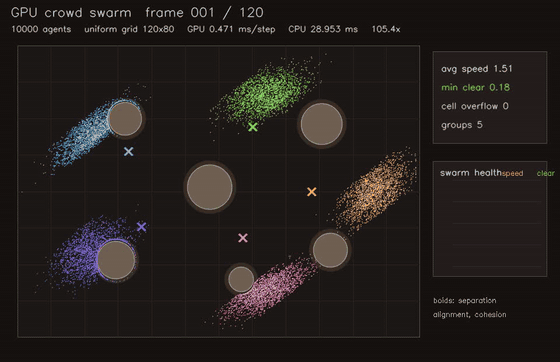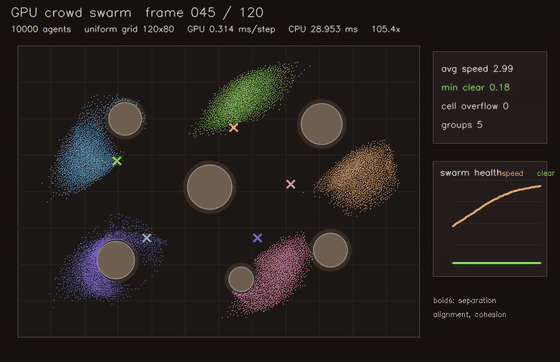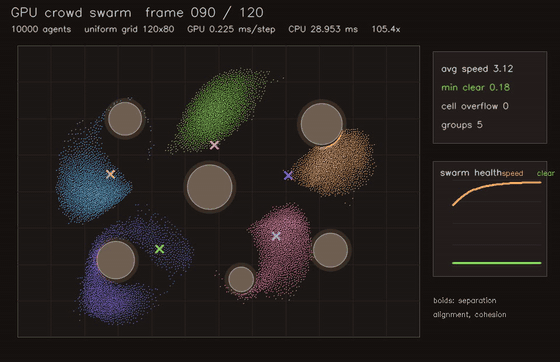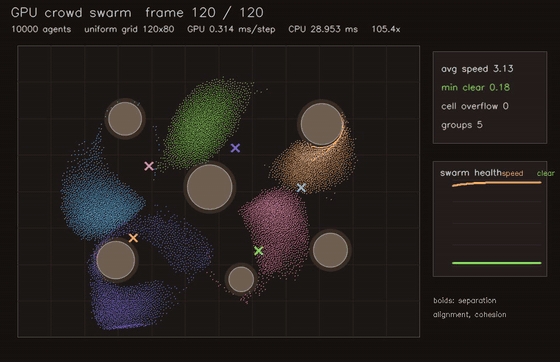
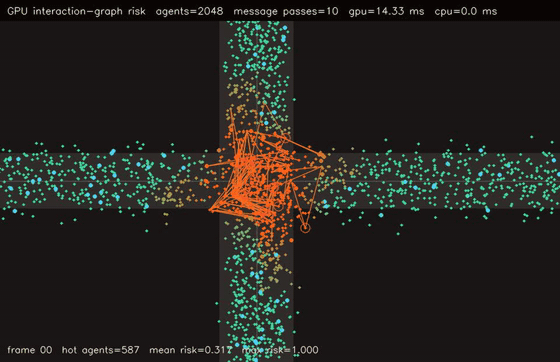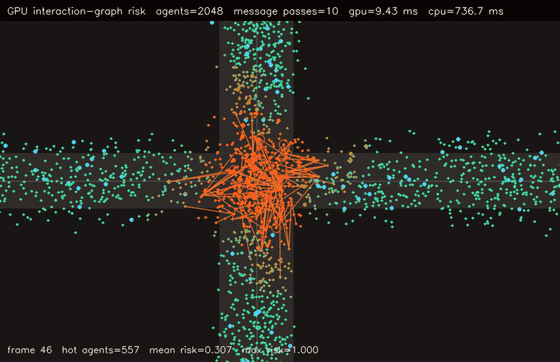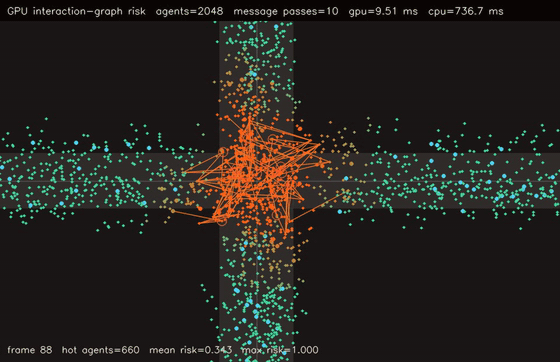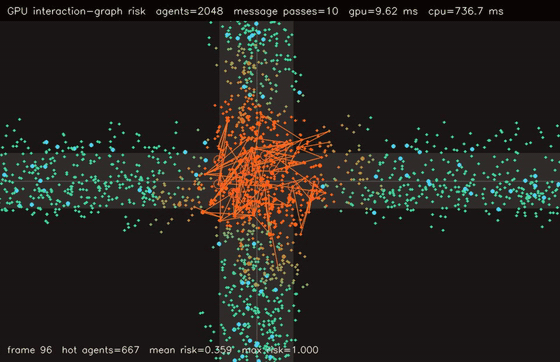
| GPU crowd swarm (10,000 boids, uniform-grid neighbours, 0.275 ms/step, 105x vs CPU) | GPU interaction-graph risk propagation (2048 agents, 10 message passes, 76.3x vs CPU) |
 |
 |
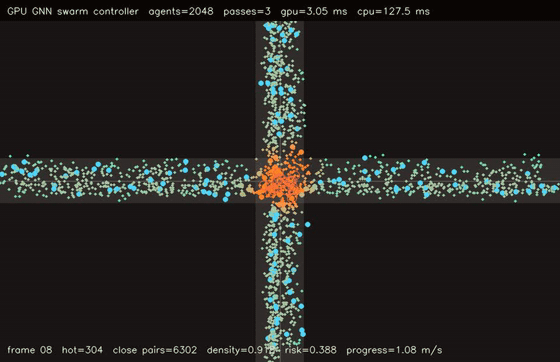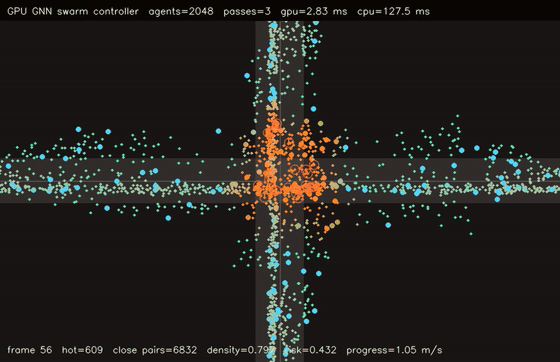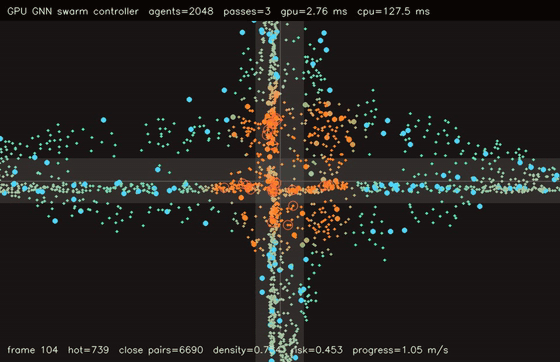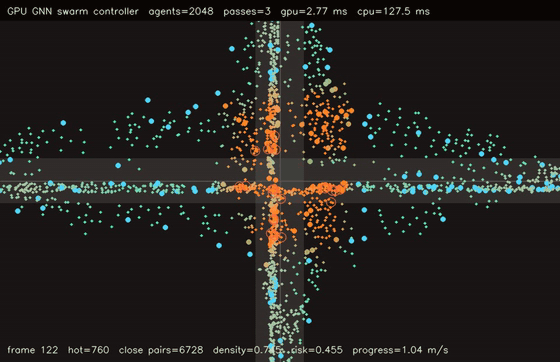
| GPU GNN swarm controller (2048 agents, 3 message passes, 2.88 ms/control, 44.3x vs CPU) | GPU reciprocal risk planner (1024 agents, 9 actions, H=16, 4.05 ms/plan, 311.5x vs CPU) |
 |
 |
| Differentiable MPPI | Differentiable Particle Filter (3 panels) |
 |
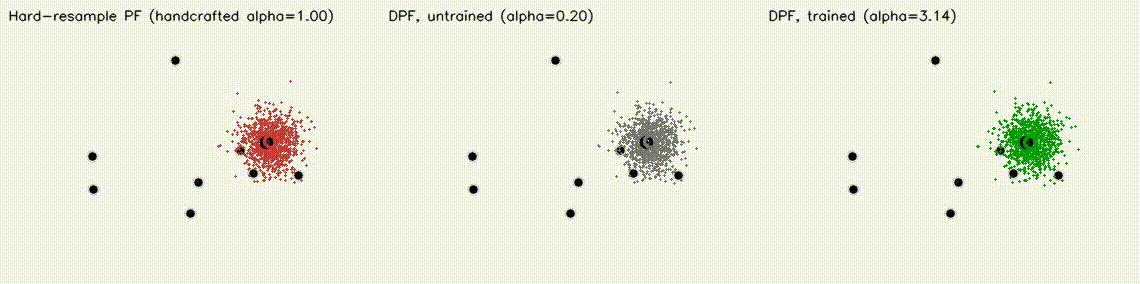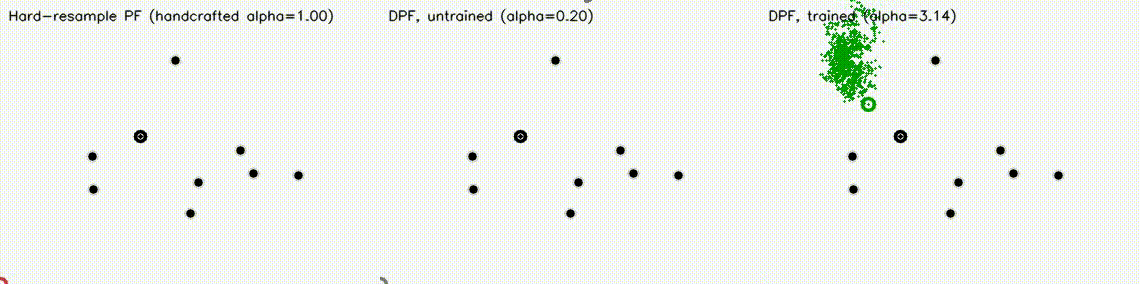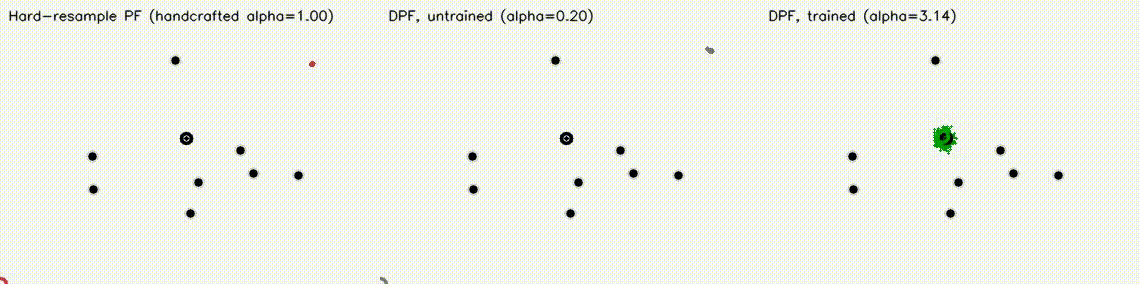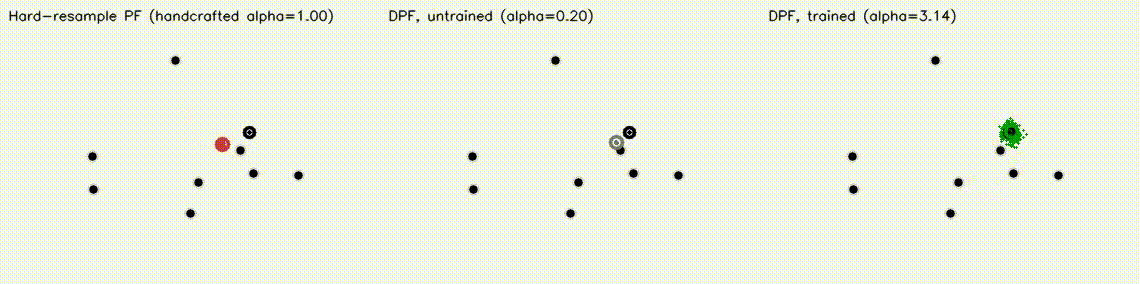 |
| DPF MLP likelihood (3 panels: Gaussian / supervised / tuned) | DPF realistic obs (Gaussian / Cauchy / learned MLP) |
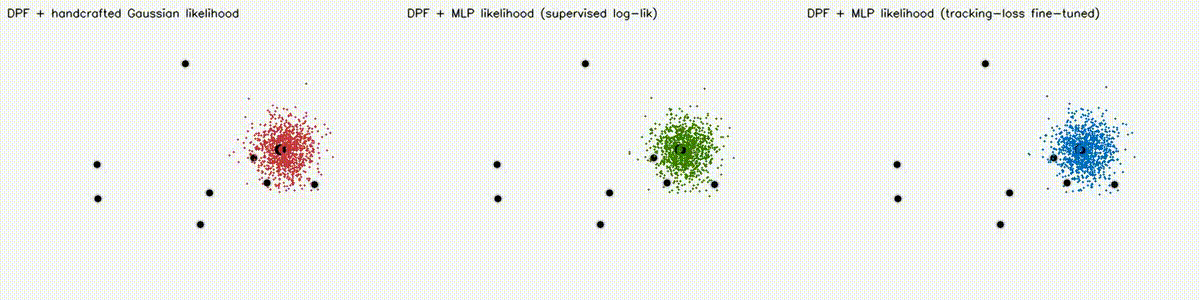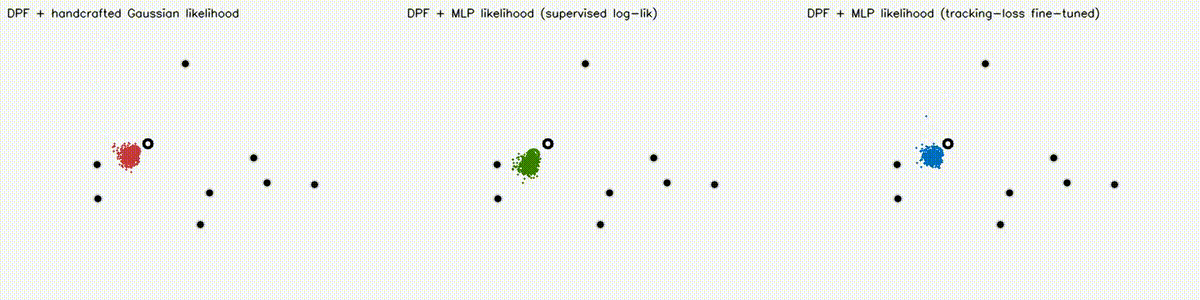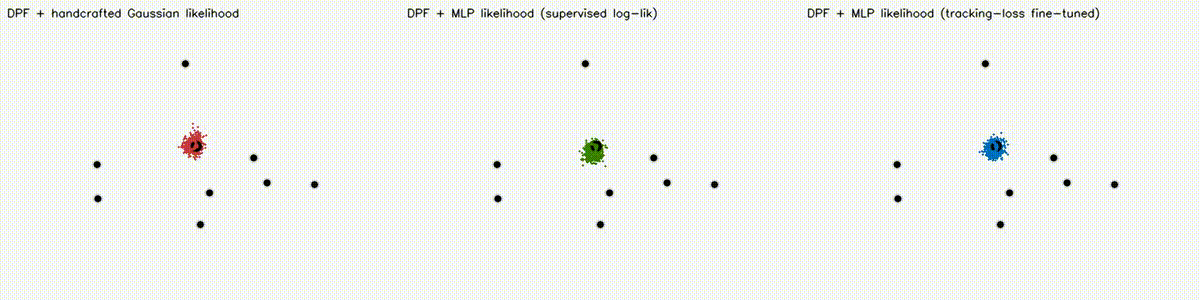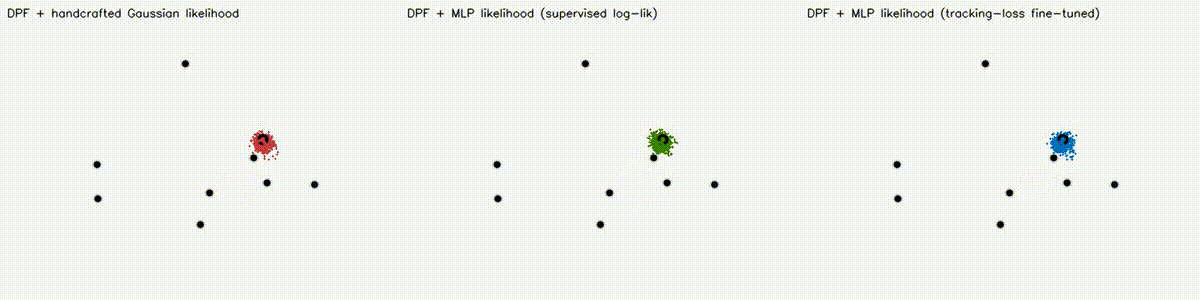 |
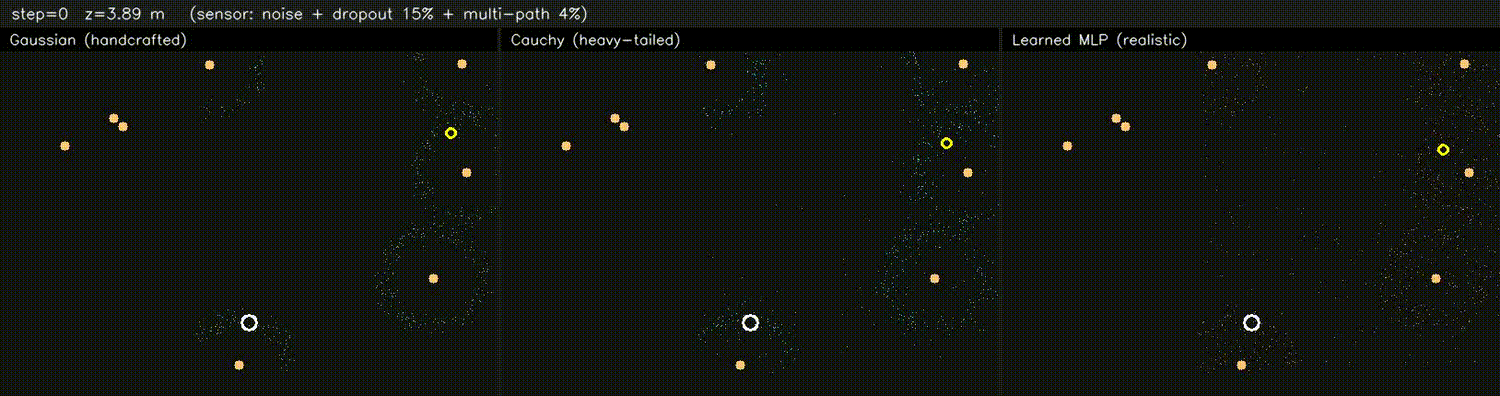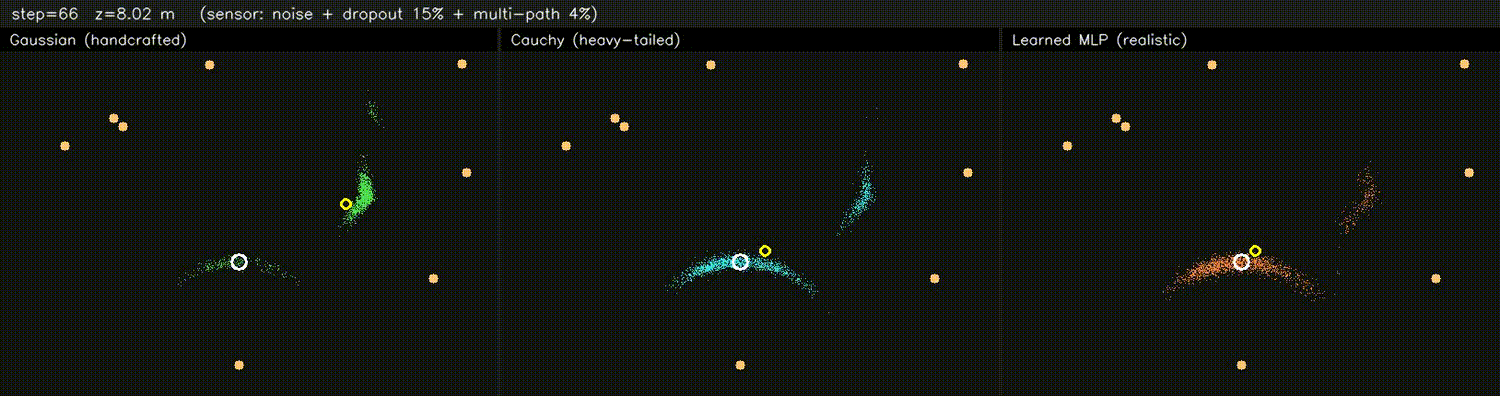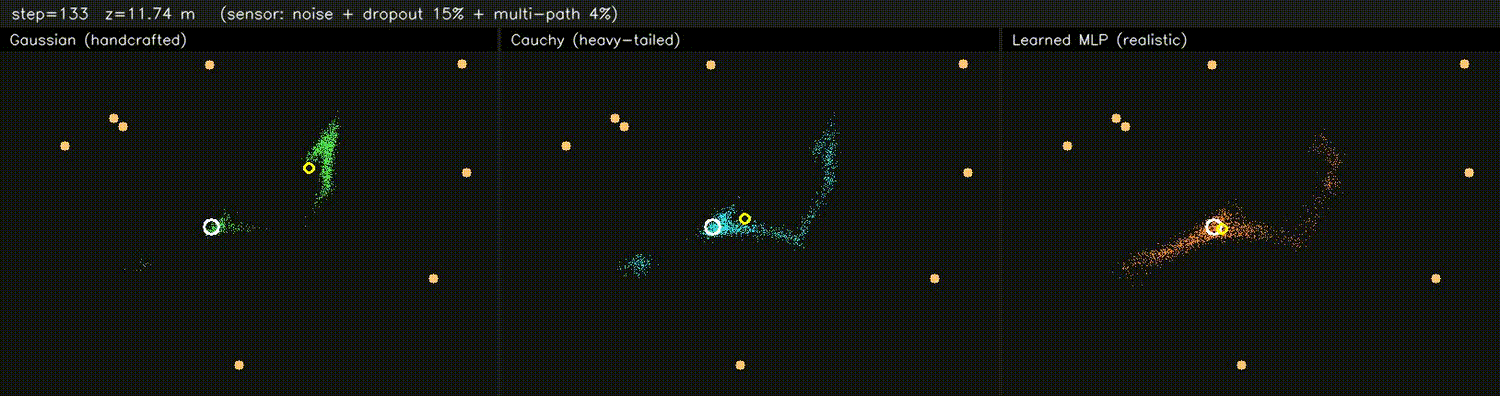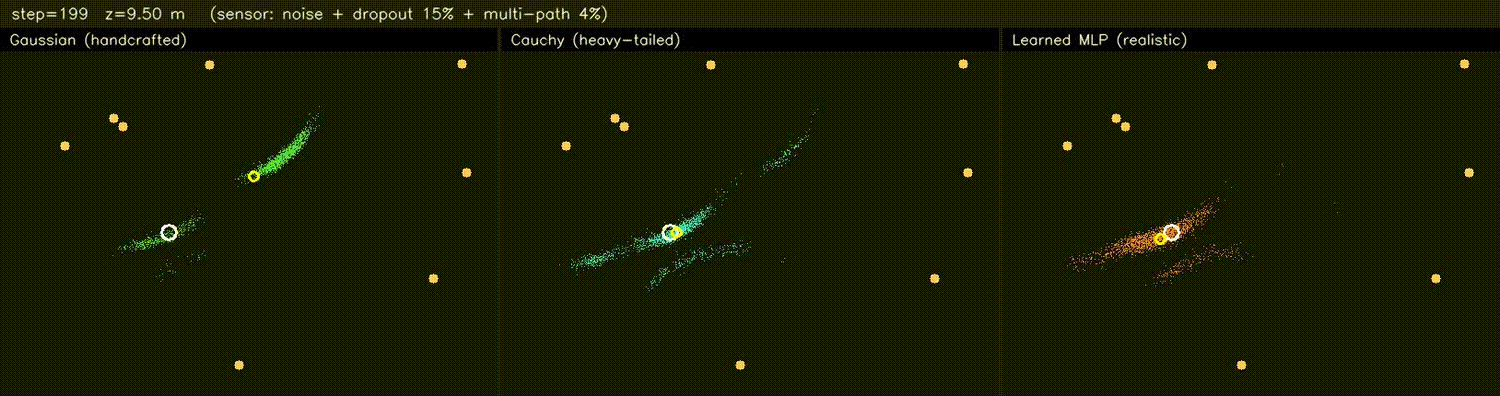 |
| PF + ESDF observation model | Differentiable end-to-end SLAM (Adam-tuned σ) |
|
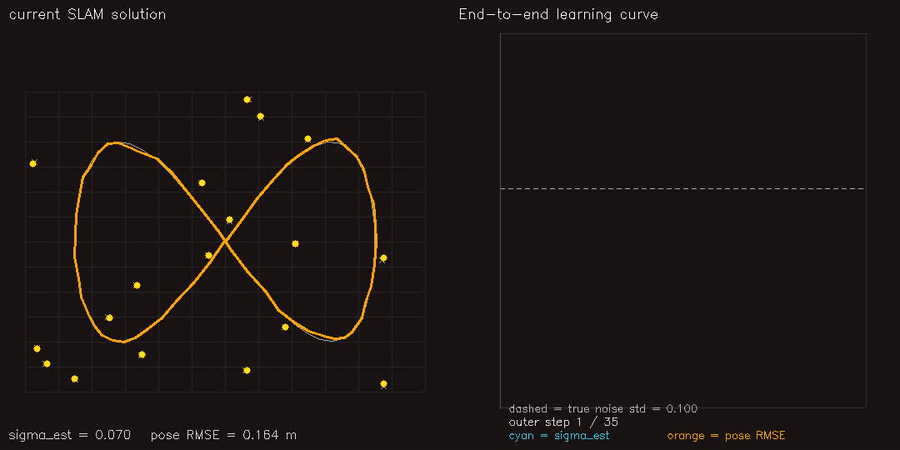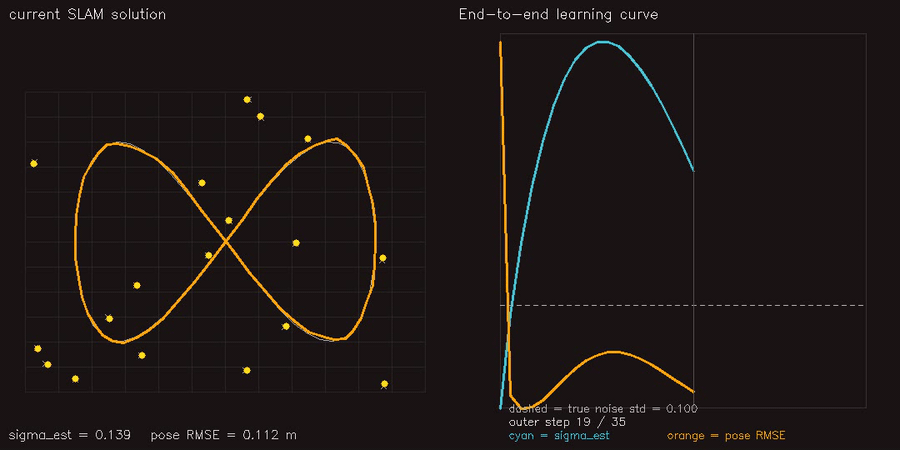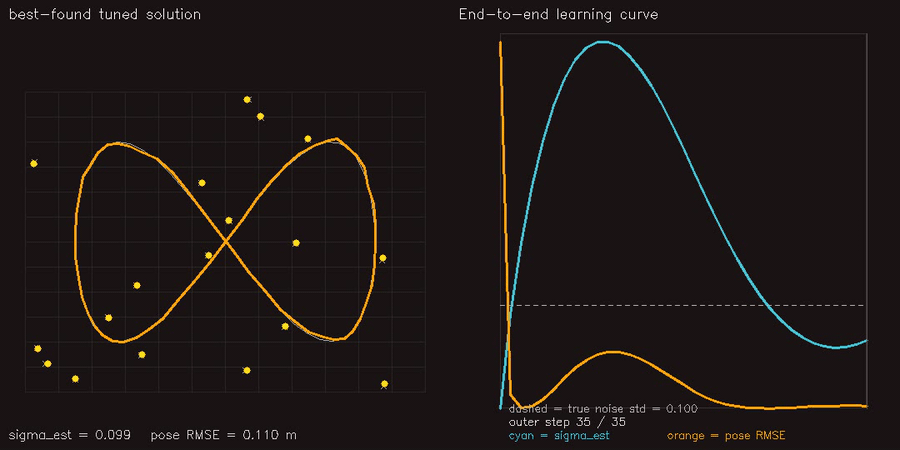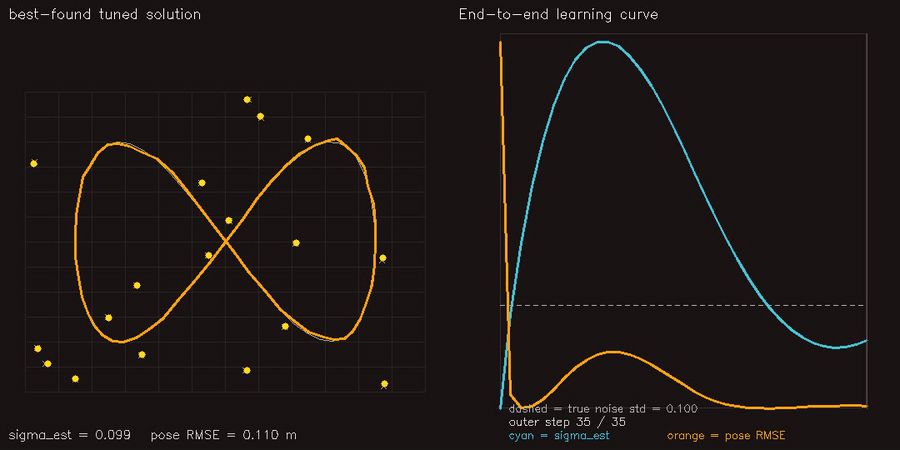 |
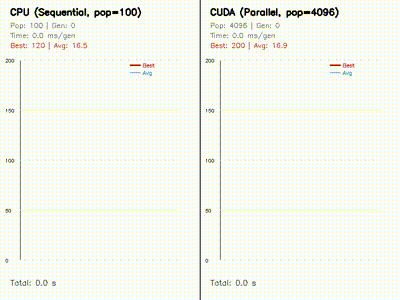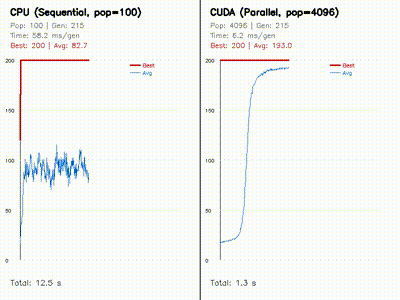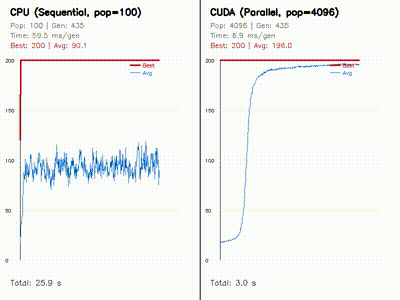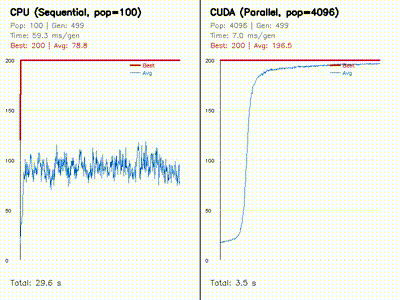
| Neural SDF MPPI | Neuroevolution: CPU 100 vs CUDA 4096 |
 |
 |
| 3D LiDAR Realistic (noise + divergence + multi-path + reflectivity + rolling shutter) | 3D Voxel Map (log-odds, 256³ scale) |
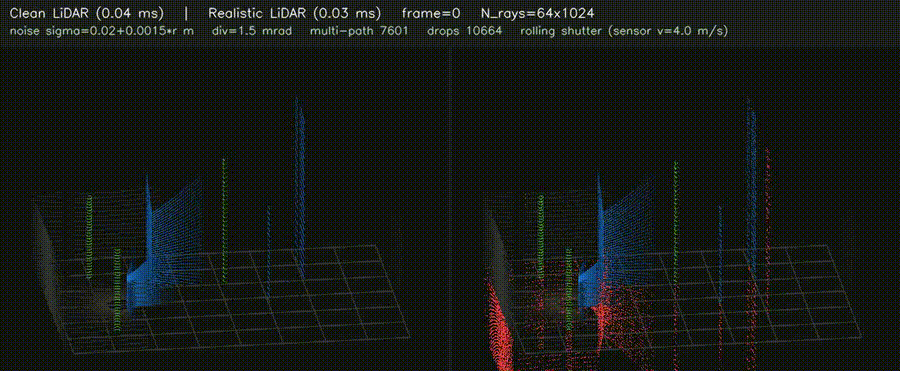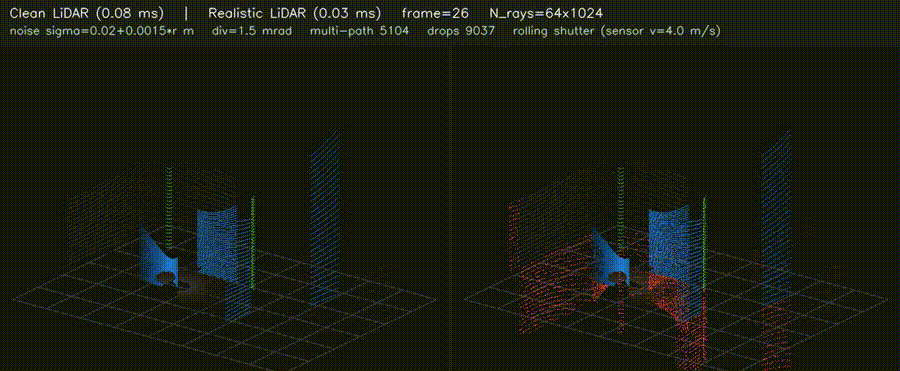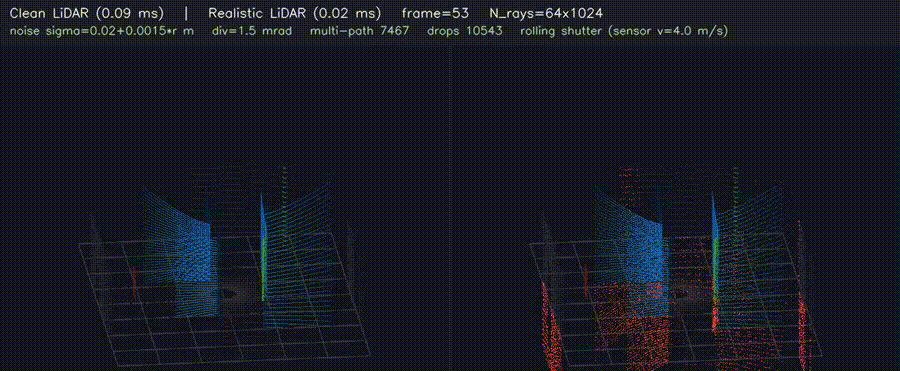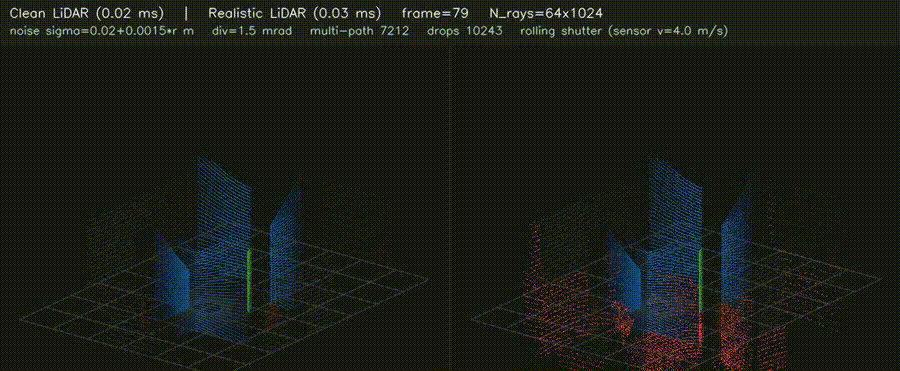 |
 |
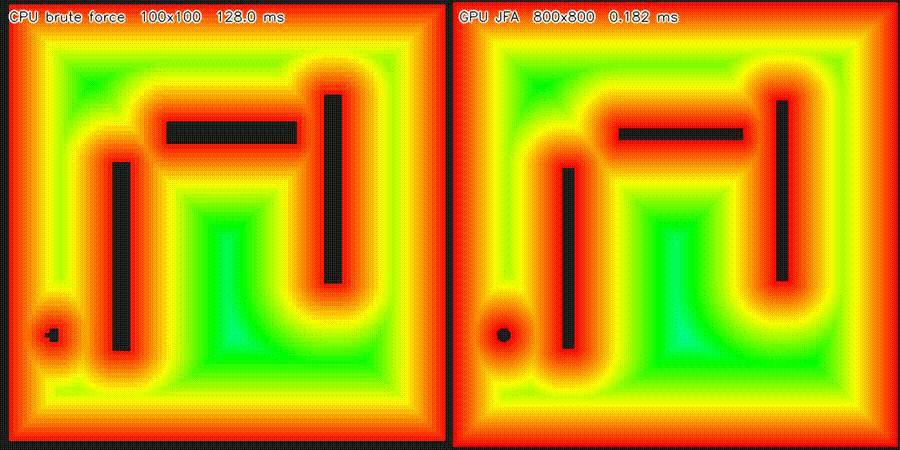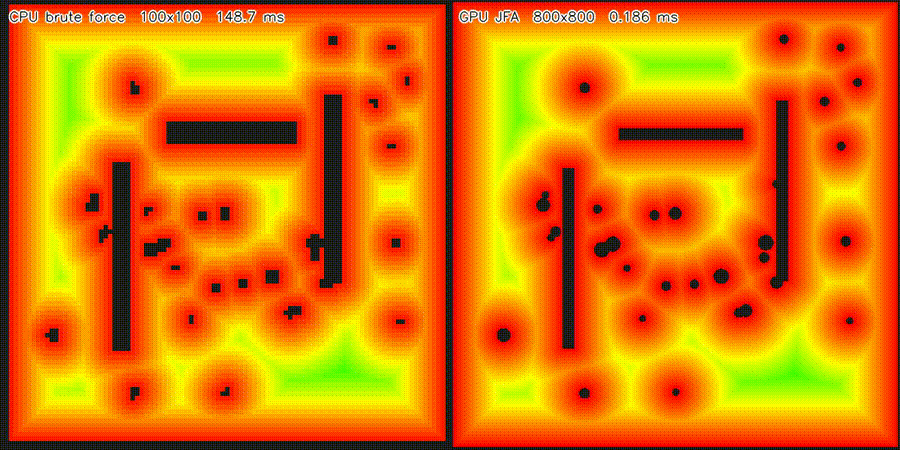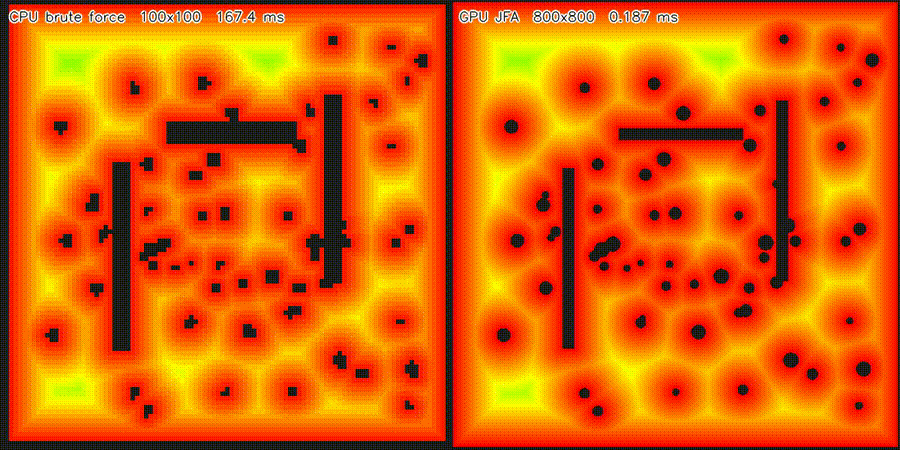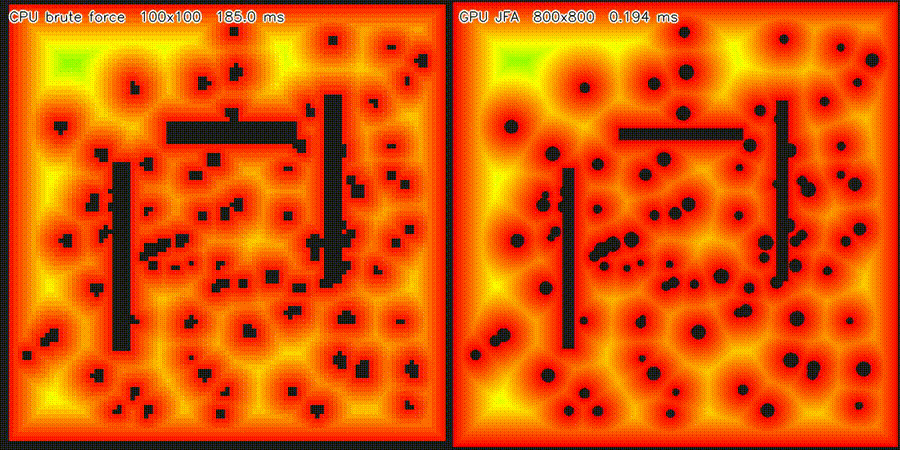
| Massive 2D LiDAR Sim (1M rays/scan) | ESDF JFA (640K cells, 53,404x) |
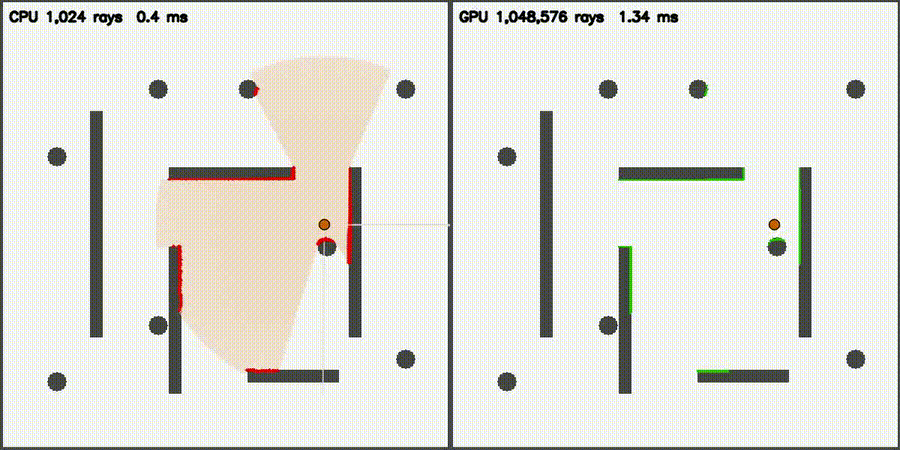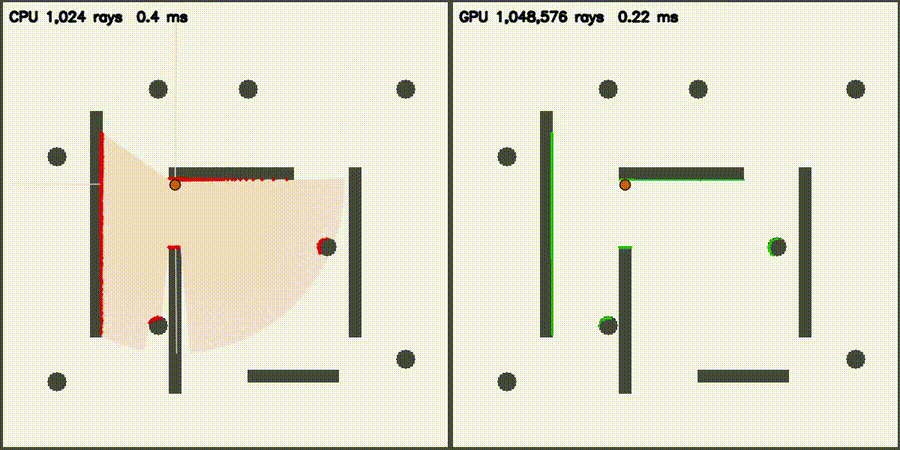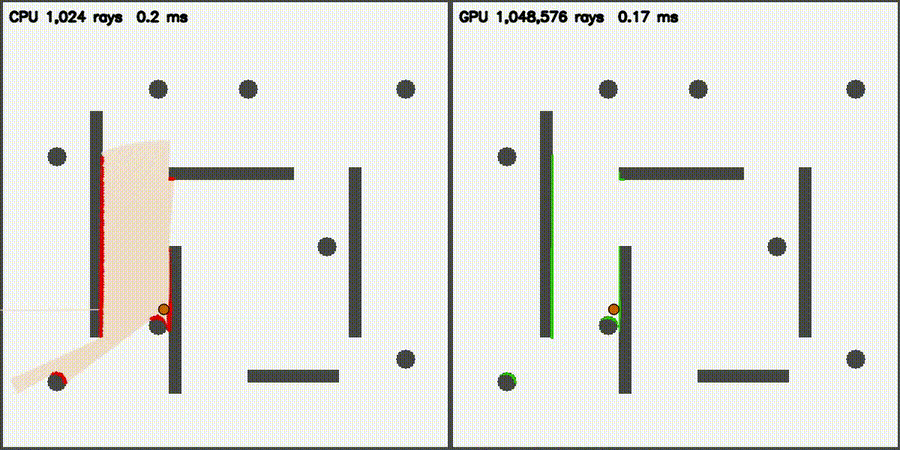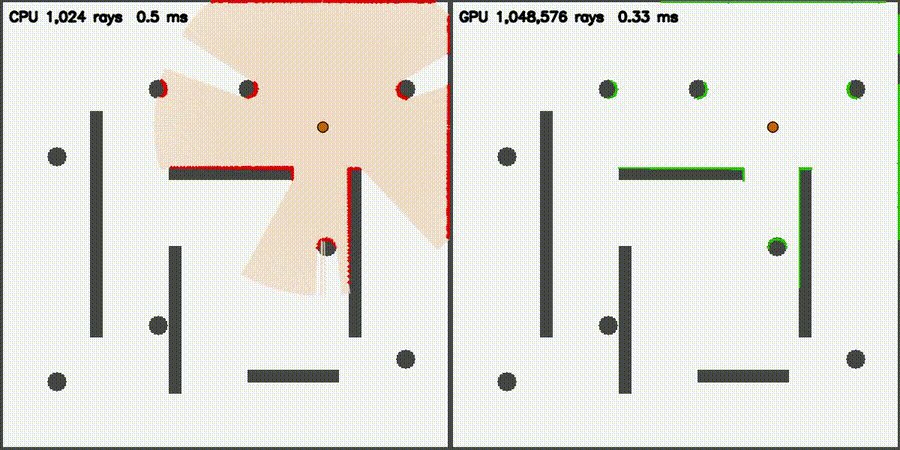 |
 |
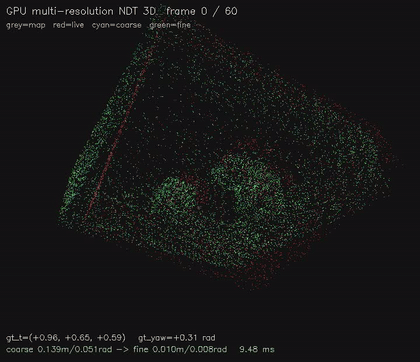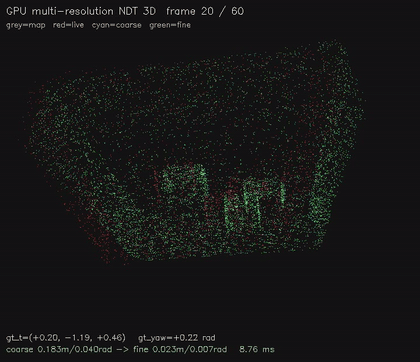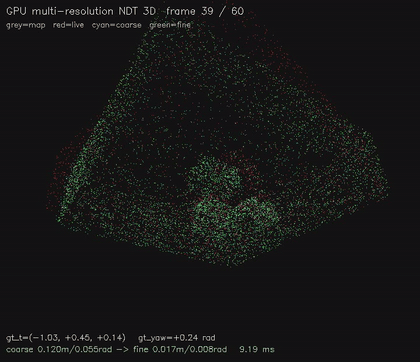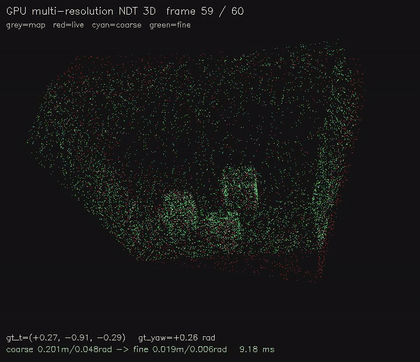
| GPU multi-resolution NDT 3D (8x8x4 -> 16x16x6, coarse-to-fine SE(3), 9.5 ms/scenario, 0.016 m avg) | GPU NDT 3D point cloud registration (16³ voxel NDT + 6-DOF GN on SE(3), 6.7 ms/scenario, ~0.03 m typical) |
 |
 |
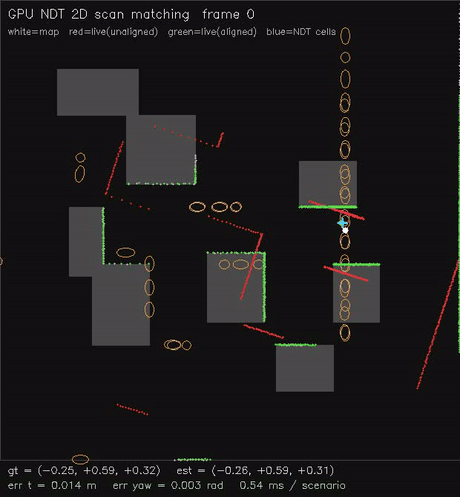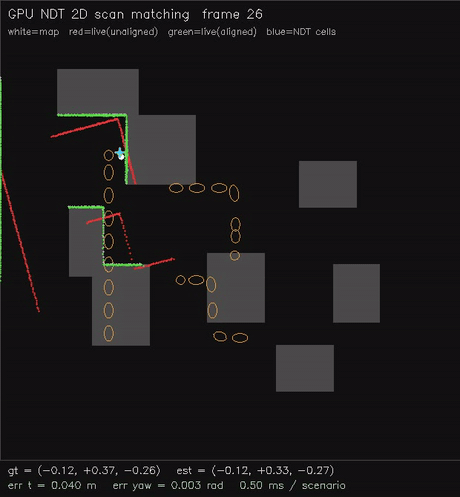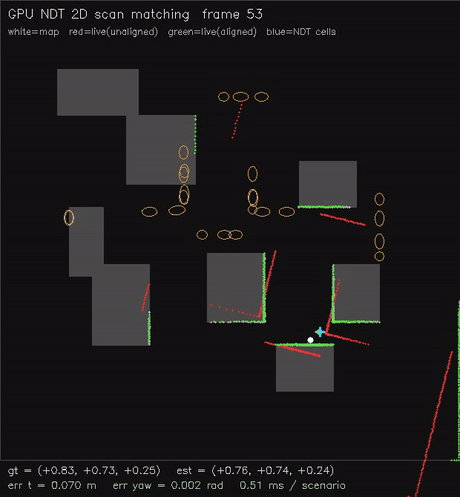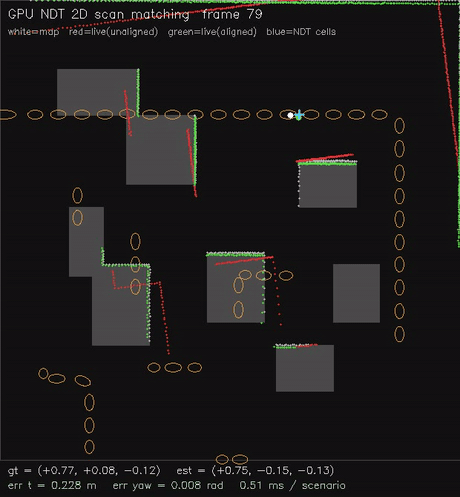
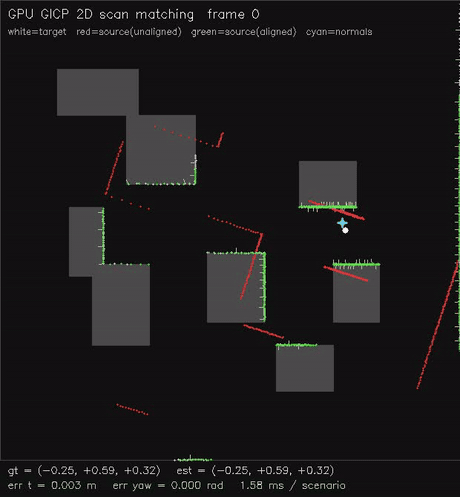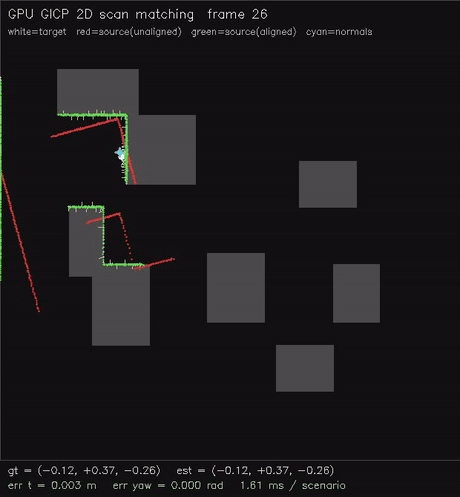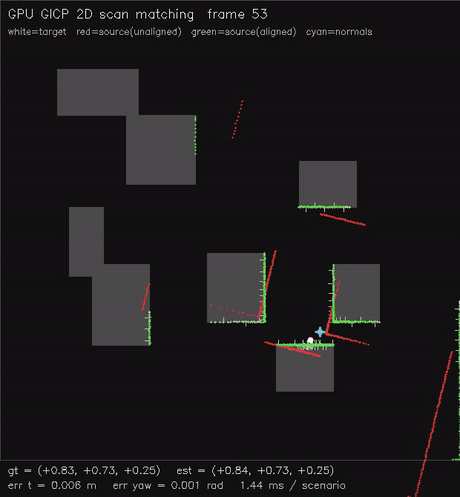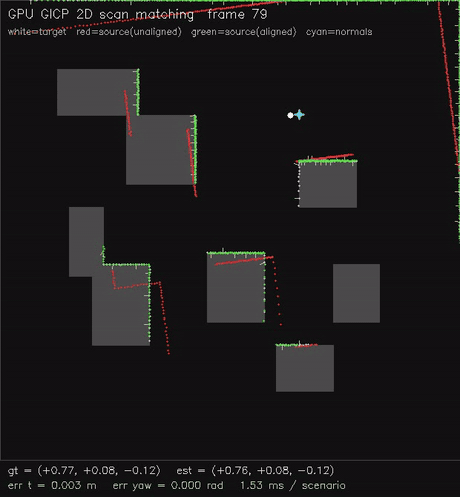
| GPU NDT 2D scan matching (Newton on NDT grid, 0.54 ms/scenario, ~0.02 m typical) | GPU GICP 2D scan matching (per-point cov + nearest-neighbour match, 1.9 ms/scenario, ~0.08 m typical) |
 |
 |
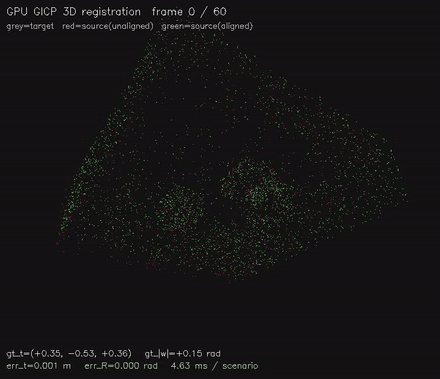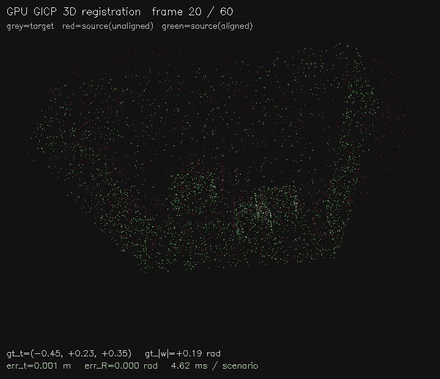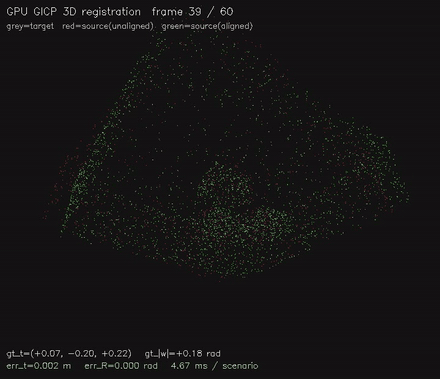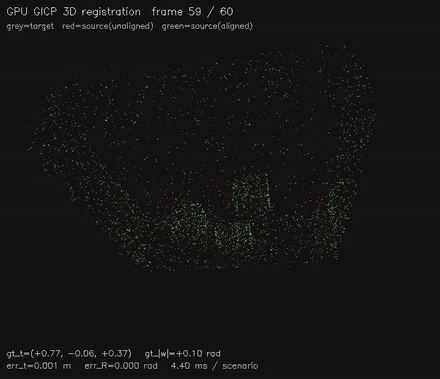
| GPU GICP 3D point cloud registration (per-point cov via Cardano eigendecomp + 6-DOF GN on SE(3), 4.7 ms/scenario, ~1 mm typical) | GPU correlative scan matching: exhaustive global alignment, 2.1M candidate poses/frame, recovers offsets where the local matcher fails (487x vs CPU) |
 |
|
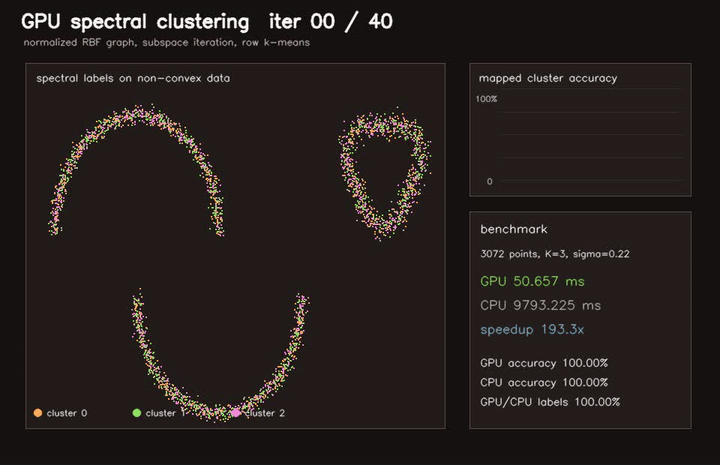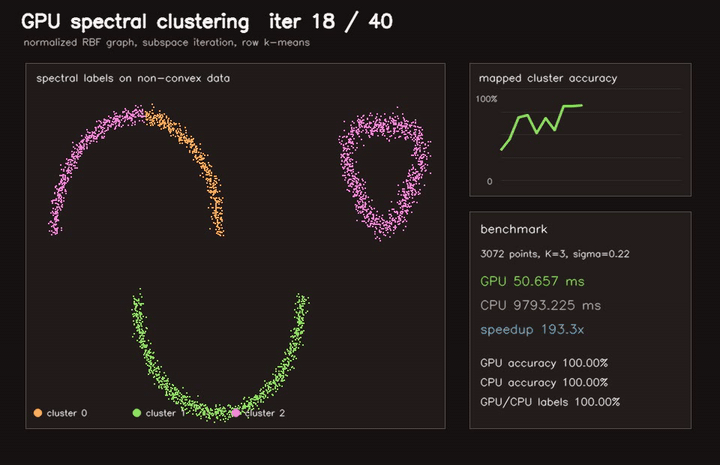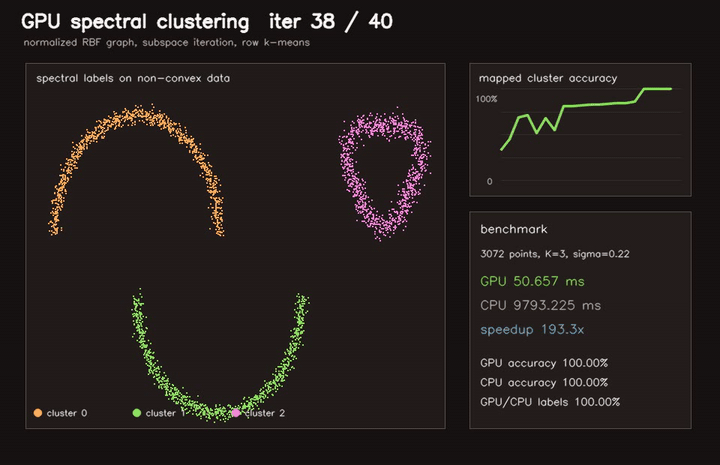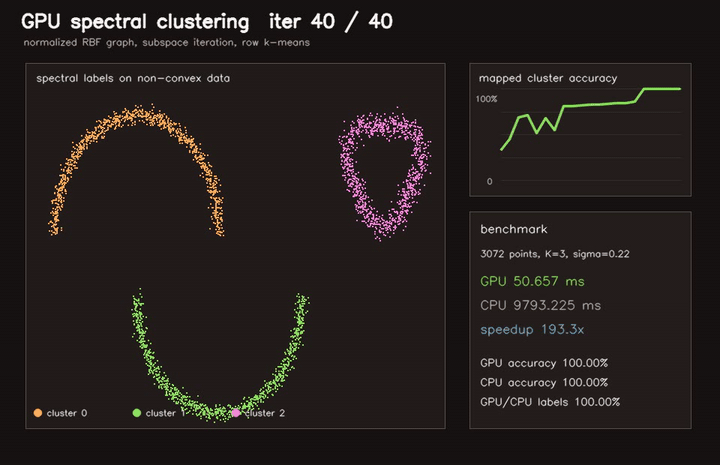
| GPU EM GMM clustering (262K points × 5 full-cov Gaussians, 42 EM iterations, 90.2x vs CPU) | GPU spectral clustering (3072-point dense RBF graph, 40 subspace iterations, 193x vs CPU) |
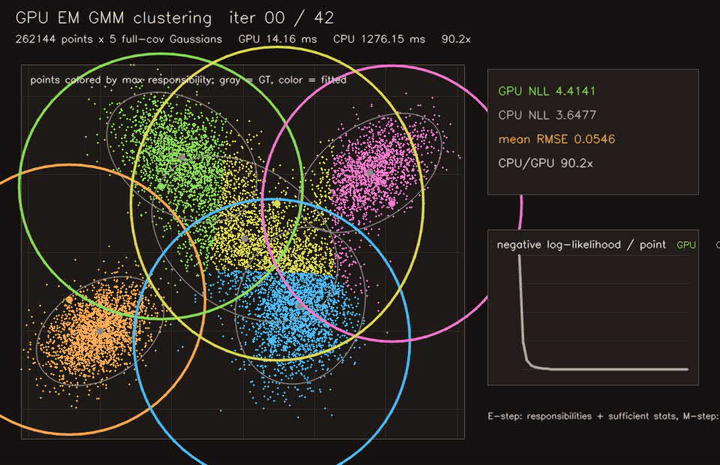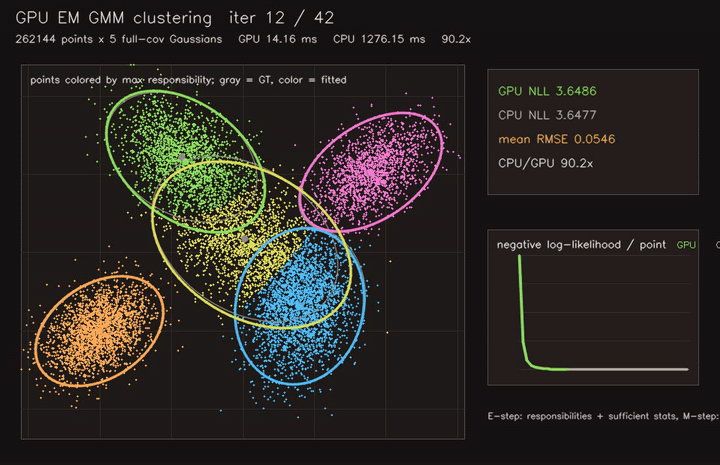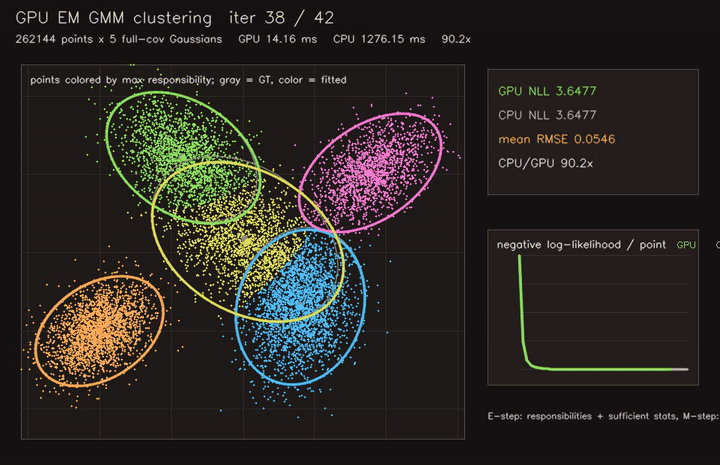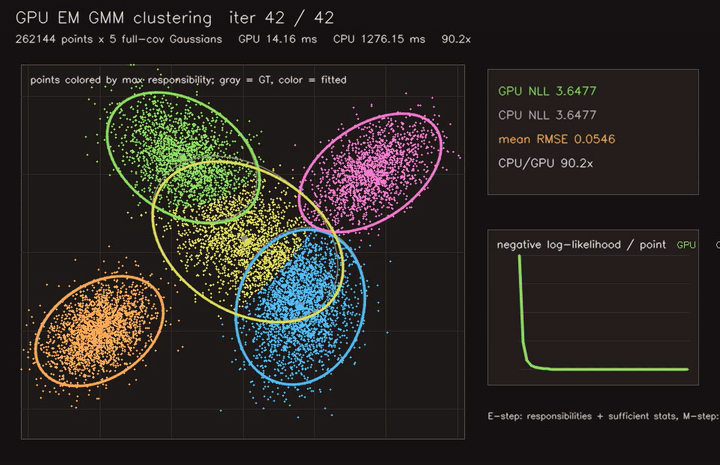 |
 |
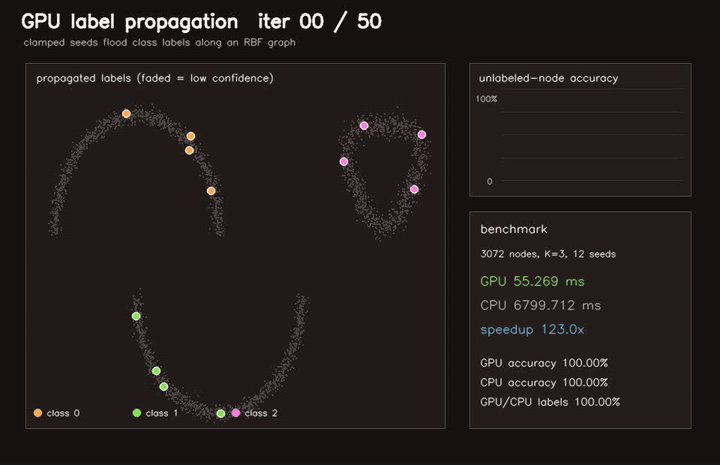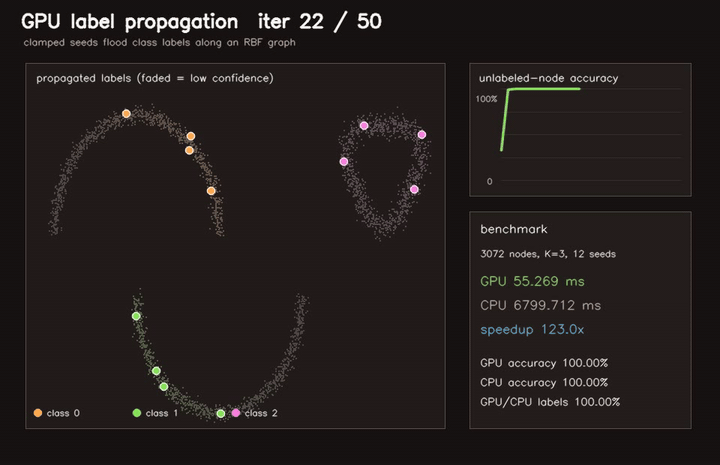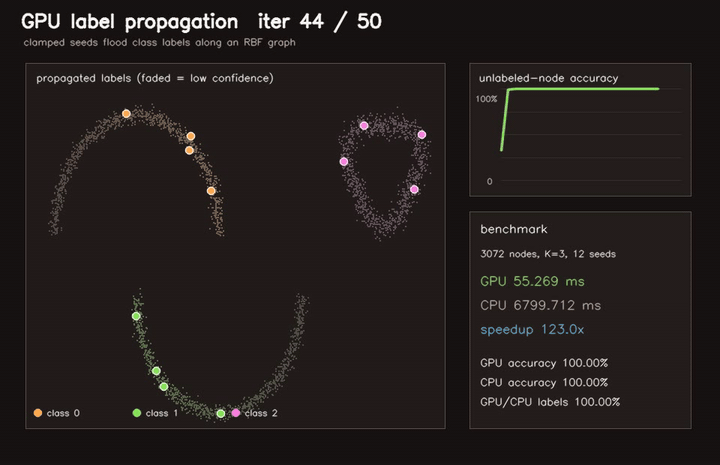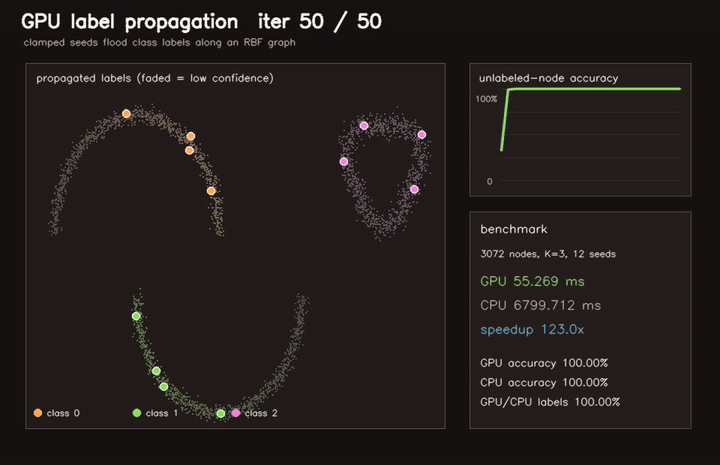
| GPU label propagation (3072-node RBF graph, 12 seeds, 50 clamped iterations, 123x vs CPU) | GPU traversability label propagation (3072 graph nodes, 40 iters, 81.2% sparse-seed accuracy, 79.9x vs CPU) |
 |
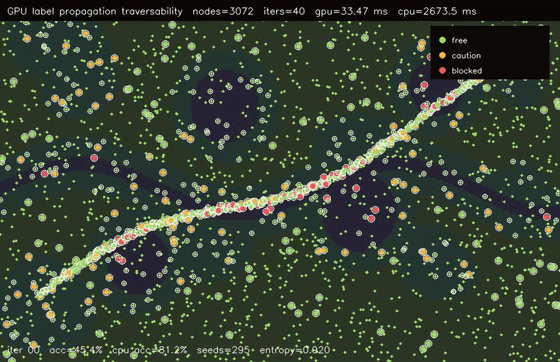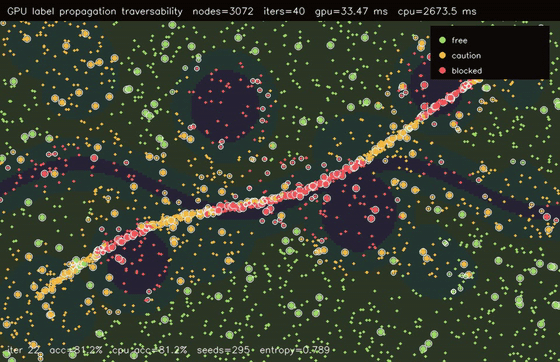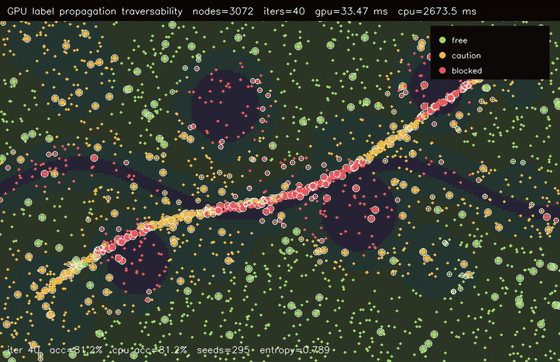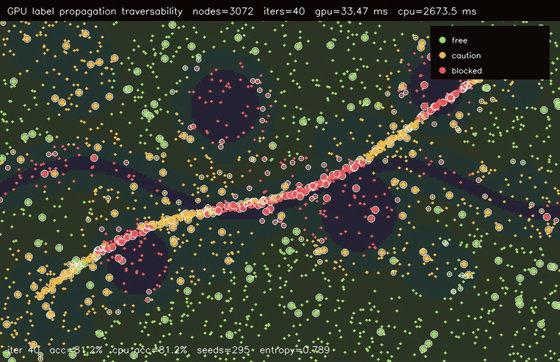 |
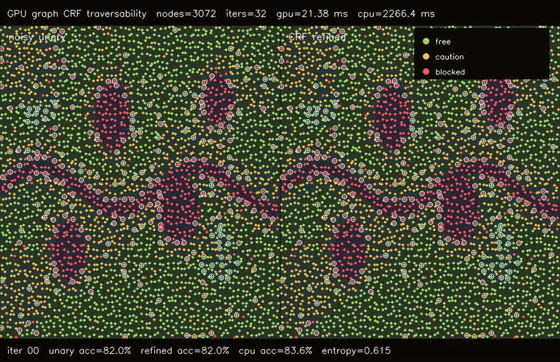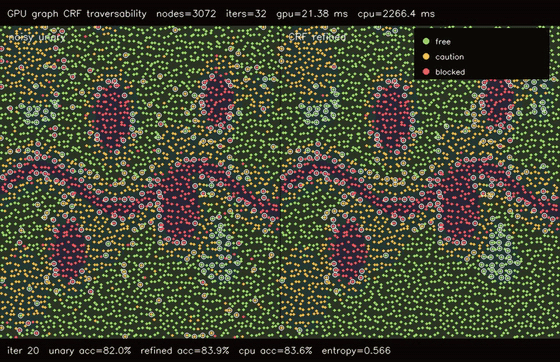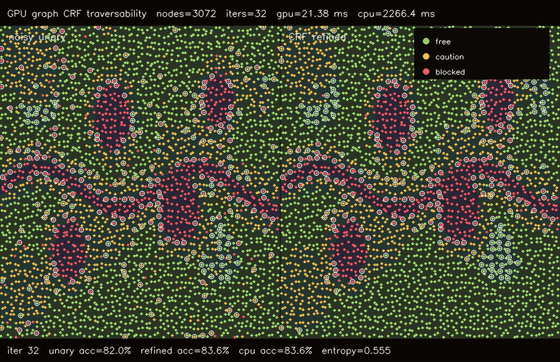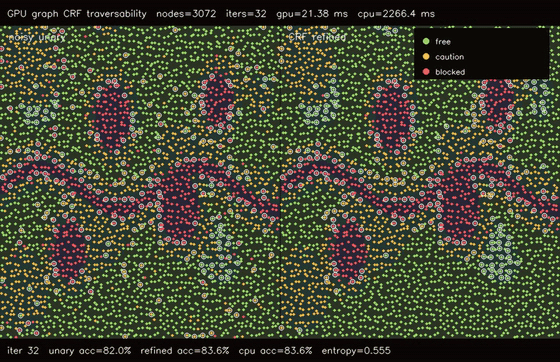
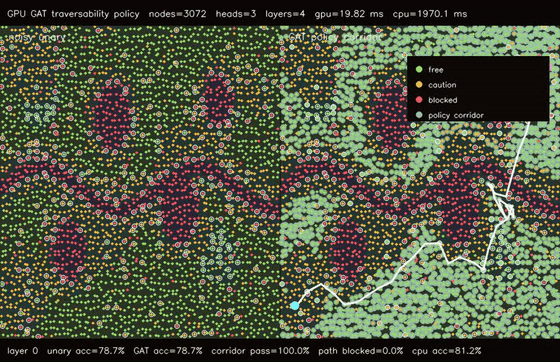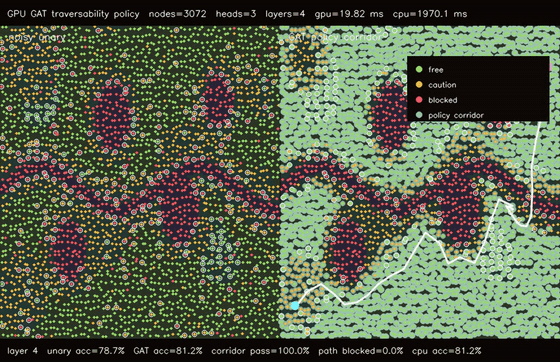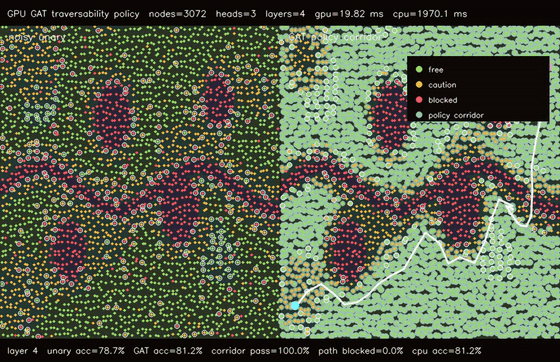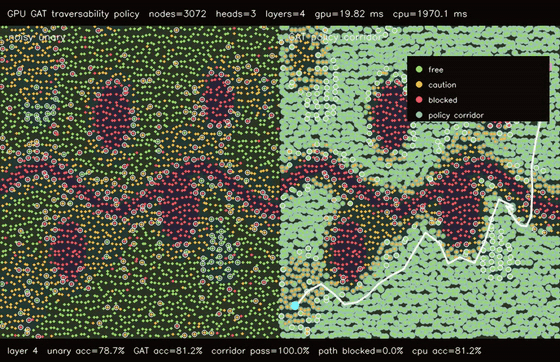
| GPU graph CRF traversability refinement (3072 nodes, noisy unary 82.0% -> CRF 83.6%, 106x vs CPU) | GPU GAT traversability policy (3072 nodes, 3 heads x 4 layers, 78.7% -> 81.3%, 99.4x vs CPU) |
 |
 |
More classical-algorithm GIFs
| RRT | RRT* |
 |
 |
| A* | Dijkstra |
 |
 |
| Potential Field | Voronoi Road Map |
 |
 |
| 3D RRT* (drone) | Occupancy Grid Mapping |
 |
 |
| FastSLAM 1.0 | AMCL |
 |
 |
| Value Iteration | PF on Episode |
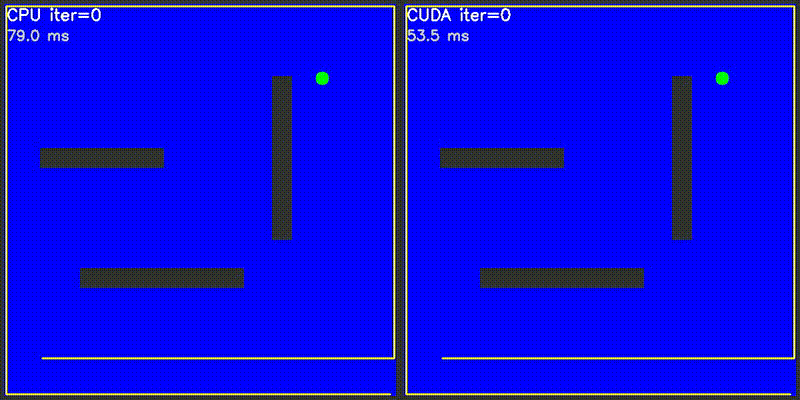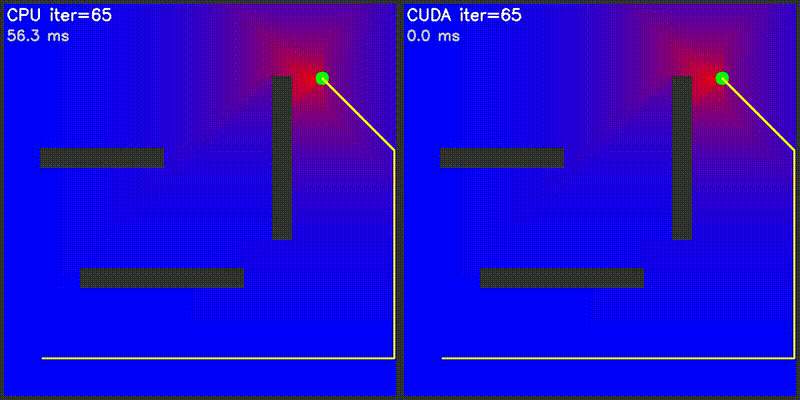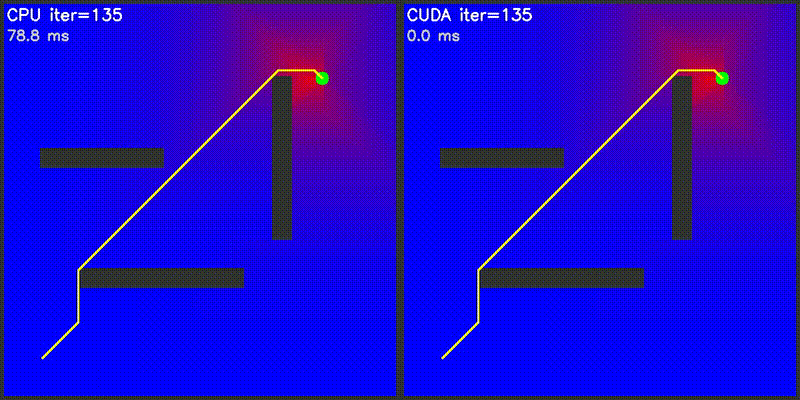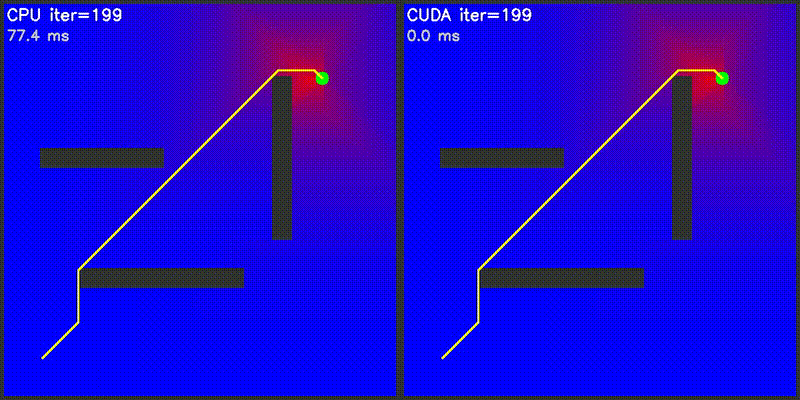 |
 |
| Dynamic Window | Frenet Optimal Trajectory |
 |
 |
| 500-robot multi-robot | Particle Filter |
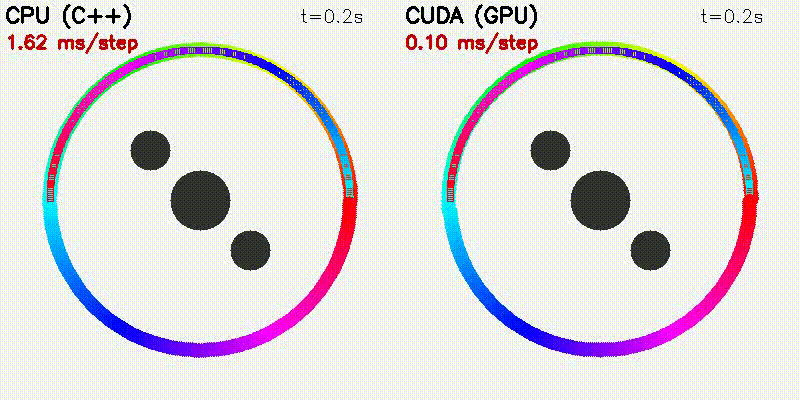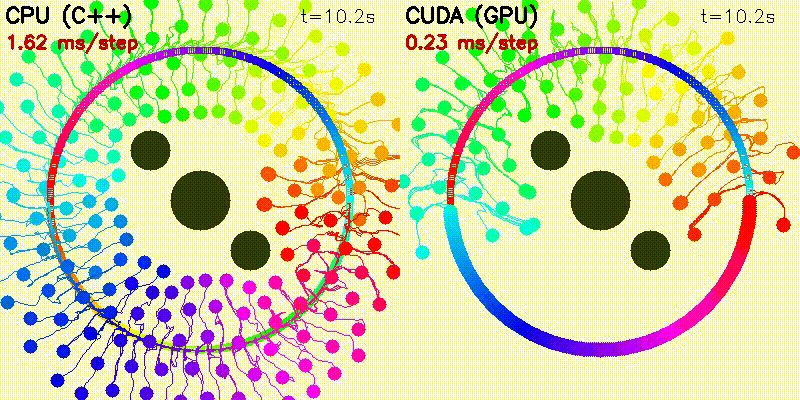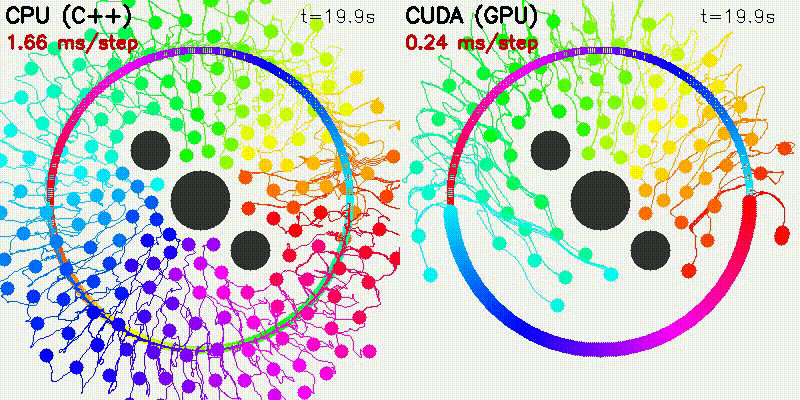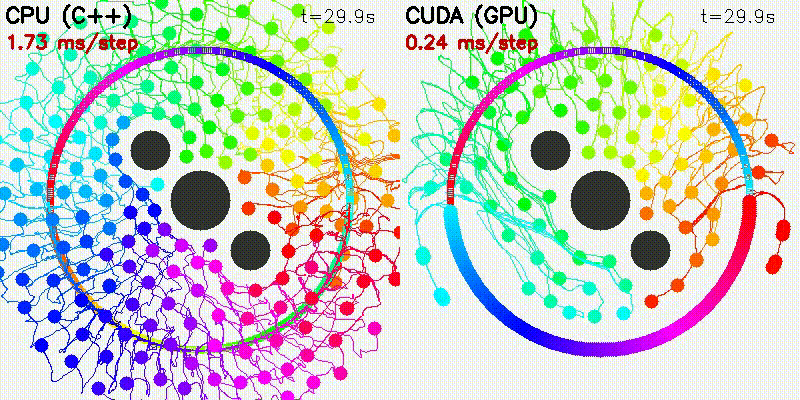 |
 |
| Gaussian Splatting Map Renderer (CPU sparse surfels vs CUDA dense splatting) | |
 |
mkdir build && cd build && cmake .. && make -j$(nproc)Requires CMake ≥ 3.18, CUDA Toolkit ≥ 12.0, OpenCV ≥ 4.5, Eigen 3. Executables go to bin/.
Planner showdown target gate:
./bin/gpu_planner_showdown_benchmark --check --no-video --json gif/gpu_planner_showdown_benchmark.json
python3 scripts/summarize_planner_showdown.py --json gif/gpu_planner_showdown_benchmark.json --markdown-out build/gpu_planner_showdown_benchmark.md --strict--check returns non-zero if the trainable safety-dual row misses the hard gates.
The gated default scenario is baseline; --scenario tight,
--scenario priority_flip, and --scenario adversarial_density are manual
stress probes for narrower crossings, flipped priority ordering, and dense
centerline conflicts.
Use --pressure-mode learned|teacher|none for the safety-pressure ablation:
the learned controller uses runtime safety metrics plus scenario context
(lane tightness, conflict density, cross-shift load, and priority flips) and
matches the teacher-style target gate on baseline,
while disabling pressure drops the adversarial-density stress probe to a target
miss (9 collisions, CVaR 32.62).
Use --adaptive-budget learned|off for the pass-budget ablation. The default
learned budget scores pass-2 CVaR, residual pressure, and scenario difficulty;
in the tracked matrix it evaluates only the adversarial-density run and records
whether a refinement candidate is accepted. Current matrix runtime remains
within 13.050 ms.
After running those probes, repeat --json to render a scenario matrix:
python3 scripts/summarize_planner_showdown.py \
--json gif/gpu_planner_showdown_benchmark.json \
--json build/gpu_planner_showdown_tight.json \
--json build/gpu_planner_showdown_priority_flip.json \
--json build/gpu_planner_showdown_adversarial_density.json \
--markdown-out build/gpu_planner_showdown_matrix.md \
--strictPressure ablation matrix:
./bin/gpu_planner_showdown_benchmark --scenario baseline --pressure-mode teacher --no-video --json build/gpu_planner_showdown_pressure_teacher.json
./bin/gpu_planner_showdown_benchmark --scenario baseline --pressure-mode none --no-video --json build/gpu_planner_showdown_pressure_none.json
./bin/gpu_planner_showdown_benchmark --scenario adversarial_density --pressure-mode none --no-video --json build/gpu_planner_showdown_pressure_none_adversarial_density.json
python3 scripts/summarize_planner_showdown.py \
--json gif/gpu_planner_showdown_benchmark.json \
--json build/gpu_planner_showdown_pressure_teacher.json \
--json build/gpu_planner_showdown_pressure_none.json \
--json build/gpu_planner_showdown_adversarial_density.json \
--json build/gpu_planner_showdown_pressure_none_adversarial_density.json \
--markdown-out build/gpu_planner_showdown_pressure_ablation.mdPlanner falsifier target gate:
./bin/gpu_planner_falsifier_benchmark --check --json gif/gpu_planner_falsifier_benchmark.json
python3 scripts/summarize_planner_falsifier.py --json gif/gpu_planner_falsifier_benchmark.json --markdown-out build/gpu_planner_falsifier_benchmark.md --strictThe falsifier scans 719,712 scenario variants over lane tightness, jitter, cross-shift, spawn phase, goal offset, and priority flips. The worst 12 cases must break no-pressure and no-regret baselines, keep the learned target planner inside the hard gates, and accept at least one adaptive repair. In the tracked run, all 12 worst cases accept repair; worst learned CVaR is 24.68 with 5.54% residual and 13.178 ms target runtime.
ROS2 (optional):
cd ros2_ws && colcon build --packages-select cuda_robotics| Domain | Best result |
|---|---|
| Particle Filter (10K) | CPU 75 s → CUDA 27 ms — 2,776x |
| Dynamic Window (8K samples) | CPU 1.2 s → CUDA 1.7 ms — 705x |
| Global Localization MCL | 32,768 particles, hidden kidnap; local-only post RMSE 20.24 m → sensor-reset recovery 0.022 m |
| MegaParticles-style Stein MCL | 1,048,576 range particles; local bootstrap post RMSE 14.61 m → Stein/bucket posterior recovery 0.097 m |
| MegaParticles LSH neighbor index | 2 × 1,048,576 particles; explicit p-stable LSH (8 tables × 3 projections) vs fixed grid; neighbor recall vs brute-force kNN 58.2% → 87.8%, post-kidnap RMSE 0.099 → 0.088 m |
| MegaParticles 6-DoF SE(3) | 1,048,576 SE(3) particles in a 3D voxel world; 3D-ESDF range likelihood, quaternion GN steps, 6-D p-stable LSH neighbor consensus; hidden kidnap: local bootstrap post RMSE 5.97 m → 6-DoF MegaParticles 0.22 m / 1.9 deg, reacquires in 0 frames |
| MegaParticles GICP D2D likelihood | 2 × 1,048,576 particles, identical Stein machinery; surface-aware GICP distribution-to-distribution scoring (per-point disk covariances, grid-indexed map cloud) vs the distance-field proxy; both recover the hidden kidnap in 0 frames, post-kidnap RMSE 0.099 → 0.064 m and final error 0.040 → 0.021 m, at ~2.4x per-step cost (4.9 → 12.1 ms) |
| MegaParticles trajectory smoother | 1,048,576 particles; robust fixed-lag smoother over the max-posterior representative state (switchable CV-motion + Huber measurement factors, data-driven reset on post-dropout relocalization); raw vs smoothed, in-track jitter (mean |Δ²pos|) 4.31 → 0.06 (~70x), in-track RMSE 5.4 → 0.25 m, post-kidnap RMSE ~1.6 → 0.09 m, recovers the hidden kidnap in 0 frames |
| Augmented KLD-AMCL | KLD-sampling adapts 400→65,536 particles, augmented injection reacquires hidden kidnap in 13 steps, settled RMSE 0.014 m, 15.2x vs CPU |
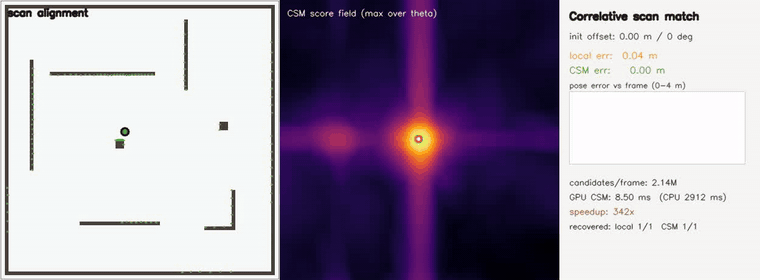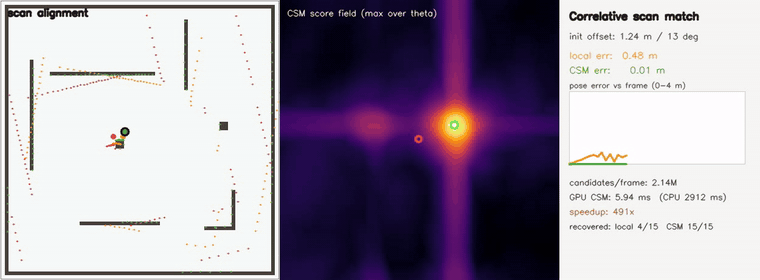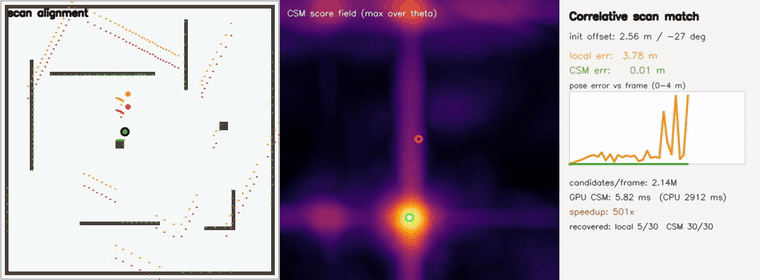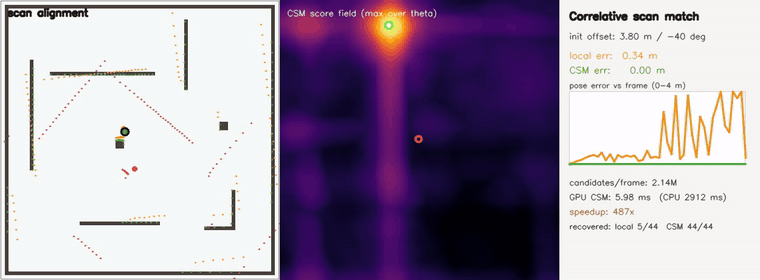
| Correlative scan matching | exhaustive global pose search, 2.1M (x,y,θ) candidates/frame (coarse-to-fine); recovers offsets up to ±3.8 m / 40° (44/44 < 0.20 m, RMSE 0.006 m) where a local field matcher stalls (5/44, RMSE 1.95 m); GPU 6 ms vs CPU 2.9 s — ~490x |
| 2D ESDF (640K cells) | 53,404x per cell (JFA) |
| 3D ESDF (1M voxels) | 86,613x per voxel (JFA-3D) |
| Massive collision check | 1,277x per candidate (2D DDA) |
| Normal estimation (10K pts) | 3,171x (PCA, one thread per point) |
| Pose-graph SLAM (200 nodes) | ~200 ms total, RMSE 4.88 → 0.56 m |
| 3D Pose-graph SLAM | 384 poses / 575 edges, finite-difference SE(3) Jacobians, RMSE 1.64 → 0.28 m |
| Robust 3D Pose-graph SLAM | 384 poses / 611 edges, 36 false loop closures, switch gate rejects 36/36; plain 6.95 m → robust 0.28 m |
| Switchable-constraint 3D Pose-graph SLAM | 384 poses / 611 edges, per-loop switch variables jointly optimised with poses; learns 36/36 false-loop rejection (no hand-set trim); plain 6.95 m → switchable 0.29 m / 2.2 deg |
| Online 3D SLAM, switchable loop constraints | 420 streamed SE(3) poses, sliding window W=80 + global pass on loop, 21 false loops injected live; plain online 9.10 m → switchable online 0.29 m, 21/21 false loops rejected as they arrive |
| CSM loop-closure SLAM | 140-keyframe 2D lap; loops DETECTED by exhaustive correlative scan matching (no GT), 1.42M candidate relposes/attempt (coarse-to-fine), score-gated (49 accepted / 3 rejected); dead-reckoning ATE 2.03 m → SLAM 0.17 m; GPU 2.4 ms vs CPU 1.5 s per attempt — 630x |
| CSM submap SLAM | same 140-keyframe lap with deliberately SPARSE, noisy scans (64 rays, 6 cm noise); loop front-end matches against a SUBMAP (8 fused scans) vs a single scan; submap recovers 48/52 loops (ATE 0.18 m) where single-scan gets only 17/52 (0.38 m), both from a 2.03 m dead-reckoning baseline; 1.42M candidate relposes/attempt, GPU 4.6 ms vs CPU 0.67 s — 148x |
| Branch-and-bound CSM | growing (x, y, θ) window up to ±6.4 m / ±35°; branch-and-bound over a GPU-built multi-resolution max-pool bound returns the IDENTICAL grid optimum as exhaustive search (40/40 frames exact) while scoring up to 1004x fewer candidates (4.5M exhaustive vs 4.5k nodes); GPU exhaustive 12 ms vs CPU 0.7 s — ~57x |
| Branch-and-bound loop-closure SLAM | branch-and-bound runs the SLAM loop-closure search over a full-resolution 4.5M-cell relpose window (±8 m / ±0.6 rad) scoring 957x fewer candidates than brute force (4.7k nodes vs 4.52M), returning the IDENTICAL relpose on 51/51 attempts; drives the live pose-graph, closing the lap (dead-reckoning ATE 2.18 m → 0.20 m); GPU B&B 0.27 ms vs brute force 7.1 ms / attempt |
| 3D Gaussian Splatting (~1k Gaussians, 720x480) | 0.94 ms / frame |
| GPU diffusion policy | 768-sample behavior cloning MLP + 512 x 64 learned denoising trajectories |
| GPU CMA-ES objective evaluation | 3 x 32,768 candidates x 10D, 1,254x vs CPU eval |
| GPU MCTS kinodynamic planning | 64 scenes x 4096 rollouts x 48 horizon, 712x vs CPU |
| GPU differentiable value iteration traversability | 192x128 learned traversability cost x 220 soft Bellman iterations, 1.53 ms, path reaches goal, 747.4x vs CPU |
| GPU neural A* traversability | 64 batched 192x128 learned-heuristic A* queries, 145.12 ms/batch, 79.0% fewer expansions than Dijkstra, 153.1x vs CPU sequential neural A* |
| GPU anytime neural A* traversability | 4-pass heuristic annealing over 64 batched 192x128 learned-heuristic A* queries, path cost 579.57 -> 522.96, 158.0x vs CPU sequential anytime |
| GPU multi-goal neural A* traversability | 8 candidate goals x 8 replans on a 192x128 learned cost field, selected G0 with score -23.71, all 8 goals reachable, 87.5x vs CPU sequential multi-goal |
| GPU spatiotemporal neural A* traversability | 64 batched 192x128 dynamic-risk neural A* queries, moving-obstacle max risk 1.94 -> 0.26, 80.9% fewer expansions than dynamic Dijkstra, 106.5x vs CPU sequential spatiotemporal A* |
| GPU learned experience graph planner | 128 batched 1536-node learned experience-graph A* queries, all queries reachable, 51.8% fewer expansions than graph Dijkstra, 278.5x vs CPU sequential graph A* |
| GPU graph-guided neural MPPI | 32768 rollouts x H=72 x guided/unguided batches, cost 1430.31 -> 842.35, terminal error 1.25 -> 0.15, route error 0.491 -> 0.045, 1320.1x vs CPU equivalent rollout evaluation |
| GPU kinodynamic graph-neural MPPI | 32768 nonholonomic speed/steering rollouts x H=72 x guided/unguided batches, cost 1516.74 -> 851.11, terminal error 5.11 -> 0.88, route error 1.530 -> 0.252, 49.9x vs CPU equivalent kinodynamic rollout evaluation |
| GPU interaction-graph neural MPPI | 48 moving agents x 4 message-passing risk updates + 32768 MPPI rollouts x H=72, social risk 1.628 -> 1.308, clearance -0.15 -> -0.10, full objective 2913.50 -> 2395.14, 4140.9x vs CPU equivalent rollout evaluation |
| GPU multi-agent graph-neural MPPI | 48 robots x 768 rollouts x H=72 x independent/coordinated modes, cross-route collisions 518 -> 261, social risk 3.544 -> 2.588, reach basin 48/48 -> 36/48, 3139.6x vs CPU equivalent rollout evaluation |
| GPU priority graph-neural MPPI | 48 robots x 768 rollouts x H=72 x coordinated/priority modes, right-of-way arbitration cuts cross-route collisions 261 -> 245, reach basin 36/48 -> 40/48, deadlocks 1 -> 0, terminal error 1.97 -> 1.65, 2870.5x vs CPU equivalent rollout evaluation |
| GPU intent graph-neural MPPI | 48 robots x 768 rollouts x H=72 x naive/intent-aware modes, top-1 intent 100.0%, cross-route collisions 518 -> 216, social risk 3.519 -> 2.897, reach basin 48/48 -> 42/48, 292.9x vs CPU equivalent rollout evaluation |
| GPU belief-risk graph MPPI | 48 robots x 768 rollouts x H=72 x expected-risk/CVaR belief modes, collision CVaR 38.23 -> 26.17, tail social risk 4.363 -> 3.972, min separation -0.391 -> -0.368, reach basin 48/48 -> 48/48, 652.8x vs CPU equivalent rollout evaluation |
| GPU best-response graph MPPI | 48 robots x 768 rollouts x H=72 x one-shot/best-response game passes, cross-route collisions 518 -> 171, collision CVaR 105.43 -> 35.00, unilateral best-response gain 25.69%, reach basin 48/48 -> 39/48, 3132.6x vs CPU equivalent rollout evaluation |
| GPU iterative game graph MPPI | 48 robots x 768 rollouts x H=72 x one-shot/raw best-response/2 damped fictitious-play updates, cross-route collisions 518 -> 154, collision CVaR 105.43 -> 38.77, reach basin 48/48 -> 39/48 -> 48/48, path delta 0.385 -> 0.191, 3181.3x vs CPU equivalent rollout evaluation |
| GPU no-regret game graph MPPI | 48 robots x 768 rollouts x H=72 x one-shot/raw best-response/3 regret-matched updates, cross-route collisions 518 -> 150, collision CVaR 105.43 -> 43.34, reach basin 48/48 -> 39/48 -> 48/48, unilateral residual 25.69% -> 13.58%, alpha avg 0.546 -> 0.281, 2960.6x vs CPU equivalent rollout evaluation |
| GPU safe no-regret game graph MPPI | 48 robots x 768 rollouts x H=72 x one-shot/raw/no-regret/safe no-regret updates, cross-route collisions 518 -> 136, collision CVaR 43.34 -> 37.93 vs no-regret, reach basin 48/48 -> 39/48 -> 48/48, safety alpha avg 0.637 -> 0.469, unilateral residual 25.69% -> 19.37%, 3043.4x vs CPU equivalent rollout evaluation |
| GPU learned safety-dual prior graph MPPI | 48 robots x 768 rollouts x H=72 x one-shot/raw/no-regret/learned-prior safety-dual updates, fixed-weight MLP prior predicts dual/alpha/scale from graph-risk features, cross-route collisions 518 -> 140, collision CVaR 43.34 -> 39.54 vs no-regret, reach basin 48/48 -> 39/48 -> 48/48, learned prior scale avg 1.168 -> 1.052, unilateral residual 25.69% -> 16.53%, 3075.5x vs CPU equivalent rollout evaluation |
| GPU trainable safety-dual prior graph MPPI | 48 robots x 768 rollouts x H=72 x one-shot/raw/no-regret/trainable-prior safety-dual updates, tiny MLP trains on 1152 synthetic graph-risk labels (loss 0.21104 -> 0.00178), cross-route collisions 518 -> 132, collision CVaR 43.34 -> 37.10 vs no-regret, reach basin 48/48 -> 39/48 -> 48/48, trainable prior scale avg 1.150 -> 1.083, unilateral residual 25.69% -> 17.48%, 3013.1x vs CPU equivalent rollout evaluation |
| GPU planner showdown benchmark | 48 robots x 768 rollouts x H=72 comparing ORCA-like reciprocal, priority graph, no-regret MPPI, and trainable safety-dual MPPI; hard target gates: reach 48/48, deadlocks 0, collisions <= 8, CVaR <= 26.5, residual <= 12.0%, runtime <= 15.0 ms; trainable safety-dual plus scenario-conditioned learned safety-pressure controller (4320 metric/context labels, loss 0.78480 -> 0.01129) and adaptive tail-risk refinement budget with collisions 0, CVaR 21.61, residual 4.90%, 13.05 ms, 2977.5x vs CPU equivalent rollout evaluation; --check emits a target-gate exit code and JSON summary |
| GPU planner falsifier benchmark | 719,712 GPU-scored scenario variants over lane scale, jitter, cross-shift, spawn phase, goal offset, and priority flips; worst 12 cases break no-pressure and no-regret (12/12 failures), learned safety-pressure target passes all 12 with worst CVaR 24.68, residual 5.54%, runtime 13.178 ms, and adaptive repair accepted 12/12; 70.7x vs CPU surrogate scan |
| GPU GNN swarm controller | 2048 agents x 3 message passes, 2.88 ms/control, 44.3x vs CPU |
| GPU reciprocal risk planner | 1024 agents x 9 actions x H=16, 4.05 ms/plan, 311.5x vs CPU |
| GPU assignment tracking | 128 scenes x 48 tracks x 72 detections, 14.0x vs CPU |
| GPU crowd swarm | 10,000 agents, uniform-grid neighbours, 105x vs CPU |
| GPU interaction graph risk | 2048 agents x 10 message-passing steps, 76.3x vs CPU |
| GPU SfM mini | 2048 features x 4 views, match + point BA, 217.0x vs CPU |
| GPU Jacobi-PCG sparse solver | 262K unknowns / 1.31M CSR nnz, 13.4x vs CPU |
| GPU EM GMM clustering | 262K points x 5 full-cov Gaussians, 90.2x vs CPU |
| GPU spectral clustering | 3072-point dense RBF graph, 40 subspace iterations, 193x vs CPU |
| GPU label propagation | 3072-node RBF graph, 12 seeds, 50 clamped iterations, 123x vs CPU |
| GPU traversability label propagation | 3072 graph nodes x 40 propagation iters, 33.47 ms, 79.9x vs CPU |
| GPU graph CRF traversability | 3072-node bilateral terrain graph x 32 mean-field iters, noisy unary 82.0% -> CRF 83.6%, 106x vs CPU |
| GPU GAT traversability policy | 3072 terrain nodes x 3 heads x 4 graph-attention layers, noisy unary 78.7% -> GAT 81.3%, 99.4x vs CPU |
- PythonRobotics
- Probabilistic Robotics
- Koide et al., MegaParticles: Range-based 6-DoF Monte Carlo Localization
- Datar, Immorlica, Indyk, Mirrokni, Locality-Sensitive Hashing Scheme Based on p-Stable Distributions (SoCG 2004)
- Fox, Adapting the Sample Size in Particle Filters Through KLD-Sampling (IJRR 2003); Augmented MCL: Thrun/Burgard/Fox, Probabilistic Robotics, Table 8.3
- Sünderhauf & Protzel, Switchable Constraints for Robust Pose Graph SLAM (IROS 2012)
- Diff-MPPI write-up:
paper/, ablations:paper/diff_mppi_*_followup.md - GitHub Pages gallery: https://rsasaki0109.github.io/CudaRobotics/