ARROW-4552: [JS] Add high-level Table and Column convenience methods #3634
Conversation
…rride static methods
…names and polymorphic chunk types
…r [Vector[], name | Field[]] arguments Supports creating tables from variable-length columns. Distributes inner chunks uniformly across RecordBatches without copying data (null bitmaps may be copied)
… columns by index
…concat, assign steps
Codecov Report
@@ Coverage Diff @@
## master #3634 +/- ##
==========================================
+ Coverage 87.7% 90.36% +2.65%
==========================================
Files 685 74 -611
Lines 83743 5325 -78418
Branches 1081 1200 +119
==========================================
- Hits 73449 4812 -68637
+ Misses 10183 504 -9679
+ Partials 111 9 -102
Continue to review full report at Codecov.
|
There was a problem hiding this comment.
This looks great, thanks!
I'm a little concerned about allowing users to create Tables from different length vectors though. Is that something that's allowed in the other implementations? It feels like a case where the user is probably making a mistake and we should throw an error.
js/src/table.ts
Outdated
| public static fromVectors<T extends { [key: string]: DataType; } = any>(vectors: VType<T[keyof T]>[], names?: (keyof T)[]) { | ||
| return new Table(RecordBatch.from(vectors, names)); | ||
| public static fromVectors<T extends { [key: string]: DataType; } = any>(vectors: Vector<T[keyof T]>[], fields?: (keyof T | Field<T[keyof T]>)[]) { | ||
| return Table.new<T>(vectors, fields); |
There was a problem hiding this comment.
I like the pattern where from methods are intended for conversions from other types and new methods are effectively constructors where we can use generics.
Do you think we should just go ahead and get rid of this to follow that pattern? or mark it deprecated or something? It's only been part of 0.4.0 for a couple of days I don't think anyone's using it.
There was a problem hiding this comment.
I'm down for either. I couldn't remember if this method predated 0.4 or not, so I left it unchanged.
There was a problem hiding this comment.
I think anyone would expect constructors instead of .new methods. Since we are pre 1.0 everything is fair game and you can be backwards incompatible in minor version bumps.
There was a problem hiding this comment.
@domoritz agreed, I say let's just rename this (and RecordBatch.from) as an overload of new, we haven't even put out a blog post or anything touting these functions in 0.4.0. We can just tout the new versions instead.
js/src/recordbatch.ts
Outdated
| vectors.reduce((len, vec) => Math.max(len, vec.length), 0), | ||
| vectors | ||
| ); | ||
| public static from<T extends { [key: string]: DataType } = any>(chunks: (Data<T[keyof T]> | Vector<T[keyof T]>)[], names: (keyof T)[] = []) { |
There was a problem hiding this comment.
Maybe this should also be deprecated in favor of a new version?
I don't agree that error-throwing would be appropriate here for two main reasons:
I'll clarify the behavior in this PR a bit further, since it's is really two features rolled into one. First, there's the re-chunking of the Table based on the chunk layout of the Columns we're joining. This features says if we're combining two columns of equal length into a table, the table will contain as many RecordBatches as the child with the most chunks. This is 100% zero-copy, since it's only slicing the Vectors and distributing them evenly by lowest common chunk size: a = Column.new('a', [1, 2, 3, 4, 5, 6])
b = Column.new('b', [1, 2, 3], [4, 5, 6])
assert(Table.new(a, b).chunks.length === 2)
// row_id | a | b ___
// 0 | 1 | 1 |
// 1 | 2 | 2 | <-- RecordBatch 1
// 2 | 3 | 3 ___|
// 3 | 4 | 4 |
// 4 | 5 | 5 | <-- RecordBatch 2
// 5 | 6 | 6 ___|I'm not certain whether it uses the same algorithm, but I think I recall @wesm mentioning the C++ implementation does support re-chunking. The second part deals with Columns of different lengths. For a = Column.new('a', [1, 2, 3, 4])
b = Column.new('b', [1, 2, 3], [4, 5, 6], [7, 8, 9])
assert(Table.new(a, b).chunks.length === 4)
// row_id | a | b ___
// 0 | 1 | 1 |
// 1 | 2 | 2 | <-- RecordBatch 1
// 2 | 3 | 3 ___|
// 3 | 4 | 4 ___| <-- RecordBatch 2
// 4 | null | 5 |
// 5 | null | 6 ___| <-- RecordBatch 3
// 6 | null | 7 |
// 7 | null | 8 | <-- RecordBatch 4
// 8 | null | 9 ___|This example illustrates both features working in concert:
|
|
Yeah I agree that the ability to pad short columns with nulls up to the length of the longest column is a nice bit of code to give our users when they need it, I'm just not sure it's always the right thing to do. We could still give this functionality to users somehow without making it the default. I really think most of the time someone is trying to create a Table from columns with an unequal length it's because they messed up somewhere, not because they want the shorter ones padded with nulls. All that being said, I did some tests with pandas and pyarrow to see how they handle this. pandas will let you create a DataFrame from unequal length Series: pyarrow does not, but pyarrow is lower-level than I think we are trying to target with arrow JS: Given the precedent in pandas I could relent on this point. |
|
@TheNeuralBit Yeah this behavior was inspired by pandas df.assign(). I do feel like padding with nulls is the friendliest way to go considering the alternatives -- if you accidentally combine some columns with uneven lengths and didn't mean to, you could always let vals = [1, 2, 3, 4, 5, 6, 7, 8, 9]
let table = Table.new(Column.new('a', vals.slice(0, 4)), Column.new('b', vals))
// correct the mistake
let a = table.getColumn('a').slice(0, 4)
let a2 = IntVector.new(vals.slice(4))
table.setColumn('a', a.concat(a2)) |
|
@domoritz I borrowed the const data = Data.Int(new Int64(), ...rest));
const vec = Vector.new(data); // vec type is inferred to Int64Vector
assert(vec instanceof Int64Vector) // true
assert(typeof vec.toBigInt64Array == 'function') // has any methods specific to the Int64Vector
assert(vec.toBigInt64Array() instanceof BigInt64Array) // true |
|
I see, that makes sense. I also think it's better not to have two different ways of initializing objects (constructors and |
|
@domoritz I forgot to mention the distinction between |
|
On the null-padding point: Maybe the right thing to do is to add a docstring and put a note about padding unequal length vectors. Then at least people browsing the API docs would know it's happening. |
|
What do you think about using |
|
I'd be fine with it if @trxcllnt is |
|
👍 for adding a note in the doc description 👎 for Relying on globals like |
|
Vega uses a tiny logger that users can override (https://github.com/vega/vega/blob/master/packages/vega-util/src/logger.js). Would it make sense for arrow to add a logger as well? |
|
@domoritz it looks like that's using the global Furthermore, I'm not convinced this is even warn-level behavior since it's only allocating a few bitmaps. Pandas doesn't warn here either. |
|
First, this is just the default logger and you can override it to print to something else. Second, I somewhat disagree that filling nulls when sizes mismatch is something that should go unnoticed. I think it is valuable to fill nulls but not showing any warnings will lead to errors that are hard to debug. I am okay with deferring this discussion but I feel that at some point arrow will need warnings. |
|
@domoritz I agree with you on principle, we will probably want to log things. I do think doing it in a way that's easy to configure externally is important, but outside the scope of this PR. Could you add a JIRA issue so someone can pick it up after this is merged? |
There was a problem hiding this comment.
I'm good with this once you address these items:
- Remove
Table.fromVectors, we'll direct users toTable.newinstead - Rename
RecordBatch.fromtonew(technically this did exist prior to 0.4, so if you'd rather just indicate it's deprecated somehow that's fine with me) - Add a docstring to
Table.newdescribing that it handles unequal length columns, but will allocate memory
053db43 to
1758063
Compare
|
@TheNeuralBit ok, I removed |
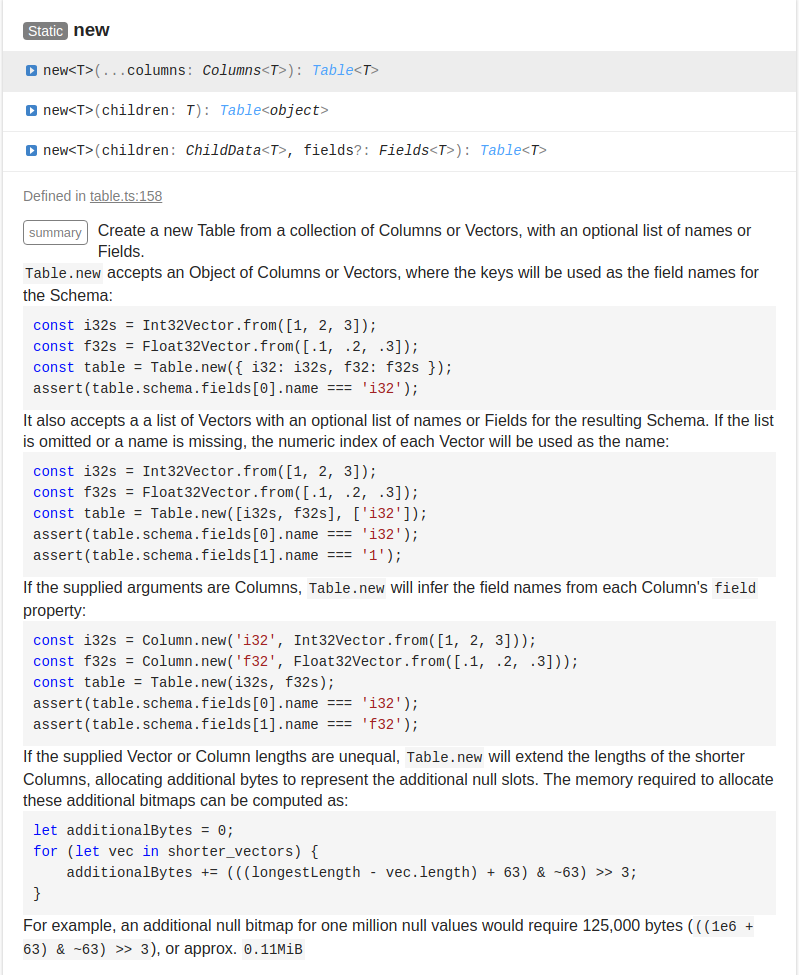
|
Perfect! thank you |
…support This started as a continuation of #3634, but grew enough to deserve its own PR. I've made a PR to my own fork that highlights just the changes here: trxcllnt#8. I'll rebase this PR after #3634 is merged so only these changes are included. This PR reverts the behavior of `Float16Vector#toArray()` back to returning a zero-copy slice of the underlying `Uint16Array` data, and exposes the copying behavior via new `toFloat32Array()` and `toFloat64Array()` methods. `Float16Array.from()` will also convert any incoming 32 or 64-bit floats to Uint16s if necessary. It also adds tighter integration with the new `BigInt`, `BigInt64Array`, and `BigUint64Array` primitives (if available): 1. Use the native `BigInt` to convert/stringify i64s/u64s 2. Support the `BigInt` type in element comparator and `indexOf()` 3. Add zero-copy `toBigInt64Array()` and `toBigUint64Array()` methods to `Int64Vector` and `Uint64Vector`, respectively 0.4.0 added support for basic conversion to the native `BigInt` when available, but would only create positive `BigInts`, and was slower than necessary. This PR uses the native Arrays to create the BigInts, so we should see some speed ups there. Ex: ```ts const vec = Int64Vector.from(new Int32Array([-1, 2147483647])) const big = vec.get(0) assert(big[0] === -1) // true assert(big[1] === 2147483647) // true const num = 0n + big // or BigInt(big) assert(num === (2n ** 63n - 1n)) // true ``` JIRAs associated with this PR are: * [ARROW-4578](https://issues.apache.org/jira/browse/ARROW-4578) - Float16Vector toArray should be zero-copy * [ARROW-4579](https://issues.apache.org/jira/browse/ARROW-4579) - Add more interop with BigInt/BigInt64Array/BigUint64Array * [ARROW-4580](https://issues.apache.org/jira/browse/ARROW-4580) - Accept Iterables in IntVector/FloatVector from() signatures Author: ptaylor <paul.e.taylor@me.com> Closes #3653 from trxcllnt/js/int-and-float-fixes and squashes the following commits: 69ee6f7 <ptaylor> cleanup after rebase f44e97b <ptaylor> ensure truncated bitmap size isn't larger than it should be 7ac081a <ptaylor> fix lint 6046e66 <ptaylor> remove more getters in favor of readonly direct property accesses 94d5633 <ptaylor> support BigInt in comparitor/indexOf 760a219 <ptaylor> update BN to use BigIntArrays for signed/unsigned 64bit integers if possible 77fcd40 <ptaylor> add initial BigInt64Array and BigUint64Array support d561204 <ptaylor> ensure Float16Vector.toArray() is zero-copy again, add toFloat32Array() and toFloat64Array() methods instead 854ae66 <ptaylor> ensure Int/FloatVector.from return signatures are as specific as possible, and accept Iterable<number> 4656ea5 <ptaylor> cleanup/rename Table + Schema + RecordBatch from -> new, cleanup argument extraction util fns 69abf40 <ptaylor> add initial RecordBatch.new and select tests 9c7ed3d <ptaylor> guard against out-of-bounds selections a4222f8 <ptaylor> clean up: eliminate more getters in favor of read-only properties 8eabb1c <ptaylor> clean up/speed up: move common argument flattening methods into a utility file b3b4f1f <ptaylor> add Table and Schema assign() impls 79f9db1 <ptaylor> add selectAt() method to Table, Schema, and RecordBatch for selecting columns by index
…support This started as a continuation of apache/arrow#3634, but grew enough to deserve its own PR. I've made a PR to my own fork that highlights just the changes here: trxcllnt/arrow#8. I'll rebase this PR after apache/arrow#3634 is merged so only these changes are included. This PR reverts the behavior of `Float16Vector#toArray()` back to returning a zero-copy slice of the underlying `Uint16Array` data, and exposes the copying behavior via new `toFloat32Array()` and `toFloat64Array()` methods. `Float16Array.from()` will also convert any incoming 32 or 64-bit floats to Uint16s if necessary. It also adds tighter integration with the new `BigInt`, `BigInt64Array`, and `BigUint64Array` primitives (if available): 1. Use the native `BigInt` to convert/stringify i64s/u64s 2. Support the `BigInt` type in element comparator and `indexOf()` 3. Add zero-copy `toBigInt64Array()` and `toBigUint64Array()` methods to `Int64Vector` and `Uint64Vector`, respectively 0.4.0 added support for basic conversion to the native `BigInt` when available, but would only create positive `BigInts`, and was slower than necessary. This PR uses the native Arrays to create the BigInts, so we should see some speed ups there. Ex: ```ts const vec = Int64Vector.from(new Int32Array([-1, 2147483647])) const big = vec.get(0) assert(big[0] === -1) // true assert(big[1] === 2147483647) // true const num = 0n + big // or BigInt(big) assert(num === (2n ** 63n - 1n)) // true ``` JIRAs associated with this PR are: * [ARROW-4578](https://issues.apache.org/jira/browse/ARROW-4578) - Float16Vector toArray should be zero-copy * [ARROW-4579](https://issues.apache.org/jira/browse/ARROW-4579) - Add more interop with BigInt/BigInt64Array/BigUint64Array * [ARROW-4580](https://issues.apache.org/jira/browse/ARROW-4580) - Accept Iterables in IntVector/FloatVector from() signatures Author: ptaylor <paul.e.taylor@me.com> Closes #3653 from trxcllnt/js/int-and-float-fixes and squashes the following commits: 69ee6f77 <ptaylor> cleanup after rebase f44e97b3 <ptaylor> ensure truncated bitmap size isn't larger than it should be 7ac081ad <ptaylor> fix lint 6046e660 <ptaylor> remove more getters in favor of readonly direct property accesses 94d56334 <ptaylor> support BigInt in comparitor/indexOf 760a2199 <ptaylor> update BN to use BigIntArrays for signed/unsigned 64bit integers if possible 77fcd402 <ptaylor> add initial BigInt64Array and BigUint64Array support d561204e <ptaylor> ensure Float16Vector.toArray() is zero-copy again, add toFloat32Array() and toFloat64Array() methods instead 854ae66f <ptaylor> ensure Int/FloatVector.from return signatures are as specific as possible, and accept Iterable<number> 4656ea55 <ptaylor> cleanup/rename Table + Schema + RecordBatch from -> new, cleanup argument extraction util fns 69abf406 <ptaylor> add initial RecordBatch.new and select tests 9c7ed3d4 <ptaylor> guard against out-of-bounds selections a4222f81 <ptaylor> clean up: eliminate more getters in favor of read-only properties 8eabb1c0 <ptaylor> clean up/speed up: move common argument flattening methods into a utility file b3b4f1fd <ptaylor> add Table and Schema assign() impls 79f9db1c <ptaylor> add selectAt() method to Table, Schema, and RecordBatch for selecting columns by index
…support This started as a continuation of apache/arrow#3634, but grew enough to deserve its own PR. I've made a PR to my own fork that highlights just the changes here: trxcllnt/arrow#8. I'll rebase this PR after apache/arrow#3634 is merged so only these changes are included. This PR reverts the behavior of `Float16Vector#toArray()` back to returning a zero-copy slice of the underlying `Uint16Array` data, and exposes the copying behavior via new `toFloat32Array()` and `toFloat64Array()` methods. `Float16Array.from()` will also convert any incoming 32 or 64-bit floats to Uint16s if necessary. It also adds tighter integration with the new `BigInt`, `BigInt64Array`, and `BigUint64Array` primitives (if available): 1. Use the native `BigInt` to convert/stringify i64s/u64s 2. Support the `BigInt` type in element comparator and `indexOf()` 3. Add zero-copy `toBigInt64Array()` and `toBigUint64Array()` methods to `Int64Vector` and `Uint64Vector`, respectively 0.4.0 added support for basic conversion to the native `BigInt` when available, but would only create positive `BigInts`, and was slower than necessary. This PR uses the native Arrays to create the BigInts, so we should see some speed ups there. Ex: ```ts const vec = Int64Vector.from(new Int32Array([-1, 2147483647])) const big = vec.get(0) assert(big[0] === -1) // true assert(big[1] === 2147483647) // true const num = 0n + big // or BigInt(big) assert(num === (2n ** 63n - 1n)) // true ``` JIRAs associated with this PR are: * [ARROW-4578](https://issues.apache.org/jira/browse/ARROW-4578) - Float16Vector toArray should be zero-copy * [ARROW-4579](https://issues.apache.org/jira/browse/ARROW-4579) - Add more interop with BigInt/BigInt64Array/BigUint64Array * [ARROW-4580](https://issues.apache.org/jira/browse/ARROW-4580) - Accept Iterables in IntVector/FloatVector from() signatures Author: ptaylor <paul.e.taylor@me.com> Closes #3653 from trxcllnt/js/int-and-float-fixes and squashes the following commits: 69ee6f77 <ptaylor> cleanup after rebase f44e97b3 <ptaylor> ensure truncated bitmap size isn't larger than it should be 7ac081ad <ptaylor> fix lint 6046e660 <ptaylor> remove more getters in favor of readonly direct property accesses 94d56334 <ptaylor> support BigInt in comparitor/indexOf 760a2199 <ptaylor> update BN to use BigIntArrays for signed/unsigned 64bit integers if possible 77fcd402 <ptaylor> add initial BigInt64Array and BigUint64Array support d561204e <ptaylor> ensure Float16Vector.toArray() is zero-copy again, add toFloat32Array() and toFloat64Array() methods instead 854ae66f <ptaylor> ensure Int/FloatVector.from return signatures are as specific as possible, and accept Iterable<number> 4656ea55 <ptaylor> cleanup/rename Table + Schema + RecordBatch from -> new, cleanup argument extraction util fns 69abf406 <ptaylor> add initial RecordBatch.new and select tests 9c7ed3d4 <ptaylor> guard against out-of-bounds selections a4222f81 <ptaylor> clean up: eliminate more getters in favor of read-only properties 8eabb1c0 <ptaylor> clean up/speed up: move common argument flattening methods into a utility file b3b4f1fd <ptaylor> add Table and Schema assign() impls 79f9db1c <ptaylor> add selectAt() method to Table, Schema, and RecordBatch for selecting columns by index
This PR closes the following JIRAs:
assign(other)implementationsselectAt(...indices)methodI extracted a few more high-level helper methods I've had laying around for creating, selecting, or manipulating Tables/Columns/Schemas/RecordBatches.
table.select(...colNames)implementation, so I also added atable.selectAt(...colIndices)method to complement. Super handy when you have duplicates.table.assign(otherTable)impl. I added logic to compare Schemas/Fields/DataTypes in order to de-dupe reliably, which lives in theTypeComparatorVisitor. I expose this viacompareTo()methods on the Schema, Field, and DataType for ease of use. Bonus: the Writer can now discern between RecordBatches of the same stream whose Schemas aren't reference-equal.Table#assign()impl. I say nearly zero-copy, because there's a bit of allocation/copying to backfill null bitmaps if chunks don't exactly line up. But this also means it's a bit easier now to create Tables or RecordBatches from values in-memory whose lengths may not exactly line up:(cc: @domoritz)