轻快、简明、高效、精确的深度学习图像目标检测
- 使用如下命令,从Gitee拉取世杰分享的项目源码:
git clone https://github.com/zhongshijie1995/light_object_detection.git
- 接下来的所有操作,都在该项目下进行
cd LightObjectDetection
- 编译项目
make
- 下载yolov3模型的权重
wget https://pjreddie.com/media/files/yolov3.weights
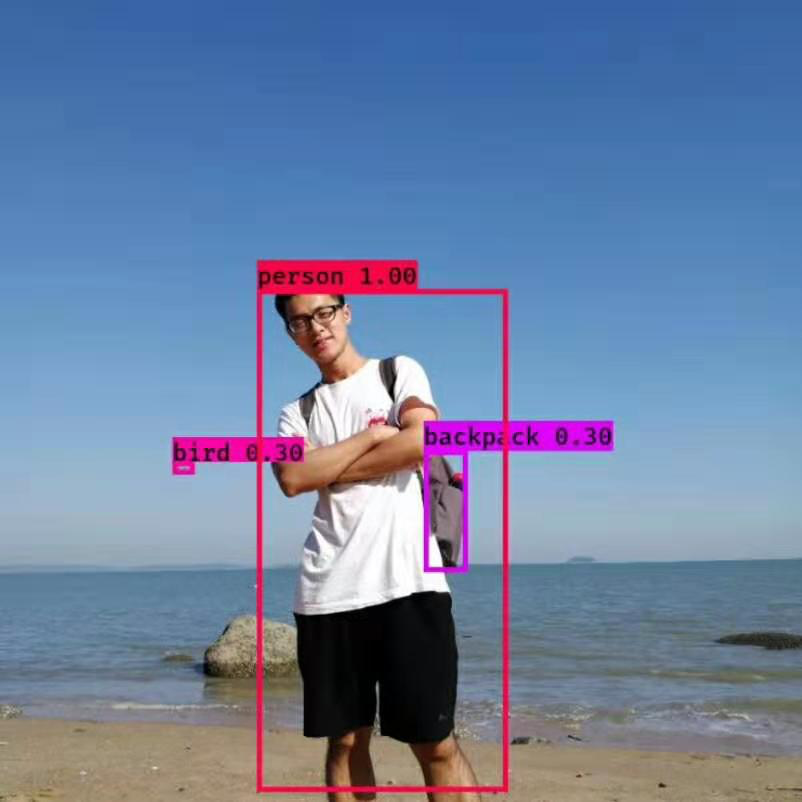
- 运行开始体验的python脚本
python3 sc_start_experience.py
- 查看结果
fim predictions.jpg
wget https://pjreddie.com/media/files/darknet53.conv.74
- 启动标注工具集
pip3 install labelImg
labelImg
- 点击VOC以选择YOLO模式,并进行标注
- 完成
#####(方法2)自己制作数据集
- 实际上,我们需要的数据集格式是每一张图片对应一个.txt标签文件,其中包含以下信息:
<对象的序号> <对象中心点的x坐标> <想象中心点的y坐标> <对象的宽度> <对象的高度>
...
...
- 将上述提及的分类配置、标签文件、图片(相同文件名,不同后缀名)以放入项目的如下结构中
- LightObjectDetection
- train_data
- classes.txt
- a.jpg
- a.txt
- b.jpg
- b.txt
- 完成!
- 对开始训练的脚本进行设置,并运行!就这么简单!
python3 sc_start_train.py
- 输入参数 Run with GPU?(y or n) How large is each batch?(Integer) How many batches? (Integer)
- 静待声名远扬的yolo3的运行
还记得编译项目之后的上手体验吗?有了模型和训练出来的权重,你应该能完成了!