rust 实现三个json parser,作为编译原理练习的小玩具
- JSON文法的分词器
- 三个JSON文法的解析器
- JSON格式化,用于将JSON解析后美化输出
- 重载了下标访问
[],像python一样轻松访问JSON对象
Value -> Array | Object | String | Number | Bool | Null
Array -> [Value ValueList]
Array -> []
ValueList -> , Value ValueList
ValueList -> ε
Object -> { Pair PairList }
Object -> {}
PairList -> , Pair PairList
PairList -> ε
Pair -> String : Value
起始符号为Value,终结符为[, ], {, }, :, ,, Bool, Null, String, Number。
Note: 以上文法描述使用了扩展巴科斯范式,其中
|表示或,ε表示空,但[]和{}仅仅表示符号本身
Note: 本文法的命名并没有完全遵循JSON标准使用的命名,但不影响最终结果
实现了Lexer用于分词,三个parser,为IndefiniteParser, DefiniteParser, TableDrivenParser
,分别对应不确定的递归下降分析,确定的递归下降分析,表驱动分析。
参照src/main.rs中的使用方法,将json_str换成你想要解析的json字符串即可
不确定的自顶向下分析器可以直接使用原JSON文法进行分析,包括尝试应用产生式消耗token,遇到错误后回溯的过程
原JSON文法存在左递归,可以进行等价转换,消除左递归得到一个LL1的文法
转换后得到的文法:
TOKEN: [ { } ] , : string number bool null
Value -> [ Array' | { Object' | string | number | bool | null
Array' -> ] | Value ValueList ]
ValueList -> , Value ValueList | ε
Object' -> } | Pair PairList }
PairList -> , Pair PairList | ε
Pair -> string : Value
分别计算非终结符的FIRST集和FOLLOW集
| set | Value | Array' | Object' | ValueList | PairList | Pair |
|---|---|---|---|---|---|---|
| FIRST | [{ string number bool null | ][{ string number bool null | } string | , ε | , ε | string |
| FOLLOW | , # ] } | # , ] | , # ] } | ] | } | , } |
Note:
#表示输入token的结束符
再计算其SELECT集
Value
SELECT(Value -> [ Array') = [SELECT(Value -> { Object') = {SELECT(Value -> string) = stringSELECT(Value -> number) = numberSELECT(Value -> bool) = boolSELECT(Value -> null) = null
Array'
SELECT(Array' -> ]) = ]SELECT(Array' -> Value ValueList]) = string number bool null [ {
ValueList
SELECT(ValueList -> , Value ValueList) = ,SELECT(ValueList -> ε) = \emptyset and FOLLOW(ValueList) = ]
Object'
SELECT(Object' -> }) = }SELECT(Object' -> Pair PairList}) = string
PairList
SELECT(PairList -> , Pair PairList) = ,SELECT(PairList -> ε) = \emptyset and FOLLOW(PairList) = }
Pair
SELECT(Pair -> string : Value) = string
同一个非终结符的所有产生式的SELECT集的交集为空,因此这个文法是LL1,可以使用递归下降
递归下降存在一个问题,对于一个元素很多的数组、键值对很多的对象,递归下降会递归地解析每一个元素或键值对,数据量大时容易爆栈,使用表驱动即可避免
分别将以上SELECT集进行编号
Value(0 - 5)
SELECT(Value -> [ Array') = [SELECT(Value -> { Object') = {SELECT(Value -> string) = stringSELECT(Value -> number) = numberSELECT(Value -> bool) = boolSELECT(Value -> null) = null
Array'(6 - 7)
SELECT(Array' -> ]) = ]SELECT(Array' -> Value ValueList]) = string number bool null [ {
ValueList(8 - 9)
SELECT(ValueList -> , Value ValueList) = ,SELECT(ValueList -> ε) = \emptyset and FOLLOW(ValueList) = ]
Object'(10 - 11)
SELECT(Object' -> }) = }SELECT(Object' -> Pair PairList}) = string
PairList(12 - 13)
SELECT(PairList -> , Pair PairList) = ,SELECT(PairList -> ε) = \emptyset and FOLLOW(PairList) = }
Pair(14)
SELECT(Pair -> string : Value) = string
分别为终结符起名为LBRACE RBRACE LBRACKET RBRACKET COMMA COLON STRING NUMBER BOOL NULL EPSILON
建立预测分析表
| noterminal | LBRACE | RBRACE | LBRACKET | RBRACKET | COMMA | COLON | STRING | NUMBER | BOOL | NULL | EPSILON |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Value | 1 | -1 | 0 | -1 | -1 | -1 | 2 | 3 | 4 | 5 | -1 |
| Array1 | 7 | -1 | 7 | 6 | -1 | -1 | 7 | 7 | 7 | 7 | -1 |
| ValueList | -1 | -1 | -1 | 9 | 8 | -1 | -1 | -1 | -1 | -1 | -1 |
| Object1 | -1 | 10 | -1 | -1 | -1 | -1 | 11 | -1 | -1 | -1 | -1 |
| PairList | -1 | 13 | -1 | -1 | 12 | -1 | -1 | -1 | -1 | -1 | -1 |
| Pair | -1 | -1 | -1 | -1 | -1 | -1 | 14 | -1 | -1 | -1 | -1 |
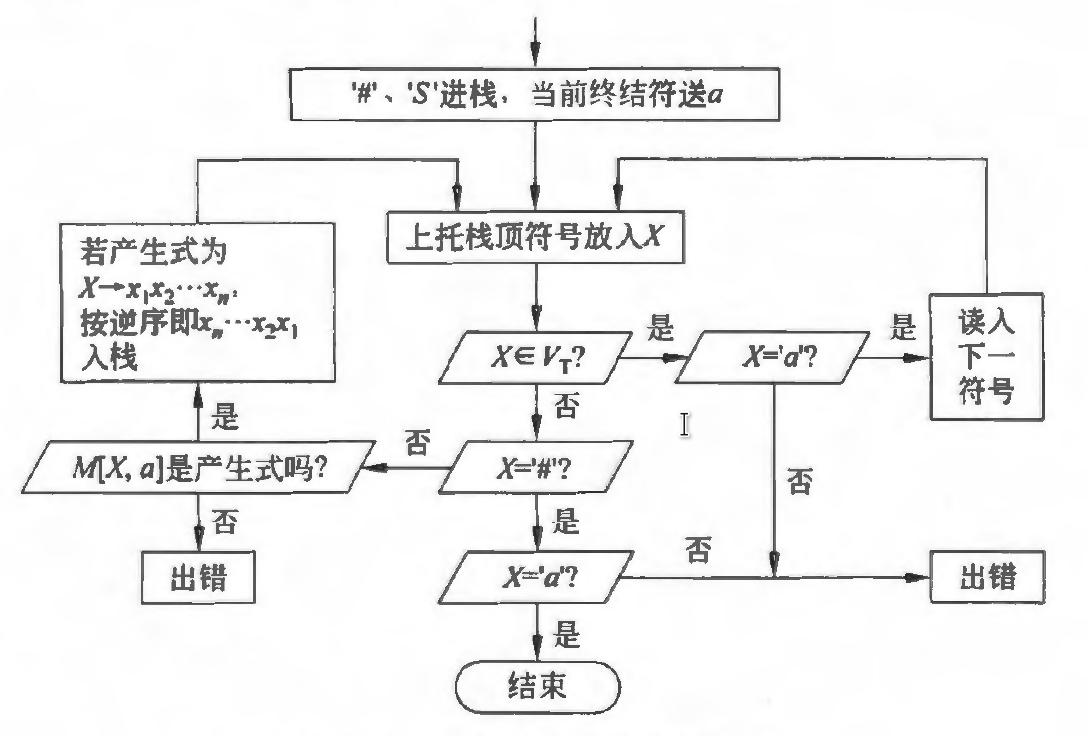
表驱动分析由分析程序、栈、预测分析表组成
设预测表是一个名为TABLE的二维数组,TABLE[i][j]表示当栈顶符号为i,输入符号为j时,应该使用的产生式编号,-1表示错误
分析程序逻辑如下:
- 当栈顶为终结符时,如果输入符号与栈顶符号相同,会消耗此符号并弹栈
- 当栈顶为非终结符时,查预测分析表确定应该使用的产生式,将产生式右部逆序压栈
- 当栈顶为
#,输入符号也为#时,分析完成
表驱动parser 99ms解析一个49M的JSON文件
