低代码数据准备
目前,您可以使用 DataPrep 来:
- 从常见数据源收集数据(通过
dataprep.connector) - 进行探索性数据分析(通过
dataprep.eda) - 清理和标准化数据(通过
dataprep.clean) - ...更多模块即将推出
| 回购协议 | 版本 | 下载 |
|---|---|---|
| 皮伊 | ||
| 康达锻造公司 |
pip install -U dataprep
DataPrep.EDA 是 Python 中最快、最简单的 EDA(探索性数据分析)工具。它允许您在几秒钟内通过几行代码理解 Pandas/Dask DataFrame。
您可以使用该函数从 Pandas/Dask DataFrame 创建漂亮的配置文件报告create_report。DataPrep.EDA与其他工具相比具有以下优点:
- 速度快 10 倍:由于其高度优化的基于 Dask 的计算模块,DataPrep.EDA 的速度比基于 Pandas 的分析工具快 10 倍。
- 交互式可视化:DataPrep.EDA 在报告中生成交互式可视化,这使得报告对最终用户更具吸引力。
- 大数据支持:DataPrep.EDA 通过接受 Dask 数据帧作为输入,自然支持存储在 Dask 集群中的大数据。
以下代码演示了如何使用 DataPrep.EDA 为 titanic 数据集创建配置文件报告。
from dataprep.datasets import load_dataset from dataprep.eda import create_report df = load_dataset("titanic") create_report(df).show_browser()
单击此处查看上述代码生成的报告。
单击此处查看基准测试结果。
在线尝试 DataPrep.EDA:Colab 中的 DataPrep.EDA 演示
DataPrep.EDA 是Python 中唯一以任务为中心的 EDA 系统。它经过精心设计,旨在提高可用性。
- 以任务为中心的 API 设计:您可以通过单个函数调用以声明方式指定不同粒度的各种 EDA 任务。所有需要的可视化效果都会自动、智能地为您生成。
- 自动洞察:DataPrep.EDA 自动检测并突出显示洞察(例如,列有许多异常值),以促进有关数据的模式发现。
- 操作指南:提供了操作指南来显示每个绘图功能的配置。通过此功能,您可以轻松自定义生成的可视化效果。

单击此处查看所有支持的任务。
检查plot、plot_correlation、plot_missing和create_report以了解每个函数的工作原理。
DataPrep.Clean 包含大约140 多个函数,旨在清理和验证 DataFrame 中的数据。它提供
- 方便的 GUI:合并到 Jupyter Notebook 中,用户无需任何编码即可清理自己的 DataFrame(请参见下面的视频)。
- 统一的 API:每个函数都遵循语法
clean_{type}(df, 'column name')(请参阅下面的示例)。 - 速度:使用 Dask 并行计算。它可以在双核笔记本电脑上每秒清理 50K 行(这意味着只需 20 秒即可清理 100 万行)。
- 透明度:生成一份报告,总结清洁期间发生的数据更改。
以下视频展示了如何使用 Dataprep.Clean 的 GUI

以下示例演示如何清理和标准化国家/地区名称列。
from dataprep.clean import clean_country import pandas as pd df = pd.DataFrame({'country': ['USA', 'country: Canada', '233', ' tr ', 'NA']}) df2 = clean_country(df, 'country') df2 country country_clean 0 USA United States 1 country: Canada Canada 2 233 Estonia 3 tr Turkey 4 NA NaN
还支持类型验证:
from dataprep.clean import validate_country series = validate_country(df['country']) series 0 True 1 False 2 True 3 True 4 False Name: country, dtype: bool
检查Dataprep.Clean 的文档以了解每个函数的工作原理。
连接器现在支持从 Web API 和数据库加载数据。
Connector 是一个直观的开源 API 包装器,它通过将对多个 API 的调用标准化为简单的工作流程来加快开发速度。
Connector 提供了一个简单的包装器来从不同的 Web API(例如 Twitter、Spotify)收集结构化数据,使 Web 数据收集变得简单高效,无需高级编程技能。
您想利用越来越多的通过公共 API 开放数据的网站吗?连接器适合您!
让我们看看 Connector 提供的几个好处:
- 统一的API:只需一两行代码即可获取数十个热门网站的数据。
- 自动分页:您是否想要调用可以返回大型结果集并需要通过分页处理它的 Web API?连接器会自动为您进行分页!只需指定所需的返回结果数量(参数
_count),而无需了解有关特定分页方案的不必要的细节。 - 速度:您是否想通过向 Web API 发出并发请求来更快地获取结果?通过该
_concurrency参数,Connector 简化了并发性,并行发出 API 请求,同时遵守 API 的速率限制策略。
from dataprep.connector import connect conn_dblp = connect("dblp", _concurrency = 5) df = await conn_dblp.query("publication", author = "Andrew Y. Ng", _count = 2000)
在这里,您可以找到详细的示例。
连接器的设计易于扩展。如果你想连接自己的Web API,你只需要编写一个简单的配置文件来支持它。该配置文件描述了API的主要属性,如URL、查询参数、授权方法、分页属性等。
Connector 现在已经采用了connectorx,以便能够以最快和最有效内存的方式将数据从数据库(Postgres、Mysql、SQLServer 等)加载到Python 数据帧(pandas、dask、modin、arrow、polars)中。[基准]
你需要做的只是安装connectorx(pip install -U connectorx)并运行一行代码:
from dataprep.connector import read_sql read_sql("postgresql://username:password@server:port/database", "SELECT * FROM lineitem")
在此处查看支持的数据库和数据框以及更多示例用法。
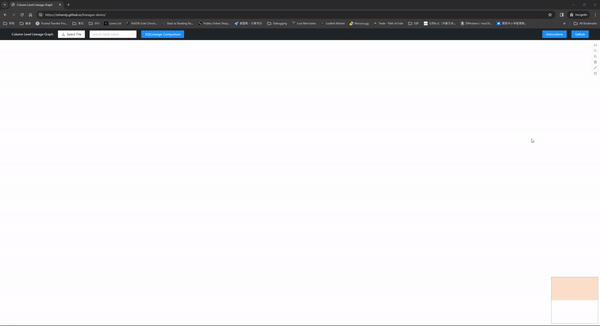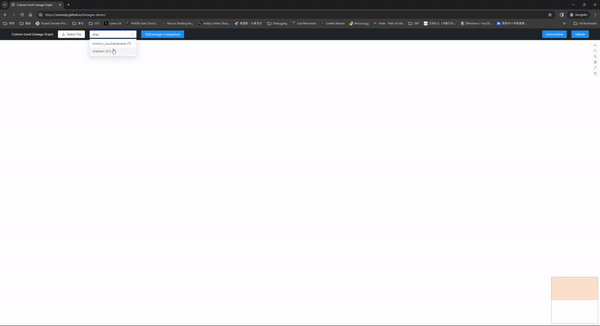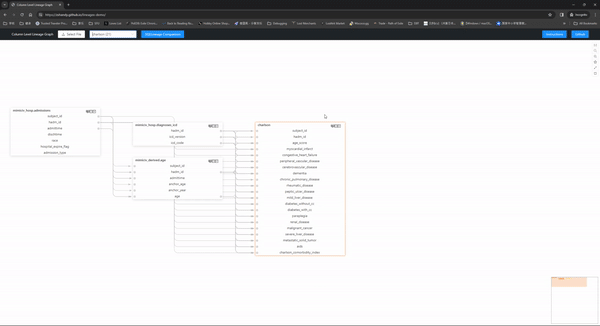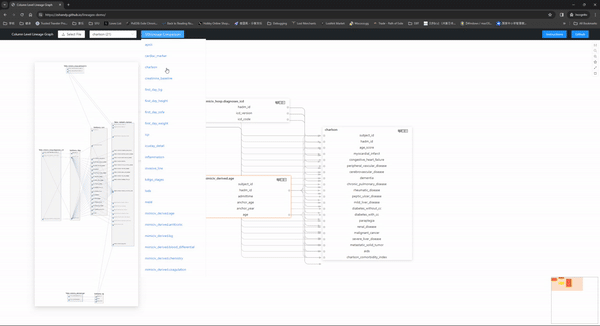
SQL 的列级沿袭图。该工具旨在帮助您在网页上创建交互式图表来探索其中的列级别沿袭。
可以在这篇博文中找到该项目的一般介绍。
- 自动依赖关系创建:当SQL文件之间存在依赖关系,并且这些表尚未在数据库中时,lineage模块将自动尝试查找依赖关系表并创建它。
- 干净、简单但交互性很强的用户界面:用户界面使用起来非常简单,页面上的混乱程度最小,同时显示了所有必要的信息。
- 多种SQL语句:lineage模块支持多种SQL语句,除了典型的
SELECT语句外,还支持CREATE TABLE/VIEW [IF NOT EXISTS]statement以及INSERTandDELETE语句。 - dbt支持:lineage 模块也在dbt-LineageX中实现,它被添加到 dbt 项目中,并通过使用 dbt 库fal,它能够重用 Python 核心并从 dbt 项目创建类似的输出。
<span data-target="animated-image.imageContainer">
<img data-target="animated-image.replacedImage" alt="example.gif" class="AnimatedImagePlayer-animatedImage" src="https://raw.githubusercontent.com/sfu-db/lineagex/main/docs/example.gif" style="display: block; opacity: 1;">
<canvas class="AnimatedImagePlayer-stillImage" aria-hidden="true" width="814" height="442"></canvas></span></a>
<button data-target="animated-image.imageButton" class="AnimatedImagePlayer-images" tabindex="-1" aria-label="Play example.gif" hidden=""></button>
<span class="AnimatedImagePlayer-controls" data-target="animated-image.controls" hidden="">
<button data-target="animated-image.playButton" class="AnimatedImagePlayer-button" aria-label="Play example.gif">
<svg aria-hidden="true" focusable="false" class="octicon icon-play" width="16" height="16" viewBox="0 0 16 16" fill="none" xmlns="http://www.w3.org/2000/svg">
<path d="M4 13.5427V2.45734C4 1.82607 4.69692 1.4435 5.2295 1.78241L13.9394 7.32507C14.4334 7.63943 14.4334 8.36057 13.9394 8.67493L5.2295 14.2176C4.69692 14.5565 4 14.1739 4 13.5427Z">
</path></svg>
<svg aria-hidden="true" focusable="false" class="octicon icon-pause" width="16" height="16" viewBox="0 0 16 16" xmlns="http://www.w3.org/2000/svg">
<rect x="4" y="2" width="3" height="12" rx="1"></rect>
<rect x="9" y="2" width="3" height="12" rx="1"></rect>
</svg>
</button>
<a data-target="animated-image.openButton" aria-label="Open example.gif in new window" class="AnimatedImagePlayer-button" href="https://raw.githubusercontent.com/sfu-db/lineagex/main/docs/example.gif" target="_blank">
<svg aria-hidden="true" class="octicon" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 16 16" width="16" height="16">
<path fill-rule="evenodd" d="M10.604 1h4.146a.25.25 0 01.25.25v4.146a.25.25 0 01-.427.177L13.03 4.03 9.28 7.78a.75.75 0 01-1.06-1.06l3.75-3.75-1.543-1.543A.25.25 0 0110.604 1zM3.75 2A1.75 1.75 0 002 3.75v8.5c0 .966.784 1.75 1.75 1.75h8.5A1.75 1.75 0 0014 12.25v-3.5a.75.75 0 00-1.5 0v3.5a.25.25 0 01-.25.25h-8.5a.25.25 0 01-.25-.25v-8.5a.25.25 0 01.25-.25h3.5a.75.75 0 000-1.5h-3.5z"></path>
</svg>
</a>
</span>
</span></animated-image><font style="vertical-align: inherit;"><font style="vertical-align: inherit;">
这是一个带有imit-ivconcepts_postgres文件(导航指令)的现场演示,它是用一行代码创建的:
from dataprep.lineage import lineagex lineagex(sql=path/to/sql, target_schema="schema1", conn_string="postgresql://username:password@server:port/database", search_path_schema="schema1, public")
在这里查看更详细的用法和示例。
以下文档可以让您了解 DataPrep 的功能:
有很多方法可以为 DataPrep 做出贡献。
- 提交错误并帮助我们在签入修复后验证修复。
- 查看源代码更改。
- 与 StackOverflow 上的其他 DataPrep 用户和开发人员互动。
- 在我们的论坛中提出问题并提出新想法。
- 贡献错误修复。
- 提供用例并写下您的用户体验。
请查看我们的wiki来获取开发文档!
DataPrep 的一些功能受到以下软件包的启发。
如果您使用 DataPrep,请考虑引用以下论文:
Jinglin Peng、Weiyuan Wu、Brandon Lockhart、Song Bian、Jing Nathan Yan、Linghao Xu、Zhixuan Chi、Jeffrey M. Rzeszotarski 和Jiannan Wang。DataPrep.EDA:Python 中统计建模的以任务为中心的探索性数据分析。 SIGMOD 2021。
BibTeX 条目:
@inproceedings{dataprepeda2021, author = {Jinglin Peng and Weiyuan Wu and Brandon Lockhart and Song Bian and Jing Nathan Yan and Linghao Xu and Zhixuan Chi and Jeffrey M. Rzeszotarski and Jiannan Wang}, title = {DataPrep.EDA: Task-Centric Exploratory Data Analysis for Statistical Modeling in Python}, booktitle = {Proceedings of the 2021 International Conference on Management of Data (SIGMOD '21), June 20--25, 2021, Virtual Event, China}, year = {2021} }