Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Implement parallel scatter reductions for CPU (pytorch#36447)
Summary: This PR implements pytorchgh-33389. As a result of this PR, users can now specify various reduction modes for scatter operations. Currently, `add`, `subtract`, `multiply` and `divide` have been implemented, and adding new ones is not hard. While we now allow dynamic runtime selection of reduction modes, the performance is the same as as was the case for the `scatter_add_` method in the master branch. Proof can be seen in the graph below, which compares `scatter_add_` in the master branch (blue) and `scatter_(reduce="add")` from this PR (orange). 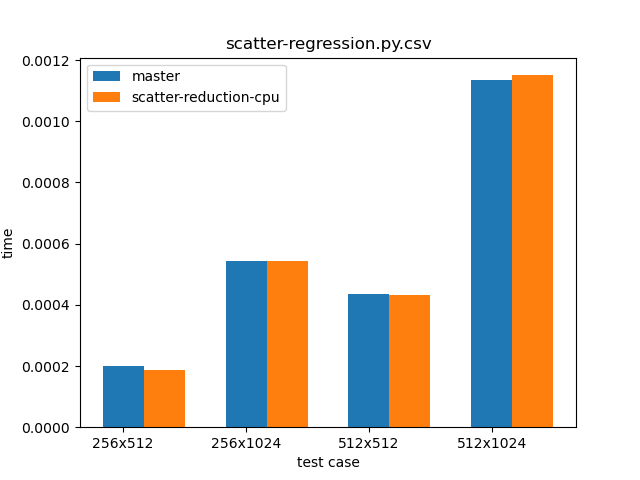 The script used for benchmarking is as follows: ``` python import os import sys import torch import time import numpy from IPython import get_ipython Ms=256 Ns=512 dim = 0 top_power = 2 ipython = get_ipython() plot_name = os.path.basename(__file__) branch = sys.argv[1] fname = open(plot_name + ".csv", "a+") for pM in range(top_power): M = Ms * (2 ** pM) for pN in range(top_power): N = Ns * (2 ** pN) input_one = torch.rand(M, N) index = torch.tensor(numpy.random.randint(0, M, (M, N))) res = torch.randn(M, N) test_case = f"{M}x{N}" print(test_case) tobj = ipython.magic("timeit -o res.scatter_(dim, index, input_one, reduce=\"add\")") fname.write(f"{test_case},{branch},{tobj.average},{tobj.stdev}\n") fname.close() ``` Additionally, one can see that various reduction modes take almost the same time to execute: ``` op: add 70.6 µs ± 27.3 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 26.1 µs ± 26.5 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) op: subtract 71 µs ± 20.5 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 26.4 µs ± 34.4 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) op: multiply 70.9 µs ± 31.5 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 27.4 µs ± 29.3 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) op: divide 164 µs ± 48.8 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 52.3 µs ± 132 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) ``` Script: ``` python import torch import time import numpy from IPython import get_ipython ipython = get_ipython() nrows = 3000 ncols = 10000 dims = [nrows, ncols] res = torch.randint(5, 10, dims) idx1 = torch.randint(dims[0], (1, dims[1])).long() src1 = torch.randint(5, 10, (1, dims[1])) idx2 = torch.randint(dims[1], (dims[0], 1)).long() src2 = torch.randint(5, 10, (dims[0], 1)) for op in ["add", "subtract", "multiply", "divide"]: print(f"op: {op}") ipython.magic("timeit res.scatter_(0, idx1, src1, reduce=op)") ipython.magic("timeit res.scatter_(1, idx2, src2, reduce=op)") ``` Pull Request resolved: pytorch#36447 Differential Revision: D22272631 Pulled By: ngimel fbshipit-source-id: 3cdb46510f9bb0e135a5c03d6d4aa5de9402ee90
{kind=link}
- Loading branch information
1 parent
11a74a5
commit 9ca4a46