

Horovod is a distributed training framework for TensorFlow, Keras, PyTorch, and MXNet. The goal of Horovod is to make distributed Deep Learning fast and easy to use.

Horovod is hosted by the LF AI Foundation (LF AI). If you are a company that is deeply committed to using open source technologies in artificial intelligence, machine and deep learning, and wanting to support the communities of open source projects in these domains, consider joining the LF AI Foundation. For details about who's involved and how Horovod plays a role, read the LF AI announcement.
Contents
The primary motivation for this project is to make it easy to take a single-GPU TensorFlow program and successfully train it on many GPUs faster. This has two aspects:
- How much modification does one have to make to a program to make it distributed, and how easy is it to run it?
- How much faster would it run in distributed mode?
Internally at Uber we found the MPI model to be much more straightforward and require far less code changes than the Distributed TensorFlow with parameter servers. See the Usage section for more details.
In addition to being easy to use, Horovod is fast. Below is a chart representing the benchmark that was done on 128 servers with 4 Pascal GPUs each connected by RoCE-capable 25 Gbit/s network:

Horovod achieves 90% scaling efficiency for both Inception V3 and ResNet-101, and 68% scaling efficiency for VGG-16. See the Benchmarks page to find out how to reproduce these numbers.
While installing MPI and NCCL itself may seem like an extra hassle, it only needs to be done once by the team dealing with infrastructure, while everyone else in the company who builds the models can enjoy the simplicity of training them at scale.
To install Horovod:
Install Open MPI or another MPI implementation. Learn how to install Open MPI on this page.
Note: Open MPI 3.1.3 has an issue that may cause hangs. The recommended fix is to downgrade to Open MPI 3.1.2 or upgrade to Open MPI 4.0.0.
If you've installed TensorFlow from PyPI, make sure that the
g++-4.8.5org++-4.9is installed.If you've installed PyTorch from PyPI, make sure that the
g++-4.9or above is installed.If you've installed either package from Conda, make sure that the
gxx_linux-64Conda package is installed.
- Install the
horovodpip package.
$ pip install horovodThis basic installation is good for laptops and for getting to know Horovod.
If you're installing Horovod on a server with GPUs, read the Horovod on GPU page.
If you want to use Docker, read the Horovod in Docker page.
Horovod core principles are based on MPI concepts such as size, rank, local rank, allreduce, allgather and, broadcast. See this page for more details.
See these pages for Horovod examples and best practices:
- Horovod with TensorFlow (Usage section below)
- Horovod with Keras
- Horovod with PyTorch
- Horovod with MXNet
To use Horovod, make the following additions to your program. This example uses TensorFlow.
- Run
hvd.init(). - Pin a server GPU to be used by this process using
config.gpu_options.visible_device_list. With the typical setup of one GPU per process, this can be set to local rank. In that case, the first process on the server will be allocated the first GPU, second process will be allocated the second GPU and so forth. - Scale the learning rate by number of workers. Effective batch size in synchronous distributed training is scaled by the number of workers. An increase in learning rate compensates for the increased batch size.
- Wrap optimizer in
hvd.DistributedOptimizer. The distributed optimizer delegates gradient computation to the original optimizer, averages gradients using allreduce or allgather, and then applies those averaged gradients. - Add
hvd.BroadcastGlobalVariablesHook(0)to broadcast initial variable states from rank 0 to all other processes. This is necessary to ensure consistent initialization of all workers when training is started with random weights or restored from a checkpoint. Alternatively, if you're not usingMonitoredTrainingSession, you can simply execute thehvd.broadcast_global_variablesop after global variables have been initialized. - Modify your code to save checkpoints only on worker 0 to prevent other workers from corrupting them.
This can be accomplished by passing
checkpoint_dir=Nonetotf.train.MonitoredTrainingSessionifhvd.rank() != 0.
Example (see the examples directory for full training examples):
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.AdagradOptimizer(0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)The example commands below show how to run distributed training. See the Running Horovod page for more instructions, including RoCE/InfiniBand tweaks and tips for dealing with hangs.
- To run on a machine with 4 GPUs:
$ horovodrun -np 4 -H localhost:4 python train.py- To run on 4 machines with 4 GPUs each:
$ horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py- To run using Open MPI without the
horovodrunwrapper, see the Running Horovod with Open MPI page. - To run in Docker, see the Horovod in Docker page.
- To run in Kubernetes, see Kubeflow, MPI Operator, Helm Chart, and FfDL.
- To run in Spark, see the Spark page.
- To run in Singularity, see Singularity.
Gloo is an open source collective communications library developed by Facebook.
Gloo comes included with Horovod, and allows users to run Horovod without requiring MPI to be installed. Gloo support only requires that you have CMake installed, and is only supported on Linux at this time.
For environments that have support both MPI and Gloo, you can choose to use Gloo at runtime by passing the --gloo argument to horovodrun:
$ horovodrun --gloo -np 2 python train.pyGloo support is still early in its development, and more features are coming soon.
Horovod supports mixing and matching Horovod collectives with other MPI libraries, such as mpi4py, provided that the MPI was built with multi-threading support.
You can check for MPI multi-threading support by querying the hvd.mpi_threads_supported() function.
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Verify that MPI multi-threading is supported.
assert hvd.mpi_threads_supported()
from mpi4py import MPI
assert hvd.size() == MPI.COMM_WORLD.Get_size()You can also initialize Horovod with an mpi4py sub-communicator, in which case each sub-communicator will run an independent Horovod training.
from mpi4py import MPI
import horovod.tensorflow as hvd
# Split COMM_WORLD into subcommunicators
subcomm = MPI.COMM_WORLD.Split(color=MPI.COMM_WORLD.rank % 2,
key=MPI.COMM_WORLD.rank)
# Initialize Horovod
hvd.init(comm=subcomm)
print('COMM_WORLD rank: %d, Horovod rank: %d' % (MPI.COMM_WORLD.rank, hvd.rank()))Learn how to optimize your model for inference and remove Horovod operations from the graph here.
One of the unique things about Horovod is its ability to interleave communication and computation coupled with the ability to batch small allreduce operations, which results in improved performance. We call this batching feature Tensor Fusion.
See here for full details and tweaking instructions.
Horovod has the ability to record the timeline of its activity, called Horovod Timeline.
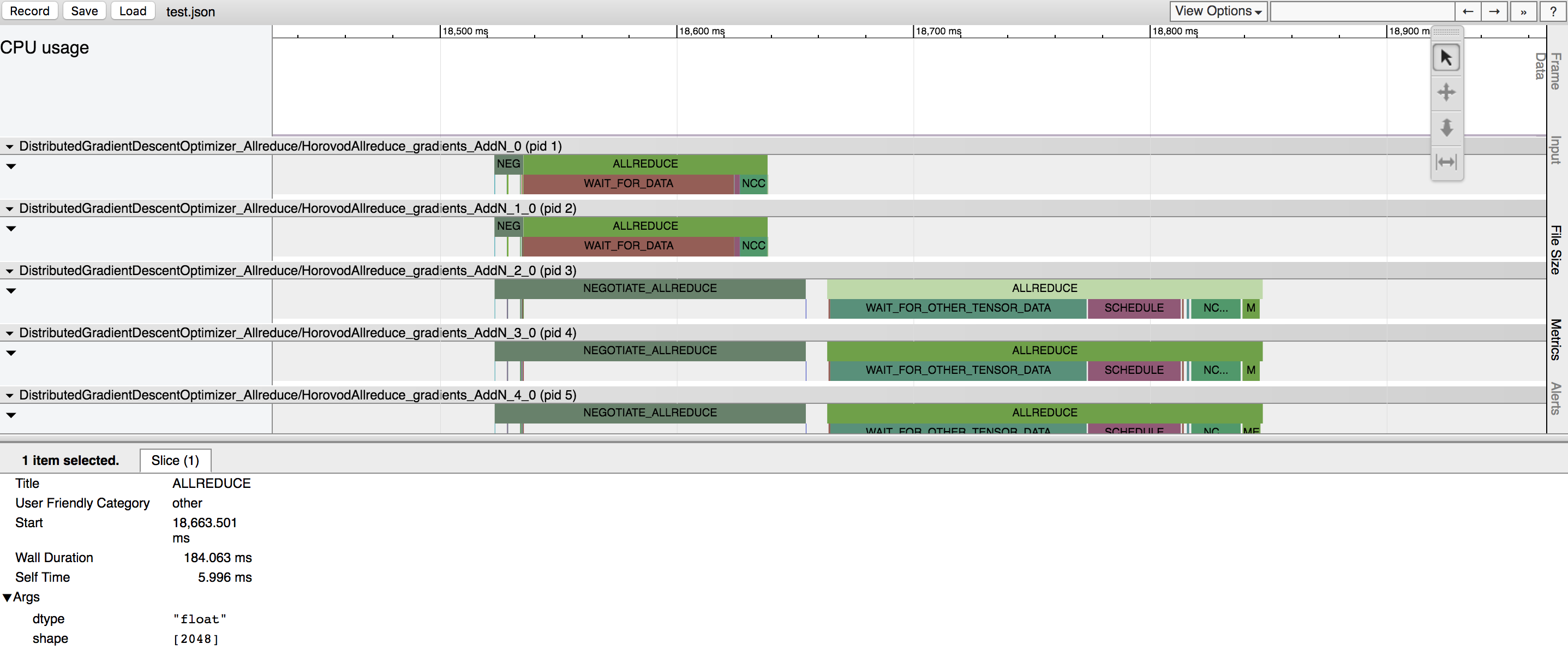
See here for full details and usage instructions.
Selecting the right values to efficiently make use of Tensor Fusion and other advanced Horovod features can involve
a good amount of trial and error. We provide a system to automate this performance optimization process called
autotuning, which you can enable with a single command line argument to horovodrun.
See here for full details and usage instructions.
- Run distributed training in Microsoft Azure using Batch AI and Horovod. Send us links to any user guides you want to publish on this site
See the Troubleshooting page and please submit a ticket if you can't find an answer.
Please cite Horovod in your publications if it helps your research:
@article{sergeev2018horovod,
Author = {Alexander Sergeev and Mike Del Balso},
Journal = {arXiv preprint arXiv:1802.05799},
Title = {Horovod: fast and easy distributed deep learning in {TensorFlow}},
Year = {2018}
}
1. Sergeev, A., Del Balso, M. (2017) Meet Horovod: Uber’s Open Source Distributed Deep Learning Framework for TensorFlow. Retrieved from https://eng.uber.com/horovod/
2. Sergeev, A. (2017) Horovod - Distributed TensorFlow Made Easy. Retrieved from https://www.slideshare.net/AlexanderSergeev4/horovod-distributed-tensorflow-made-easy
3. Sergeev, A., Del Balso, M. (2018) Horovod: fast and easy distributed deep learning in TensorFlow. Retrieved from arXiv:1802.05799
The Horovod source code was based off the Baidu tensorflow-allreduce repository written by Andrew Gibiansky and Joel Hestness. Their original work is described in the article Bringing HPC Techniques to Deep Learning.
Subscribe to Horovod Announce and Horovod Technical-Discuss to stay up to date.