
Lightweight Python library for configuring ETL (Extract, Transform, Load) pipelines. Designed to create services with multi-step data processing using just Python and nothing more.
This module is a simplified analogue of ETL-related libraries (e.g. luigi and bonobo (bonobo by the way is also pretty simple tool) and workflow management (workflow orchestration) platforms (e.g. Apache Airflow and prefect).
Wiredflow is well-suited for both prototype preparation, quick experiments, and incorporation into industrial systems step-by-step. However, we recommend starting to use the library as a tool for prototyping. It could be especially convenient for IoT applications data processing (data from sensors often can be delivered via MQTT protocol). So wiredflow is pretty good solution for continuous streaming workflows. It allows configuring HTTP/HTTPS, MQTT, database connectors, schedulers, and much more to use all of it through pure Python.
Use the following commands to install this module
Using pip:
pip install wiredflowUsing poetry:
poetry add wiredflowNB: All examples should start in your virtual environment without any problems. The wiredflow-based services do not require any configuration beyond Python and library's dependencies (unless it is explicitly stated).
First, check examples folder, which can be easily launched locally. In threads folder you will find examples how to configure service and launch pipelines in different threads:
- simple HTTP case - single data source which can be reached via simple HTTP GET request
- simple HTTP case with configuration - single data source which can be reached via simple HTTP POST request. Parameters of POST request configured with custom logic.
- advanced HTTP case - several data sources (receive data via HTTP) with custom data processing
- simple MQTT case - single data source which send messages using MQTT
- advanced MQTT case - several data sources (receive data via MQTT) with custom data processing
- complex multi-source case - complex flow example with custom multi-step data processing and several notificators
Examples with pre-configured databases:
- simple_http_with_mongo.py - single data source which can be reached via simple HTTP GET request and saved into MongoDB. Tutorial how to configure free remote MongoDB can be found here.
- advanced_http_with_custom_mongodb.py - single data source which can be reached via simple HTTP GET request and custom storage (MongoDB) logic. Tutorial how to configure free remote MongoDB can be found here.
If you want to know how to launch pipelines in separate processes (launch service in parallel) - just set use_threads=False in builder
and check processes folder for usage examples.
The full documentation build for this library can be found here. There you will find a detailed description of the library's internals as well as a lot of examples and tutorials
If you are looking forward to start using the library, it is recommended to begin the exploration with the section "Quick start".
The library is not a low-code solution, but it's great for developing custom pipelines when you can't avoid writing custom business logic. The library consists of the following key blocks (by combining these blocks it is possible to implement processing pipelines of flexible structure):
- Configuration - Optional block before other stages to configure next stage parameters. Allows implementing custom configurations logic using Python function. Configuration block pass parameters to next stage.
- HTTP connector - Retrieving data using
HTTPrequests, for example using theGETmethod. - MQTT connector - Retrieving data using
MQTTprotocol, the connector subscribes to the MQTT queue and receives data real-time. - Storage - File or database where to save data
- Core logic - An abstraction that allows implementing custom business logic using Python function. Core logic block pass data to next stage.
- Send - An abstraction that sends data received through core logic processing to specified endpoints.
Can use both
MQTTbrokers and standardPOST/PUTHTTP/HTTPSmethods
To make it clearer, here are some examples of possible service structures that can be built using wiredflow:
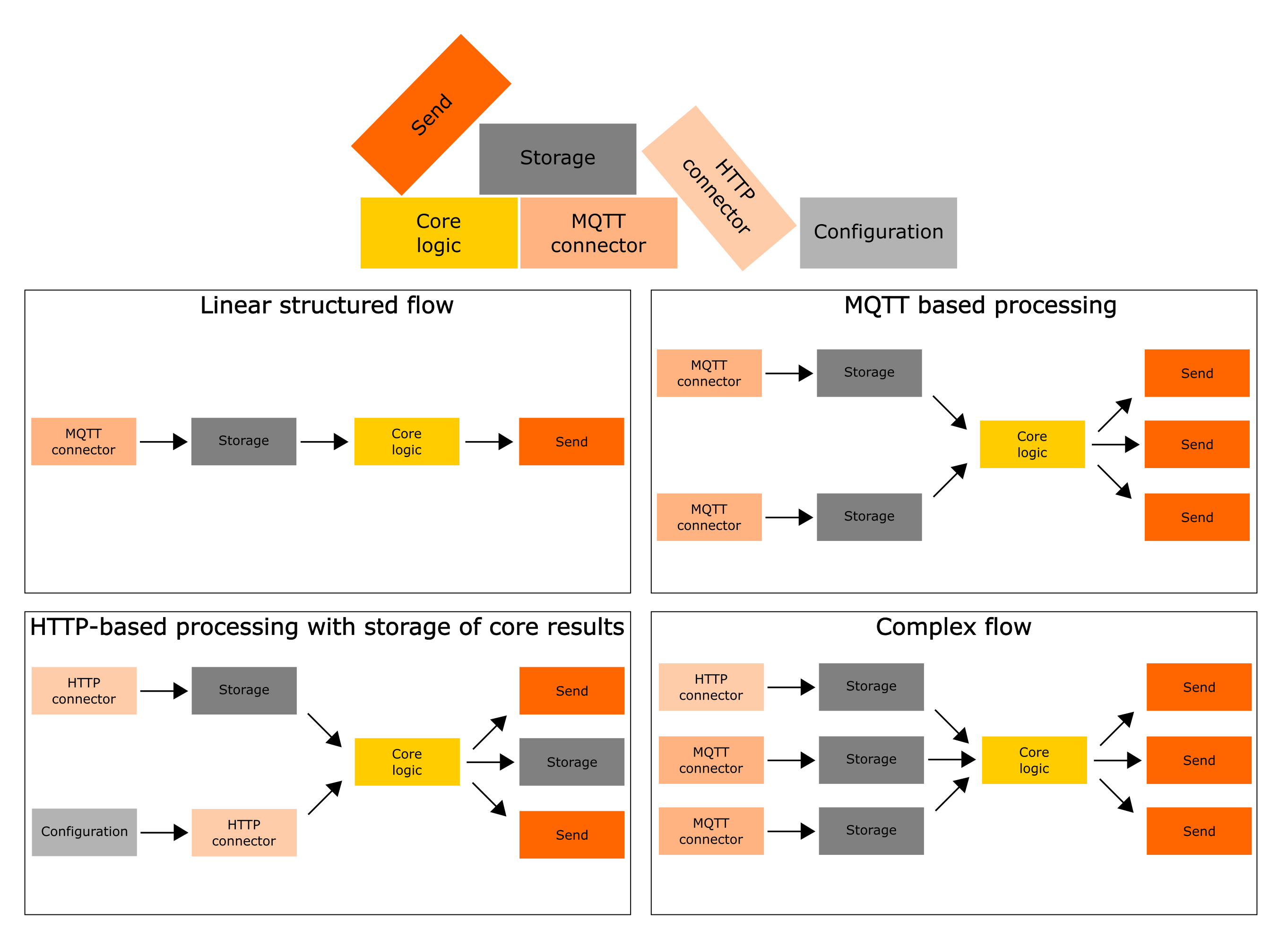
The fastest way to understand wiredflow is to think of it as a lightweight builder for services. Protocols, endpoints, notifications, schedulers and storages are our constructor, and we (engineers), can play with it the way we want to. If you would like to know more about wiredflow key features and limitations - follow the page "Features and limitations" in particular and check the official documentation in common.
Feel free to join wiredflow open source project!
Check contribution guide for more details.