https://help.aliyun.com/document_detail/145715.html?spm=a2c4g.11174283.6.885.1f026ad1gDFilP
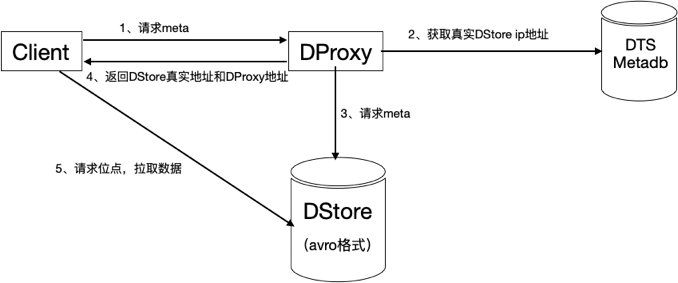
| Kafka原生client | DTS封装的订阅SDK | 大数据平台connector | |
|---|---|---|---|
| 优点 | 灵活,用户完全自主可控 | 使用简单,提供如下完整支持: 1)限制用户行为,暴露有限的参数 2)对消息位点的管理进行了明确 3)增加了统计信息 4)帮助客户快速地定位问题 |
使用方便,用户不需要了解DTS订阅逻辑或者Kafka,在平台内部使用即可 |
| 缺点 | 用户接入成本较高,自己解析DTS avro格式,容易出错,出错排查问题成本较高 | 数据接收完之后如果需要同步到大数据平台需要再单独编写代码 | 专门领域使用,DTS自身开发成本较高 |
| 适用人群 | Kafka资深用户,同时熟悉DTS | 对DTS订阅有需要的任何用户 | 大数据片平台使用者如Flink、Spark需要关系型数据库的实时数据 |
1.包装FlinkKafkaConsumer,只暴露用户需要的参数 2.Flink SQL的支持需要限定固定的表,并且该表有查询的列
1.直接反序列化二进制bytes到DTSRecord,不经过avro 格式record的转换
1.定制Flink持久化状态的数据,保证Dstore容灾数据连续: Dstore是单节点,可能发生切换,切换之后用户消费位点的offset发生变化,需要通过timestamp重新定位
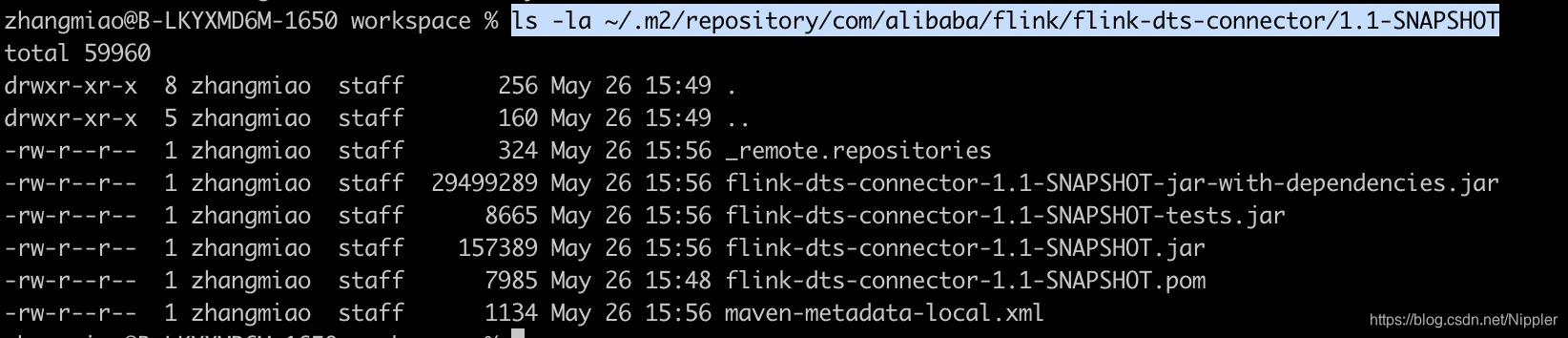
这个工程是dts connector,下载之后,执行mvn clean install,检查自己目录下有如下文件:
ls -la ~/.m2/repository/com/alibaba/flink/flink-dts-connector/1.1-SNAPSHOT
然后在自己的项目中进行依赖
<groupId>com.alibaba.flink</groupId>
<artifactId>flink-dts-connector</artifactId>
<version>1.1-SNAPSHOT</version>
<classifier>jar-with-dependencies</classifier>
</dependency>
flink-dts-demo中有使用的实例: https://github.com/silly-fofo/flink-dts-demo 你可以参考下,有两种用法,一种是Flink底层接口DataStream API,一种是Flink SQL
DataStream input = env.addSource(
new FlinkDtsConsumer(
(String) properties.get("broker-url"),
(String) properties.get("topic"),
(String) properties.get("sid"),
(String) properties.get("user"),
(String) properties.get("password"),
Integer.valueOf((String) properties.get("checkpoint")),
new DtsRecordDeserializationSchema(),
null))
.filter(
new FilterFunction<DtsRecord>() {
@Override
public boolean filter(DtsRecord record) throws Exception {
if (OperationType.INSERT == record.getOperationType()
|| OperationType.UPDATE == record.getOperationType()
|| OperationType.DELETE == record.getOperationType()
|| OperationType.HEARTBEAT
== record.getOperationType()) {
return true;
} else {
return false;
}
}
})
dts.server、topic、dts.sid、dts.password、dts.checkpoint参数参考: https://help.aliyun.com/document_detail/121239.html?spm=a2c4g.11174283.6.896.7ff86ad1UiqVz1
dts-cdc.table.name必须是单张表,格式为:库.表
"create table `dts` (\n"
+ " `ts` TIMESTAMP(3) METADATA FROM 'timestamp',\n"
+ " `id` bigint,\n"
+ " `name` varchar,\n"
+ " `age` bigint,\n"
+ " WATERMARK FOR ts AS ts - INTERVAL '5' SECOND"
+ ") with (\n"
+ "'connector' = 'dts',"
+ "'dts.server' = '<dts proxy url>',"
+ "'topic' = 'xxx',"
+ "'dts.sid' = 'xxx', "
+ "'dts.user' = 'xxx', "
+ "'dts.password' = '******',"
+ "'dts.checkpoint' = 'xxx', "
+ "'dts-cdc.table.name' = 'yanmen_source.test',"
+ "'format' = 'dts-cdc')";
注意和DTS订阅任务使用de区别是没有dts.sid的属性,可以添加dts.group的属性
"create table `dts` (\n"
+ " `ts` TIMESTAMP(3) METADATA FROM 'timestamp',\n"
+ " `id` bigint,\n"
+ " `name` varchar,\n"
+ " `age` bigint,\n"
+ " WATERMARK FOR ts AS ts - INTERVAL '5' SECOND"
+ ") with (\n"
+ "'connector' = 'dts',"
+ "'dts.server' = '<kafka-broker-url>',"
+ "'topic' = 'xxx',"
+ "'dts.group' = 'xxx', "
+ "'dts.user' = 'xxx', "
+ "'dts.password' = '******',"
+ "'dts.checkpoint' = 'xxx', "
+ "'dts-cdc.table.name' = 'yanmen_source.test',"
+ "'format' = 'dts-cdc')";