JavaScript Call Stack #55
Description
JavaScript Call Stack
在这篇文章中, 将学习关于 JavaScript Call Stack, 它是一种关于跟踪函数调用栈的技术.
介绍 JavaScript Call Stack
JavaScript engine 使用调用栈去管理 执行上下文: 全局执行上下文和函数执行上下文.
既然是通过栈进行管理, 那么遵循 LIFO 的原则.
当执行代码时, JavaScript engine 将会创建全局执行上下文并压入到调用栈的顶端.
每当调用一个函数时,JavaScript engine都会为该函数创建一个函数执行上下文, 将其压入到调用堆栈的顶部, 然后开始执行该函数.
如果一个函数调用另一个函数, JavaScript engine会为被调用的函数创建一个新的函数执行上下文, 并将其压入调用堆栈的顶部.
当前函数完成后, JavaScript engine 将其从调用堆栈中弹出, 并从上次代码清单中停止的地方继续执行.
当调用栈是空时, 则脚本将停止.
JavaScript call stack example
看下面代码:
function add(a, b) {
return a + b;
}
function average(a, b) {
return add(a, b) / 2;
}
let x = average(10, 20);当代码执行时, JavaScript engine 将全局执行上下文(用 main() or global()表示) 压入调用栈中.
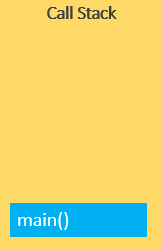
全局执行上下文进入创建阶段并移动到执行阶段.
JavaScript engine 执行对 average(10, 20)函数调用, 并为 average() 函数创建一个函数执行上下文, 并将其压入到调用栈顶端.
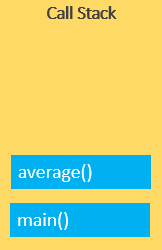
JavaScript engine 开始执行 average(), 因为它位于调用堆栈的顶部.
average() 函数调用 add() 函数. 此时, JavaScript engine 为 add() 函数创建另一个函数执行上下文并将其放在调用堆栈的顶部:

当 JavaScript engine 执行完 add(), 则会把对应执行上下文从调用栈中移除.
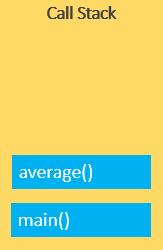
此时, average() 函数是在调用栈的顶部, JavaScript engine 执行它并从调用栈中移除它:

现在,调用栈为空, 因此脚本将停止执行:

下面图片表示完整调用栈:
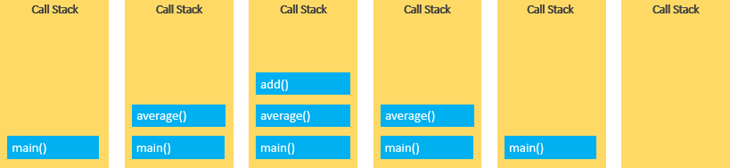
Stack overflow
调用栈大小固定, 依赖宿主环境实现, web browser 或 Node.js.
如果执行上下文的数量超过堆栈的大小,就会发生堆栈溢出.
例如, 当你执行递归函数是且不包含终止递归当条件, 将会发生栈溢出:
function foo() {
foo();
}
foo(); // stack overflowAsynchronous JavaScript
JavaScript 是基于单线程的编程语言. JavaScript engine 只有一个调用堆栈, 因此一次只能做一件事.
当执行脚本时, JavaScript engine 从上往下逐行执行.(同步代码)
异步与同步相反, 同步意味着同时发生. 那么 JavaScript 是如何承载回调、promise、async/await 等异步任务的呢? 这就是事件循环出现的地方, 我们将在下一个文章中介绍.