Benchmarks to compare the performance of async runtimes / executors.
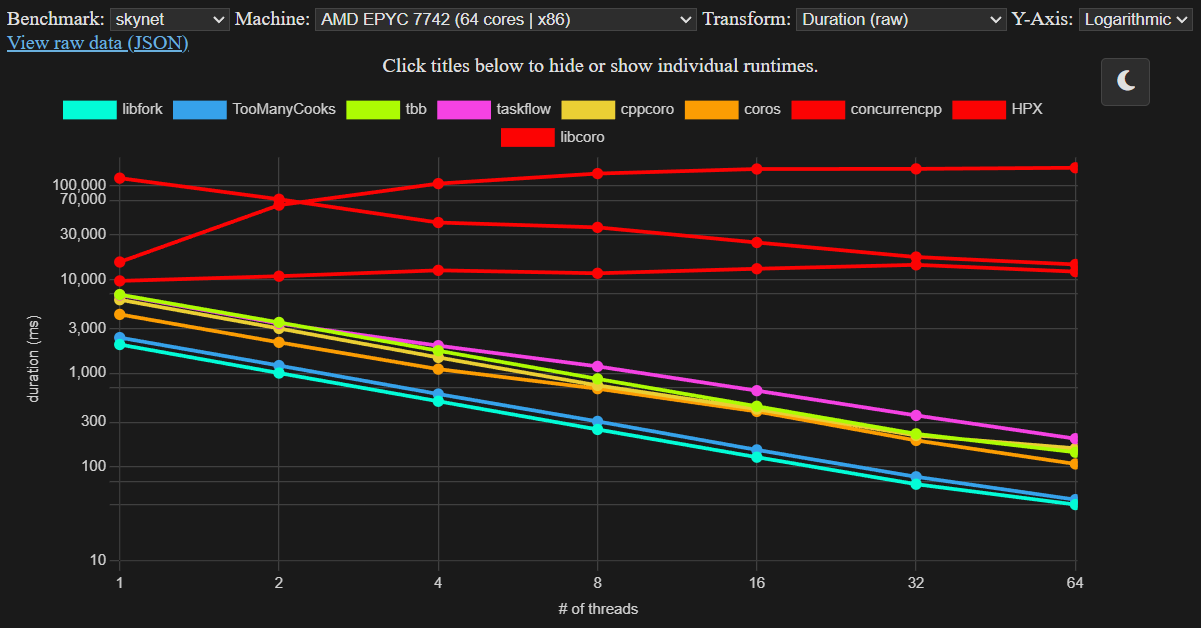
An interactive view of the full results dataset is available at: https://fleetcode.com/runtime-benchmarks/
| Runtime | citor | libfork | TooManyCooks | tbb | taskflow | cppcoro | coros | HPX | concurrencpp | libcoro |
|---|---|---|---|---|---|---|---|---|---|---|
| Mean Ratio to Best (lower is better) |
1.06x | 1.18x | 1.32x | 3.25x | 3.34x | 3.67x | 4.83x | 186.81x | 258.19x | 2513.96x |
| skynet | 24932 us | 36519 us | 37949 us | 142887 us | 185019 us | 144907 us | 94532 us | 11965484 us | 12514888 us | 119686148 us |
| nqueens | 80765 us | 69010 us | 70248 us | 125730 us | 114721 us | 162773 us | 741141 us | 3452638 us | 8000700 us | 33347402 us |
| fib(39) | 49966 us | 62367 us | 86731 us | 215592 us | 156590 us | 269384 us | 187136 us | 10789290 us | 20663744 us | 238019884 us |
| matmul(2048) | 48069 us | 44140 us | 44822 us | 50127 us | 50173 us | 49684 us | 46780 us | 59066 us | 57383 us | 374412 us |
| Runtime | TooManyCooks | cobalt | libcoro | cppcoro |
|---|---|---|---|---|
| Mean Ratio to Best (lower is better) |
1.00x | 1.16x | 1.42x | 1.55x |
| io_socket_st | 339340 us | 393036 us | 483074 us | 524717 us |
| Runtime | TooManyCooks_mt | TooManyCooks_st_asio | libcoro_mt | cobalt_st_asio |
|---|---|---|---|---|
| Mean Ratio to Best (lower is better) |
1.00x | 1.00x | 1.05x | 2.33x |
| channel | 390771 us | 391661 us | 409967 us | 910778 us |
| Runtime | citor | libfork | TooManyCooks | TooManyCooks_st_asio | TooManyCooks_mt | tbb | taskflow | cppcoro | coros | concurrencpp | HPX | libcoro | libcoro_mt | cobalt_st_asio | cobalt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| skynet | 20.74 MB | 11.36 MB | 13.99 MB | N/A | N/A | 14.29 MB | 10.91 MB | 134.09 MB | 10.94 MB | 11.38 MB | 24.87 GB | 14.66 GB | N/A | N/A | N/A |
| nqueens | 51.01 MB | 10.51 MB | 14.12 MB | N/A | N/A | 12.66 MB | 10.88 MB | 134.09 MB | 9.18 MB | 13.04 MB | 11.23 GB | 5.03 GB | N/A | N/A | N/A |
| fib(39) | 44.5 MB | 11.52 MB | 12.62 MB | N/A | N/A | 11.69 MB | 9.1 MB | 134.13 MB | 9.44 MB | 11.29 MB | 15.59 GB | 15.81 GB | N/A | N/A | N/A |
| matmul(2048) | 68.8 MB | 60.43 MB | 60.07 MB | N/A | N/A | 59.35 MB | 56.17 MB | 186.36 MB | 58.55 MB | 61.16 MB | 103.89 MB | 56.37 MB | N/A | N/A | N/A |
| io_socket_st | N/A | N/A | 10.62 MB | N/A | N/A | N/A | N/A | 9.36 MB | N/A | N/A | N/A | 10.91 MB | N/A | N/A | 10.95 MB |
| channel | N/A | N/A | N/A | 25.76 MB | 32.99 MB | N/A | N/A | N/A | N/A | N/A | N/A | N/A | 9.95 MB | 7.68 MB | N/A |
Click to view the machine configuration used in the summary tables
- Processor: EPYC 7742 64-core processor
- Worker Thread Count: 64 (no SMT)
- OS: Debian 13 Server
- Compiler: Clang 21.1.7 Release (-O3 -march=native)
- CPU boost enabled / schedutil governor
- Linked against libtcmalloc_minimal.so.4
Currently only includes C++ frameworks, and several recursive fork-join benchmarks:
- recursive fibonacci (forks x2)
- skynet (original link) but increased to 100M tasks (forks x10)
- nqueens (forks up to x14)
- matmul (forks x4)
As well as some miscellaneous benchmarks:
- channel - tests the performance of the library's async MPMC queue
- io_socket_st - tests TCP ping-pong between a single-threaded client and single-threaded server
Benchmark problem sizes were chosen to balance between making the total runtime of a full sweep tolerable (especially on weaker hardware with slower runtimes), and being sufficiently large to show meaningful differentiation between faster runtimes.
Note: if you have issues with a particular runtime, you can simply remove it from line 17 of build_and_bench_all.py to skip it.
- The build+bench script uses python3. The only Python dependency is libyaml.
- CMake + Clang 18 or newer
- libfork and TooManyCooks depend on the hwloc library.
- TBB benchmarks depend on system installed TBB - see the installation guide here for the newest version or you may be able to find the old version 'libtbb-dev' in your system package manager
- HPX and boost::cobalt requires Boost 1.82 or newer. You may need to build Boost from source, since cobalt is currently not included in distro packages.
- A high performance allocator (tcmalloc, jemalloc, or mimalloc) is also recommended. The build script will dynamically link to any of these if they are available.
On Debian/Ubuntu:
sudo apt-get install cmake hwloc libhwloc-dev intel-oneapi-tbb-devel libtcmalloc-minimal4
On MacOS:
brew install cmake gperftools hwloc libyaml tbb
NOTE: If a particular library or benchmark fails to build or run, don't worry - its output will simply be ignored.
python3 ./build_and_bench_all.py
Results will appear in RESULTS.md and RESULTS.csv files.
python3 ./build_and_bench_all.py full
Results will also appear in RESULTS.json file; this file can be parsed by the interactive benchmarks site. A locally viewable version of this HTML chart will be generated as well.
git-ref can be a SHA, tag, or branch:
./build_and_bench_all.py <runtime> [git-ref]
./build_and_bench_all.py compare <runtime> <new-git-ref> [baseline-git-ref]
Frameworks to come:
- (C#) .Net thread pool
- (Rust) tokio
- (Golang) goroutines
- Facebook Folly
- PhotonLibOS https://github.com/alibaba/PhotonLibOS
Benchmarks to come:
- Some inspiration here