

a keyword analysis tool/API in flask: extracts keywords from e-commerce items in different categories and provides keywords/price distribution information with user’s feedback input;
Base Path: http://175.106.99.99:16758/
| method | url | input format | output format | desc |
|---|---|---|---|---|
| GET | /api/v1/results/keyword | n/a | JSON | returns keywords' frequencies and relevant productIds for each category |
| GET | /api/v1/results/price-spread | n/a | JSON | returns a dictionary of img link of histogram depicting item's price distribution for each category |
| POST | /api/v1/feedback | JSON | str | reads and applies user's feedback for future GET requests requests |
beforehand: upload target database to MongoDB
for i = 1 to repeat do:
{
-
a. i=1: return keyword information for each category in its initial state
b. i>=2: returns feedback-applied keyword information and most recent feedback file for #3(POST-FEEDBACK)
-
GET-PRICESPREAD: (optional)
a. i=1: returns a dictionary of item name and img link of histogram depicting item's price distribution for each category
b. i>=2: after inputting feedback: returns histogram img links with feedback applied
-
a. i=1: posts feedback information based on information from GET-KEYWORDS and GET-PRICESPREAD
b. i>=2: posts a new feedback by APPENDING new options from the most recent feedback received from GET-KEYWORDS
Note: Refer to Important Note
}
END IF: retrieved satisfactory information
URL: /api/v1/results/keyword
returns keywords' frequencies and productIds that included the keywords for each category
Successful Response
Code: 200
Content:
-
result: array of category-objs
-
category-objects
attributes type desc uses categ str keywords list of keyword-objects see below -
keyword-objects
attributes type desc uses rank int rank based on appearance frequencies keyword str keyword name appearance int appearance frequencies *note: app.freq and product_list's value can differ product_list list of ints productId which had keyword in the title
-
-
previous-feedback: feedback json which was posted most recently ; see read-feedback for relevant data structure
e.g.
```
{
"result": [
{
"categ": "portable_fan",
"keywords": [
{
"rank": 1,
"keyword": "fan",
"appearance": 5,
"product_list": [
"82497194884"
]
},
{
"rank": 2,
"keyword": "paperclip",
"appearance": 1,
"product_list": [
"82497194884"
]
},
},
{
"categ": "dustproof_mask",
"keywords": [
{
"rank": 1,
"keyword": "mask",
"appearance": 32,
"product_list": [
"27224642701",
"26883864380",
"25295068476",
]
},
]
}
"previous-feedback": [
{
"categ": "golfbag_set",
"lprice": 60000,
"hprice": 150000,
"sub-cats": [
"golfpouch",
"bostonbag"
],
"ignore": [
"golfb",
"bKakaofriends",
"special",
"basic"
],
"effective": [
"official_website",
"high-quality",
"PLACEHOLDER"
]
}
]
}
```
curl --location --request GET 'http://175.106.99.99:16758/api/v1/results/price-spread'
-
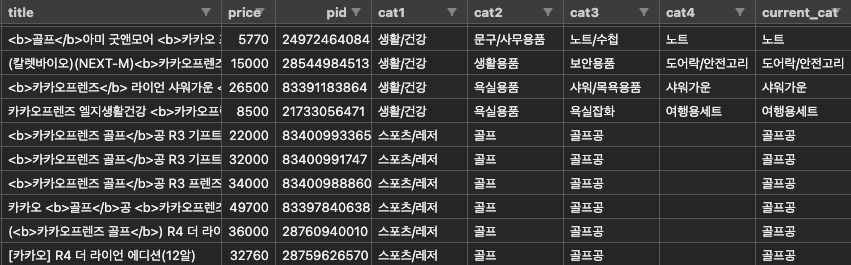
Dataset Prep & Cleaning
- Generate the following dataframe obj from target DB in mongoDB
current_catacts as a pointer showing current item's lowest category level (most specific category level)- i.e) iPhone is the lowest category from [Electronics -> Smartphones -> iPhones]
titlecolumn is saved after basic string-cleaning
i.e. (AMAZON)(NEXT-M)<b>Kakaofriends golf</b> mask 세탁 30회 다회용mask (6395452) ⬇️ AMAZON NEXT-M Kakaofriends golf mask 세탁 30회 다회용mask- when
sub-catsis given in feedback: merges lower category to current category
i.e. "categ": "golfbag_set", "sub-cats": [ "golfpouch", "bostonbag" ],In this case,
golfbag_set + bostonbag + golfpouch => merged into golfbag_set `current_cat` column value is changed to golfbag_set - Generate the following dataframe obj from target DB in mongoDB
-
Keyword Extraction 1 [when no feedback is given]
-
save all keywords that appeared in each category's item to
dict{Category: Counter(keywords)}a. i.e. {
Category1:[('handbags',23), ('luxurious',12), ('pouches',5)]}
-
-
Keyword Extraction 2 [when feedback is given]
-
Iterate through all keywords that appeared in each category's item
a. if price is inside the range [
lprice,hprice] -> save keyword togen_countobjb. if price is outside the range => save keyword to
sus_countobj -
Update
Counterobjecta. Remove
gen_countobjkeywords fromsus_countobjb. Iterate the remaining keywords again to update
ignore,effective.
-
-
JSON Generation
{kind=link}
- generate a dumpable final JSON file based on
dictfrom step 2Category A { "rank": (int), "keyword": (str), "appearance": (int), "product_list": list(int) }
URL: /api/v1/results/price-spread
returns a dictionary of img link of histogram depicting item's price distribution for each category
Successful Response
Code: 200
Content:
| KEY | VALUE |
|---|---|
| category (str) | img_link (str) |
예시
{
"portable_fan": "https://fkz-web-images.cdn.ntruss.com/price-spread/portable_fan.png",
"mask": "https://fkz-web-images.cdn.ntruss.com/price-spread/mask.png",
"laptop": "https://fkz-web-images.cdn.ntruss.com/price-spread/laptop.png",
"showergown": "https://fkz-web-images.cdn.ntruss.com/price-spread/showergown.png",
"waterbottle": "https://fkz-web-images.cdn.ntruss.com/price-spread/waterbottle.png",
"large_umbrella": "https://fkz-web-images.cdn.ntruss.com/price-spread/large_umbrella.png",
"macbook": "https://fkz-web-images.cdn.ntruss.com/price-spread/macbook.png"
}
curl --location --request GET 'http://175.106.99.99:16758/api/v1/results/price-spread'
for categ in all_categories_as_list:
- generate a fresh DataFrame of rows in which
lowest_category==categin DB - generate a seaborn.histplot(histogram) from DataFrame's price column
- Upload generated histograms to objective storage using boto3
- save the links as dict{categ: img_link}
end for
return dict
URL: /api/v1/feedback
reads and applies user's feedback for future GET requests
- array of:
- keyword-feedback object
-
attributes type desc uses categ str keyword name lprice int min value in genuine product's price range item keywords with the price inside genuine's range is removed from final results hprice int max value in genuine product's price range " sub-cats listOfStrings lower category names that will be merged into current category items in lower category will all belong under current keyword ignore listOfStrings keywords to ignore removed from final return effective listOfStrings keywords that seem promising/critical displayed even if app.freq is 0
i.e.
[
{
"categ": "golfbag_set",
"lprice": 60000,
"hprice": 150000,
"sub-cats": [
"golfpouch",
"bostonbag"
],
"ignore": [
"golfb",
"bKakaofriends",
"special",
"basic"
],
"effective": [
"official-website",
"high-quality",
"PLACEHOLDER"
]
},
{
"categ": "hats",
"lprice": 35000,
"hprice": 55000,
"sub-cats": [], # they can be left as empty list
"ignore": [],
"effective": []
}
]
Successful Response
Code: 200
Content: received feedback
curl --location --request POST 'http://175.106.99.99:16758/api/v1/feedback' \
--data-raw '[
{
"categ": "hats",
"lprice": 35000,
"hprice": 55000,
"sub-cats": [],
"ignore": [],
"effective": []
},
]'
For any iteration(i>=2) mentioned inTypical Code Workflow, you must include previous-feedback from [GET] get-keywords so all the previous options can be applied for the new iteration.
Therefore when writing new feedback files, we suggest you copy previous-feedback's content and edit accordingly.
i.e.
"previous-feedback":
[
{
"categ": "golfbag_set",
"lprice": 60000,
"hprice": 150000,
"sub-cats": [
"golfpouch",
"bostonbag"
],
"ignore": [
"golfb",
"bKakaofriends",
"special",
"basic"
],
"effective": [
"official-website",
"high-quality",
]
}
]
updated feedback.json
[
{
"categ": "golfbag_set",
"lprice": 60000,
"hprice": 150000,
"sub-cats": [], # editted
"ignore": [
"golfb",
"bKakaofriends",
"special",
"basic",
"discount", # added
"golf" # added
],
"effective": [
"official-website",
"high-quality",
"made_in_china", # added
"imitation" # added
]
}
]
- "sub-cats": remove options as lower categories were merged in the previous iteration
- "ignore": added 'discount' and 'golf'
- "effective": added "made_in_china" and "imitation"
- read the POSTed json file
- save as `./cache/feedback.json` & `./cache/feedback.pkl` for future accesses