Matrices : Extend pseudoinverse capability #16305
Conversation
|
✅ Hi, I am the SymPy bot (v147). I'm here to help you write a release notes entry. Please read the guide on how to write release notes. Your release notes are in good order. Here is what the release notes will look like:
This will be added to https://github.com/sympy/sympy/wiki/Release-Notes-for-1.5. Note: This comment will be updated with the latest check if you edit the pull request. You need to reload the page to see it. Click here to see the pull request description that was parsed.
Update The release notes on the wiki have been updated. |
Codecov Report
@@ Coverage Diff @@
## master #16305 +/- ##
============================================
+ Coverage 73.257% 73.867% +0.61%
============================================
Files 618 619 +1
Lines 158200 159835 +1635
Branches 37175 37524 +349
============================================
+ Hits 115893 118066 +2173
+ Misses 36783 36291 -492
+ Partials 5524 5478 -46 |
|
I have commented out some symbolic matrix test, because the diagonalization method makes an expression too complicated. |
|
Looks good. Are you finished with this? |
| # XXX Computing pinv using diagonalization makes an expression that | ||
| # is too complicated to simplify. | ||
| # A1 = Matrix([[a, b], [c, d]]) | ||
| # assert simplify(A1.pinv(method="ED")) == simplify(A1.inv()) |
There was a problem hiding this comment.
I'm only looking for a way to make this commented-out test as some allowed timeout failings.
Things like this is taking too much time, to see it fail
Is there any way to specify the timeout?
There was a problem hiding this comment.
This is pretty quick. Is it convincing enough?
import random
q=A1.pinv(method="ED")
w=A1.inv()
v=(a,b,c,d)
for do in range(5):
reps = dict(zip(v, (random.randint(-10**5,10**5) for i in v)))
assert all(comp(i.n(), j.n()) for i, j in zip(q.subs(reps),w.subs(reps)))If you are nervous about dividing be zero you could check that
all(i.subs(reps) for i in denoms(q)) before doing the comp.
| for do in range(5): | ||
| while True: | ||
| reps = \ | ||
| dict(zip(v, (random.randint(-10**5, 10**5) for i in v))) |
There was a problem hiding this comment.
Why do we need to use random numbers here?
I don't think we should have random testing in the main tests because it gives hard to debug test failures that can slip through CI and it messes up coverage measurement.
In general I think that random number testing can be good for picking up issues when you think you've just about got something working. You can run a large number of random tests and then pick out failure cases, fix them and then add them as examples for the proper tests.
Maybe just generate the random numbers once and then add those to the code as fixed numbers?
There was a problem hiding this comment.
If we can't prove that the two expressions are equal then the next best thing is to show that they are highly unlikely to be different. If this test ever fails it means the two expressions are not the same. Without a random test we will not include this test and leave code totally uncovered.
There was a problem hiding this comment.
Rather than using randint in the test code though you can use it to generate numbers that you then bake in to the code.
If you think that a single run of this test is good enough then why is it necessary to have it use different numbers each time?
There was a problem hiding this comment.
why is it necessary to have it use different numbers each time
If the expressions have not been proved to be the same then we don't know they are the same. The best we can do is know, with every increasing likelihood, that they are not different. If we always tests the same numbers we are never increasing the assurance that they are the same.
Any given set of numbers may produce an expression that is zero by fortuitous cancellation of terms. I don't know what sort or wrong expression might be returned by any changes in the future so I am just suggesting that it be tested in a way that is quick and matches the other method.
|
@oscarbenjamin , this is +1 from me, but I defer to any ideas you have for the random testing. |
>>> from sympy import thisThe Zen of SymPy Unevaluated is better than evaluated. |
|
Fair enough :). I didn't mean to hold up the PR... Having looked at it, how about this: diff --git a/sympy/matrices/tests/test_matrices.py b/sympy/matrices/tests/test_matrices.py
index 161bf957eb..cf9a3f191a 100644
--- a/sympy/matrices/tests/test_matrices.py
+++ b/sympy/matrices/tests/test_matrices.py
@@ -2932,20 +2932,17 @@ def test_pinv():
# A1 = Matrix([[a, b], [c, d]])
# assert simplify(A1.pinv(method="ED")) == simplify(A1.inv())
- import random
- from sympy.core.numbers import comp
+ from sympy import factor, sqrtdenest, ratsimp
+ my_simplify = lambda x: factor(sqrtdenest(ratsimp(x)))
+
q = A1.pinv(method="ED")
w = A1.inv()
- v = (a, b, c, d)
- while True:
- reps = \
- dict(zip(v, (random.randint(-10**5, 10**5) for i in v)))
- if (a*d - b*c).subs(reps) != 0:
- break
- assert all(
- comp(i.n(), j.n())
- for i, j in zip(q.subs(reps), w.subs(reps))
- )
+
+ reps = {a:-73633, b:11304, c:55486, d:62570} # random.randint(10**5)
+ qs = q.subs(reps)
+ ws = w.subs(reps)
+ qs_simp = qs.applyfunc(my_simplify)
+ assert qs_simp == ws
def test_pinv_solve():
# Fully determined system (unique result, identical to other solvers).
`` |
|
I had similar concerns that random tests may likely fail many times, because complex rationals or square roots can get easily blown up at this state. There should be some things to improve for symbolic diagonalization Using rank decomposition in sympy: Using diagonalization in sympy: And if there exists no method to improve symbolic diagonalization on the earth, I would just believe that diagonalization is not a 'proper' method for symbolic pseudoinverse computation. |


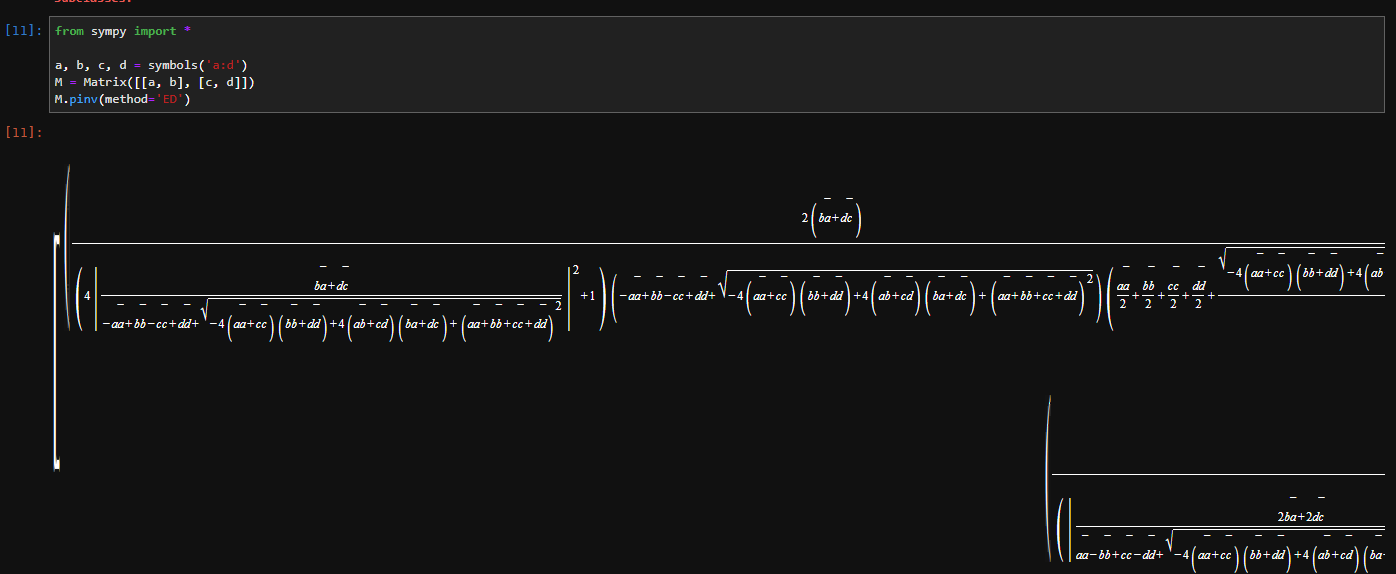
|
Concerning random tests: having looked at this more closely I don't think it really makes much difference here. Using random tests to generate the input to a tested function means that the test is testing different things each time. In some cases that is useful but it also has the drawbacks I mentioned above. Here the test is essentially that the general formula returned is correct and the randomness is just which value to substitute into it to check that. So the tested function always receives the same input and gives the same output. That does mean though that the randomness isn't that useful and some specific values can be chosen. As it stands if the test randomly fails it would most likely be a bug in evalf rather than pinv. What I dislike about the random tests is that reproducing them from a failure on Travis is hard. In principle you need to fix the random seed and the hash seed and have all the same versions of CPython etc and you need to run the exact split of tests that Travis runs in order to get the same random seed at the point the test runs. Even if this test never fails it still modifies the random seed which affects the reproducibility of subsequent random tests. I don't want to hold up the PR over the random tests though so please merge if you otherwise would. Note in the diff I showed above though that it's possible to compare the substituted results without using evalf. The Mathematica results are only valid if the matrix is invertible. Do the SymPy results hold more generally? If the formula is only valid under the assumption of invertibility then can we get a faster simpler result using inv()? E.g.: |
|
It's possible that part of the simplification problem is the fact that the matrix is not known to be invertible. The invertibility isn't embodied in any assumptions... We can make an almost arbitrary (needs a!=0) explicit invertible matrix like this: In [1]: b, c, d = symbols('b, c, d', complex=True, finite=True)
In [2]: a, e = symbols('a, e', complex=True, finite=True, zero=False)
In [3]: M = Matrix([[a, b], [c, b*c/a+e]])
In [7]: M
Out[7]:
⎡a b ⎤
⎢ ⎥
⎢ b⋅c⎥
⎢c e + ───⎥
⎣ a ⎦
In [4]: M.det().expand().is_zero
Out[4]: False
In [5]: simplify(M.pinv())
Out[5]:
⎡a⋅e + b⋅c -b ⎤
⎢───────── ───⎥
⎢ 2 a⋅e⎥
⎢ a ⋅e ⎥
⎢ ⎥
⎢ -c 1 ⎥
⎢ ─── ─ ⎥
⎣ a⋅e e ⎦
In [6]: M.inv()
Out[6]:
⎡a⋅e + b⋅c -b ⎤
⎢───────── ───⎥
⎢ 2 a⋅e⎥
⎢ a ⋅e ⎥
⎢ ⎥
⎢ -c 1 ⎥
⎢ ─── ─ ⎥
⎣ a⋅e e ⎦Unfortunately that still comes out very complicated with |
|
I am in favor of a single numerical tests. The numbers are different enough that any (wrong) change in the result will result in a test failure. |
|
Okay, I'm going to merge this, as I see it is being agreed on. On my second observation, the exact numeric tests were already done in here, but with simpler numbers, though. |
|
There was the question about using |
References to other Issues or PRs
#16209
Brief description of what is fixed or changed
With rank decomposition, we can finally get a valid routine that can apply for the most generic cases.
I don't think the gamble like
sympy/sympy/matrices/matrices.py
Lines 4061 to 4069 in 6979792
this offers any significant performance boost or such at this point, so I had rather added
methodoption and made the specific routine to private, so it can internally be used in some cases where matrix is guaranteed to be full rank.I have named rank-decomposition as
RDand diagonalization asdiag, but I would open a discussion about the naming.I also have an idea of naming diagonalization as
EDwhen used in keywords, which stands for Eigen-decompositionhttps://en.wikipedia.org/wiki/Eigendecomposition_of_a_matrix#Eigendecomposition_of_a_matrix
Also, I see the failing pseudoinverse test succeeding after this change, so I will further work on the tests, one for adding some tests for each methods, and the other for adding the failing test specific for the diagonalization routine.
At this point, SymPy's eigen solver is giving too verbose result, and quite poor in numeric stability after cubic polynomial roots formula is used.
Other comments
Release Notes
Matrix.pinvwill use rank decomposition by default.methodoption forMatrix.pinv