add auth and session design #501
Conversation
doc/auth_design.md
Outdated
|
|
||
| ```go | ||
| type Session struct { | ||
| ClientEndpoint string |
There was a problem hiding this comment.
What's the ClientEndpoint?
There was a problem hiding this comment.
Usually means IP:port, see: https://docs.oracle.com/javase/tutorial/networking/sockets/definition.html
doc/auth_design.md
Outdated
| Users can set auth information in SQLFlow extended SQL statement like: | ||
|
|
||
| ```sql | ||
| SET CREDENTIAL username secretkey |
There was a problem hiding this comment.
I'm not sure if a user inputs the credential in the notebook is a good way, due to such credential information might be exposed.
Don't mind too much about this, just take it as a reminder.
There was a problem hiding this comment.
Well, we should let user set the application keys, usually access key and secret key, please refer to: https://docs.aws.amazon.com/general/latest/gr/aws-sec-cred-types.html and https://usercenter.console.aliyun.com/#/manage/ak
| ClientEndpoint string | ||
| DBConnStr string // mysql://user:pass@127.0.0.1:3306 | ||
| Token int64 // useful only in "side-car" design | ||
| } |
There was a problem hiding this comment.
Should we consider the expired time to eliminate those zombie sessions?
There was a problem hiding this comment.
We should! Thanks!
doc/auth_design.md
Outdated
|
|
||
| <img src="figures/auth1.png"> | ||
|
|
||
| In production environments, one SQLFlow server is designed to accept many clients' |
There was a problem hiding this comment.
Maybe we can implement the Authentication and Authorization separated, for my brief idea:
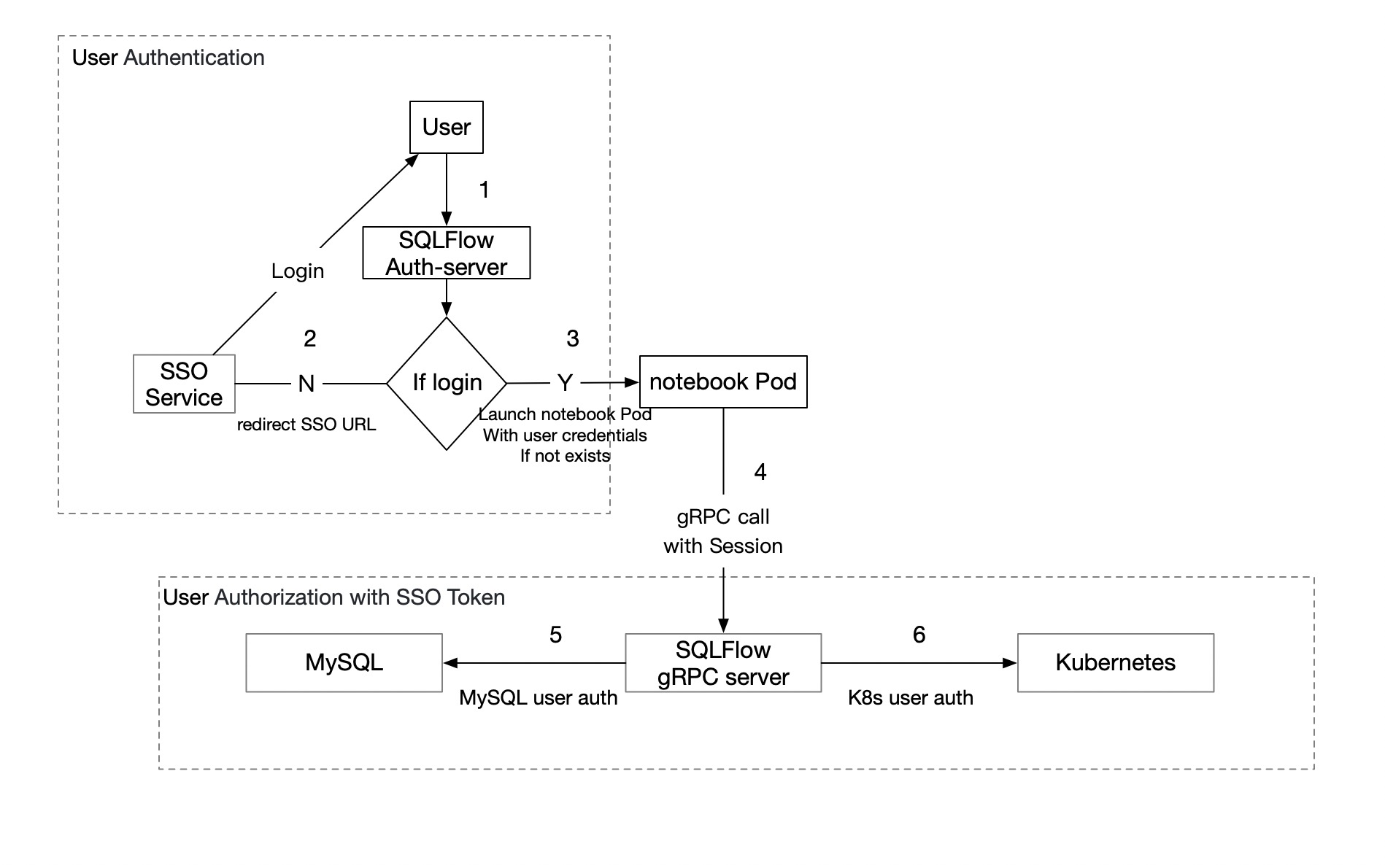
- Uses can go the SQLFlow website such as
https://sqlflow.domain.com, the auth-server would process the request and check the user. - If the user has not logged in, auth-server would redirect to the SSO URL with 302 redirections.
- If the user has logged in, the SQLFlow auth-server (maybe another name) would launch the notebook Pod if not exists with the user token as environment vars, and then redirect to the notebook URL.
- notebook would call the SQLFlow server with Session struct (fill the user token)
5/6. SQLFlow server instance would auth MySQL/kubernetes and etc. with the user token.
There was a problem hiding this comment.
Updated the design with some modifications.
doc/auth_design.md
Outdated
| type Session struct { | ||
| Token int64 // useful only in "side-car" design | ||
| ClientEndpoint string // ip:port from the client | ||
| DBConnStr string // mysql://127.0.0.1:3306 |
There was a problem hiding this comment.
Is the schema "mysql://" what we invented to help identify the kind of SQL engines? I ask because I think an address of MySQL server is something like http://user:passwd@127.0.0.1:3306, but not beginning with mysql://....
If so, how about we have
DBKind string // can be "mysql", "hive", ...
DBConnStr string // e.g., "http://user:passwd@127.0.0.1:3306"There was a problem hiding this comment.
Is the schema "mysql://" what we invented to help identify the kind of SQL engines?
Yes. The string before :// is the "driver string, can be mysql://, hive:// or odps://
doc/auth_design.md
Outdated
|
|
||
| To make it modulized and extensible, we prefer to introduce an authentication server, a.k.a., auth server. We use a | ||
| [Django](https://www.djangoproject.com/) Web server so that the authentication methods | ||
| can extend to: |
There was a problem hiding this comment.
Good to know that Django has so many features. Do we need to write code on top of Django, or we only need to configure and run the Django server for authentication?
There was a problem hiding this comment.
Oh, I need to delete these lines, the latest design does not involve a Django server. All the authentication and authorization should be done by the jupyter notebook
doc/auth_design.md
Outdated
| - Database service that stores the training data | ||
| - A training cluster that runs the SQLFlow training job, e.g. Kubernetes | ||
|
|
||
| SQLFlow should depend on the [SSO](https://en.wikipedia.org/wiki/Single_sign-on) |
There was a problem hiding this comment.
Why should SQLFlow use SSO? What are other choices?
There was a problem hiding this comment.
Using JupyterHub, we can add any type of authenticators including SSO, Kerbros, etc, :https://github.com/jupyterhub/jupyterhub/wiki/Authenticators
doc/auth_design.md
Outdated
| Token int64 // useful only in "side-car" design | ||
| ClientEndpoint string // ip:port from the client | ||
| DBConnStr string // mysql://127.0.0.1:3306 | ||
| AK string // access key |
There was a problem hiding this comment.
Do we need only one pair of AK and SK? Or do we need multiple pairs, like one for the SQL engine and the other one for Kubernetes?
doc/auth_design.md
Outdated
|
|
||
| ```go | ||
| type Session struct { | ||
| Token int64 // useful only in "side-car" design |
There was a problem hiding this comment.
What is a side-car design?
Does the token identify an SQLFlow service user who has logged in?
There was a problem hiding this comment.
Removed, it's not useful anymore.
doc/auth_design.md
Outdated
| Once the user is logged in, SSO service will return the "token" represents the user's | ||
| identity. Then the web IDE will call the "Auth Service" to get AK/SK for the database and | ||
| training cluster. After that, the web IDE will call SQLFlow RPC service to create | ||
| a new session, and the SQLFlow server will verify that all tokens, AK/SK are valid, then |
There was a problem hiding this comment.
Does the "to create a new session" imply that we need to change the gRPC service definition to add a remote call named SQLFlowService.CreateSession?
There was a problem hiding this comment.
Yes, I'll add the new RPC defination in this doc
| Authorization is not a too much a challenge because we can rely on | ||
| SQL engines and training clusters, which denies requests if the user | ||
| have no access. In this document, we focus on authentication of SQLFlow users. | ||
|
|
There was a problem hiding this comment.
I assume that we should clarify the concept of the "client" in this section. A client of SQLFlow server might be the SQLFlow magic command, which is an extension to Jupyter Notebook server, or a Windows-native or macOS-native GUI program. It looks to me that we introduce an authentication server because we want to support both kinds of clients?
doc/auth_design.md
Outdated
|
|
||
| Users can use SQLFlow server with a simple jupyter notebook for simple deployment, | ||
| for production deployments, users can take advantage of the cloud web IDE. The web | ||
| IDE will redirect a user to the SSO service if the user is not logged in. |
There was a problem hiding this comment.
Why would "the web IDE" redirect a user to the SSO service"? Is it configured to do so? Could users use Jupyter Notebook as their "web IDE"? If so, how should they configure it to work with SSO? And, how comes the SSO service? Who is supposed to build it?
There was a problem hiding this comment.
Removed all "web IDE" stuff and move to "JupyterHub"
doc/auth_design.md
Outdated
|
|
||
| Users can use SQLFlow server with a simple jupyter notebook for simple deployment, | ||
| for production deployments, users can take advantage of the cloud web IDE. The web | ||
| IDE will redirect a user to the SSO service if the user is not logged in. |
There was a problem hiding this comment.
I know how to connect to a Jupyter Notebook server running on my laptop -- I need to copy-and-paste a URL containing a token printed by the Jupyter Notebook server on my console into my Web browser, so could I access the server while identify myself. However, I don't understand how am I supposed to identify myself to a Jupyter Notebook server running remotely as part of a Kubernetes service. Do you know how could we do that? Or, does this document imply that there is a Jupyter Notebook service there on a Kubernetes cluster?
doc/auth_design.md
Outdated
| identity. Then the web IDE will call the "Auth Service" to get AK/SK for the database and | ||
| training cluster. After that, the web IDE will call SQLFlow RPC service to create | ||
| a new session, and the SQLFlow server will verify that all tokens, AK/SK are valid, then | ||
| the session will be stored. |
There was a problem hiding this comment.
To where "the session will be stored"? To the etcd cluster?
There was a problem hiding this comment.
@wangkuiyi I've updated the design doc on the basis of recent surveys.
…flow into add_auth_and_session_design
…oonzero/sqlflow into add_auth_and_session_design
Fix #399
Fix #496