-
Notifications
You must be signed in to change notification settings - Fork 292
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Updates ml/clean-feature/bian-liang-fen-xiang-fang-fa/zui-you-qia-fan…
…g-fen-xiang-fa.md Auto commit by GitBook Editor
- Loading branch information
Showing
9 changed files
with
134 additions
and
1 deletion.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,16 @@ | ||
| ## 无监督编码 | ||
|
|
||
| onehot编码 | ||
|
|
||
| Dummy编码 (不推荐) | ||
|
|
||
| Label编码 | ||
|
|
||
| ## 有监督编码 | ||
|
|
||
| WOE编码 | ||
|
|
||
|  | ||
|
|
||
|
|
||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,36 @@ | ||
| 变量分箱的好处: | ||
|
|
||
| 1. 降低异常值影响,增加模型稳定性 | ||
| 2. 缺失值作为特殊变量参与分箱,减少缺失值填补的不确定性 | ||
| 3. 增加变量的可解释性 | ||
| 4. 增加变量的非线性 | ||
| 5. 增加模型的预测效果 | ||
|
|
||
| 变量分箱的局限性 | ||
|
|
||
| 1. 同一箱内的样本具有同质性 | ||
| 2. 需要专家经验支持 | ||
|
|
||
| 需要注意 | ||
|
|
||
| 1. 分箱结果不能过多,不能过少 | ||
| 2. 分箱后的单调性 | ||
|
|
||
|
|
||
|
|
||
| 变量分箱流程: | ||
|
|
||
|  | ||
|
|
||
| 1)选择优化指标,可以选择卡方值、KS值、IV值等作为优化指标,以判断最优切分点;同时初始化分箱数nbin=1,开始认为只有1箱,通过切分的方式得到最优分箱结果。 | ||
|
|
||
| 2)初始化切分点,对于连续变量采用等距离初始化方法,并且要满足组间距离不能太小的约束条件;对于离散变量可以将变量的取值作为切分点,如果变量非常稀疏,则可以先用坏样本比率数值化,然后按照连续变量分箱操作。切分点即为分箱合并的候选集,可以初始化100个切分点,然后分别计算在切分点处的目标函数值,通过切分点分裂的方式从初始化箱数为1逐步达到最优分箱结果。(注意:分箱可以消除异常值的影响,但是异常值会影响初始化切分点的选择。例如,初始化分箱数是100,采用等距离初始化方法。如果存在异常值,则会出现切分点的间隔较大,数据分布不均,即靠近异常值的箱内样本分布较少,而在某些箱内样本分布较多的情况。因此,初始化切分点钱要做异常值处理。) | ||
|
|
||
| 3)初始化切分点后,要判断不同切分点间的最小样本数是否小于最小样本数约束。如果小于最小样本数,则重新进行切分点选择,即采用切分点合并的方式,将临近的切分点合并,以满足最小样本数的约束。 | ||
|
|
||
| 4)随后在最大分箱数的约束下进行切分点选择,如果大于最大分箱数,则分箱结束。 | ||
|
|
||
| 5)如果小于最大分箱数,则先计算最优切分点,以每个初始化切分点为边界,分别计算在此分箱后的优化指标值,选择最优的指标值对应的切分点作为最优切分点。 | ||
|
|
||
| 6)得到最优切分点后要计算增益值,判断当前分箱策略下的优化指标是否由于前一次分箱得到的优化指标值,如果分箱溢价无法得到更优的指标值或指标值增加的速度明显变缓,则分箱结束,满足Earlystopping约束条件。如果增益明显增加则分箱数增加,直到满足最大分箱约束条件后分箱结束。 | ||
|
|
18 changes: 18 additions & 0 deletions
18
ml/clean-feature/bian-liang-fen-xiang-fang-fa/best-ksfen-xiang-fang-fa.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,18 @@ | ||
| Best-KS分箱方法是一种自顶向下的分箱方法。与卡方分箱相比,Best-KS分享方法只是目标函数采用了KS统计量,其余分箱步骤没有差别。这里介绍KS统计量的计算方法与目标变量之间的关系。 | ||
|
|
||
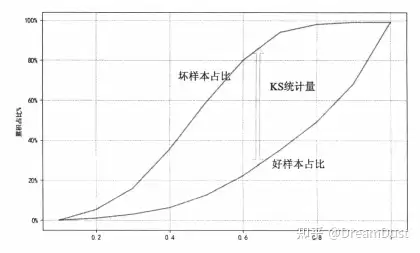
| KS统计量用于评估模型对好坏样本的区分能力。K-S曲线的绘制方法:做变量排序,以变量的某个值为阈值点,统计样本中好坏样本占总样本中的好坏样本分别的比例。随着变量阈值点的变化,这两个比值也随之改变,这两个比值之差的最大值就是KS统计量。 | ||
|
|
||
|  | ||
|
|
||
| 如果采用模型预测的概率值排序,分别计算在不同概率下好坏样本的累计比,所得到的K-S曲线与K-S统计量就可以用来衡量模型的预测效果。如果横坐标是变量排序后的变化值,纵坐标为不同变量取值下的好坏样本数与总体样本中好坏样本数的比,那么此时的K-S曲线与K-S统计量就可以用来评估变量分箱中的最优切分点。 | ||
|
|
||
| K-S统计量的计算过程如下: | ||
|
|
||
| 1)将变量进行升序排序,确定初始化阈值点候选集,离散变量可以直接采用变量的可能取值作为候选集,连续变量可以先进行分组,如分10组,将每组的边界作为阈值点。 | ||
|
|
||
| 2)分别计算在小于阈值点的样本中,好坏样本与总体好坏样本数的比值。 | ||
|
|
||
| 3)将好坏样本比值的差作为各个切分点的KS统计值。 | ||
|
|
||
| Best-KS分享方法不适用于不可排序的离散变量,因为排序没有意义,该方法更适合连续变量的分箱过程。此外,Best-KS方法只能对二分类问题进行分箱操作,基于这些局限性在变量处理的时候需要留意。 | ||
|
|
28 changes: 28 additions & 0 deletions
28
...-feature/bian-liang-fen-xiang-fang-fa/ji-yu-shu-de-zui-you-fen-xiang-fang-fa.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,28 @@ | ||
| 基于树的分箱方法借鉴了决策树在树生产的过程中特征选择(最优分裂点)的目标函数来完成变量分箱过程,可以理解为单变量的决策树模型。决策树采用自顶向下的方法进行树的生成,每个节点的选择目标是为了分了结果的纯度更高,也就是样本的分类效果更好。因此不同的损失函数有不同的决策树,ID3采用信息增益方法,C4.5采用信息增益比,CART采用基尼系数(Gini)指标。这里主要介绍采用信息增益作为目标函数进行变量分箱的过程。 | ||
|
|
||
| 概率是表示随机变量确定性的度量,而信息是随机变量不确定性的度量。信息熵是不确定性度量的平均值,就是信息平均值。定义为: | ||
|
|
||
| 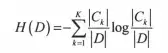 | ||
|
|
||
| 其中k表示类别个数,Ck表示在第k个类别的样本数,D表示样本总数。严格来说这属于经验熵。 | ||
|
|
||
| 熵与纯度对应,熵越大不确定度越大,纯度越低。熵越小不确定度越小,纯度越高。纯度就是类别的多少,只有一种类别纯度最高,所以在对一直变量进行分箱时,如果在某个切分点进行分箱,使得变量的信息熵下降,则得到最佳分箱切分点,衡量信息熵下降的指标就是信息增益。定义为: | ||
|
|
||
| 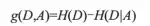 | ||
|
|
||
| 其中H\(D\)表示原始数据集中类别属性的不确定性;H\(D\|A\)为条件熵,表示变量在某一切分点下分箱后类别属性的不确定性。信息增益表示变量在某一切分点下分箱后对得知类别属性的信息不确定性减少的程度,也就是类别属性纯度增加的程度。在样本给定后,原始数据集中类别属性的信息熵H\(D\)就已经确定了,分箱调整的是在不同的切分点处得到的条件熵不同,将那些条件熵小的切分点作为最优切分点完成分箱。条件熵的计算公式如下: | ||
|
|
||
| 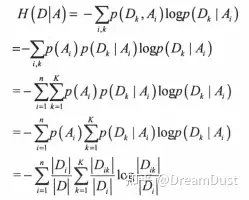 | ||
|
|
||
| 其中n表示变量分箱的个数。注意在最优切分点选择时,每次切分为2箱,此时n=2;而经过多次切分后得到多个箱,此时要评估当前分箱数下的条件熵,则此时n等于到当前时刻的分箱数。Di表示第i个划分中样本个数,D表示样本总数;K表示类别种类,本例中为二分类K=2。 | ||
|
|
||
| 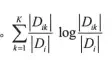 | ||
|
|
||
| 表示变量在第i个分类下的信息熵,即计算在某个切分点分箱后,每个箱内类别属性的信息熵,然后再与该箱内样本数与总体样本数的比值相乘后做加权求和。其中还Dik表示第i个划分下第K个类别的样本数,Di表示第i个划分下的总样本数。 | ||
|
|
||
| 信息增益越大,表示本次分箱下样本类别属性的不确定性越小,纯度越高,对好坏样本的分类效果越好。如果能通过分箱的方式将好坏样本完美地分开,那么这就是最好的分箱结果。 | ||
|
|
||
| 可以将公式两边都除以类别的信息熵,类似归一化的过程,信息增益的公式就变换为如下无量纲的形式: | ||
|
|
||
| 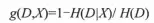 | ||
|
|
20 changes: 20 additions & 0 deletions
20
ml/clean-feature/bian-liang-fen-xiang-fang-fa/zui-you-qia-fang-fen-xiang-fa.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,20 @@ | ||
| Chi-merge卡方分箱方法是一种自底向上的分箱方法,其思想是将原始数据初始化为多个数据区间,并对相邻区间的样本进行合并,计算合并后的卡方值,用卡方值的大小衡量相邻区间中类分布的差异情况。如果卡方值较小,表面该相邻区间的类分布情况非常相似,可以进行区间合并;反之,卡方值越大,则表面该相邻区间的类分布情况不同,不能进行区间合并操作。卡方值计算公式如下: | ||
|
|
||
| 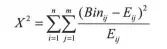 | ||
|
|
||
| 其中n表示区间数,因为是相邻区间进行合并,所以n=2;m表示类别数,如二分类m=2。Eij表示第i个区间第j个类别的期望值,计算方式是第j个类别在总体样本中的占比乘以第i个区间的全部样本数。Binij表示第i个区间第j类样本的个数。 | ||
|
|
||
| 假设样本总数为1000,坏样本与好样本的样本量分别为300和700,计算如图: | ||
|
|
||
| 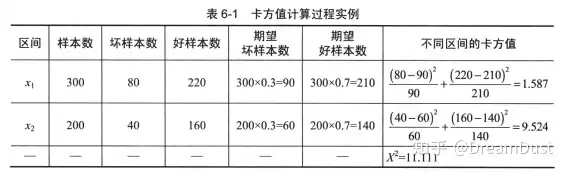 | ||
|
|
||
| 上述过程就是一个卡方检验的过程,因此,根据置信度和自由度可以计算出卡方检验的阈值,当计算的卡方值小于阈值,则认为相邻区间的类分布情况相似,可进行合并。其中自由度为类别个数减1,置信度可以用0.9、0.95和0.99。 | ||
|
|
||
| 另外计算两个卡方值,两者相加即为合并后样本的卡方值。在卡方分箱合并的使用中,每个卡方值都是在检验该区间的类分布情况与总体样本的类分布情况是否相同,卡方值只是衡量这种相似程度的一个量化表示,而两个区间可以合并的前提就是:每个区间的类分布情况都与总体相似,合并后的类分布情况也将与总体的样本分布情况相似,因此可以合并。如果一个区间与总体的类分布情况相似而另一个区间与总体的类分布情况不想死,加和后的卡方值将更大,就不能将这两个区间进行合并。 | ||
|
|
||
| 自底向上的思想是由多至少逐层合并的过程,自顶向下是有少至多逐层切分的过程。为了统一要将卡方自底向上的思想改为自顶向下的方式实现。因此只需要每次切分时令卡方值最大即可(后续采用这种方法)。 | ||
|
|
||
| 在实际进行分箱操作时,如果采用阈值判断的方式,如果不加限制可能导致结果不收敛,从而得到的分箱数太多而失去分箱的意义。因此,实际引用时往往要限制最大分箱数。 | ||
|
|
||
| 基于分箱流程,卡方分箱方法就是目标函数是卡方值,在一定约束条件下的优化问题,约束条件可以自由选择不需要全部使用。根据卡方值的计算公式可知,该方法既可以在二分类问题中,也可以用于多分类中进行变量分箱,同时,对离散变量和连续变量也均适用。 | ||
|
|
8 changes: 8 additions & 0 deletions
8
ml/clean-feature/bian-liang-fen-xiang-fang-fa/zuiyou-iv-fen-xiang-fang-fa.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,8 @@ | ||
| 最优IV分箱方法也是自顶向下的分箱方式,期目标函数为Information Value值。IV值的计算是在WOE值的基础上演化而来的。 | ||
|
|
||
| 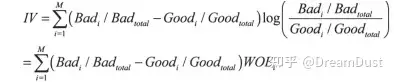 | ||
|
|
||
| 其中M为分组的个数,本例中为自顶向下的分箱方式采用的二叉树的方式,因此M=2。Goodi和Badi分别为以不同切分点划分后第i组内好坏样本的个数,Goodtotal和Badtotal为总体样本中好坏样本的个数。 | ||
|
|
||
| IV值本质是对陈华的K-L距离,即在切分点处分裂得到的两部分数据中,选择好坏样本的分布差异最大点作为最优切分点。分箱结束后,计算每个箱内的IV值加和得到变量的IV值,可以用来刻画变量对目标值的预测能力。即变量的IV值越大,则对目标变量的区分能力越强,因此IV只还可以用来做变量选择。 | ||
|
|