An implementation of Decision tree and Random Forest models for classification and regression tasks from scratch. A few sample datasets like Iris, Breast cancer and Boston Housing dataset are also included in the repo for testing purposes.
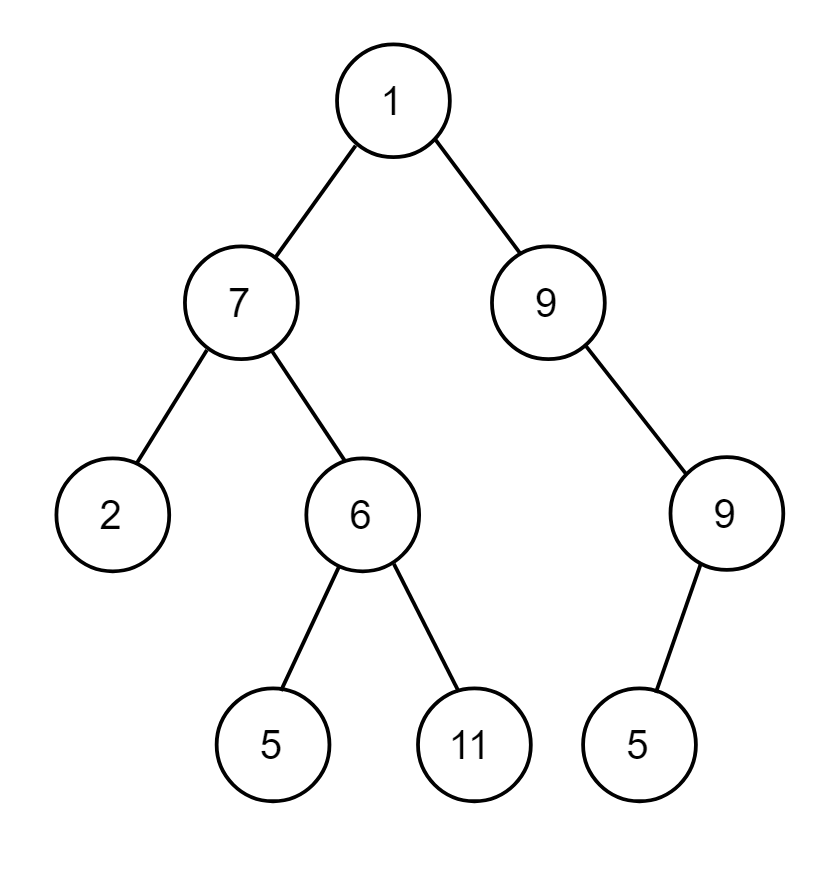
Decision tree divides the feature space into hyper rectangles, which minimize the impurity/variance of the labels in the resulting hyper rectangles. In this implementation, this mechanism is replicated using the binary tree data structure, and the regions/hyper-rectangles are represented by leaf nodes in the tree.
For classification, the majority label of samples in the leaf node is chosen as the final prediction and for regression, the average of the labels of the samples in the leaf node is chosen as the final prediction.
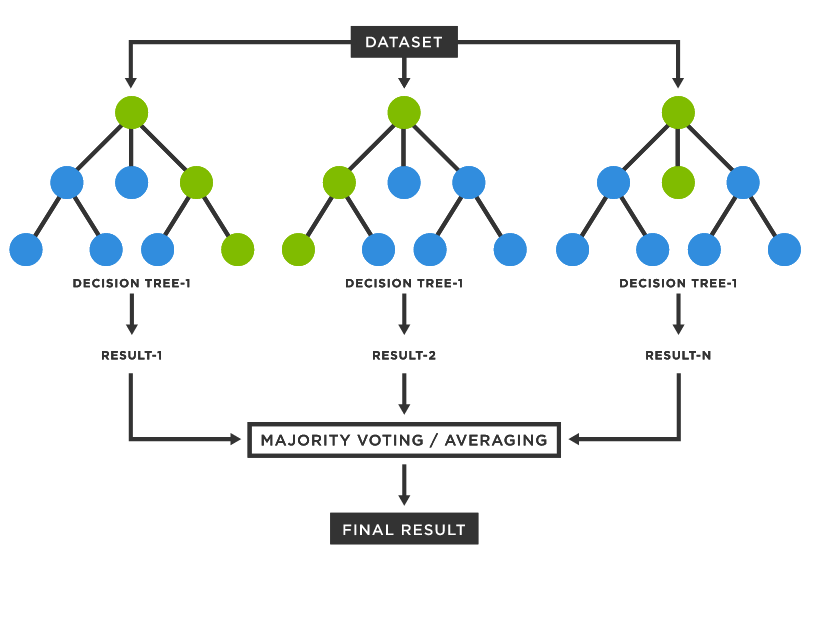
Random Forest is an ensemble of Decision Tree classifiers, which are trained following a bagging method. After training, the predictions of the base estimators are combined to generate the final robust prediction. In case of classification, a majority vote is chosen as the final prediction and in case of regression, an average is taken of the predictions of the base estimators.
To learn how to implement the models created in this repo, check out the tutorial ipython notebook, copy the notebook to google colab or local jupyter notebook and follow the cloning cells to load the files into runtime environment.
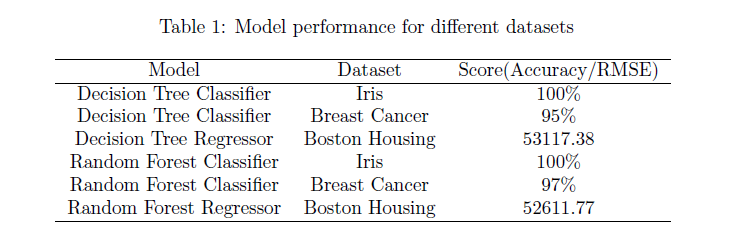
The models implemented for this project are not optimized for computational efficiency and take a lot of time for training. In order to speed of computation, paralell processing can be employed, for example to train each of the individual base estimators in the Random Forest model, we can assign the tasks to multiple processors as they are independent processes. Also additional hyper-parameters can be added to the models for tuning for higher performance and flexibility
Video explanation : https://drive.google.com/file/d/1K7jlJ0__fCouihY8uBvrHh1_XOltPsys/view?usp=sharing