我们基于GAGAvatar开发了可语音驱动的3D数字人模型。
如下图所示 .
.
我们的方法包含两个分支:重建模块与表情驱动模块。我们使用双提升方法(dual-lifting)生成头部高斯从而得到初步结果,然后使用神经渲染器(neural renderer)获得优化结果。我们利用DiffPoseTalk强大的生成能力将语音映射为FLAME模型参数,从而驱动头部口型变化。

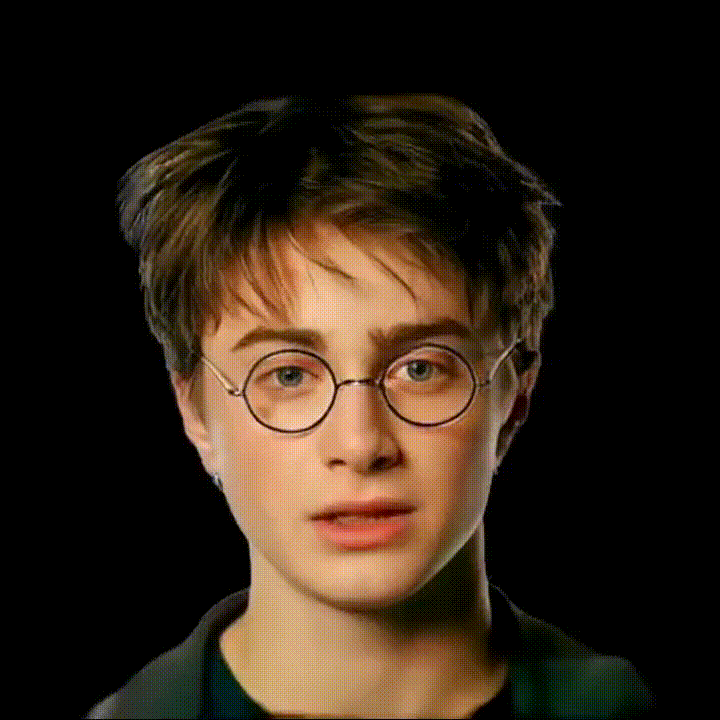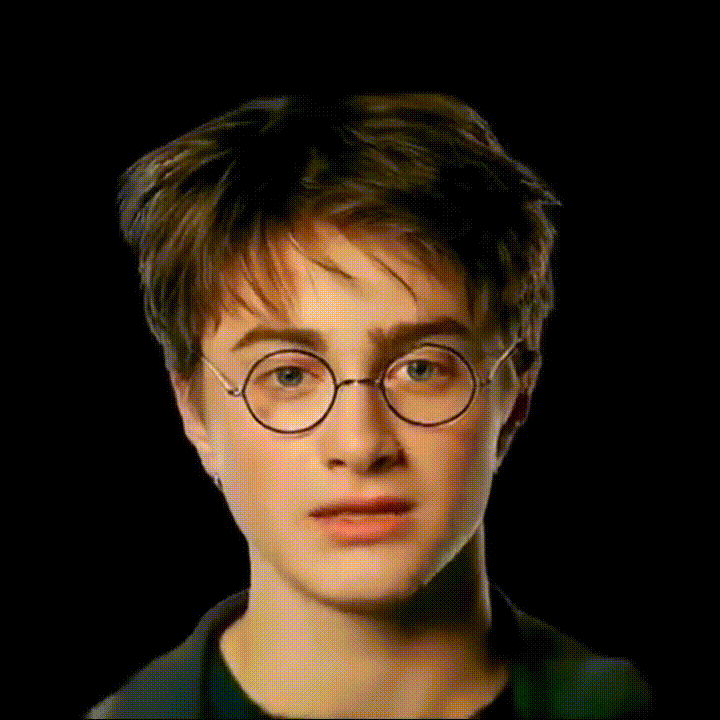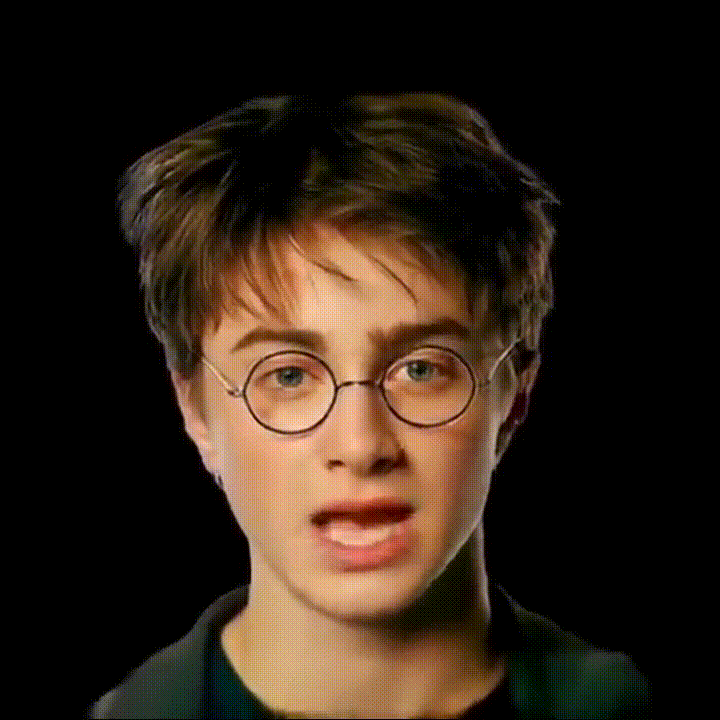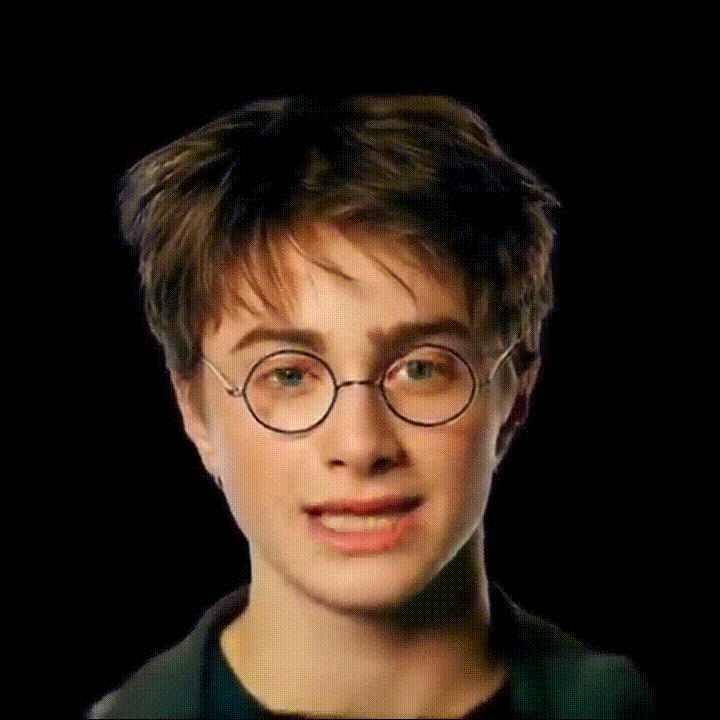


conda env create -f /data/fuxiaowen/talkinggaga/environment.yml
talkinggaga/GAGAvatar/diff-gaussian-rasterization需要按GAGAvatar指引安装
运行talkinggaga/GAGAvatar/test.py