- 개발기간
- 2022.07.22 ~ 2022.07.27
- 사용 언어 및 라이브러리
python,pandas,sklearn,matplot,seaborn
- DASS 설문조사 결과를 활용하여 세 가지의 부정적인 감정 척도를 예측하는 시스템
- AI 부트캠프 Section2 Project
현대 사회에 우울증, 불안, 스트레스와 같은 부정적인 감정을 가지고 살아가는 사람들이 많다. 2020년 상반기 20대 여성 우울증 환자가 39.5% 증가하였고, 20대 불안 장애 환자는 86%, 스트레스 장애 환자는 5년 간 45.4% 증가하였다.
부정적인 감정으로 인해 더욱 무기력해지고 힘들어 지게 되는 것을 방지하고자 자신의 감정 상태를 예측하고 관리할 수 있는 시스템이 필요하다고 생각한다.
- 프로젝트 기획 및 문제 정의
- 데이터 수집
- 데이터 탐색 및 전처리
- 모델링
Depression Anxiety Stress Scales Responses
- 우울, 불안, 긴장 또는 스트레스와 관련된 부정적인 감정 상태를 측정하도록 설계된 DASS 설문조사 결과 데이터
- DASS의 42가지 설문, 10개 항목의 성격 목록, 정의를 알고 있다고 확신하는 단어를 선택하는 목록, 기타 개인 정보 등을 담고 있는 172개의 columns와 39775개의 row로 구성된 csv 파일 데이터
-
Data Description
- 데이터의 각 항목과 척도가 의미하는 바를 파악
-
데이터 전처리
- Data Descripation 과정을 통해 필요없다고 판단되는 컬럼을 제거.
- 모든 컬럼의 데이터형, 결측값을 확인한 후 컬럼 이름을 알기 쉽게 변경.
- 42가지의 설문 중 우울, 불안, 스트레스에 해당하는 문항 번호를 dictionary로 만들어주어 우울, 불안, 스트레스 문항에 따른 점수의 합계를 추출.
- 우울, 불안, 스트레스를 Scoreing Guide에 따라 Normal, Mild, Moderate, Severe, Extremely Severe 총 5개의 지표로 카테고리 함.
-
EDA
- 시각화를 진행하여 데이터 Feature의 분포를 파악
- 분포를 보며 이상치의 값을 가진 Feature는 기준을 가지고 이상치를 제거함.
-
가설 검증
-
문제를 정의하며 설정한 2가지의 가설을 검증
-
가설 1 : 연령별 부정적인 감정이 나타나는 빈도에 차이가 있을 것이다.
- 우울증 척도가 ‘Extremely serve’인 사람들의 평균 나이가 ‘Moderate’인 사람들의 평균 나이보다 큰지를 귀무가설과 대립가설을 세워 판단하고자 함.
귀무가설 : 우울증 척도가 ‘Extremely serve'인 사람들의 평균 나이는 'Moderate'인 사람들의 평균 나이보다 작거나 같다.
대립가설 : 우울증 척도가 ‘Extremely serve'인 사람들의 평균 나이는 'Moderate'인 사람들의 평균 나이보다 크다.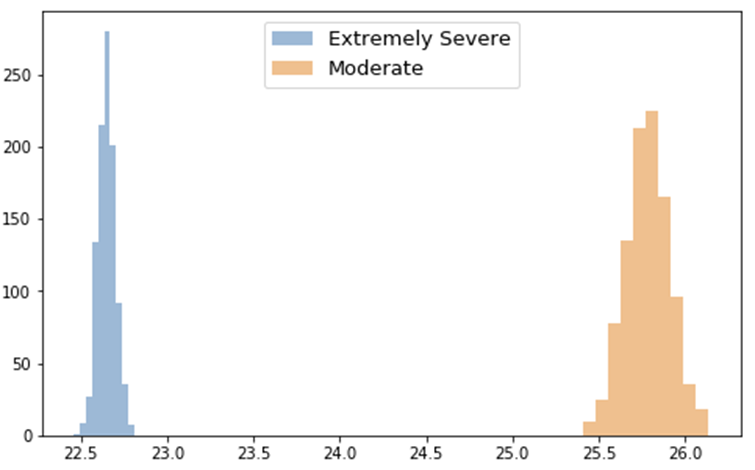
왼쪽의 파란색 분포는 우울증 척도가 ‘Extremely Serve’인 사람들의 평균 나이 표본 분포이고, 오른쪽의 주황색 분포는 우울증 척도가 ‘Moderate’인 사람들의 평균 나이 표본 분포임. 우울증 척도가 ‘Extremely Serve’인 사람들의 평균 나이는 척도가 ‘Moderate’인 사람들의 평균 나이보다 작다는 것을 알 수 있으므로 귀무 가설을 채택함.
-
가설 2 : 우울증, 불안, 스트레스와 같은 감정들은 같이 올 것이다.
- 데이터들의 비율을 통해 판단하고자 함.
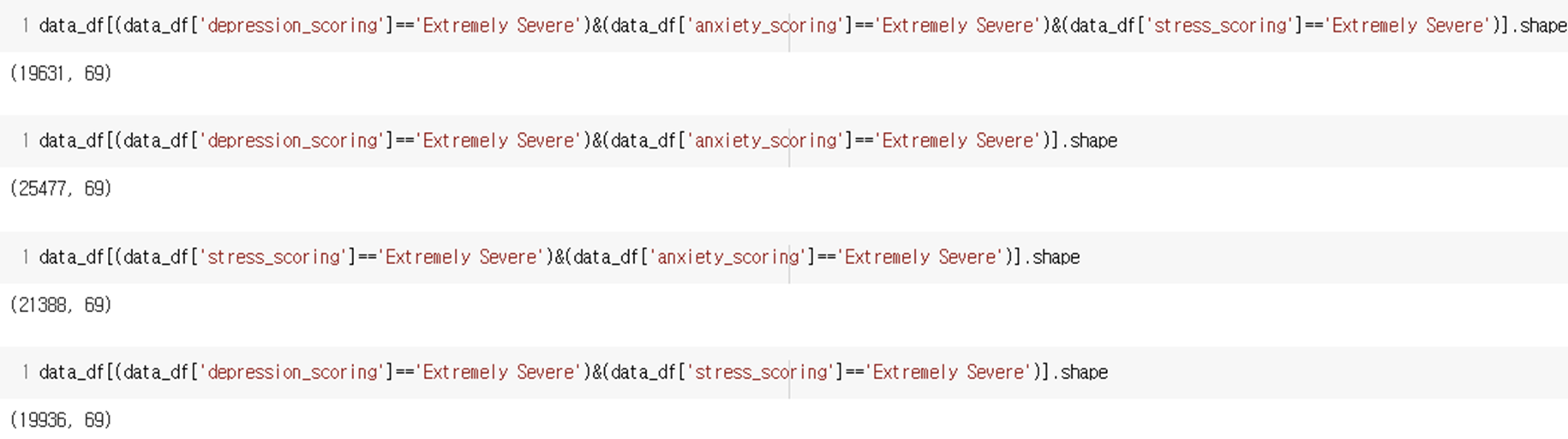
우울증과 불안, 불안과 스트레스, 우울증과 스트레스가 ‘Extremely Serve’한 경우의 데이터 수는 전체 데이터 수의 0.5~0.6%의 비율을 가지고 있음. 우울증과 불안의 감정은 같이 올 가능성이 높고, 우울증과 스트레스는 경우에 따라 다르지만 절반 이상의 데이터에서 같이 오는 것으로 보아 세 감정은 같이 올 것이라 판단함.
-
-
Target Feature 설정
- 가설 검증을 통해 세 가지 감정이 같이 올 것으로 판단하였으므로 우울, 불안, 스트레스 점수의 합계인 ‘total_count’ 컬럼을 생성.
- total_count 컬럼의 4분위 수를 기준으로 5개의 범주로 카테고리화하여 target feature를 설정함.
-
모델링
-
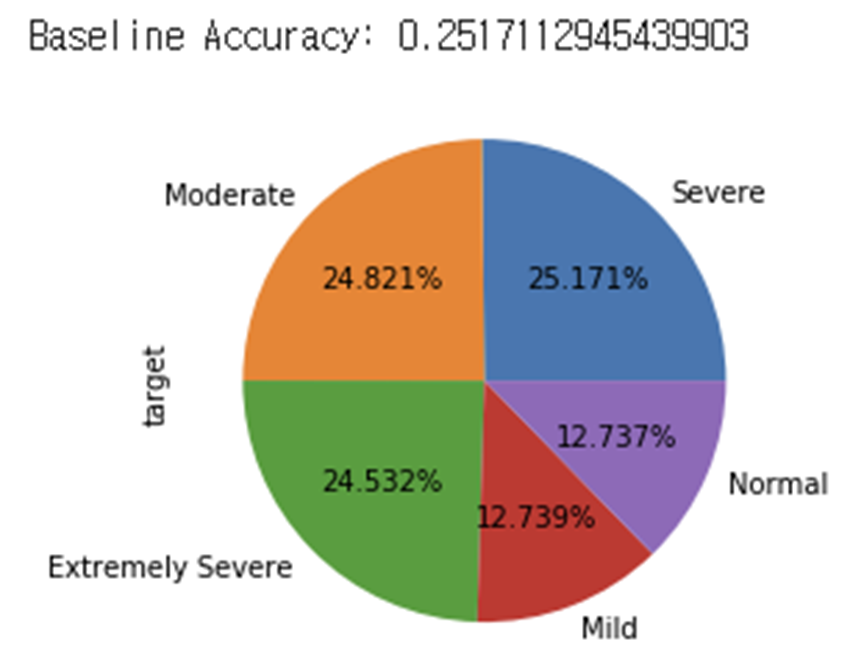
타겟의 값 중 최빈값을 기준모델로 설정함.
-
랜덤포레스트와 XGBoost의 개념과 차이점을 살펴본 후 두 모델의 성능을 비교
-
랜덤포레스트를 사용한 검증 데이터셋 정확도 0.750393, XGBoost를 사용한 검증 데이터셋 정확도 0.822271
-
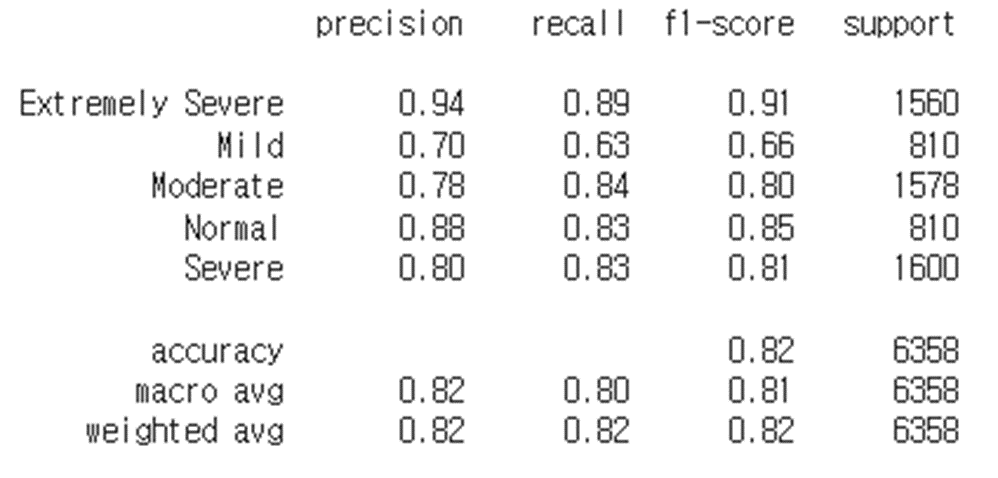
XGBoost 검증 데이터 셋 평가지표
-
XGBoost 검증 데이터 셋 Confusion Matrix
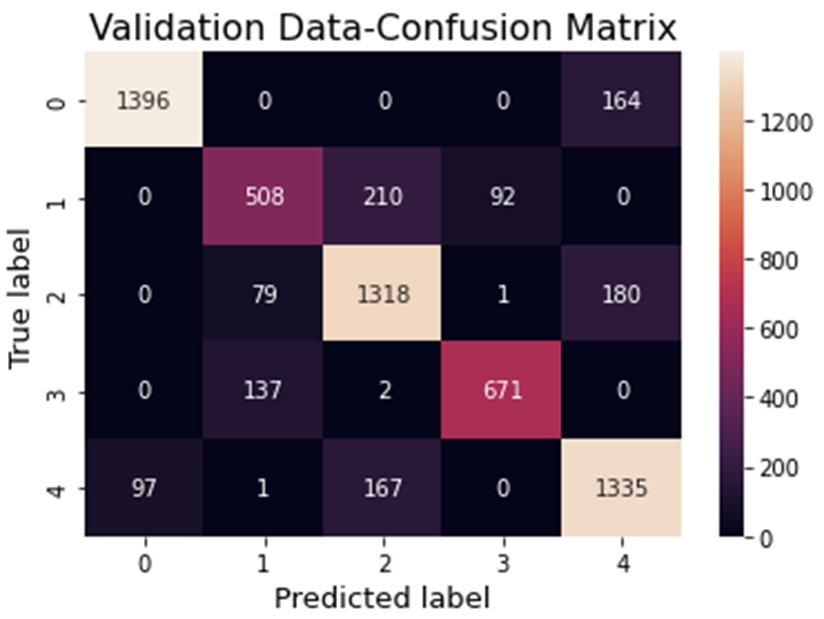
-
XGBoost를 사용하여 Test Set Accuracy : 0.820457
-
특성 중요도를 통해 모델이 중요하게 본 특성을 파악함
-
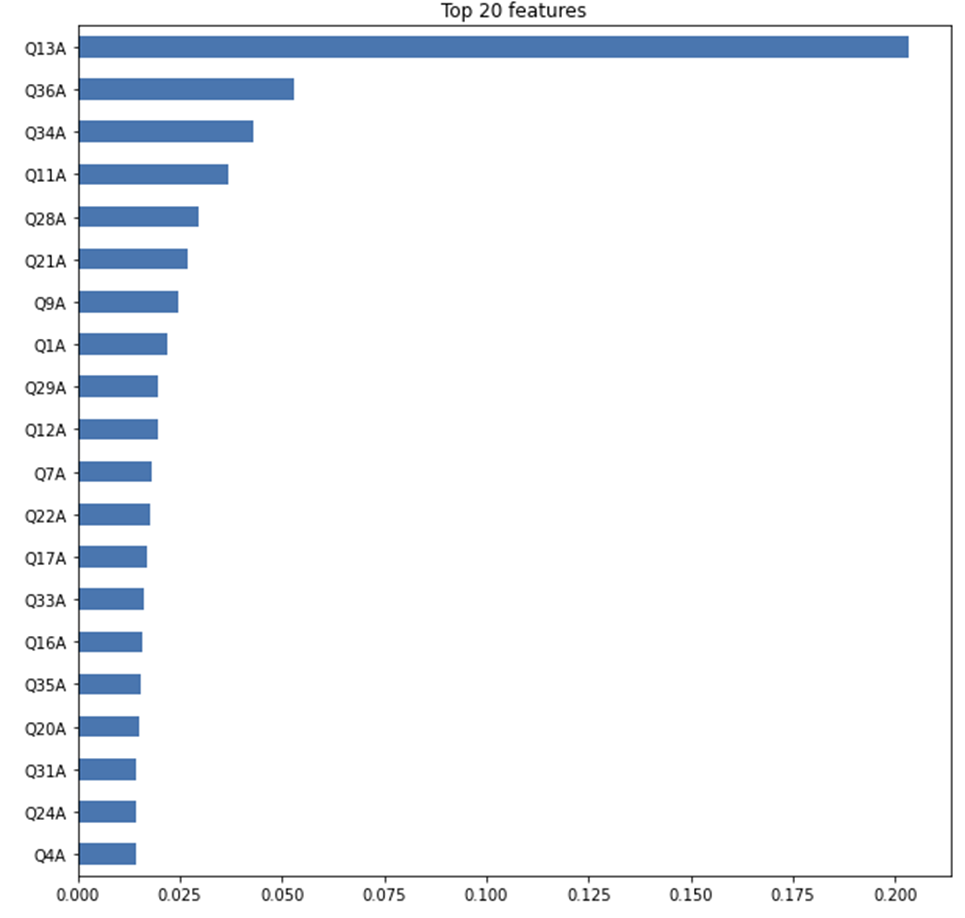
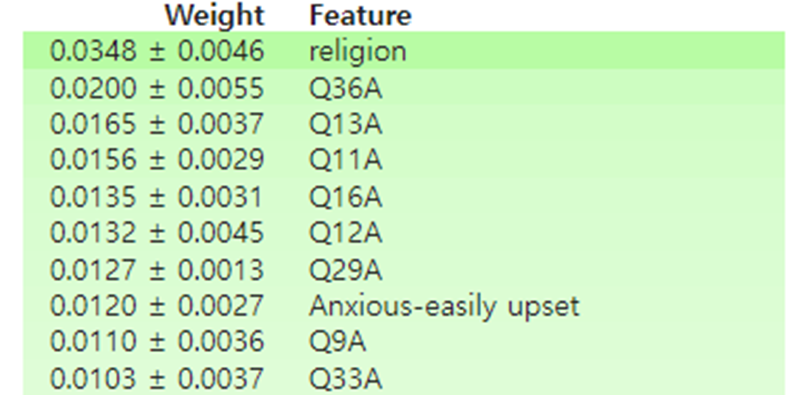
- 문제에 대해
가설을 세우고 검증하면서 데이터를 분석하는 방법을 익히게 되었음. - 모델의 최소한의 성능을 나타내는 기준인
baseline을 세우는 것의 중요성을 알게 되었음. 랜덤포레스트와XGBoost모델을 사용해보면서 두 모델의 개념을 배울 수 있었음.- 모델의
특성중요도를 살펴보며모델을 해석하는 과정을 배울 수 있었음.