Cloud Dataflow is a managed service for executing a wide variety of data processing patterns.
This documentation shows you how to deploy your batch pipelines using Cloud Dataflow in Java. The goal here is to create a pipeline to load data from a CSV file to BigQuery table.
- Eclipse 4.6 +
- JDK 1.8+
- GCP account
- GCS and BigQuery enabled
- Service account
Follow this page to install Cloud SDK.
https://cloud.google.com/sdk/docs/quickstart-windows
Install Cloud Tools for Eclipse by following this page:
https://cloud.google.com/eclipse/docs/quickstart
Create a new project through New Project wizard.
Select Google Cloud Dataflow Java Project wizard. Click Next to continue.
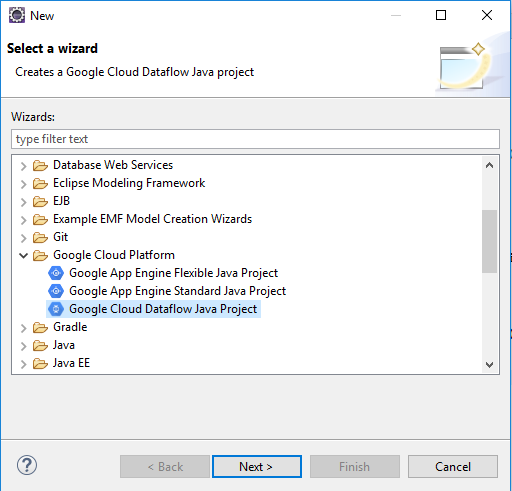
Input the details for this project:
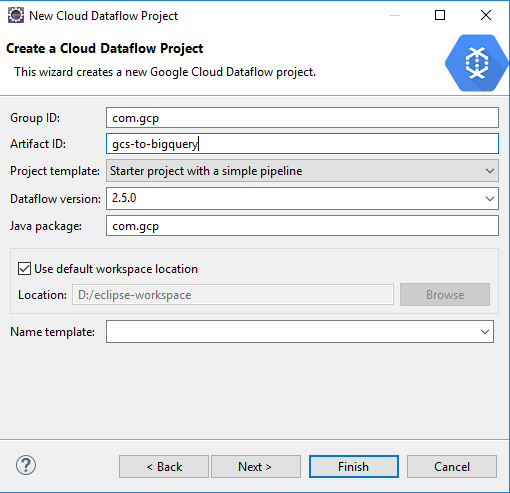
Click Next. Setup account details:
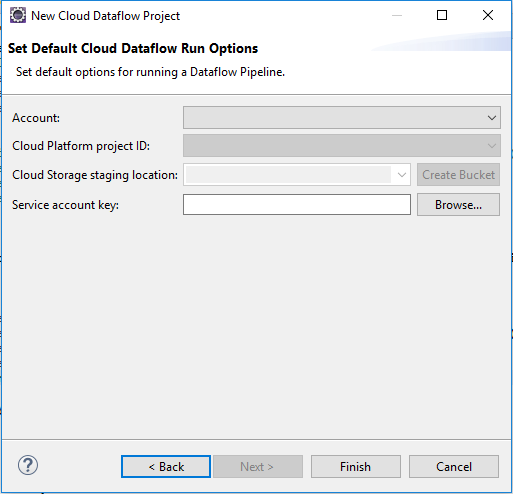
Click Finish to complete the wizard.
Run Maven Install to install the dependencies. You can do this through Run Configurations or Maven command line interfaces.
Upload the CSV file into a bucket.
Refer the code from class CsvToBQPipeline and create a new one.
Create a run configuration for Dataflow pipeline:
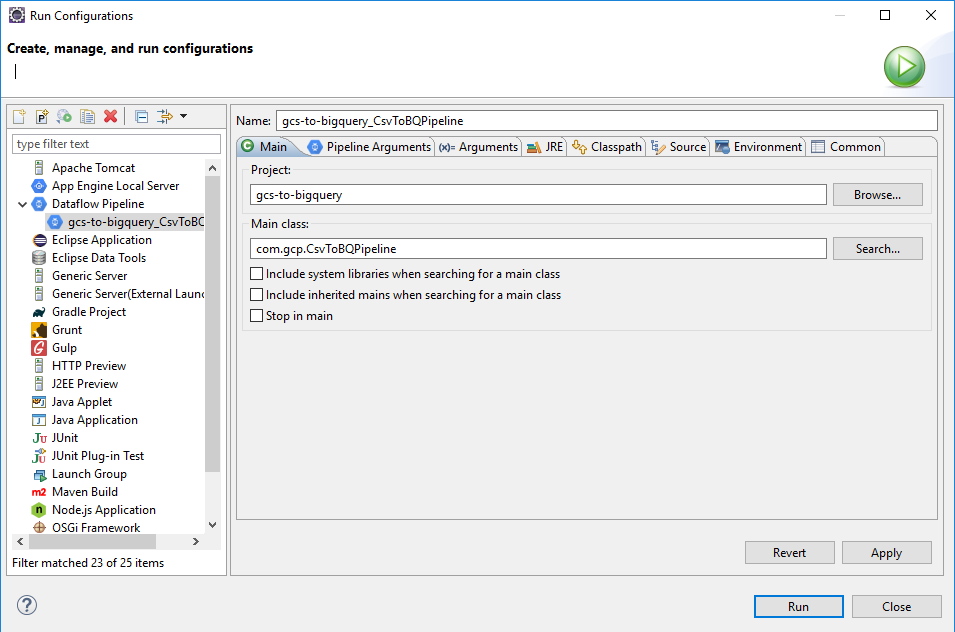
For Pipeline Arguments tab, choose DirectRunner to run job on local machine.
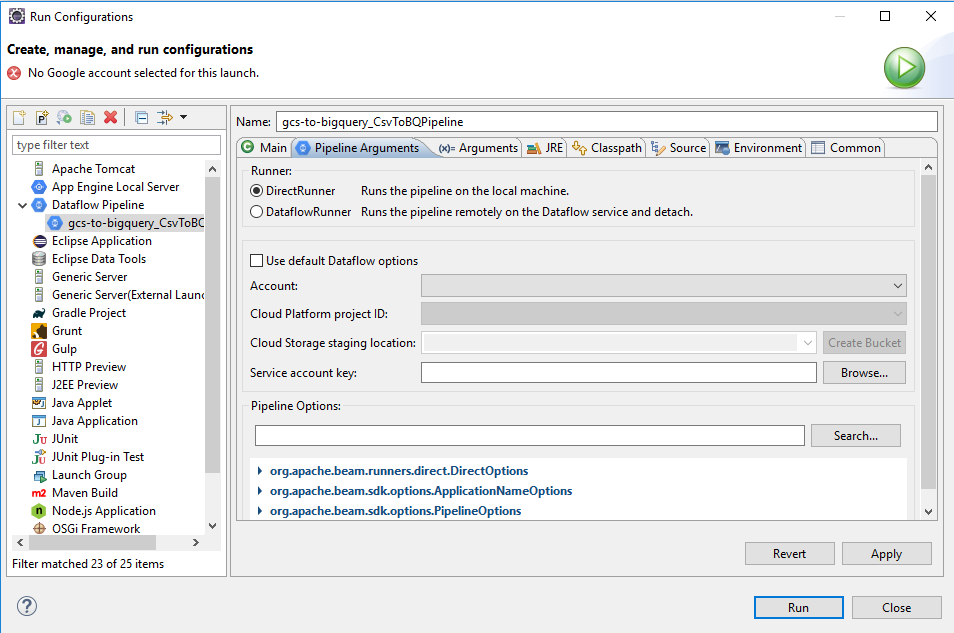
Check Use default Dataflow options and then run the code.
You can also run through DataflowRunner (set through Pipeline Arguments tab). The job will then be submitted to Dataflow in GCP.
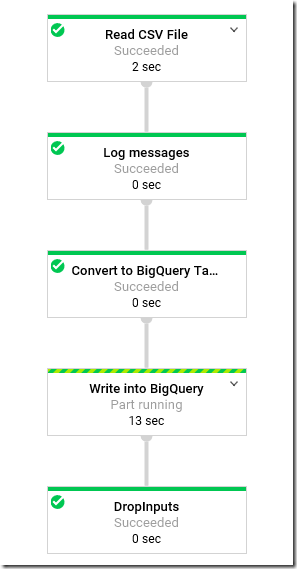
Once data is loaded, you can run the following query to query it:
SELECT * FROM `project-id.dataset.table-name` LIMIT 1000
This demonstrates using a fully managed and reliable service to transform data in batch modes. We can create a pipeline to process historical data which can be generated from various applications.
Once the data is ingested in BigQuery, it can be used for further analysis, visualization, training ML models, etc.