Declarative Memory
In the psychological theory that ACT-R uses, humans have many memory types.
Some memories are of fact-like beliefs, such as that whales are mammals, or that Moskow is the capital of Russia. These kinds of memories are fact-like (propositional), and we can often retrieve them and be consciously aware of them. Other kinds of memory might be associations between concepts (associative memories), or memories of how to do things (procedural memory).
In ACT-R, the declarative memory is distinct from the procedural memory (which is the set of productions.)
Each declarative memory is called a "chunk."
The ACT-R agent requests a memory from the long-term declarative memory store, and retrieved memories go into the declarative memory buffer. We can think of this buffer's size as being able to hold about 2 to 6 chunks (often referred to as "four plus or minus two.")
For example, an agent might want to recall the capital of Russia. They might submit a request to declarative memory that looks like this:
Country: Russia
Capital: ?
If the agent knows that Moskow is the capital of Russia, then the full "chunk" will be put in declarative memory.
Country: Russia
Capital: Moskow
A request production puts a copy of the chunk in the declarative memory buffer, and another production will be activated in order to use it for anything.
Your ability to retrieve a declarative memory is determined by its current activation level ("activation.") If the activation of a particular chunk is below the threshold, it cannot be retrieved. Higher activations are more quickly retrieved. The threshold can move up and down, depending on the agent's focus.
According to ACT-R theory, the brain updates the activation of all memories all the time. But this is computationally expensive, so the implemented versions of ACT-R simplify this so computers can actually run it.
Activation can be turned on or off.
The brain is a wet, biological system. The current activation level of a chunk is subject to some noise. In Python ACT-R, noise is just about always set to 0.3.
Activation goes down over time. This is known as decay. It follows a classic "forgetting curve;" a negative exponential. It will continue to do this until it asymptotes to the base level activation (see below).
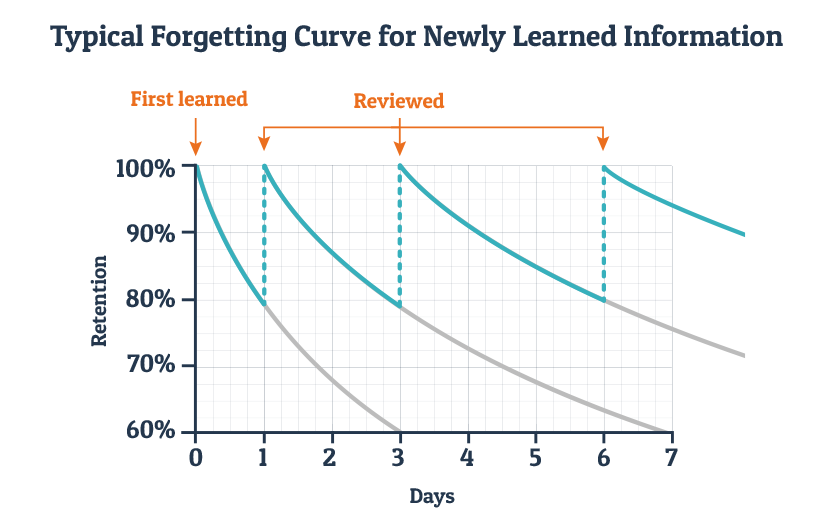
Image from https://blog.wranx.com/ebbinghaus-forgetting-curve
In the real world, decay happens, but often declarative memories in the declarative memory buffer are pushed out by other retrieved memories. Some think of this decay as a stand-in for interference from other memories, but rather than modelling these distractions, we just approximate it with decay.
When you use a chunk, its activation level goes up.
No matter what you happen to be thinking about today, certain memories are more easily retrieved than others in general. A chunk's activation can decay until it reaches its base level. When we refer to "activation," we mean the current activation, and if we mean the base activation, we will call it as such.
To raise the base level activation, the agent tries to add a new chunk to declarative memory, but that chunk already exists. So the agent either adds a new chunk to the declarative memory, or increases the base activation of the same chunk that already exists there.
Memories activate other memories they are related to (the "targets.") This is called "spreading activation." We'll talk about it happening from a source memory to target memories. When a source activates a target, the source does not lose activation.
How does Python ACT-R determine targets? It ignores slot names, and uses values. If a chunk contains the same symbol that is in the source, then that chunk is a target. This is Python ACT-R's implementation of semantic priming.
Only retrieved chunks are sources. Targets do not become sources unless they are retrieved.
There are also associative targets in Python ACT-R. That is, two things experienced simultaneously are connected by association, even if there's no relation between them (like has-a, or isa-a).
How much is spread? It's a function of a few things, including the strength of association between the two chunks.