A commandline tool to anonymize PostgreSQL databases for DSGVO/GDPR purposes.
It uses a YAML file to define which tables and fields should be anonymized and provides various methods of anonymization. The tool requires a direct PostgreSQL connection to perform the anonymization.

![]()
Contents
- Intentionally compatible with Python 2.7 (for old, productive platforms)
- Anonymize PostgreSQL tables on data level entry with various providers (some examples in the table below)
- Exclude data for anonymization depending on regular expressions or SQL
WHEREclauses - Truncate entire tables for unwanted data
| Field | Value | Provider | Output |
|---|---|---|---|
first_name |
John | choice |
(Bob|Larry|Lisa) |
title |
Dr. | clear |
|
street |
Irving St | faker.street_name |
Miller Station |
password |
dsf82hFxcM | mask |
XXXXXXXXXX |
credit_card |
1234-567-890 | partial_mask |
1??????????0 |
email |
jane.doe@example.com | md5 |
0cba00ca3da1b283a57287bcceb17e35 |
email |
jane.doe@example.com | faker.unique.email |
alex7@sample.com |
phone_num |
65923473 | md5 as_number: True |
3948293448 |
ip |
157.50.1.20 | set |
127.0.0.1 |
uuid_col |
00010203-0405-...... | uuid4 |
f7c1bd87-4d.... |
- Note:
faker.unique.[provider]only supported on Python 3.6+ (Faker library min. supported python version) - Note:
uuid4- only for (native uuid4) columns
See the documentation for a more detailed description of the provided anonymization methods.
The default installation method is to use pip:
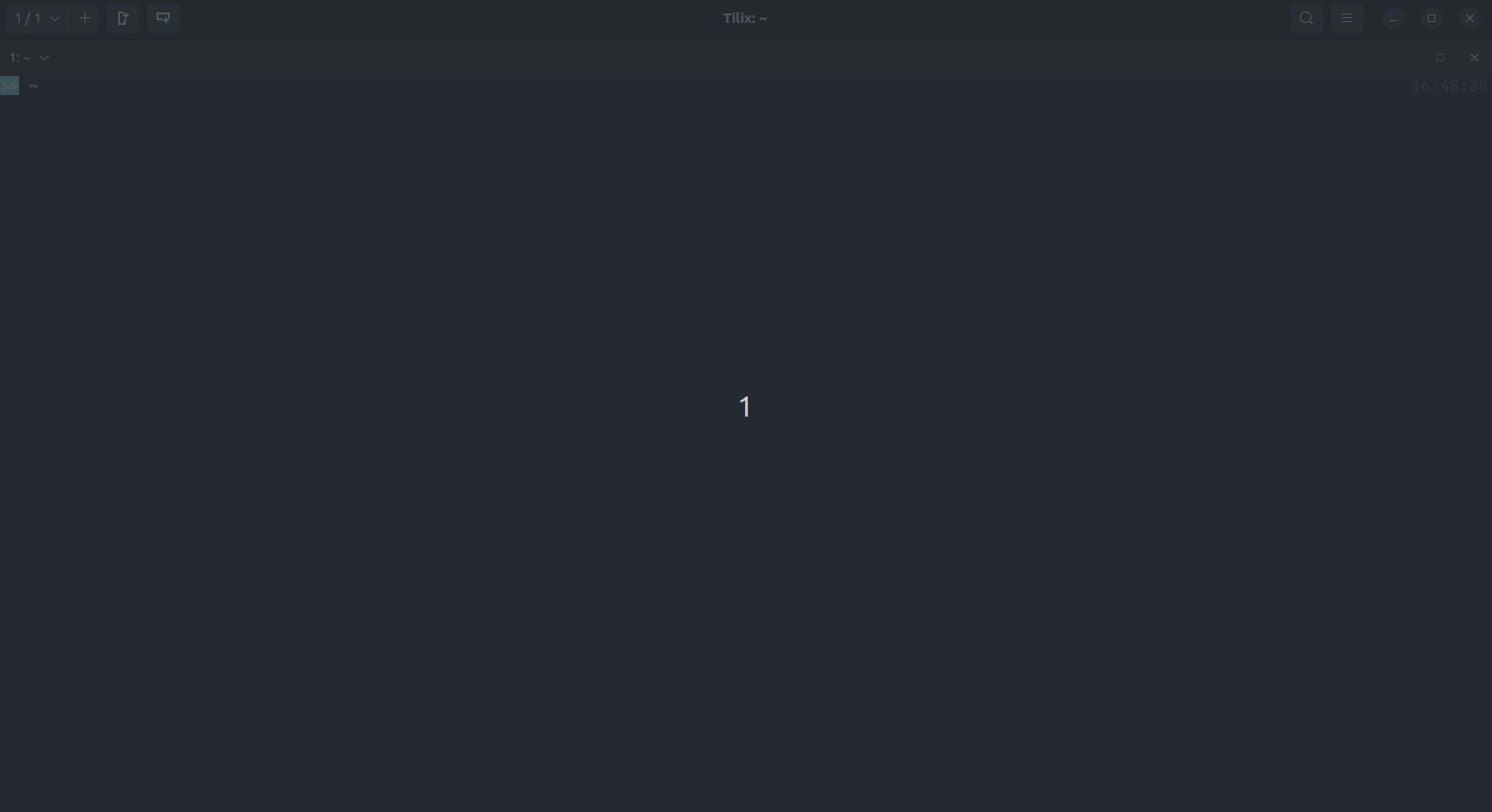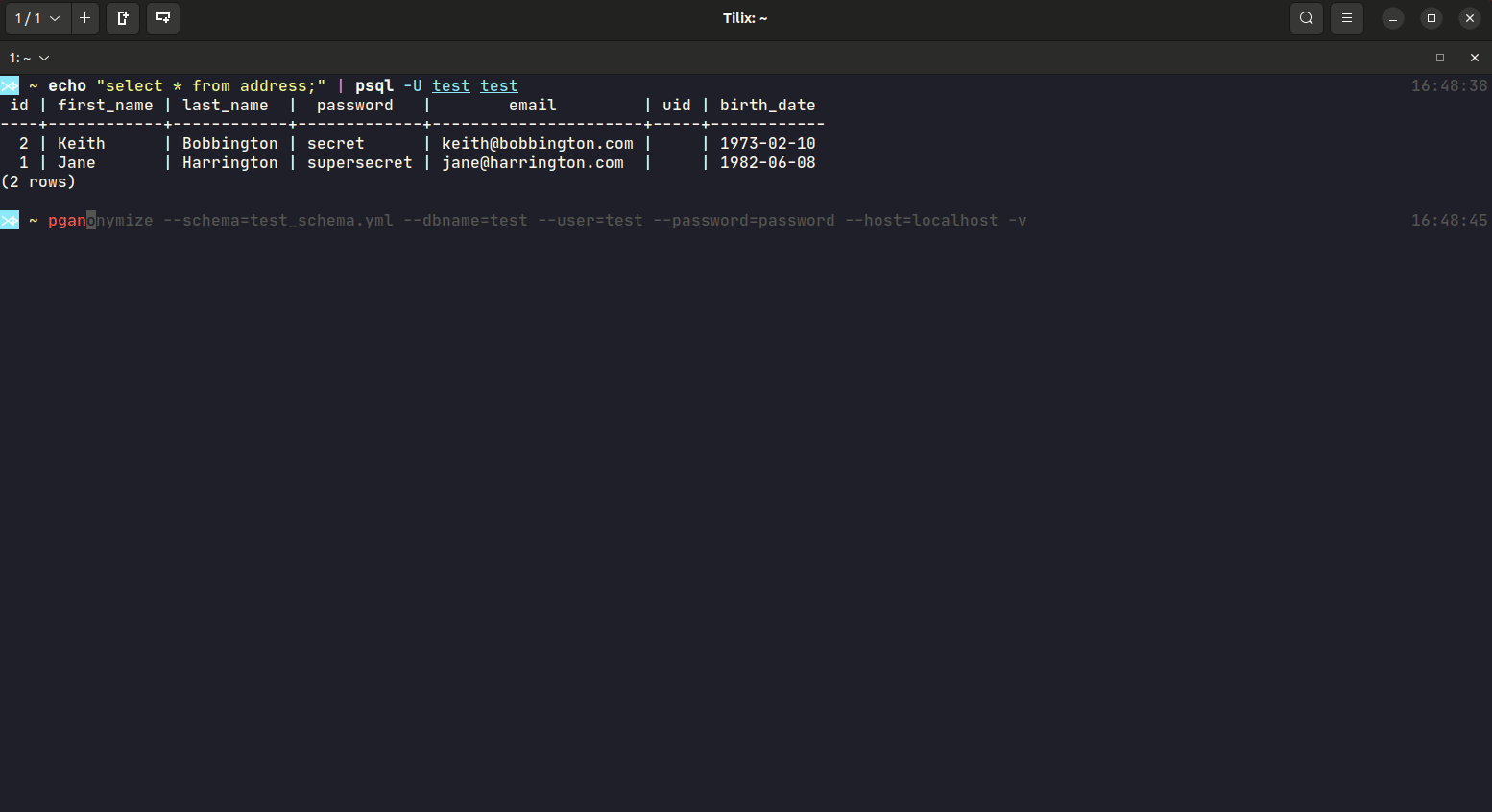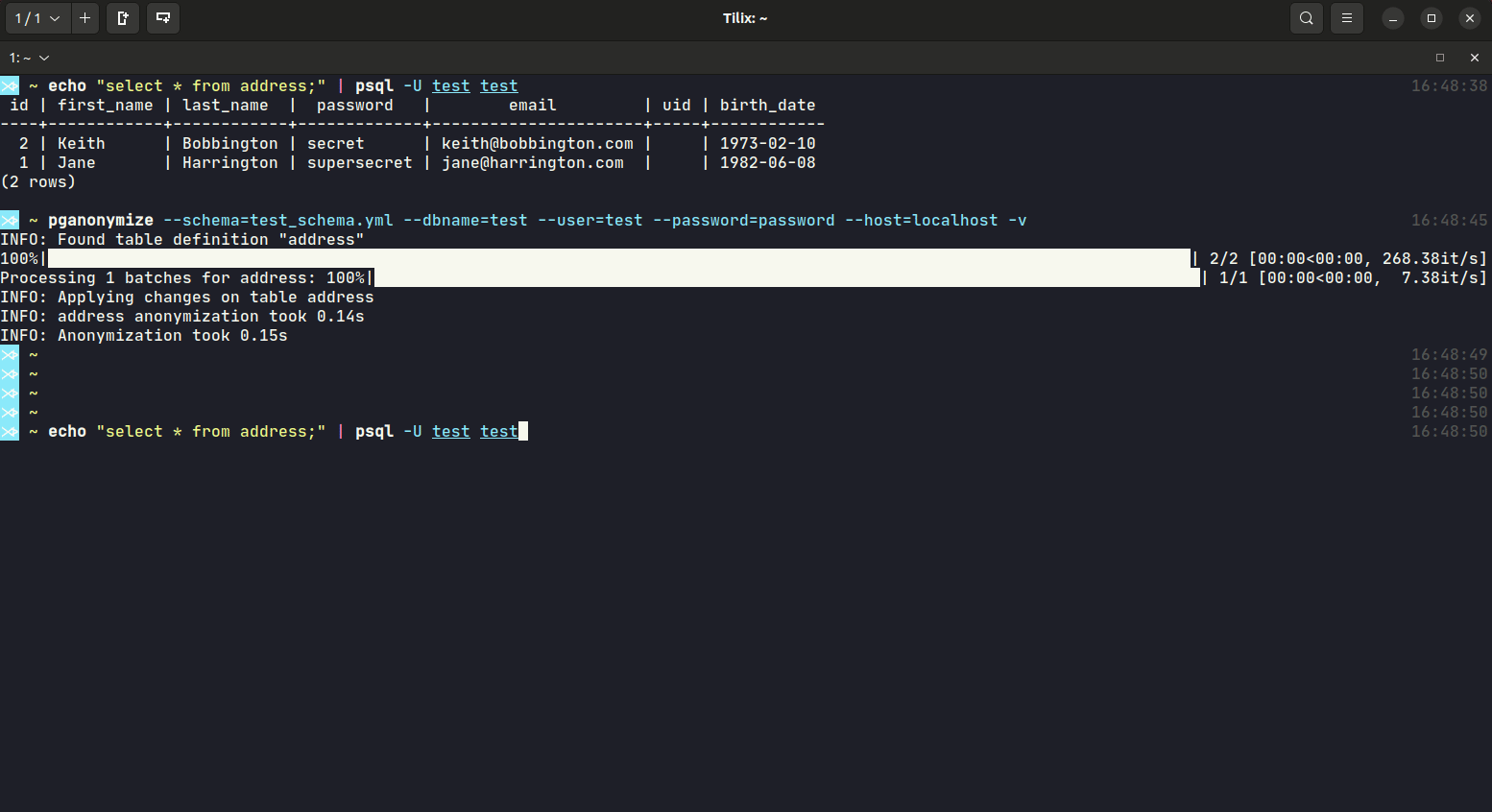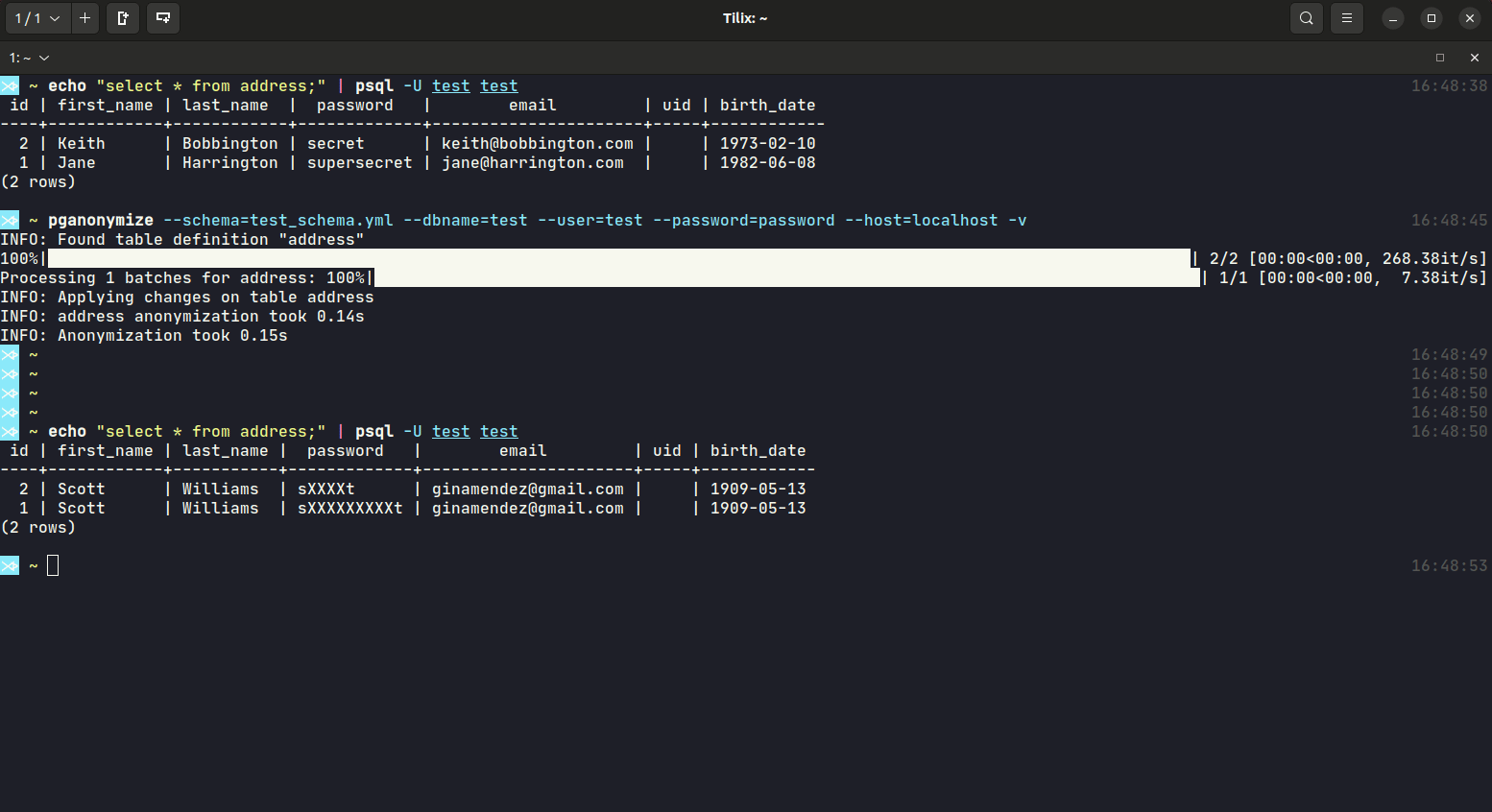
$ pip install pganonymize
usage: pganonymize [-h] [-v] [-l] [--schema SCHEMA] [--dbname DBNAME]
[--user USER] [--password PASSWORD] [--host HOST]
[--port PORT] [--dry-run] [--dump-file DUMP_FILE]
Anonymize data of a PostgreSQL database
optional arguments:
-h, --help show this help message and exit
-v, --verbose Increase verbosity
-l, --list-providers Show a list of all available providers
--schema SCHEMA A YAML schema file that contains the anonymization
rules
--dbname DBNAME Name of the database
--user USER Name of the database user
--password PASSWORD Password for the database user
--host HOST Database hostname
--port PORT Port of the database
--dry-run Don't commit changes made on the database
--dump-file DUMP_FILE
Create a database dump file with the given name
--dump-options DUMP_OPTIONS
Options to pass to the pg_dump command
--init-sql INIT_SQL SQL to run before starting anonymization
--parallel Data anonymization is done in parallel
Despite the database connection values, you will have to define a YAML schema file, that includes all anonymization rules for that database. Take a look at the schema documentation or the YAML sample schema.
Example calls:
$ pganonymize --schema=myschema.yml \
--dbname=test_database \
--user=username \
--password=mysecret \
--host=db.host.example.com \
-v
$ pganonymize --schema=myschema.yml \
--dbname=test_database \
--user=username \
--password=mysecret \
--host=db.host.example.com \
--init-sql "set search_path to non_public_search_path; set work_mem to '1GB';" \
-v
With the --dump-file argument it is possible to create a dump file after anonymizing the database. Please note,
that the pg_dump command from the postgresql-client-common library is necessary to create the dump file for the
database, e.g. under Linux:
$ sudo apt-get install postgresql-client-common
Example call:
$ pganonymize --schema=myschema.yml \
--dbname=test_database \
--user=username \
--password=mysecret \
--host=db.host.example.com \
--dump-file=/tmp/dump.gz \
-v
So that the password for dumping does not have to be entered manually, it can also be entered as an environment var
PGPASSWORD:
$ PGPASSWORD=password pganonymize --schema=myschema.yml \
--dbname=test_database \
--user=username \
--password=mysecret \
--host=db.host.example.com \
--dump-file=/tmp/dump.gz \
-v
Warning
Currently only the dump-file operation supports environment variables.
If you want to run the anonymizer within a Docker container you first have to build the image:
$ docker build -t pganonymize .
After that you can pass a schema file to the container, using Docker volumes, and call the anonymizer:
$ docker run \
-v <path to your schema>:/schema.yml \
-it pganonymize \
/usr/local/bin/pganonymize \
--schema=/schema.yml \
--dbname=<database> \
--user=<user> \
--password=<password> \
--host=<host> \
-v