[REVIEW] RF: Variable binning and other minor refactoring #4479
Conversation
There was a problem hiding this comment.
Could you create a small struct like:
// Non-owning data structure for accessing quantiles
// Can be used in kernels
class Quantiles{
private:
DataT *quantiles; // csr matrix where each row contains quantiles for a feature
int * row_offsets;
IdxT num_features;
int max_bins;
public:
IdxT FeatureValueToBinIdx(IdxT feature_idx, DataT value){}
DataT BinIdxToFeatureValue(IdxT feature_idx, IdxT bin_idx){}
};
Maybe the above doesn't work because we need to cache in shared memory, perhaps you can think of something. It is useful to semantically group functionality into an object instead of having a bunch of variables or pointers hanging around 'loose' in kernels. We can make the pointers private and control the way they are used via the public interface. These are just thoughts, so ok if it doesn't work.
| __syncthreads(); | ||
|
|
||
| for (int bin = threadIdx.x; bin < n_bins; bin += blockDim.x) { | ||
| if (bin >= unq_nbins) break; |
There was a problem hiding this comment.
Shouldn't the above loop just be < unq_nbins?
Sidenote, google c++ style guide and c++ core guidelines recommend not abbreviating function names. Long is okay (within reason), aim for clear and unambiguous. Variable names are critical to code readability/maintenance.
There was a problem hiding this comment.
oh yea 😅
thanks rory 👍🏻
I have separated |
| Input<DataT, LabelT, IdxT> input, | ||
| NodeWorkItem* work_items, | ||
| __global__ void nodeSplitKernel(const IdxT max_depth, | ||
| const IdxT min_samples_leaf, |
There was a problem hiding this comment.
Good job making these const. Less import for single integers but very important for pointers (or structs containing pointers).
| for (IdxT b = threadIdx.x; b < nbins; b += blockDim.x) | ||
| sbins[b] = input.quantiles[col * nbins + b]; | ||
| for (IdxT b = threadIdx.x; b < max_nbins; b += blockDim.x) { | ||
| if (b >= nbins) break; |
There was a problem hiding this comment.
I think you can just change the loop condition.
There was a problem hiding this comment.
you're right, have changed it 👍🏾
|
|
||
| if (threadIdx.x == 0) { | ||
| // make quantiles unique, in-place | ||
| auto new_last = thrust::unique(thrust::device, quantiles, quantiles + max_nbins); |
There was a problem hiding this comment.
There was a problem hiding this comment.
oh I see, thanks for the article rory... haven't encountered such an error here...but have changed policy to thrust::seq to be on safer side 👍🏾
| namespace DT { | ||
|
|
||
| template <typename T> | ||
| __global__ void computeQuantilesKernel( |
There was a problem hiding this comment.
Am I seeing things or is this kernel defined twice?
There was a problem hiding this comment.
oh that's on me 😅 thank you for the catch!
| { | ||
| double bin_width = static_cast<double>(n_rows) / max_nbins; | ||
|
|
||
| for (int bin = threadIdx.x; bin < max_nbins; bin += blockDim.x) { |
There was a problem hiding this comment.
I see you changed this to use a single block, which makes sense.
| @@ -106,7 +106,7 @@ class RandomForestClassifier(BaseRandomForestModel, DelayedPredictionMixin, | |||
| * If ``'log2'`` then ``max_features=log2(n_features)/n_features``. | |||
| * If ``None``, then ``max_features = 1.0``. | |||
| n_bins : int (default = 128) | |||
| Number of bins used by the split algorithm. | |||
| Maximum number of bins used by the split algorithm per feature. | |||
| @@ -84,13 +84,13 @@ struct DecisionTreeParams { | |||
| * i.e., GINI for classification or MSE for regression | |||
| * @param[in] cfg_max_batch_size: Maximum number of nodes that can be processed | |||
| in a batch. This is used only for batched-level algo. Default | |||
| value 128. | |||
| value 4096. | |||
| max_blocks = 1 + params.max_batch_size + input.nSampledRows / TPB_DEFAULT; | ||
| ASSERT(quantiles != nullptr, "Currently quantiles need to be computed before this call!"); | ||
| max_blocks = 1 + params.max_batch_size + dataset.nSampledRows / TPB_DEFAULT; | ||
| ASSERT(q.quantiles_array != nullptr, |
There was a problem hiding this comment.
q.n_uniquebins_array should also be checked?
| // populating shared memory with initial values | ||
| for (IdxT i = threadIdx.x; i < shared_histogram_len; i += blockDim.x) | ||
| shared_histogram[i] = BinT(); | ||
| for (IdxT b = threadIdx.x; b < nbins; b += blockDim.x) | ||
| sbins[b] = input.quantiles[col * nbins + b]; | ||
| for (IdxT b = threadIdx.x; b < nbins; b += blockDim.x) { |
There was a problem hiding this comment.
Are we going for {} for single line loops or not? Because loop above does not seem to have them.
| const double* sorted_data, | ||
| const int length); | ||
| const int max_nbins, | ||
| const int n_rows); | ||
|
|
||
| } // end namespace DT | ||
| } // end namespace ML |
There was a problem hiding this comment.
Let's add a EOF to keep git happy.
|
Good to merge from my side. Any idea about the build failures? Perhaps we need to merge latest 22.04? |
Codecov Report
@@ Coverage Diff @@
## branch-22.04 #4479 +/- ##
===============================================
Coverage ? 85.71%
===============================================
Files ? 236
Lines ? 19365
Branches ? 0
===============================================
Hits ? 16599
Misses ? 2766
Partials ? 0
Flags with carried forward coverage won't be shown. Click here to find out more. Continue to review full report at Codecov.
|

|
@gpucibot merge |
…)" This reverts commit 962d6f0.
* This PR enables variable bins capped to `max_n_bins` for the feature-quantiles. This makes Decision Trees more robust for a wider variety of datasets by avoiding redundant bins for columns having fewer uniques. * Added tests for the same * Some accompanying changes in naming and format of the structures used for passing input and quantiles * Deleting the `cpp/test/sg/decisiontree_batchedlevel_*` files as they are not tested. * changed param `n_bins` to `max_nbins` in C++ layer to differentiate it's meaning with the actual `n_bins` used [here](https://github.com/rapidsai/cuml/blob/eb62fecce4211a1022cf19380be31981680fc5ab/cpp/src/decisiontree/batched-levelalgo/kernels/builder_kernels_impl.cuh#L266) * The python layer still maintains `n_bins` but have tweaked the docstrings to convey that it denotes the "_maximum bins used_" * Other variable renamings in the core Decision Tree classes --- This PR does not improve perf of GBM-bench datasets by much as almost all of the features have unique values that exceed the `n_bins` used. 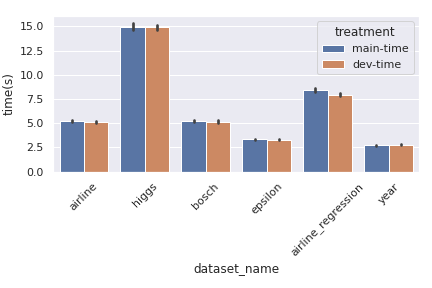 Authors: - Venkat (https://github.com/venkywonka) Approvers: - Rory Mitchell (https://github.com/RAMitchell) - Vinay Deshpande (https://github.com/vinaydes) - Dante Gama Dessavre (https://github.com/dantegd) URL: rapidsai#4479
{kind=link}
max_n_binsfor the feature-quantiles. This makes Decision Trees more robust for a wider variety of datasets by avoiding redundant bins for columns having fewer uniques.cpp/test/sg/decisiontree_batchedlevel_*files as they are not tested.n_binstomax_nbinsin C++ layer to differentiate it's meaning with the actualn_binsused heren_binsbut have tweaked the docstrings to convey that it denotes the "maximum bins used"This PR does not improve perf of GBM-bench datasets by much as almost all of the features have unique values that exceed the
n_binsused.