Classic mirrored queue leadership transfer eagerly clears the list of mirrors which can result in data loss #2749
Description
Describe the bug
Data loss issue with mirror queues on operator deployed clusters. Reported by internal team. cc @mkuratczyk @Gsantomaggio
To Reproduce
Steps to reproduce the behavior:
- Deploy 3 nodes rabbitmq cluster
- Create HA policy with params: "ha-mode: exactly, ha-params: 2, ha-promote-on-failure: when-synced, ha-sync-batch-size: 5000, ha-sync-mode: automatic"
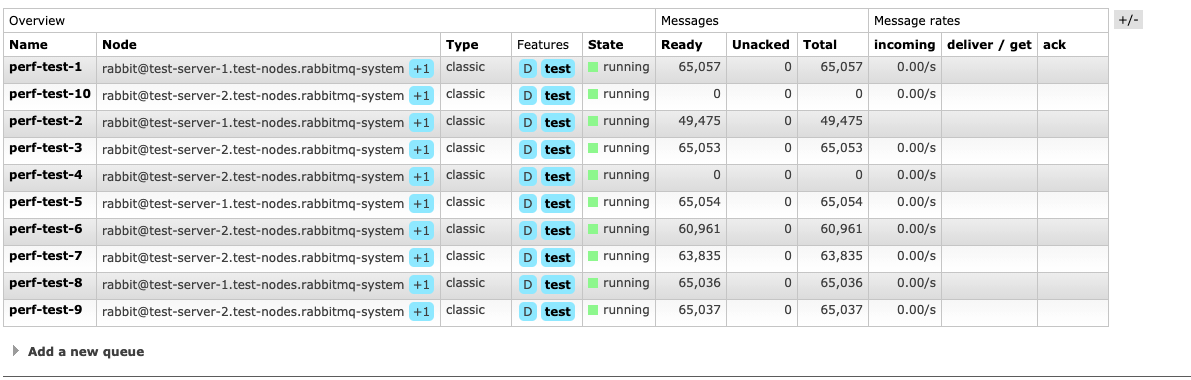
- Use perf tests to populate the cluster with unconsumed messages
-y0 -queue-pattern 'perf-test-%d' \ --auto-delete false --queue-pattern-from 1 --queue-pattern-to 10 -s 1000 -x 10 -y 0 -r 1000 -R 0 -f persistent - Stop perf-tests (without triggering any alarms and all queues should be synced)
- Delete one node which has queue masters located on and observe data loss (0 message left)
Include any YAML or manifest necessary to reproduce the problem.
Expected behavior
After deleting one rabbitmq node, the mirror queue should be promoted as the master queue and rabbitmq should create a new mirror in node that's not deleted.
Screenshots
Version and environment information
- RabbitMQ: 3.8.9
- RabbitMQ Cluster Operator: Latest main: rabbitmq/cluster-operator@c420661
- Kubernetes: 1.17.0
- Cloud provider or hardware configuration:
Additional context
This is a reported issue. The user has also seem similar data loss with "ha-params: 3" on 5 nodes cluster.
Metadata
Metadata
Labels
No labels