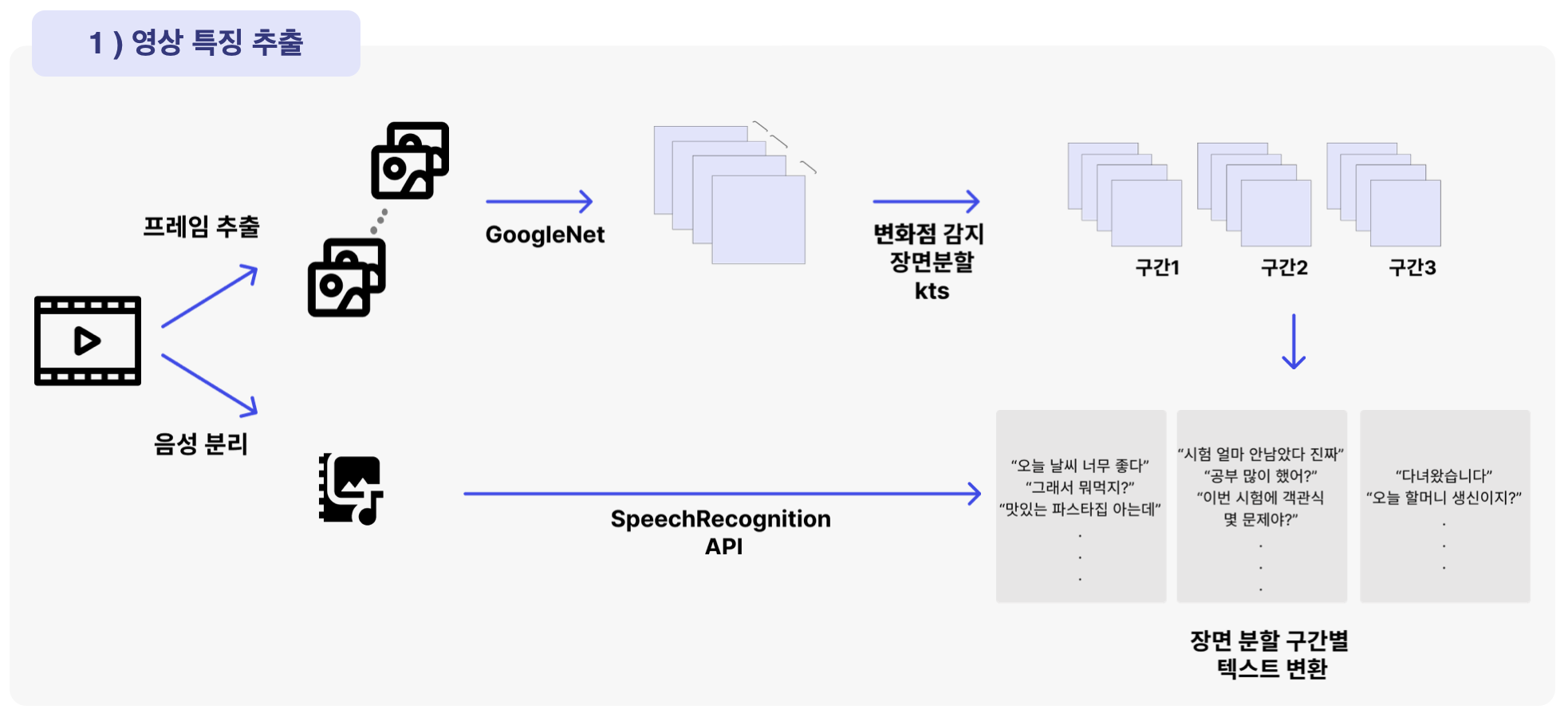
음성데이터와 이미지 데이터로부터 해시태그를 뽑아내는 프로젝트입니다.
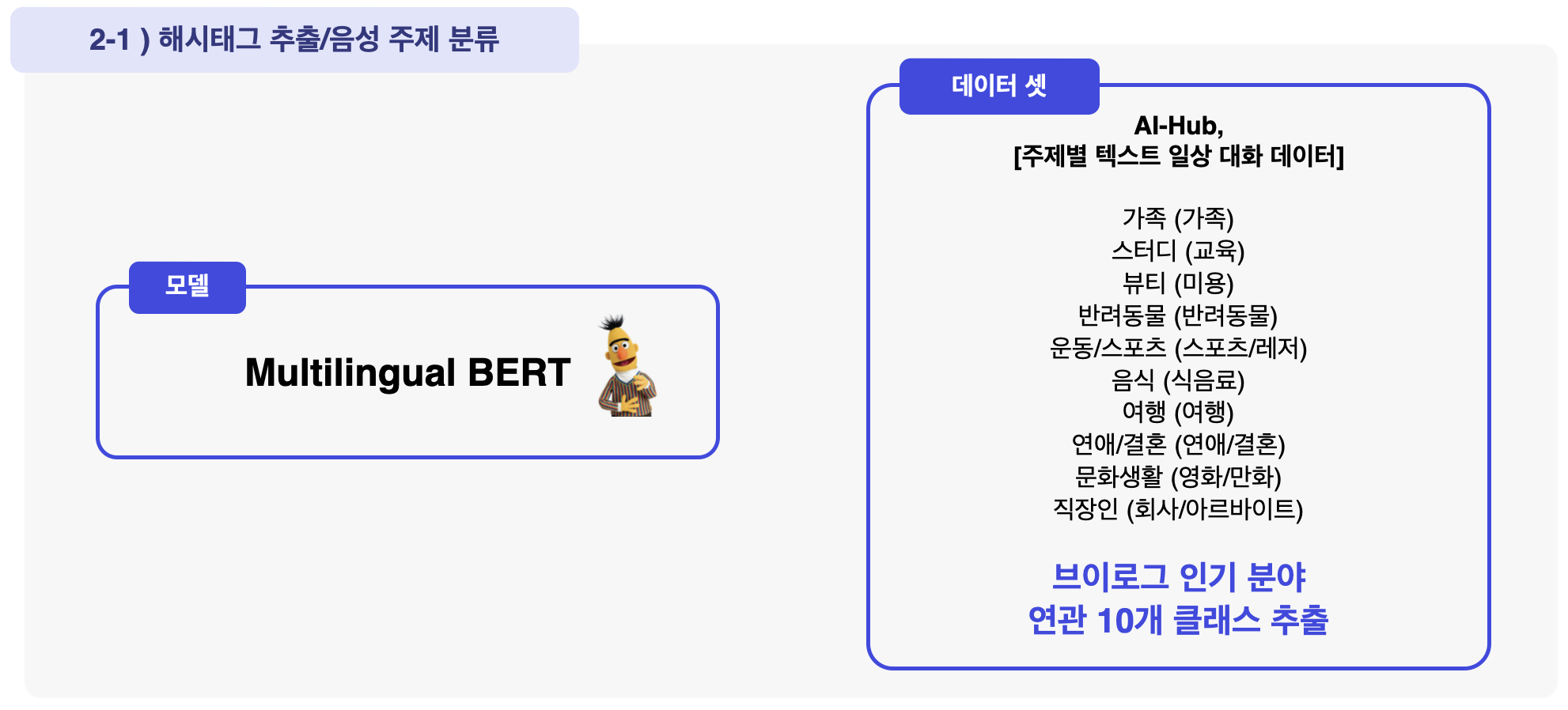
언어 모델로 다국어 Bert를 사용 다양한 모델들이 존재하였지만 성능이 제일 우수하여 이를 선택하였습니다.
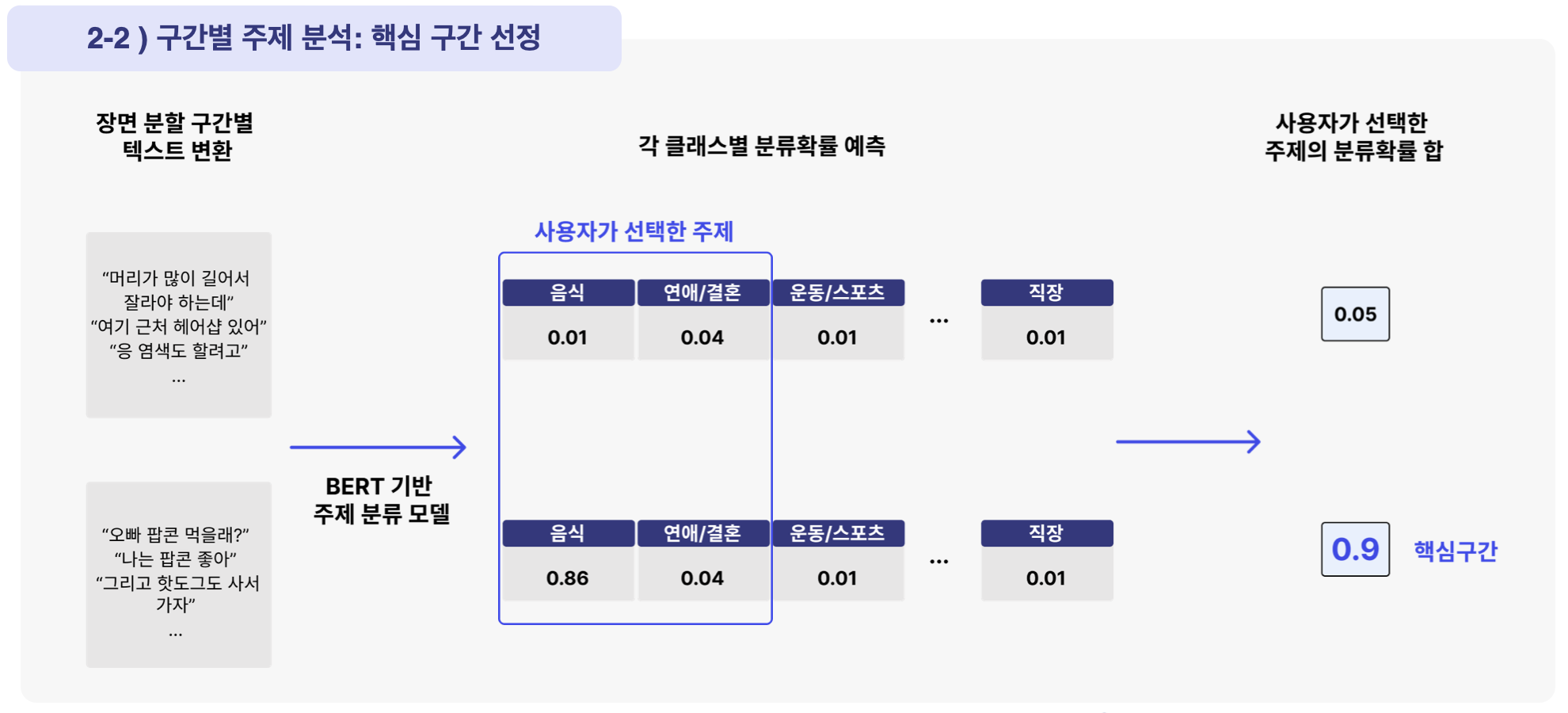
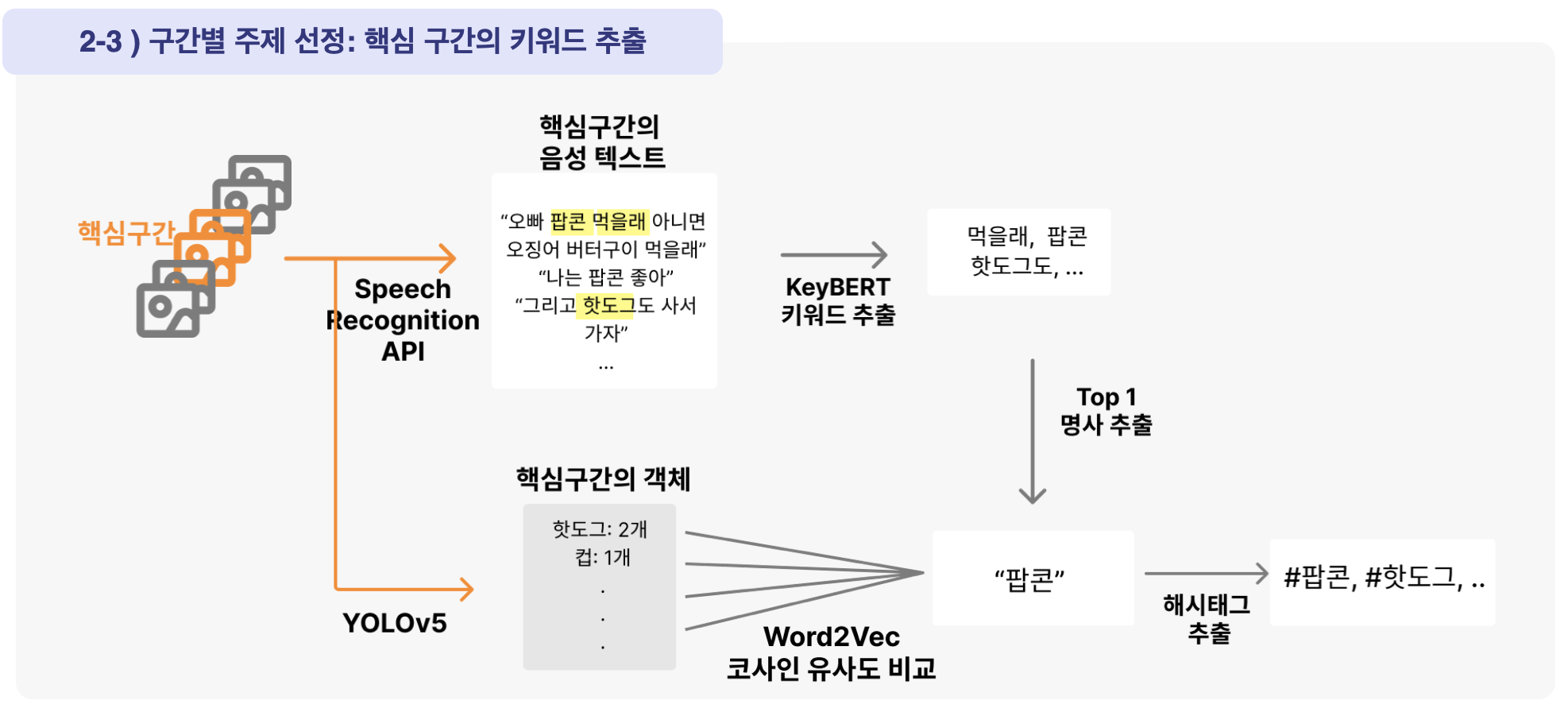
음성부분의 데이터와 이미지로부터온 데이터의 유사도를 word2vec으로 계산하여 유사도가 가장 높은 순위를 뽑았습니다.

wanso/
├── pickle_data/
│ ├── common_tag.pickle
│ ├── dic.pickle
│ ├── hash_table.pickle
│ └── img_table.pickle
├── weights/
│ └── classification_model.pt
├── ko.bin
├── adot_clf_model.py
├── adot_tag_generate.py
└── adot_tag_run.py
requirements.txt
- 필요한 라이브러리 설치
!pip install -r requirements.txt
!gdown https://drive.google.com/file/d/1-0FZyuS9gt1Avb8vY_VtCsksVL_JMTUv/view?usp=share_link
!gzip -d ko.bin
!wget https://drive.google.com/file/d/1-XnfaC5az-1pVzixhQZkMLnSgxz7cv0e/view?usp=sharing
python3 adot_tag_run.py