Hidden text is being extracted even using scrub() #736
Description
Describe the bug
The scrub() method is not completely sanitizing the pdf. It is still possible to extract hidden text from it.
To Reproduce
I can't share this PDF, but I guess it was generated in Excel.
doc = fitz.open(pdf_dir)
doc.scrub()
blocks = doc[0].getText("rawdict")["blocks"]
Check the X_0 coord for each char
| x_0 | y_0 | x_1 | y_1 | c | |
|---|---|---|---|---|---|
| 0 | 256.35 | 327.575 | 262.353 | 339.941 | S |
| 1 | 262.353 | 327.575 | 268.851 | 339.941 | R |
| 2 | 268.851 | 327.575 | 273.855 | 339.941 | # |
| 3 | 273.855 | 327.575 | 276.357 | 339.941 | |
| 4 | 276.357 | 327.575 | 281.361 | 339.941 | 2 |
| 5 | 281.361 | 327.575 | 286.365 | 339.941 | 2 |
| 6 | 286.365 | 327.575 | 291.369 | 339.941 | 3 |
| 7 | 291.369 | 327.575 | 296.373 | 339.941 | 4 |
| 8 | 296.373 | 327.575 | 301.377 | 339.941 | 8 |
| 9 | 301.377 | 327.575 | 306.381 | 339.941 | 5 |
| 10 | 306.381 | 327.575 | 311.385 | 339.941 | 8 |
| 11 | 311.385 | 327.575 | 316.389 | 339.941 | 3 |
| 12 | 316.389 | 327.575 | 321.393 | 339.941 | 9 |
| 13 | 321.393 | 327.575 | 326.397 | 339.941 | 7 |
| 14 | 326.397 | 327.575 | 328.899 | 339.941 | |
| 15 | 328.899 | 327.575 | 335.901 | 339.941 | O |
| 16 | 335.901 | 327.575 | 341.4 | 339.941 | T |
| 17 | 341.4 | 327.575 | 347.898 | 339.941 | H |
| 18 | 347.898 | 327.575 | 350.4 | 339.941 | |
| 19 | 350.4 | 327.575 | 356.898 | 339.941 | H |
| 20 | 356.898 | 327.575 | 362.901 | 339.941 | V |
| 21 | 362.901 | 327.575 | 368.904 | 339.941 | A |
| 22 | 368.904 | 327.575 | 375.402 | 339.941 | C |
| 23 | 375.402 | 327.575 | 377.904 | 339.941 | |
| 24 | 377.904 | 327.575 | 380.901 | 339.941 | - |
| 25 | 380.901 | 327.575 | 383.403 | 339.941 | |
| 26 | 383.403 | 327.575 | 390.405 | 339.941 | O |
| 27 | 390.405 | 327.575 | 394.905 | 339.941 | v |
| 28 | 394.905 | 327.575 | 399.909 | 339.941 | e |
| 29 | 399.909 | 327.575 | 402.906 | 339.941 | r |
| 30 | 397.6 | 327.575 | 402.604 | 339.941 | 3 |
| 31 | 402.604 | 327.575 | 407.608 | 339.941 | 8 |
| 32 | 407.608 | 327.575 | 412.612 | 339.941 | 1 |
| 33 | 412.612 | 327.575 | 415.114 | 339.941 | . |
| 34 | 415.114 | 327.575 | 420.118 | 339.941 | 0 |
| 35 | 420.118 | 327.575 | 425.122 | 339.941 | 0 |
While .getText("dict") extracted it just as SR# 2234858397 OTH HVAC - Over381.00
Expected behavior
I expected the scrub() method to sanitize hidden text like this. Also, a new word block for "381.00" would be nice here.
Screenshots
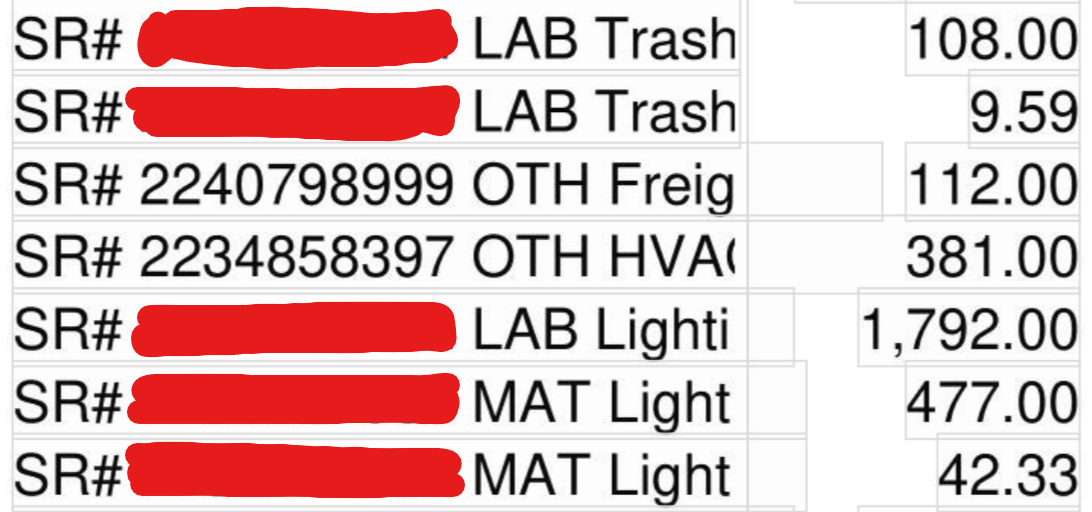
Your configuration
3.7.7 (default, May 6 2020, 11:45:54) [MSC v.1916 64 bit (AMD64)]
win32
PyMuPDF 1.17.6: Python bindings for the MuPDF 1.17.0 library.
Version date: 2020-08-26 14:54:32.
Built for Python 3.7 on win32 (64-bit).