Report dead entry points #187
Conversation
|
I did not change the set of entry points because I think the entry points should be consistent with the entry points which are used to create call graph. Hence, I just report the dead entry points for now. |
|
When the tool evaluates a project, it generates a set of dead entry points and prints those entry points into a txt file named I've added 3 methods:
|
|
I've added two new dead entry points in to The
|
|
Project: Result: Project: Result: This test case is interesting: Result: |
|
How are the results correct for your last example? There should be no dead entry points there. They all lead to methods instantiating streams. |
|
Also, ctors and static initializers are only dead iff all non-ctor and non-static initializers in the associated class are dead. |
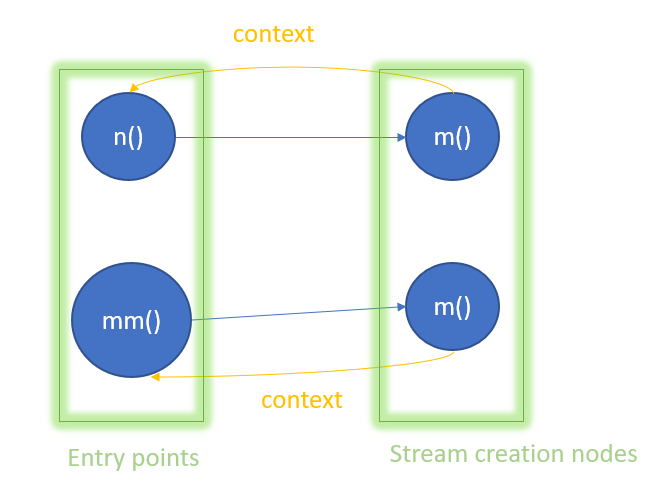
It seems that the current strategy only detects one path from the any entry point to a specific stream creation node and ignore other paths. I do not think the logic of my code is wrong for now. I need to check whether my work is wrong or this issue is from difference of call graph. I will check it.later. |
|
It would be good to add such test cases to the refactoring test suite, even if the assertions are not in place. At least we can see the output.
|
The results are very strange here. , the result are |
You have mentioned to test reporting entry points instead of refactoring. I have looked at Or I just need to remove the parameters of And the output file will be overwritten again and again. Should I rename them to avoid overwriting. |
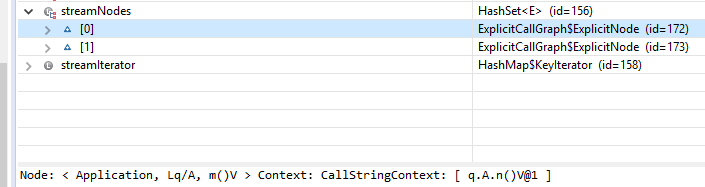
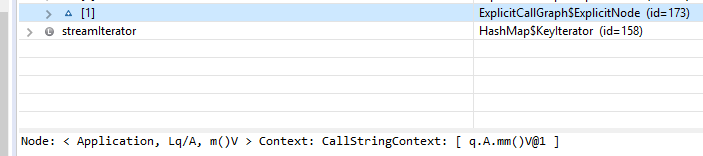
I guess the reason of it may be that one CGNode only binds one method in its call string context. , the CGNode of m() should have two call string contexts. Actually, it only has one. Sometime, it has Because of this, I cannot get all entry points for a specific stream creation node and I can just get at most one entry point for a specific stream creation node. |
|
#187 (comment) should be another issue as well. |
|
I've changed the code snippet of getting a set of stream creation nodes. Then, the results are right. , I get nothing in the txt file. When the test case is: , I also get 0 dead entry points. When the test is , the output is |
|
Each node represents a method IMethod in a context. I did not find any official words to describe edges. I think each edge means the predecessor calls the successor. The test case: The CallGraph class represents potentially context-sensitive call graphs. Hence, there should be 2 nodes of I found the context of a CGNode only contains call string context: Then, I found the CGNode
|


| @@ -362,20 +362,20 @@ private IR getEnclosingMethodIR(EclipseProjectAnalysisEngine<InstanceKey> engine | |||
| } | |||
|
|
|||
| /** | |||
| * @return The {@link CGNode} representing the enclosing method of this stream. | |||
There was a problem hiding this comment.
This file is from cherry pick and I need your change.
There was a problem hiding this comment.
Nope. This should not be part of the change set. No need to cherry-pick. You need to do a merge.
| CallGraph callGraph) { | ||
| Set<CGNode> deadEntryPoints = new HashSet<CGNode>(); | ||
| Set<String> aliveClass = new HashSet<String>(); | ||
| Set<CGNode> cotersOrStaticInitializerNodes = new HashSet<CGNode>(); |
| @@ -362,20 +362,20 @@ private IR getEnclosingMethodIR(EclipseProjectAnalysisEngine<InstanceKey> engine | |||
| } | |||
|
|
|||
| /** | |||
| * @return The {@link CGNode} representing the enclosing method of this stream. | |||
There was a problem hiding this comment.
Nope. This should not be part of the change set. No need to cherry-pick. You need to do a merge.
This reverts commit e90d188.
| Set<CGNode> streamNodes = new HashSet<CGNode>(); | ||
| while (streamIterator.hasNext()) { | ||
| Stream stream = streamIterator.next(); | ||
| streamNodes.addAll(stream.getEnclosingMethodNodes(engine)); |
There was a problem hiding this comment.
I can also catch the NoEnclosingMethodNodeFoundException here to avoid the interruption of a program.
| Stream stream = streamIterator.next(); | ||
| try { | ||
| streamNodes.addAll(stream.getEnclosingMethodNodes(engine)); | ||
| } catch (NoEnclosingMethodNodeFoundException e) { |
There was a problem hiding this comment.
If the exception is not caught here, the tool cannot produce the correct result for the test case below:
class A {
void m() {
HashSet h1 = new HashSet();
h1.stream().count();
}
@EntryPoint
void n() {
HashSet h2 = new HashSet();
h2.stream().count();
}
}
The program will be interrupted by throwing a NoEnclosingMethodNodeFoundException because there is no CGNode for m() in the call graph.
| } catch (IOException | CoreException | CancelException e) { | ||
| LOGGER.log(Level.SEVERE, | ||
| "Exception encountered while building call graph for: " + project.getElementName() + ".", e); | ||
| throw new RuntimeException(e); | ||
| } | ||
|
|
||
| Collection<CGNode> deadEntryPoints; |
There was a problem hiding this comment.
Collection<CGNode> deadEntryPoints = new HashSet<>();
| Collection<CGNode> deadEntryPoints; | ||
| if (!usedEntryPoints.isEmpty()) | ||
| deadEntryPoints = discoverDeadEntryPoints(engine); | ||
| else |
There was a problem hiding this comment.
Then, you wouldn't need this else clause.
| */ | ||
| private Set<CGNode> getStreamCreationNodes(Iterator<Stream> streamIterator, | ||
| EclipseProjectAnalysisEngine<InstanceKey> engine) { | ||
| Set<CGNode> streamNodes = new HashSet<CGNode>(); |
There was a problem hiding this comment.
Set<CGNode> streamNodes = new HashSet<>();
| * a {@link CallGraph}. | ||
| * @return a set of dead entry points. | ||
| */ | ||
| private Set<CGNode> getDeadEntryPointNodes(Collection<CGNode> entryPointNodes, Set<CGNode> streamNodes, |
There was a problem hiding this comment.
Does this have to be an instance method?
| Set<CGNode> ctorsOrStaticInitializerNodes = new HashSet<CGNode>(); | ||
| for (CGNode entryPointNode : entryPointNodes) { | ||
| // We will process ctors and static initializers later | ||
| if (Util.isCtors(entryPointNode) || Util.isStaticInitializers(entryPointNode)) { |
There was a problem hiding this comment.
English: these method names should be singular, e.g., Util.isCtor().
| * @param callGraph | ||
| * @return true: reachable; false: unreachable | ||
| */ | ||
| private boolean isReachable(CGNode entryPointNode, Collection<CGNode> streamNodes, CallGraph callGraph) { |
There was a problem hiding this comment.
Does this need to be an instance method?
| } catch (IOException | CoreException | CancelException e) { | ||
| LOGGER.log(Level.SEVERE, | ||
| "Exception encountered while building call graph for: " + project.getElementName() + ".", e); | ||
| throw new RuntimeException(e); | ||
| } | ||
|
|
||
| Collection<CGNode> deadEntryPoints; | ||
| if (!usedEntryPoints.isEmpty()) | ||
| deadEntryPoints = discoverDeadEntryPoints(engine); |
There was a problem hiding this comment.
Can we add an INFO log here for each entry point?
There was a problem hiding this comment.
Log one info for each dead entry point (one per line).
Probably line 243 in https://github.com/ponder-lab/Java-8-Stream-Refactoring/pull/187/files.
If you do it on line 243 (above), then |
| // rebuild the callgraph | ||
| usedEntryPoints = getPrunedEntryPoints(deadEntryPoints, usedEntryPoints); | ||
| buildCallGraphFromEntryPoints(engine, usedEntryPoints); | ||
| } |
|
I've evaluated the
In my opinion, the reasons may be
|
|
What is old version? |
Why are the number of entry points different here? |
|
It sounds to me that if rebuilding the call graph is too expensive, we'll have to find a way to alter the original call graph. But, I would say make sure that this is the operation that is dominating the run time. If, on the other hand, the dominant run time is finding dead entry points, then there's no hope. We should profile this and see where most of the time is being spent, i.e., in the call graph reconstruction or in the finding of the dead entry points. |
No description provided.