Utilizar o MLFlow para log de métricas e parâmetros #120
Conversation
A instalação da PlatIA agora possui o MLFlow como um de seus componentes. Uma das funcionalidades do MLFlow é o tracking de métricas, dependências e artefatos. Nesta tarefas iremos usar o SDK do MLFlow para salvar métricas das tarefas nativas da Plataforma. https://www.mlflow.org/docs/latest/tracking.html
|
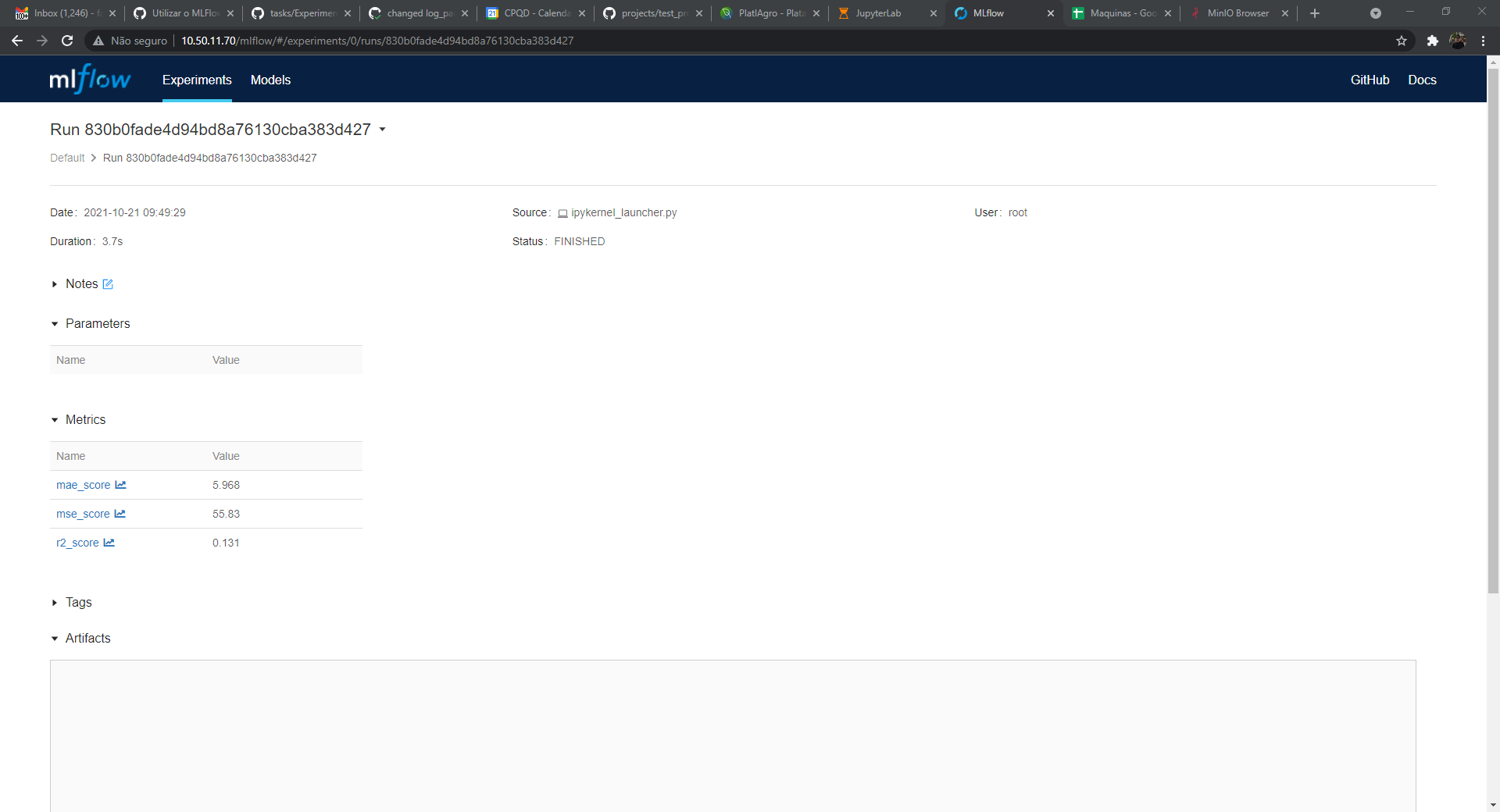
@fberanizo eu acabei utilizando em todos os casos o método "log_param" e não "log_metrics" não sei se tem diferença ou não. |
changed log_param to log_metric
 fberanizo
left a comment
fberanizo
left a comment
There was a problem hiding this comment.
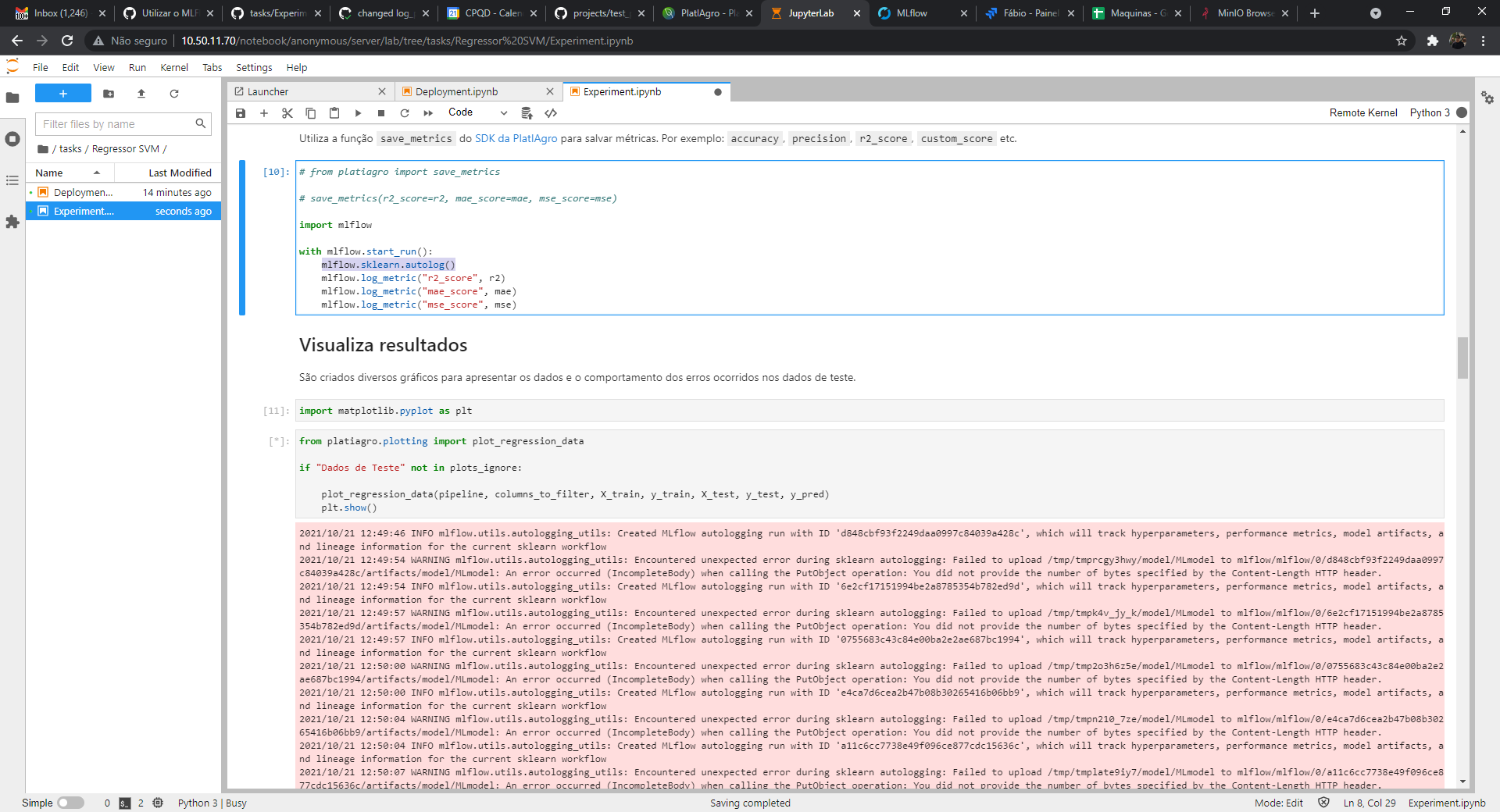
@dfvneto pelo que vi o log_metric parece que deu certo, mas vou deixar algumas orientações para terminar a tarefa:
O mlflow.sklearn.autolog() só faz sentido para Notebooks que usam o sklearn: linear regression, kmeans, isolation forest, logistic regression, mlp-classifier, mlp-regressor, random-forest classifier, random-forest regressor, svc, svr.
O autolog é algo que deve ser executado antes do treinamento (antes do .fit(X_train, y_train)) para que o mlflow detecte os parametros usados no sklearn.
Acredito que a melhor solução é criar uma célula logo após os parâmetros do notebook, lá no início com o start_run e o autolog.
mlflow.start_run()
mlflow.sklearn.autolog()
Por fim, só relembro de não deixar código-fonte comentado. Pode remover o platiagro.save_metrics
|
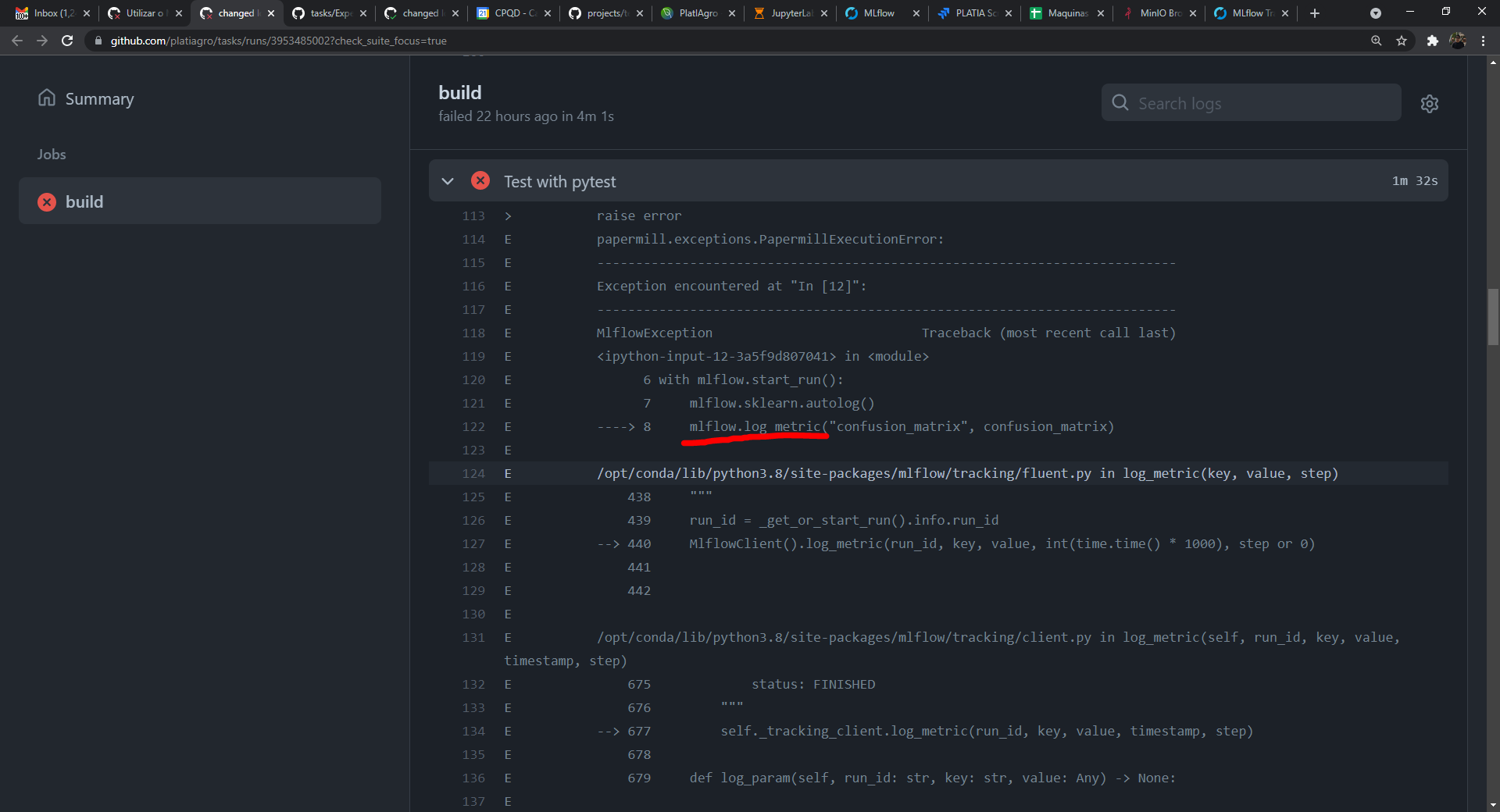
@dfvneto os notebooks falharam os testes por conta da dependência do MLflow: Será necessário adicionar o @mock.patch(
"mlflow.log_metric",
) |
Changed the placement of the initialization of the mlflow
Changed the placement of the initialization of the mlflow
Changed the placement of the initialization of the mlflow and removed wrong initialization of sklearn in notebooks where sklearn is not used
added mock to tests to include mlflow.log_metric
Changed cell description to fit new metric saving
Changed the number of arguments in mock.patch
Added mocked method as argument to test method so when called the method can assert true
Changed assert call location
Changed assert call location and formatted files
Removed unnecessary assert call
Removed unnecessary assert call
|
Lendo alguns resultados do CI percebi que está tendo problema no conda e no pickling na hora de serializar os objetos na hora de salvar |
Removed wrong extra import
new utils file for mocked method
Removed sklearn autolog
Changed mock annotation placement
Removed mock of log metrics since it's possible to test and use inside the container
Removed usage of mlflow
Removed autolog
Removed log_metric state because log metric can't be used to log arrays or dataframes
Removed log_metric state because log metric can't be used to log arrays or dataframes
It is necessary to cause this tests to fail and catch the error because they take too long to execute then causing timeout on the continuous integration. The errors are caused passing wrong arguments at the paper_mill.execute_notebook method, triggering the PapermillExecutionError at the majority of the cases (one error in the isolation forest clustering triggers JSONDecodeError).
|
Kudos, SonarCloud Quality Gate passed!
|








| max_features=1.0, | ||
| ), | ||
| ) | ||
| with pytest.raises(JSONDecodeError): |
There was a problem hiding this comment.
O statement desta linha ja faz o assert para o erro. Caso o erro ocorra, o teste é concluído com sucesso.
There was a problem hiding this comment.
Esse foi o único caso que consegui criar outro erro além do PapermillExecutionError. Embora todos os erros seguintes sejam os mesmos, as causas são diferentes, mas o papermill trata todos como a mesma exceção. Para capturar a exceção correta e ter acesso aos dados da exceção é necessário encapsular a exceção do papermill com a exceção desejada.
Fonte: nteract/papermill#344
| "Experiment.ipynb", | ||
| "/dev/null", | ||
| parameters=dict( | ||
|
|
There was a problem hiding this comment.
Nesse caso, o parâmetro removido foi o de dataset
|
|
||
| max_samples="auto", | ||
| contamination=0.1, | ||
| max_features=105665, |
There was a problem hiding this comment.
Nesse caso, max features excedeu o limite
| C=1.0, | ||
| fit_intercept=True, | ||
| class_weight=None, | ||
| solver="arroz", |
There was a problem hiding this comment.
Nesse caso, o solver foi alterado para um inválido
| one_hot_features="", | ||
|
|
||
| hidden_layer_sizes=100, | ||
| activation="lulu", |
There was a problem hiding this comment.
Nesse caso, o parâmetro activation foi alterado para um inválido
| one_hot_features="", | ||
|
|
||
| n_estimators=10, | ||
| criterion="gina", |
There was a problem hiding this comment.
Nesse caso, o parâmetro criterion foi alterado para um inválido
| one_hot_features="", | ||
|
|
||
| C=1.0, | ||
| kernel="linux", |
There was a problem hiding this comment.
Nesse caso, o parâmetro kernel foi alterado para um inválido
| max_features=1.0, | ||
| ), | ||
| ) | ||
| with pytest.raises(JSONDecodeError): |
There was a problem hiding this comment.
Esse foi o único caso que consegui criar outro erro além do PapermillExecutionError. Embora todos os erros seguintes sejam os mesmos, as causas são diferentes, mas o papermill trata todos como a mesma exceção. Para capturar a exceção correta e ter acesso aos dados da exceção é necessário encapsular a exceção do papermill com a exceção desejada.
Fonte: nteract/papermill#344
|
Os testes que falharam são os testes que estão falhando na master atualmente. Neles foram removidas as alterações referentes ao mlflow e removidas as chamadas referentes ao platia.save_metrics conforme orientado |
|
@dfvneto vou aguardar uns merges de outros PRs, mas já vou fechar a tarefa no Jira. |
removed unnecessary code block
A instalação da PlatIA agora possui o MLFlow como um de seus componentes.
Uma das funcionalidades do MLFlow é o tracking de métricas, dependências e artefatos.
Nesta tarefas iremos usar o SDK do MLFlow para salvar métricas das tarefas nativas da Plataforma.
https://www.mlflow.org/docs/latest/tracking.html