Convolutional layers are the primary building blocks of convolutional neural networks (CNNs), which are used in many machine learning tasks like image classification, object detection, natural language processing, and recommendation systems. In general, CNNs work well on tasks where the data/input features have some level of spatial relationship.
This project is working with a modified version of the LeNet-5 architecture shown below.
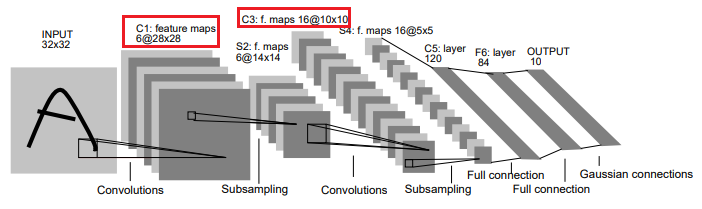
Source: http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
My optimized CUDA implementation of the convolutional layer will be used to perform inference for layers C1 and C3 (shown in red) in the figure above. I will be leveraging the mini-dnn-cpp (Mini-DNN) framework for implementing the modified LeNet-5.
Using the Fashion MNIST dataset, where the inputs to the network will be a batch of 10,000 single channel images, each with dimensions of 86 x 86 pixels. The output layer consists of 10 nodes, where each node represents the likelihood of the input belonging to one of the 10 classes (T-shirt, dress, sneaker, boot etc.)
Run the default Mini-DNN forward pass using rai without any CPU/GPU implementation.
Use RAI to run a batch forward pass on some test data.
rai -p <project-folder>
This will upload your project directory to rai and move it to /src, where the execution specified in rai_build.yml will occur.
Understanding rai_build.yml
The image: key specifies the environment that the rest of the execution will occur in.
This environment includes the Mini-DNN framework as well as the model definition and pre-trained weights that will be used to do inference. (Do not modify this entry)
The resources: key specifies what computation resources will be available to the execution. (Do not modify this entry)
The commands: key specifies the recipe that rai will execute. First, the project files are copied to the /build/student_code directory so that we have a record of your code along with your performance.
Then the files in custom are copied to /project/src/layer/custom in the Mini-DNN source tree and the pretrained weights are copied to /build. Finally, Mini-DNN is recompiled with your custom code.
./m1 100 runs the code specified in m1.cc program for a batch of 100 input images.
You should see the following output:
✱ Running /bin/bash -c "./m1 100"
Test batch size: 100
Loading fashion-mnist data...Done
Loading model...Done
Conv-CPU==
Op Time: 0.000655 ms
Conv-CPU==
Op Time: 0.000246 ms
Test Accuracy: 0.08
It is okay for the accuracy is low here since you haven't implemented the convolutional layers yet.
Modify rai_build.yml to use time to measure the elapsed time of the whole program.
- /bin/bash -c "time ./m1 100"
Modify rai_build.yml to invoke
- /bin/bash -c "./m1"
Please be patient as the CPU implementation is slow and will take several minutes to run. (For instance, a correct implementation with 10k images may take 13+ mins to run). If you want to iterate quickly when developing code using smaller batch sizes, see Specifying Batch Size. When your implementation is correct, you should see output like this:
Test batch size: 1000
Loading fashion-mnist data...Done
Loading model...Done
Conv-CPU==
Op Time: 7425.3 ms
Conv-CPU==
Op Time: 21371.4 ms
Test Accuracy: 0.886
Every time your layer is invoked, it will print the "Op Time," the time spent working on that layer.
Since the network has two convolutional layers, two times will be printed.
You can time the whole program execution by modifying rai_build.yml with
- /bin/bash -c "time ./m1"
./m1, ./m2, ./m3 and ./final all take one optional argument: the dataset size.
If the correctness for each possible batch size is as below, you can be reasonably confident your implementation is right. The correctness does depend on the data size.
For example, to check your accuracy on the full data size of 10,000, you could modify rai_build.yml to run
- /bin/bash -c "./m1 10000"
| Number of Images | Accuracy |
|---|---|
| 100 | 0.86 |
| 1000 | 0.886 |
| 10000 | 0.8714 |
Use gprof to profile the execution of your CPU forward convolution implementation.
Compile and link your cpu-new-forward.cc with the -pg flag, which creates a gmon.out artifact containing profile information when the binary m1 is executed. To analyze this information in human readable form, modify rai_build.yml and modify the line to redirect gprof output as outfile.
- /bin/bash -c "./m1 1000 && gprof -Q m1 gmon.out > outfile"
By default, gprof prints both a flat profile and a call graph (see "Interpreting gprof's Output" in the GNU gprof Documentation). With the -Q flag, we only print the flat profile. The information you need can be found near the beginning of gprof's output. You can download your build folder and process the output outfile with grep (with your function's name) or head. You can also open it with text editor if you want to examine the complete output.
| Implement a basic GPU Convolution kernel |
custom/new-forward.cu creates a GPU implementation of the forward convolution. The host code is separated in 3 parts. conv_forward_gpu_prolog allocates memory and copies data from host to device (Note: the device pointers given in this function are double pointers). conv_forward_gpu computes kernel dimensions and invokes kernel. conv_forward_gpu_epilog copies output back to host and free the device memory.
Modify rai_build.yml to run with batch_size=10000. Run
- /bin/bash -c "./m2"
to use GPU implementation.
System level profiling using Nsight-Systems
Use nsys (Nsight Systems) to profile the execution at the application level.
Once you've gotten the appropriate accuracy results, generate a profile using nsys. Make sure rai_build.yml is configured for a GPU run.
You have to remove -DCMAKE_CXX_FLAGS=-pg in cmake and make line of your rai_build.yml:
- /bin/bash -c "cmake /project/ && make -j8"
Then, modify rai_build.yml to generate a profile instead of just executing the code.
- /bin/bash -c "nsys profile --stats=true ./m2"
You should see something that looks like the following (but not identical):
Collecting data...
Test batch size: 10000
Loading fashion-mnist data...Done
Loading model...Done
...
Generating CUDA API Statistics...
CUDA API Statistics (nanoseconds)
Time(%) Total Time Calls Average Minimum Maximum Name
------- ---------- ----- ----------- -------- --------- ----------------
72.3 294859478 2 147429739.0 675112 294184366 cudaMalloc
22.8 92865680 2 46432840.0 44841150 48024530 cudaMemcpy
4.5 18405301 2 9202650.5 25789 18379512 cudaLaunchKernel
0.4 1467989 2 733994.5 473054 994935 cudaFree
Generating CUDA Kernel Statistics...
Generating CUDA Memory Operation Statistics...
CUDA Kernel Statistics (nanoseconds)
Time(%) Total Time Instances Average Minimum Maximum Name
------- ---------- ---------- ------- ------- --------- --------------------
100.0 3360 2 1680.0 1664 1696 conv_forward_kernel
CUDA Memory Operation Statistics (nanoseconds)
Time(%) Total Time Operations Average Minimum Maximum Name
------- ---------- ---------- ---------- -------- -------- ------------------
100.0 89602913 2 44801456.5 41565528 48037385 [CUDA memcpy HtoD]
CUDA Memory Operation Statistics (KiB)
Total Operations Average Minimum Maximum Name
-------- ---------- -------- ---------- -------- ------------------
538906.0 2 269453.0 250000.000 288906.0 [CUDA memcpy HtoD]
The CUDA API Statistics section shows the CUDA API calls that are executed. The CUDA Kernel Statistics lists all the kernels that were executed during the profiling session. There are also more details on the CUDA memory operations (CudaMemcpy) listed. There are columns corresponding to percentage of time consumed, total time, number of calls, and average/min/max time of those calls.
The CUDA documentation describes kernels and the programming interface.
You can find more information about nsys in the Nsight Systems Documentation
Kernel level profiling using Nsight-Compute
Nsight-Systems does not give you detailed kernel level performance metrics. For that, use nv-nsight-cu-cli (Nsight-Compute).
The Nsight Compute installation section describes how to install Nsight-Compute GUI on your personal machine. Note that you do not need CUDA to be installed.
You will see two types of times reported per layer as follows
✱ Running bash -c "./m3 1000" \\ Output will appear after run is complete.
Test batch size: 1000
Loading fashion-mnist data...Done
Loading model...Done
Conv-GPU==
Layer Time: 61.1231 ms
Op Time: 4.82135 ms
Conv-GPU==
Layer Time: 55.4437 ms
Op Time: 16.6154 ms
Test Accuracy: 0.886
- "Op Time" - This is time between the last cudaMemcpy call before your first kernel call and the first cudaMemcpy after your last kernel call (i.e. just
new-forward.cu -> conv_forward_gpu()). It does not include the cudaMemcpy times. - "Layer Time" - This is the total time taken to perform the convolution layer (C1 or C3). It includes the times for all kernel and CUDA API calls (i.e. the total time of all three
new-forward.cu -> conv_forward_gpu*functions).
You can gather system level performance information using nsys.
For detailed kernel level GPU profiling, use nv-nsight-cu-cli and view that information with nv-nsight-cu. To enable profiling with these tools,
you have to remove -DCMAKE_CXX_FLAGS=-pg in cmake and make line of your rai_build.yml:
- /bin/bash -c "cmake /project/ && make -j8"
You can see some simple information like so (as we did in milestone 2):
- /bin/bash -c "nsys profile --stats=true <your command here>"
You can additionally gather some detailed kernel level performance metrics.
- /bin/bash -c "nv-nsight-cu-cli --section '.*' -o analysis_file <your command here>"
This will generate analysis_file.ncu-rep.
--section '.*' may significantly slow the run time since it is profiling all the metrics. You may wish to modify the command to run on smaller datasets during this profiling.
You will need to follow the link rai prints after the execution to retrieve these files.
You can use the NVIDIA Nsight Compute GUI (nv-nsight-cu) to import those files.
You will need to install NVIDIA NSight Compute on your own machine. It can be downloaded as a standalone application. See instructions here
To import the files:
- Launch the GUI
/usr/local/NVIDIA-Nsight-Compute/nv-nsight-cu(or from wherever you installed it) - Close the intial Quick Launch menu
- Go to File > Open File and select the
.ncu-repfile from the\buildfolder you downloaded from rai (note that the downloaded file is aTARfile, not aTAR.GZas the name implies).
OR
- Directly launch from the terminal
/usr/local/NVIDIA-Nsight-Compute/nv-nsight-cu <filename>.ncu-rep
For a high-level overview of the Nsight software, visit here.