为啥String是不可变类?
-
string设置出来就是当一个值使用的。
-
技术上实现
- string被声明成为final
- 内部存储的数组是private final 外面是拿不到这个数组的引用
- 类只会提供读的方法,不提供内部修改的写方法
-
为啥要做成不可变?
-
安全性:类名(class forname)文件路径、URL、数据库连接符 系统变量、环境变量、token短暂的存储在String
-
字符串常量池需要不可变(想要字符串常量池的的内存优化和性能优势,前提就是String必须不可变)
-
作为Map/Set的key,必须稳定(放入map时会计算一次“abc”的
hashCode(),并根据它放到某个桶内,后续如若“abc”修改,hashcode()\equals()都会发生改变,但是key依旧放在旧的桶中
-
-
因为不可变,
hashcode()也可以安全缓存,下次直接使用安全缓存的值,查询更快
-
JVM的内存规范
- 堆(Heap)
- 存储所有对象的实例、数组的真实数据
- 所有线程共享
- 栈(stack)
- 每个线程单独一份,线程私有
- 一帧一帧的栈帧
- 局部变量表
- 操作数栈
- 中间计算结果
- 基本类型的局部变量的直接在栈中;引用类型的局部变量在栈中存的是指针,指向堆上的对象
- 堆(Heap)
-
JMM 并发语义规范(多个线程是怎样通过内存“看见”彼此写入的值?)
- 主内存
- 存储所有共享变量
- 包括:实例字段、静态字段、数组方法
- 简单理解成为**“堆+一堆方法区”**
- 工作内存
- 每个线程自己的工作内存
- 里面存的是主内存的本地缓存
- 实现上可以在:CPU 寄存器、CPU cache、线程栈中的局部副本等
- JMM 不直接讨论“堆”和“栈”这些物理区域,只关心
- 什么时候从主内存读到工作内存(load)
- 什么时候从工作内存刷新回主内存(store)
- 不同操作之间有什么 happens-before 关系
- 局部变量/方法参数是线程安全的因为根本没有共享,存在线程自己的栈中,天然线程私有、JMM对他们基本不做约束、也不关心可见性问题
- 栈中引用本身本身私有的,但是指向堆上的对象却是共享的
- 主内存
-
基本类型和包装类型?
-
基本类型是为了快和省
- 不是对象
- 直接存值,没有对象头
- 运算非常快
- 不能为null
-
包装类型是为了面向对象&框架统一
- Java是面向对象语言,很多API是基于object或者泛型写的
- 集合:
List<T>、Map<K,V>要求类型参数是引用类型。 - 反射、序列化、通用框架等都按对象来处理数据。
- 集合:
- 可以为null
- Java是面向对象语言,很多API是基于object或者泛型写的
-
两套并存属于历史+性能+语义折中的结果
-
装箱\拆箱
Integer a = 1; // 自动装箱,相当于 Integer.valueOf(1) int b = a; // 自动拆箱,相当于 a.intValue() List<Integer> list = new ArrayList<>(); list.add(1); // 这里也发生了装箱
-
-
面向对象的三大特征
- 封装:该暴露的暴露,该隐藏隐藏
- 信息隐藏,降低出错概率
- 降低耦合,方便维护
- 隐藏负载性
- 继承
- 代码复用
- 建立层次结构、方便抽象
- 配合多态、达到面向抽象编程
- 多态(父类引用指向子类对象,调用同一个方法,表达出不同的行为)
- 解耦调用方和实现方
- 方便扩展,而不用修改原来的代码(开闭原则:对扩展开放、对修改关闭)
- 让框架和业务代码松耦合(框架只依赖接口)
- 编译时多态VS运行时多态
- 绑定:一次方法调用,最终会执行到哪一个具体方法实现
- 编译时多态(静态绑定):
- 方法重载(overload)
- static/final/private JVM直接按编译时类型来绑定(不参与多态)
- 字段访问
- 运行时多态:方法重写(override)+动态分配
- x.f(arg)隐式参数x为类C的一个对象,编译器查找C类所有名为f的方法和父类中为f且可访问的方法(父类的private方法不可以访问)
- 重载解析:在所有名为f的方法中,找到一个与所提供参数类型完全匹配的方法
class Parent { public void hello(Object o) { System.out.println("Parent: Object"); } } class Child extends Parent { // 不是重写,而是重载! public void hello(String s) { System.out.println("Child: String"); } } public class Demo { public static void main(String[] args) { Parent p = new Child(); p.hello("abc"); } } // 实际输出 Parent Object /* 变量p的静态类型是parent 在 Parent 这个类型的视角里,只存在一个方法:hello(Object o) Parent.hello(Object) 这个方法签名。 这里已经完成了“编译时多态”的选择 运行时 p 的实际对象是 Child。 但 Child 没有 重写 hello(Object),它只是多了一个 重载 的 hello(String) */
- 封装:该暴露的暴露,该隐藏隐藏
-
接口VS抽象类
- 接口=能力的规范,多实现,无状态,为了解耦和组合而生
- 抽象类=半成品的父类,有状态、有构造、有默认逻辑、为复用和抽象而生。
- 抽象类
- 抽象一类东西 ,(is-a)
- 可以有构造方法,专门给子类”
super()“调用。用来初始化公共字段 - 是类,不能直接new: 抽象类本身不能 new,但可以有构造方法、可以被继承, 真正 new 的永远是“具体实现了所有抽象方法的子类对象”(包含匿名子类)
- 成员变量(实例、静态) 构造方法、抽象方法、普通方法
- 接口
- 抽象一类能力 (can-do)(Runnable、Comparable、Serializable)
- 不能有实例状态(只能有常量),不能有构造方法
- 方法都是public abstract 字段后世public static inal
- 接口无法随便加入新的方法(类必须实现接口的所有方法),Java8中引入default 方法,专门用来解决上面问题
- 构造方法不能重写?
- 构造方法根本就不能继承。所以无法重写
- 构造器本身不参与多态
- 构造方法的作用是负责本类的实例化
new 子类()时,大致顺序是: 父类静态 → 子类静态(类加载时一次) → 父类实例成员和实例代码块 → 父类构造方法 → 子类实例成员和实例代码块 → 子类构造方法。super()只能在子类构造方法中调用父类构造方法,super.hello()是显示的调用父类的hello()- this 可以作为当前对象的引⽤,但是 super 却不可以作为⽗类对象的引⽤。原因对象只有一个,父类部分不是“另一个对象
this.xxx():从子类类型开始往上找方法,遇到重写就用子类的,super.xxx():从父类类型那一层开始往上找方法,直接用父类的实现
-
静态变量&静态方法&静态代码块&静态内部类
- 静态内部类不依赖外部类实例
- 静态代码块在类加载的时候执行,并且只执行一次
-
类之间的关系
-
依赖(use-a)::⼀个类的⽅法使⽤另⼀个类的对象
-
聚合(has-a):l类A的对象包含类B的对象
-
继承(is-a)
-
向上转型变量:左父右子,多态:不能直接调用子类独有的方法使用向下转型
Animal a = new Dog(); // 向上转型 Animal a = new Dog(); Dog d = (Dog) a; // ✅ 向下转型,但要确保 a 真的是 Dog d.wagTail();
-
-
强制类型转化
Employee[] staff = new Employee[3]; // 统一定义为父类数组 staff[0] = new Manager(); // 向上转型 Manager m = new Manager(); Employee e = m; // 向上转型:子 -> 父,自动的 staff[1] = new Employee(); // 父类对象 staff[2] = new Employee(); // 父类对象 Employee e = new Manager(); // 向上转型 Manager m = (Manager) e; Manager boss = (Manager) staff[0]; // ✅ OK,上转型来的子类对象,转回去没问题 Manager boss = (Manager) staff[1]; // ❌ ERROR if (staff[1] instanceof Manager) { boss = (Manager) staff[1]; } // 向上转型:(子->父) 自动完成,永远安全 // 向下转型:(父->子) 必须强制转化"原本就是子类对象"的前提下才安全,否则会抛出ClassCastException
-
var关键字声明局部变量
-
创建新对象
-
构造器:
new User(...)静态工厂方法:
User.of(...) / valueOf(...) / getInstance(...)实例工厂方法:
factory.create()(适合需要有配置的工厂)Builder 的
build()方法:User.builder().xxx().build()拷贝 / 转换方法:
User.copyOf(other)/from(dto)clone()/ 原型模式:obj.clone()框架提供的构建方法:反射
newInstance()、反序列化readObject()、JSON/ORM 的readValue()/map()等 -
class User { private String name; private int age; private User(String name, int age) { // 构造器可以设成 private this.name = name; this.age = age; } // 静态工厂方法 public static User of(String name, int age) { return new User(name, age); } } //像 Integer.valueOf(...)、LocalDate.of(...)、List.of(...) 都是 JDK 里典型的静态工厂方法。 // 静态工厂方法的优点 // 1 方法名可以说明如何创建 // 2 可以复用/缓存对象 // 3 返回接口/父类 隐藏实现细节 // 4 of/valueOf/getInstance
-
class User { private final String name; private final int age; private final String address; private User(Builder b) { this.name = b.name; this.age = b.age; this.address = b.address; } public static class Builder { private String name; private int age; private String address; public Builder name(String name) { this.name = name; return this; } public Builder age(int age) { this.age = age; return this; } public Builder address(String addr) { this.address = addr; return this; } public User build() { // ⚠️ 真正“构建对象”的地方 return new User(this); } } } // 使用 User u = new User.Builder() .name("Tom") .age(18) .address("Beijing") .build(); // 类+内部builder+build() //
-
-
局部变量没有默认值的原因
- 防止忘记赋值的隐藏bug
- 局部变量生命周期短,显式赋值成本低
- Java编译器对局部变量有一个规则:在每个使用点之前,必须证明这个变量已经在所有可能的路径已经赋值
- 成员变量则统一由JVM给默认值,方便对象有一个合法的初始状态
-
对象的内存布局
-
对象头:(Mark Word)+ Klass Pointer+示例数据+对齐填充padding
- 运行时的元数据
- 哈希值
- GC分代年龄
- 锁状态标志
- 01:无锁
- 01 + biased 标记:偏向锁(只被一个线程反复使用)
- 00:轻量级锁(多线程但竞争不激烈,自旋 + CAS)
- 轻量级锁 = 用对象头 + CAS + 自旋实现的“用户态小锁""
- 10:膨胀后的重量级锁(monitor)(竞争激烈,使用 Monitor,线程阻塞/唤醒)
- 有其他线程来抢偏向锁 → 先撤销偏向锁,再考虑升级
- 线程持有的锁
- 指向栈上的锁记录(Lock Record),或者
- 指向 Monitor 对象(重量级锁里的监视器结构)
- 偏向线程的ID
- 几乎总是同一个线程在加锁, 就把“偏向线程 ID”写在对象头里,以后这个线程再进
synchronized,基本不需要原子操作。
- 几乎总是同一个线程在加锁, 就把“偏向线程 ID”写在对象头里,以后这个线程再进
- 偏向时间戳
- 类型指针
- 数组对象还有需要记录数据的长度
- 从JVM的视角看:每个对象都可以当作一把普通的锁,锁的状态就用对象头里的那几位+可以指定辅助结构。
- 运行时的元数据
-
-
JVM内存划分
-
堆:对象实例的仓库
- 普通对象
- 数组对象
-
方法区
- 类的信息 方法的字节码 常量等跟类有关的部分
- 运行常量池(Stirng pool)
- 运行时常量池VS字符常量池
- 运行时常量池=类的常量字典,在方法区上,每个类有一个
- 字符串常量池=全局String共享池,在堆上,一个JVM只有一个
- 字符串常量信息会先出现在运行时常量池,真正的string对象会被放到字符串池中复用
-
本地方法栈
-
Java的虚拟机栈
- 栈帧
- 本地变量表
- 基本变量
- 引用变量
- 操作数栈
- 动态连接 返回地址
- 本地变量表
- 栈帧
-
-
Object
-
Object与Cloneable()之间的关系:
Object.clone()在运行时检查当前对象是否是Cloneable类型。 是则允许克隆,不是就抛异常。 -
常见的空接口还有:
serializable\randomaccess -
Cloneable:给Object.clone()开门的“许可证” 重写clone():把这个“内部能力”包装成一个对外可用、类型正确、逻辑可控的方法。
-
-
异常
- Java中所有异常都是Throwable的子类+throw 可以由JVM抛,也可以由手动抛
- 在方法体内,如果可能抛出受检异常又不在本方法里
try...catch, 那么这个方法必须在签名上写throws(受检异常) - try-catch
try块中某行代码抛出了一个异常对象 JVM 停止执行try块后面的代码 从上到下按顺序找第一个“能接得住这个异常类型”的catch找到以后,执行该catch的处理逻辑 执行完catch后,继续执行finally(如果有),然后从整个try-catch-finally后面接着往下走- 没有任何
catch能匹配这个异常 或者当前方法根本没有try-catch异常会沿调用栈向上抛,直到某一层把它catch住,或者一直抛到最顶层导致线程结束。沿栈逐层退出并传播异常 - 父类异常要写在子类之后
- catch可以为空,不进行处理本身就是一种处理
- 对于基本类型或局部变量来说,如果
return在try里已经执行过了,而finally里又没有自己的return,那么finally中对这些局部变量的修改,不会改变最终返回值。
-
泛型(类型当参数)
-
将对象添加到集合中后,集合会失去对该对象的具体数据类型的记忆,导致在 取出对象时,集合将其视为
Object类型 为保持通透性-
集合对元素类型没有限制
-
集合取出对象后需要进行强制类型转化 可能引发
classcastException -
泛型就是在定义类、接口、方法的时候先不写具体的数据类型,而是直接使用一个类型占位符(T\E\K\V)
-
public class Box<T> { private T value; public void setValue(T value) { this.value = value; } public T getValue() { return value; } } // 类型安全 // 少写强制类型转化 Box<Integer> integerBox = new Box<>(); integerBox.setValue(42); Box<String> stringBox = new Box<>(); stringBox.setValue("Hello"); // 上界 表示T必须是Number 或者其子类 class NumberBox<T extends Number> { private T value; } if (obj instanceof List<String>) { } // 编译直接报错 if (obj instanceof List<?>) { }
-
泛型主要是编译期检查+自动加强转
-
泛型擦除主要是为了兼容性
-
规则:没有上界
T->Object有上界T->上界类型 -
编译器起作用、运行时就会删除
-
不能
new T[],不能new List<String>[]
-
-
-
反射?
Person.class.getConstructor(String.class).newInstance("Tom");
-
集合
-
任何集合框架包括对外的接口、接口的实现和对节后运算的算法
-
接口
-
Collection、Map、List、Set、Queue、Deque
Collection<E> / | \ List<E> Set<E> Queue<E> | Deque<E> Map<K,V> // 不继承 Collection
-
Collection:单值集合的“老祖宗”
-
List:有顺序、可重复的一维表
- 接口特点:
- 有顺序:按插入顺序保存元素。
- 可重复:允许多个元素
equals为 true。 - 支持 按下标随机访问
- 典型实现类
ArrayList:内部用动态数组,随机访问快,插入/删除中间元素相对慢LinkedList:内部用双向链表,按下标慢,插入/删除中间元素不需要大规模挪动元素
- 接口特点:
-
Set:不重复的“数学集合
- 接口特点
- 不允许重复元素:重复的判断依据是
equals(),哈希类 Set 还依赖hashCode()。 - 通常不保证顺序(HashSet),也可以是:
- 插入顺序:
LinkedHashSet - 有序 / 排序:
TreeSet(按元素的自然顺序或 Comparator)
- 插入顺序:
- 不允许重复元素:重复的判断依据是
- 典型实现类:
HashSet:基于哈希表,查找/插入/删除平均 O(1)LinkedHashSet:哈希表 + 双向链表,既快又能保持插入顺序。TreeSet:红黑树,自动排序,O(log n)。底层使⽤⾃平衡的⼆叉搜索树存储元素,以保持有序性
- 接口特点
-
Queue:排队用的队列
- 典型实现:
LinkedList:既是List又是Queue,可以当队列用。PriorityQueue:优先级队列,出队顺序按优先级来,不是单纯 FIFO。- 并发包里的
ArrayBlockingQueue、LinkedBlockingQueue等。
- 典型实现:
-
Deque:双端队列(可以当队列也可以当栈)
-
Deque继承Queue,表示 Double Ended Queue。两头都能插入和删除:
- 队头:
addFirst/pollFirst/peekFirst - 队尾:
addLast/pollLast/peekLast
- 队头:
-
典型实现:
ArrayDeque:基于循环数组的双端队列,效率很高,推荐替代Stack。LinkedList:同时实现了List、Queue、Deque,也可以当双端队列用。PriorityQueue: 基于优先级堆实现的队列。底层使⽤数组表示的⼆叉堆
-
-
Map<K,V>:键值对映射(不是 Collection)
- 接口特点:
- 存的是 key → value 的对应关系。
- key 不允许重复,value 可以重复。
- 通过 key 查 value,复杂度通常是 O(1) 或 O(log n)。
- 典型实现:
HashMap:最常用,哈希表 + 拉链 / 红黑树。LinkedHashMap:保持插入顺序或访问顺序。TreeMap:按 key 排序,基于红黑树。底层使⽤⾃平衡的⼆叉搜索树存储键值对,以保持有序性。- 并发版:
ConcurrentHashMap等。
- 接口特点:
-
-
辅助性质的接⼝Iterator、 LinkIterator、Comparator、Comparable这些接⼝
-
Iterator —— 遍历集合的“游标”
List<String> list = new ArrayList<>(); list.add("a"); list.add("b"); Iterator<String> it = list.iterator(); while (it.hasNext()) { String s = it.next(); if ("a".equals(s)) { it.remove(); // 使用迭代器删除,安全 } } for (String s : list) { ... }
-
ListIterator —— List 专用的“加强版迭代器”
List<String> list = new ArrayList<>(); list.add("a"); list.add("b"); list.add("c"); ListIterator<String> it = list.listIterator(); // 正向遍历 while (it.hasNext()) { String s = it.next(); if ("b".equals(s)) { it.add("B+"); // 在 b 后面插入一个元素 } } // 反向遍历 while (it.hasPrevious()) { System.out.println(it.previous()); }
- Comparable —— “我自己知道怎么跟别人比”
public class Person implements Comparable<Person> { private String name; private int age; @Override public int compareTo(Person other) { return this.age - other.age; // 年龄小的排前面 } }
-
Comparator —— “外部给你一套比较规则”
// 按年龄排序 Comparator<Person> byAge = new Comparator<Person>() { @Override public int compare(Person p1, Person p2) { return p1.getAge() - p2.getAge(); } }; // 按姓名字典序排序 Comparator<Person> byName = new Comparator<Person>() { @Override public int compare(Person p1, Person p2) { return p1.getName().compareTo(p2.getName()); } }; Collections.sort(list, byAge); Collections.sort(list, byName); Collections.sort(list, Comparator.comparing(Person::getAge)); Collections.sort(list, Comparator.comparing(Person::getName));
-
-
-
中间抽象类
-
实现类
- ArrayList、LinkedList、HashMap、HashSet、TreeMap
- Collections和Arrays类⽤来提供各种⽅法,⽅便开发
-
算法
-
-
集合和数组Array的关系?
- 数组不是集合的一部分,是更底层的存储结构
- 数组长度固定、支持基本类型、运行时保留元素类型
- 很多集合其实是在里面自己维护数组,帮你做自动扩容、封装各种操作
-
iterable iterator这两个接口的区别
- Iterable:我能给你一个迭代器 Iterator:我就是那个迭代器,本人亲自往前走
// 1. Iterable 接口(容器) public interface Iterable<T> { Iterator<T> iterator(); // 只要求实现这一个方法 // JDK 8 之后加的一些默认方法: default void forEach(Consumer<? super T> action) { ... } default Spliterator<T> spliterator() { ... } } // 2. Iterator 接口(游标) public interface Iterator<E> { boolean hasNext(); // 还有下一个元素吗? E next(); // 取出下一个 default void remove() { ... } // 删除当前元素(可选操作) }
- Collection 同时是 Iterable 的实现者和 Iterator 的生产者
public class ArrayList<E> implements List<E> { // 内部数组略 @Override public Iterator<E> iterator() { return new Itr(); // 返回一个内部类对象 } private class Itr implements Iterator<E> { int cursor; // 下一个要访问的下标 public boolean hasNext() { ... } public E next() { ... } public void remove() { ... } } } // ArrayList: // 实现了 Iterable:所以你可以 for (E e : list)。 // 内部有一个实现了 Iterator 的内部类,用来干真正遍历的工作。
- 凡是想在
for (… : …)里用的对象,就让它实现 Iterable; 但真正往前走、取元素的,是 Iterator
-
迭代器
- 迭代器就是:把“遍历一个容器时的当前位置和规则”,封装成一个独立的对象。
- Iterable 负责“能被遍历”,Iterator 负责“怎么走”
- 遍历的状态 + 遍历的动作”对象化,从而屏蔽底层是数组、链表还是树
-
remove()和clear()
-
remove()属于差集删除 clear()属于清空 -
removeall()属于集合减集合 -
remove(Object o):删一个匹配的元素(List 是删第一个匹配的)。removeAll(Collection<?> c):删所有属于 c 的元素。retainAll(Collection<?> c):保留“属于 c 的元素”,其他都删掉(这是“交集”操作)。clear():全部清空。
-
-
ArrayList的扩容机制
- 本质就是计算出新的扩容数组的size后实例化,并将原有数组内容复制到新数组中去
- 新的容量会是原容量的1.5倍。 新容量=旧容量右移⼀位(相当于除于2)在加上旧容量
- 当我们添加第一个元素时,内部会调整扩容方法返回最小容量10
-
BlockingQueue
- 带“阻塞”功能的线程安全队列,专门为多线程生产者–消费者场景准备的 Queue。
BlockingQueue是多个线程一起用,而且在队列满/空的时候,会让线程“等一等”,而不是马上返回失败或抛异常- 普通
Queue``add满就抛异常;offer满就false;remove/poll空就抛异常 / 返回null;完全不会阻塞当前线程。 - 多了
put()、take()等,会在满/空时 挂起线程等待。 - 常⻅实现类:
ArrayBlockingQueue:基于数组实现的有界队列。LinkedBlockingQueue:基于链表实现的有界或⽆界队列PriorityBlockingQueue:基于优先级的⽆界队列。DelayQueue:⽤于实现延迟任务的⽆界队列
-
Map
- 需要保证线程安全,则可以使⽤
ConcurrentHashMap。它的性能好于Hashtable,因为它在put时采⽤分段锁/CAS的加锁机制,⽽不是像Hashtable那样,⽆论是put还是get都做同步处理 - Hashtable 的迭代器是通过 Enumerator 实现的。HashMap 的迭代器是通过 Iterator 实现的。
- Hashtable 不允许键或值为 null。HashMap 允许键和值都为 null。
- Hashtable 是 Dictionary 类的⼦类,⽽ HashMap 是 AbstractMap 类的⼦类,实现了 Map 接⼝
- 需要保证线程安全,则可以使⽤
-
HashMap和HashSet的区别?
-
JDK7和JDK8中的HashMap有什么区别?
-
Map的6种遍历
-
注解
- 框架在启动时用“反射”去扫描这些注解,然后根据标签决定怎么处理这个类 / 方法。
- 注解其实就是一种特殊的接口
- 注解的成员叫做注解属性(基本类型、String\Class\枚举\数组)注解本身不能写普通平方法
-
IO流
- 字节流
- 每次读取(写出)⼀个字节,当传输的资源⽂件有中 ⽂时,就会出 现乱码。
InputStream 和 OutputStream: 是所有字节输⼊流和输出流的抽象基类。它们分别⽤于读取和写⼊字 节。FileInputStream 和 FileOutputStream: ⽤于从⽂件中读取字节和向⽂件中写⼊字节。ByteArrayInputStream 和 ByteArrayOutputStream: 分别⽤于从字节数组中读取数据和将数据写⼊字 节数组。
- 字符流
Reader 和 Writer: 是所有字符输⼊流和输出流的抽象基类。它们分别⽤于读取和写⼊字符。FileReader 和 FileWriter: ⽤于从⽂件中读取字符和向⽂件中写⼊字符。BufferedReader 和 BufferedWriter: ⽤于提供缓冲区,提⾼读取和写⼊的效率。
- 节点流和处理流(包装流)
- 字符流是字节流的包装:InputStreamReader/OutputStreamWriter
- 字节流
-
ByteArrayInputStream/BufferedInputStream/int read(byte[] b) -
Java的序列化与反序列化
- 要实现Serializable接⼝,该接⼝是⼀个标记接⼝,它没有提供任何⽅法,只 是标明该类是可以序列化的
- Java的很多类已经实现了Serializable接⼝,如包装类、String、Date等
- 需要使⽤对象流ObjectInputStream和ObjectOutputStream
-
多线程
-
RunnableVSExecutor-
Runnable是一个函数式接口,只干一件事:定义任务逻辑 -
给我一个
Runnable,我负责找地方(新线程 / 线程池 / 当前线程)帮你执行 -
类比
-
CallablevsExecutorService.submit():有返回值的任务IterablevsIterator:能被遍历的容器 vs 遍历的游标ComparatorvsCollections.sort():比较规则 vs 使用这个
-
-
-
-
Java 内存模型
- 并发编程中,线程间的通信有两种模型:共享内存和消息传递。
- Java采⽤的是共享内存模型,隐式通信,显示同步
-
数据依赖性
- 如果两个操作访问同⼀个变量,且这两个操作中有⼀个为写操作,此时这两个操作之间就存在数据依赖性。
- 数据依赖分为 写后读、写后写、读后写
- 编译器和处理器在重排序时,会遵守数据依赖性
-
顺序⼀致性模型
- 所有线程共享一个“全局的、大家都认同的顺序”,而且每个线程内部的执行顺序不能被打乱。
- 对每个线程来说,它自己的操作顺序和程序中写的顺序一致(不乱序);
- 所有线程的操作可以被看成按某种单一的顺序执行,每个操作一旦执行,就立刻对所有线程可见。
- JMM 不是严格的顺序一致性模型,但 Java 提供了一些机制,让你“获得顺序一致的效果
- 临界区内部可以进行重排序,但是不能越过锁的边界逃逸出去
-
volatile(只管同步内存视图和顺序,不管临界区互斥)
-
对
volatile变量的读写 直接作用于主内存,保证线程间的 可见性 -
volatile写具有 release 语义,volatile读具有 acquire 语义,在其前后插入内存屏障,禁止相关指令重排 -
对同一个
volatile变量的写 happens-before 后续线程对该变量的读,从而可以用它来做“轻量级同步” -
volatile的内存语义就是:写 volatile 像“释放(release)”,读 volatile 像“获取(acquire)- 对一个
volatile变量的 写,会把当前线程工作内存中对该变量以及之前的写操作 刷新到主内存 - 对一个
volatile变量的 读,会让当前线程 从主内存重新读取 这个变量的值,并且丢弃对应的旧缓存
- 对一个
-
有序性 / 禁止重排序(ordering)
- 写 volatile v
- JMM 禁止:在程序顺序上 排在它之前 的普通读写,跑到它后面;
- 也禁止:在它之后的东西被重排到它前面
- 效果:写
volatile之前的所有写,都必须先“对外生效”,然后才写v
- 读 volatile v
- JMM 禁止:在程序顺序上 排在它之后 的读写,跑到它前面
- 也禁止:它前面的东西被重排到它后面
- 先读到
v,再基于这个“新世界观”去读后面的变量
- 写 volatile v
-
8 种内存交互操作
-
lock:作用于 主内存中的某个变量,把它标记成“当前线程独占 -
unlock:作用于 主内存中的某个已锁定变量,把锁释放掉,释放后别的线程才可以再lock它 -
read:作用于 主内存中的变量,把变量的值从主内存“运送”到当前线程这里 -
load作用于 工作内存中的变量,把刚刚read得到的值 放进工作内存里的那个变量副本 -
use:作用于 工作内存中的变量副本,把它的值交给执行引擎用 -
assign:作用于 工作内存中的变量副本,把执行引擎计算出来的新值 写回到工作内存副本 -
store:作用于 工作内存中的变量副本,把副本的值发送到主内存,准备写回 -
write:作用于 主内存中的变量,把store送来的值真正写进主内存的那个变量
-
-
-
锁的内存语义
- 释放锁(unlock)时:当前线程在临界区里对共享变量做的修改,都会被强制
store+write回主内存。 - 获取锁(lock)时:当前线程原来工作内存里缓存的那些共享变量值会被视为“过期”,必须重新
read+load从主内存里拿一份最新的。 - 任何线程在进入临界区时,看到的共享变量值,都是其他线程在上一次释放锁时已经刷回主内存的结果
- 锁的加解锁,底层实现时就会利用这套 volatile 语义来实现上面说的“释放时刷新、获取时失效”的效果
- JMM 定义了“锁”的抽象内存语义-》AQS 提供了一个框架:用
volatile state+ CAS + 队列 来实现“锁/信号量”等同步器-》ReentrantLock 是在 AQS 上实现的一个具体的“可重入互斥锁”, 并且提供了公平 / 非公平 两种策略 synchronized:JVM 自己用 monitor + 内存屏障实现,✅ 不需要 Java 层的volatile字段ReentrantLock:在 Java 层用 AQS 的volatile state+ CAS 来实现
- 释放锁(unlock)时:当前线程在临界区里对共享变量做的修改,都会被强制
-
final内存语义实现
- 其他线程如果拿到了这个对象引用,那么它看到的 final 字段值一定是构造函数里设好的最终值
- 只要你 第一次 拿到了这个对象的引用,那么你之后读到的 final 字段值,至少是构造函数里写入的那个值,不会再看到“旧版本
-
happens-before
- JMM 保证 happens-before 规则满足时,就有足够的内存可见性保证,只要不打破这些 happens-before 关系,怎么重排都行
- A happens-before B” ⇒ A 对共享内存的结果对 B 一定可见, 并且在所有合法的执行中,A 的执行“先于” B
- happens-before 同时包含了 “可见性 + 先后顺序(有序性)
-
线程安全
-
阻塞同步(互斥)
- 内置锁也就是
synchronized关键字 JUC下具体锁ReentrantLock、ReentrantReadWriteLock、StampedLock等
- 内置锁也就是
-
⾮阻塞同步
-
JUC下的各种原子类(CAS + volatile) -
AtomicInteger AtomicLong AtomicBoolean AtomicIntegerArray AtomicLongArray AtomicReferenceArray AtomicReference<T> AtomicStampedReference<T>(带版本号,解决 ABA) AtomicMarkableReference<T>
-
-
-
Semaphore
emaphore内部也用 AQS 实现,属于 共享模式的同步器- 许可证数本质上是 AQS 的
state,是一个volatile
-
JUC
- 原子类
atomic - 显式锁
locks - 并发容器
collections- 帮你封装好了内部锁 / CAS 等逻辑,对外提供线程安全的集合操作
- 同步器
synchronizers - 线程池 / 任务执行框架
executors
- 原子类
-
线程池
- 一组提前创建好的工作线程,再配上一条任务队列
- 复用线程,减少频繁创建/销毁线程的开销/控制并发数量/统一管理线程
- 线程池中核心接口
Executor:最顶层接口,只有一个execute(Runnable)ExecutorService:在 Executor 基础上加了submit(Callable/Runnable)shutdown()、shutdownNow()等生命周期方法。
- 实现类
ThreadPoolExecutor:真正的通用线程池实现ScheduledThreadPoolExecutor:定时任务线程池。
- 工具类
Executors:帮你快速创建常见配置:newFixedThreadPoolnewCachedThreadPoolnewSingleThreadExecutornewScheduledThreadPool
-
堆和栈的区别
- 堆是运⾏时确定内存⼤⼩,⽽栈在编译时即可确定内存⼤⼩
- 堆内存由⽤户管理( Java中由JVM管理),栈内存会被⾃动释放
- 栈实现⽅式采⽤数据结构中的栈实现,具有先进后出的顺序特点,堆为⼀块⼀块的内存
-
对象的创建
- 类加载检查
- 分配内存
- 内存规整
- 内存不规整
- 并发问题解决方法
- CAS+失败重试
- TLAB:线程先在自己的TLAB中分配,用完了之后,分配新的缓冲区,进行同步锁定
- 初始化内存空间
- 进行对象头的配置
- 执行构造函数
-
JVM经典收集器--G1
- 在大内存(几十 GB)情况下也能工作得比较好,尽量控制 STW(Stop-The-World)停顿时间
- G1将整个堆内存划分为多个等⼤的region,然后每个region不同时间代表⻆⾊不固定,不过整体分为四种:Eden、Survioor、Old、Humongous
- Young GC(年轻代收集)
- 回收所有 Eden Region + 部分/全部 Survivor Region;
- 停顿是 STW
- Mixed GC(混合收集)
- 在 Young GC 的基础上,再加上一些 Old Region 一起回收;
- 这些 Old Region 按“垃圾比例高不高”来选,垃圾多的优先被选中(Garbage-First);
-
类加载机制
-
加载
- 通过类的全限定名来获取定义此类的⼆进制字节流
- 将这个字节流所代表的静态存储结构转化为⽅法区的运⾏时数据结构
- 、在内存中⽣成⼀个代表这个类的java.lang.class对象,作为⽅法区这个类的各种数据访问的⼊
-
连接
- 验证
- 准备
- 类中静态变量分配内存并设置类变量初始值
public static int a = 123, 准备阶段会给 a 赋值为 0,⽽不是 123 public static final int value = 123
- 类中静态变量分配内存并设置类变量初始值
- 解析
- 是Java虚拟机将常量池内的符号引⽤替换为直接引⽤的过程
- 执⾏类构造器()⽅法的过程
-
初始化
-
初始化时期
-
new 对象:
new A() -
调用类的静态方法:
A.staticMethod() -
访问或赋值静态变量:
A.staticField = 1 -
通过
Class.forName("pkg.A")主动加载(默认会初始化) -
作为程序入口的主类:
public static void main(...) -
反射调用会触发初始化的地方
-
-
-
使用
-
卸载
-
-
双亲委派制度
- 双亲委派 = 类加载器接到“加载类”的请求时,先让父加载器试,父不行自己再加载。这样可以保证核心类库由上层统一加载,避免重复加载和安全问题,是 Java 类加载体系的基础规则。
BootstrapClassLoader:加载java.*核心库。PlatformClassLoader(或 ExtensionClassLoader):加载扩展/模块库。AppClassLoader:加载 classpath 下的应用类、第三方库。- 你自己写的 ClassLoader,默认如果只重写
findClass,也会跑上面那套loadClass逻辑,仍然遵守双亲委派。
- 双亲委派 = 类加载器接到“加载类”的请求时,先让父加载器试,父不行自己再加载。这样可以保证核心类库由上层统一加载,避免重复加载和安全问题,是 Java 类加载体系的基础规则。
-
内部类(定义在 另一个类或方法内部 的类)
-
编译后都是“普通类”,只是名字变成
Outer$Inner.class这种形式 -
分类
- 成员内部类=类里面、方法外面,没有 static 修饰
- 依赖外部类实例而存在
- 可以直接访问外部类的 所有成员(包括 private)
- 需要一个“跟某个外部对象强绑定”的小工具类;
- 静态内部类
- 不依赖外部类实例,可以像普通类一样创建
- 只能访问外部类的 static 成员,不能直接访问实例字段。
- 作为某个类的“内部工具类 / Builder / 配置类”存放
- 局部内部类=定义在 方法内部 的类,作用域只在这个方法内
- 只能在定义它的方法里使用
- 现在更多时候会用 匿名内部类 / Lambda 替代。
- 匿名内部类
- 匿名内部类 = 没有名字的局部内部类,一般用来“临时实现一个接口/抽象类”顺手 new 出来
- 成员内部类=类里面、方法外面,没有 static 修饰
-
使⽤原因
- 内部类可以对同⼀个包中的其他类隐藏
- 内部类⽅法可以访问定义这个类的作⽤域中的数据,包括私有数据
-
-
lambda
(参数列表) -> 表达式 (参数列表) -> { 语句块 } // 1)无参数,无返回值 () -> System.out.println("hello"); // 2)一个参数,无返回值(括号可以省略) x -> System.out.println(x); // 3)多个参数,有返回值 (int a, int b) -> { return a + b; }; // 4)类型可省略(编译器能推断) (a, b) -> a + b; // 单行表达式可以省略 { } 和 return MyFunc f = (a, b) -> a + b; int res = f.apply(3, 5); // 8
-
和匿名内部类的关系 & 区别
-
匿名内部类:创建了一个新的类,实现某接口/继承某父类;
lambda:更像是一个函数,编译器用 invokedynamic 等机制实现,不是简单的匿名类语法糖。
-
匿名内部类里:
this→ 匿名内部类对象本身;lambda 里:
this→ 外部类Outer的实例。 -
名内部类有自己的作用域,可以定义与外部同名的变量(会遮蔽外部变量);
lambda 的作用域跟外层方法一样,不能声明同名局部变量:
-
-
代理类
-
外暴露和“真实对象”几乎一样的接口,但内部会在调用前后加点“额外操作”,然后再去调真正的目标对象。
-
原因
- 想在不修改原来业务代码的情况下,统一加一些横切逻辑:
- 打日志
- 权限校验
- 性能统计
- 事务管理
- RPC 调用前后的封装
- 想在不修改原来业务代码的情况下,统一加一些横切逻辑:
-
静态代理和动态代理
- 三要素:
- 接口:比如
UserService - 真实对象:
UserServiceImpl - InvocationHandler:写“调用前后干什么”的地方
- 接口:比如
UserService target = new UserServiceImpl(); UserService proxy = (UserService) Proxy.newProxyInstance( target.getClass().getClassLoader(), // 用目标类的类加载器 new Class<?>[]{UserService.class}, // 要实现的接口 new InvocationHandler() { @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { System.out.println("[日志] 调用方法:" + method.getName()); Object result = method.invoke(target, args); // 反射调用真实对象 System.out.println("[日志] 方法结束:" + method.getName()); return result; } } ); proxy.addUser("张三");
- CGLIB 动态代理
- DK 动态代理有个硬要求:目标类必须实现接口。如果没有接口,就用 CGLIB(基于继承的字节码增强)
- JDK 动态代理:基于接口,CGLIB 代理:基于继承
- ASM 生成字节码,创建子类,MethodInterceptor 拦截
- 三要素:
-
-
Java中的移位符?
>>向右移动若干位,高位补符号位,低位补零>>>无符号右移,忽略符号位,空位都以0补齐- 移位操作,只支持
int\long,编译器对short\byte\char移位前都会将其转化位int类型 - 位字段管理、哈希算法、数据压缩、数据校验、内存对齐
- 当int类型左移右移之前大于等于32位时候,会先执行%32操作
-
字节码+解释执行+运行时再编译优化
-
包装类型的缓存机制
- 包装类型不要直接使用
==比较大小
- 包装类型不要直接使用
-
为啥成员变量有默认值?
- Java语言强制规范,对象一旦创建出来。它的状态一定是确认的,可以预测的
- 有了默认值,不必立即给每个字段指定初始值
- 成员变量强调是安全和确定性,局部变量强调“程序员显式初始化,避免逻辑bug”
-
浮点数精度丢失问题?
- 因为浮点数的小数部分通过
整数/2^n来实现,浮点数的运算会进一步放大这种误差 - bigdeimcal解决浮点数精度丢失的问题
- 大整数和小数位数 “123.45”
unscaledValue=12345,scale=2
- 大整数和小数位数 “123.45”
- 因为浮点数的小数部分通过
-
字符型常量只占2个字节;字符串常量占n+1个常量
-
静态方法不能调用非静态成员
-
重写的多态效果是在运行期才体现出来的,
- 编译器只做“语法验证+生成虚调用指令”真正“选哪个实现”这件事是在运行期体现
final/private/static方法都不会发生动态分配- 如果父类方法返回的是基本类型或者
void,子类重写时候,返回类型必须完全相同,不能改 - 如果父类方法返回的是引用类型,子类重写时可以返回同类型或者其子类
- 异常类型“更小或者相等”
- 子类方法的访问权限,不能比父类更小
-
Java中常见的标记接口
CloneableSerializableRandomAccessEventListener
-
Java 语言本身并不支持运算符重载,“+”和“+=”是专门为 String 类重载过的运算符,也是 Java 中仅有的两个重载过的运算符。
- 字符串对象通过“+”的字符串拼接方式,实际上是通过
StringBuilder调用append()方法实现的,拼接完成之后调用toString()得到一个String对象 。
- 字符串对象通过“+”的字符串拼接方式,实际上是通过
-
常量折叠
-
String str3 = "str" + "ing";` // 编译器会给你优化成 ` String str3 = "string";
-
- 基本数据类型和字符串常量
- final修饰的基本类型和字符串变量
- 字符串通过+基本类型之间算术运算位运算
- 引用类型无法在编译器及逆行确定,不会进行折叠
-
不要在finally语句块中使用return,当try与finally语句都存在return,try语句中return会被忽略,try中语句return会被暂存在一个本地变量中,当执行finally语句中的return之后,这个本地变量的retun中就会变成rfinally
-
异常使用注意地方
- 不要把异常定义为变量,手动new一个新的异常对象抛出
- 抛出的异常对象一定得有意义
- 抛出更加具体的异常
-
枚举的本质也是一下语法糖
public enum Color { RED, GREEN, BLUE; } public final class Color extends java.lang.Enum<Color> { public static final Color RED = new Color("RED", 0); public static final Color GREEN = new Color("GREEN", 1); public static final Color BLUE = new Color("BLUE", 2); private static final Color[] $VALUES = { RED, GREEN, BLUE }; private Color(String name, int ordinal) { super(name, ordinal); } public static Color[] values() { return $VALUES.clone(); } public static Color valueOf(String name) { return Enum.valueOf(Color.class, name); } } // enum会被编译器变成一个final类 // 继承java.lang.enum // 每个枚举对象是一个public static final // 编译器自动生成value\valueof\ordinal()
- -
12种语法糖
-
switch支持String与枚举
public class switchDemoString { public static void main(String[] args) { String str = "world"; switch (str) { case "hello": System.out.println("hello"); break; case "world": System.out.println("world"); break; default: break; } } } // switch对string的支持 public class switchDemoString { public switchDemoString() { } public static void main(String args[]) { String str = "world"; String s; switch((s = str).hashCode()) { default: break; case 99162322: if(s.equals("hello")) System.out.println("hello"); break; case 113318802: if(s.equals("world")) System.out.println("world"); break; } } } // 进行switch的是equals()和hashcode()方法实现的
-
可变长参数
-
自动装箱与拆箱
-
枚举
public enum Color { RED, GREEN, BLUE; } public final class Color extends java.lang.Enum<Color> { public static final Color RED = new Color("RED", 0); public static final Color GREEN = new Color("GREEN", 1); public static final Color BLUE = new Color("BLUE", 2); private static final Color[] $VALUES = { RED, GREEN, BLUE }; private Color(String name, int ordinal) { super(name, ordinal); } public static Color[] values() { return $VALUES.clone(); } public static Color valueOf(String name) { return Enum.valueOf(Color.class, name); } }
-
-
ArrayList和Array的区别
Arraylist动态扩容或缩容Array不能改变大小Arraylist泛型保证安全ArrayArraylist只能存储对象。对于基本类型数据,需要使用其对应的包装类Array直接存储基本类型数据,也可以存储对象Arraylist持插入、删除、遍历等常见操作,并且提供了丰富的 API 操作方法ArrayArraylist创建时不需要指定大小Array创建时必须指定大小。Arraylist
-
Queue与Deque
- queue扩展了collectio的接口,根据因为容量问题而导致操作失败处理方法的不同,可以分为两类方法:一种操作失败后抛出异常。另一种则会返回特殊值,
- 抛出异常
add(E e)remove() element()返回特殊值offer(E e)poll()peek() - 阻塞队列:内部已经实现等待/唤醒机制,已经处理好了并发访问,提供了多种语义清晰的API
- 适合用在多线程的生产者–消费者模型中,可以大幅简化线程间通信和协调的代码。
-
HashMap和Hashtable的区别
- 线程是否安全:
HashMap是非线程安全的,Hashtable是线程安全的,因为Hashtable内部的方法基本都经过synchronized修饰。(如果你要保证线程安全的话就使用ConcurrentHashMap吧!) - 效率: 因为线程安全的问题,
HashMap要比Hashtable效率高一点。另外,Hashtable基本被淘汰,不要在代码中使用它 - 对 Null key 和 Null value 的支持:
HashMap可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;Hashtable 不允许有 null 键和 null 值,否则会抛出NullPointerException - 初始容量大小和每次扩充容量大小的不同: ① 创建时如果不指定容量初始值,
Hashtable默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么Hashtable会直接使用你给定的大小,而HashMap会将其扩充为 2 的幂次方大小(HashMap中的tableSizeFor()方法保证,下面给出了源代码)。也就是说HashMap总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。 - 底层数据结构: JDK1.8 以后的
HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间(后文中我会结合源码对这一过程进行分析)。Hashtable没有这样的机制
- 线程是否安全:
-
HashMap和HashSet
-
hashmap和treemap
-
为什么优先扩容而非直接转为红黑树?
- 数组扩容能减少哈希冲突的发生概率(即将元素重新分散到新的、更大的数组中),这在多数情况下比直接转换为红黑树更高效。
- 红黑树需要保持自平衡,维护成本较高。并且,过早引入红黑树反而会增加复杂度
-
hashmap的长度为啥是2的幂次方?
- 只有当 n 是 2 的幂时,
(n - 1) & hash才等价于hash % n。 计算速度更快 - 扩容会更加高效:扩容时不用重新算 hash,只要看 hash 的某一位是 0 还是 1 即可
- 保证索引分布均匀,减少哈希冲突
- new HashMap<>(10);JDK 内部会通过一个
tableSizeFor方法把它“上调到最近的 2 次幂”,也就是变成16
- 只有当 n 是 2 的幂时,
-
JDK 1.2 及以后,Java 线程改为基于原生线程(Native Threads)实现,也就是说 JVM 直接使用操作系统原生的内核级线程(内核线程)来实现 Java 线程,由操作系统内核进行线程的调度和管理。
- 用户线程:由用户空间程序管理和调度的线程,运行在用户空间,创建和切换成本低,但不可以利用多核
- 内核线程:由操作系统内核管理和调度的线程,运行在内核空间,内核态线程,创建和切换成本高,可以利用多核。
- 现在Java线程的本质其实就是操作系统的线程
-
内存模型
- 程序计数器私有的原因:为了线程切换后能恢复到正确的执行位置
- 虚拟机栈和本地方法栈:为了保证线程中局部变量不被别的线程访问到
-
sleep()与wait()方法
-
sleep()方法没有释放锁,wait()方法释放了锁 -
sleep()通常被用于暂停执行wait()方法通常被用于线程之间的交互 -
sleep()超时自动苏醒,wait()方法不会自动苏醒 -
sleep()方法是Thread类的静态本地方法,是让当前线程暂停执行。不涉及到对象类,也不需要获得对象锁,wait()获得对象锁的线程实现等待,会自动释放当前线程占有的对象锁
-
-
调用
start()方法方可启动线程并使线程进入就绪状态,直接执行run()方法的话不会以多线程的方式执行。 -
JVM 本身不负责线程的调度,而是将线程的调度委托给操作系统。
- 操作系统通常会基于线程优先级和时间片来调度线程的执行,高优先级的线程通常获得 CPU 时间片的机会更多。
- Java 使用的线程调度是抢占式的
- 任务是 CPU 密集型的,那么开很多线程会影响效率;如果任务是 IO 密集型的,那么开很多线程会提高效率。
-
双重检验锁方式实现单例模式
public class Singleton { // 关键:必须是 volatile private static volatile Singleton instance; // 私有构造函数,禁止外部 new private Singleton() {} public static Singleton getInstance() { // 第一次校验:大部分情况直接通过,不用加锁 if (instance == null) { synchronized (Singleton.class) { // 只在首次初始化时真正加锁 // 第二次校验:防止并发情况下重复创建 if (instance == null) { instance = new Singleton(); } } } return instance; } }
- 原因:懒加载+线程安全+尽量少加锁
- 第一层是为了保证性能,多数情况下,已经不为null了,第二层是为了保证单例模式
- 为啥一定要加voatile
new Singleton()并不是一个原子操作:- 分配内存
- 调用构造函数初始化对象
- 将内存地址赋给
instance()- 如果没有volatile约束情况下,编译器和CPU可能会对2,3进行指令重排
-
syncgronized和volatile有什么区别volatile轻量级线程同步,只能修饰变量、保证数据可见性,但是不保证数据的原子性synchronized解决多个线程中间访问资源的同步性
-
stampedLock
- JDK1.8引入性能更好的读写锁,不可重入且不支持条件变量
conition - 写锁:独占锁
- 读锁(悲观读):共享锁,
- 乐观读:允许多个线程获取乐观读,以及读锁,同时允许一个写线程获取写锁
- 最大亮点,不h会真正加读锁,只是会返回一个当前版本的stamp
- 读完后,用
validate(stamp)判断期间是否有写线程修改过数据true:说明这段时间内没有写操作,读到的数据是“逻辑一致”的,可以直接使用false:说明有写操作发生,你这次读可能不一致,需要 退化为正常读锁 重读一遍
- 基于独立
clh锁
- JDK1.8引入性能更好的读写锁,不可重入且不支持条件变量
-
ThreadLocalMap与ThreadLocal- 不是 “ThreadLocal 里有 Map”,而是 “Thread 里有 Map”
- ThreadLocalMap 的 key 是 ThreadLocal 实例本身,value 是你为这个 ThreadLocal 在该线程里 set 的值。
- key是弱引用,value是强引用
- 跨线程传递threadlocal的值
InheritableThreadocal:继承自ThreadLocal。使用InheritableThreadLocal时,会在创建子线程时,令子线程继承父线程中的ThreadLocal值,但是无法支持线程池场景下的ThreadLocal值传递。TransmittableThreadLocal:TransmittableThreadLocal(简称 TTL) 是阿里巴巴开源的工具类,继承并加强了InheritableThreadLocal类,可以在线程池的场景下支持ThreadLocal值传递。
-
threadpoolexcutor与excutor(实现类与接口的关系)
-
线程拒绝策略
-
AbortPolicy(默认策略)直接抛出RejectedExecutionException -
CallerRunsPolicy:由提交任务的线程直接执行这个任务(同步执行 -
DiscardPolicy(直接丢弃)
-
-
任务持久化
- 设计一张任务表将任务存储到 MySQL 数据库中。
- Redis 缓存任务
- 将任务提交到消息队列中
-
线程池中线程异常后,销毁还是复用
- 通过
execute()提交的任务:异常会导致当前工作线程结束,线程池再按配置新建一个线程补上 - 通过
submit()提交的任务:异常被封装进Future,线程本身不会挂,后续还会继续被复用。
- 通过
-
future类的作用
-
// V 代表了Future执行的任务返回值的类型 public interface Future<V> { // 取消任务执行 // 成功取消返回 true,否则返回 false boolean cancel(boolean mayInterruptIfRunning); // 判断任务是否被取消 boolean isCancelled(); // 判断任务是否已经执行完成 boolean isDone(); // 获取任务执行结果 V get() throws InterruptedException, ExecutionException; // 指定时间内没有返回计算结果就抛出 TimeOutException 异常 V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutExceptio }
-
Runnable:要做的“活”,无返回值、不能抛受检异常
-
Runnable task = () -> { System.out.println("do something"); }; new Thread(task).start();
-
Callable:带结果的“活”,有返回值、可以抛受检异常
-
future:任务的“回执 / 小票”,代表异步结果
-
FutureTask不光实现了Future接口,还实现了Runnable接口,因此可以作为任务直接被线程执行
-
-
CompletableFuture -
AQS
-
JUC里各种锁和同步器的“底层框架”
- 一个
state状态 - 管一条线程等待队列(CLH双向链表)
- 帮你实现“排队获取锁 / 释放锁 / 唤醒下一个线程”的通用逻辑
- 一个
-
ReentrantLock、CountDownLatch、Semaphore、ReentrantReadWriteLock、FutureTask 等,全都是基于 AQS 实现的。
-
基于AQS常见的同步器
-
reentrantlock
- 独占模式
- state表示重入次数
- 公平锁/非公平锁逻辑都是在
tryAcquire中控制的
-
ReentrantReadWriteLock
-
读锁:共享模式;
写锁:独占模式;
state的高 16 位可以用来计读锁次数,低 16 位用来计写锁重入次数(典型“打包到一个 int 里”的技巧)。
-
-
countdownlatch
- 共享模式;
state= 计数器;await()调用acquireShared,当state == 0时才能通过;countDown()调用releaseShared,state--到 0 时唤醒所有等待线程。
-
Semaphore
- 共享模式;
state= 当前剩余许可数量;acquire()试图减 state,减成功则获得许可,失败则排队;release()加 state,唤醒等待线程。
-
-
-
CLH 锁(Craig–Landin–Hagersten 锁)是一种基于队列的自旋锁,每个线程在自己的“前驱节点”上本地自旋,实现 FIFO 公平、可扩展的锁。
- 原因:所有线程都在同一个变量上自旋,大量cache失效,扩展性差,每个线程只在本地变量上自旋,减少总线争用,
- FIFO
-
创建线程池的方式
ThreadPoolExcutor构造函数直接创建Executors工具类创建
-
常见的并发容器
ConcurrentHashMap: 线程安全的HashMapCopyOnWriteArrayList: 线程安全的List,在读多写少的场合性能非常好,远远好于VectorConcurrentLinkedQueue: 高效的并发队列,使用链表实现。可以看做一个线程安全的LinkedList,是一个非阻塞队列。BlockingQueue: 这是一个接口,JDK 内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。ArrayBlockingQueue:lockingQueue接口的有界队列实现类,底层采用数组来实现。LinkedBlockinggQueue:底层基于单向链表实现的阻塞队列,可以当做无界队列也可以当做有界队列来使用PriorityBlockinggQueue:
ConcurrentSkipListMap: 跳表的实现。这是一个 Map,使用跳表的数据结构进行快速查找。
-
InputStream
-
// 新建一个 BufferedInputStream 对象 BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("input.txt")); // 读取文件的内容并复制到 String 对象中 String result = new String(bufferedInputStream.readAllBytes()); System.out.println(result);
-
字符流的原因:
-
适配模式与装饰器模式
InputStream in = new FileInputStream("a.txt"); // 具体组件 in = new BufferedInputStream(in); // 加缓冲功能 in = new DataInputStream(in); // 加按基本类型读取的功能 InputStream in = new FileInputStream("a.txt"); Reader reader = new InputStreamReader(in);
- 装饰器模式:
- 装饰类和被装饰类实现的是同一个接口 / 抽象类
- 对客户端是“透明的”。
- 感知地换成(或叠加)多个装饰器
- 适配器模式
- 适配器面向的是客户端期望的接口,被适配者是另一套接口。
- 适配器的目的就是让这两套接口“对得上”
- 对客户端不透明,客户端明确知道自己使用的是
Target接口
- 装饰器模式:
-
-
观察者模式
-
WatchService接口和Watchable接口。WatchService属于观察者,Watchable属于被观察者 -
public interface Path extends Comparable<Path>, Iterable<Path>, Watchable{ } public interface Watchable { WatchKey register(WatchService watcher, WatchEvent.Kind<?>[] events, WatchEvent.Modifier... modifiers) throws IOException; } // 创建 WatchService 对象 WatchService watchService = FileSystems.getDefault().newWatchService(); // 初始化一个被监控文件夹的 Path 类: Path path = Paths.get("workingDirectory"); // 将这个 path 对象注册到 WatchService(监控服务) 中去 WatchKey watchKey = path.register( watchService, StandardWatchEventKinds...); WatchKey register(WatchService watcher, WatchEvent.Kind<?>... events) throws IOException;
-
-
JavaIO模式详解
- BIO是同步阻塞 IO 模型 。
- NIO 是 I/O 多路复用模型
- I/O 多路复用模型
- AIO 是异步 IO 模型
-
Java的线程私有与公有
-
程序计数器
-
虚拟机栈
-
-
局部变量表
- 操作数栈
-
动态链接
- 方法返回地址
- 本地方法栈
- 堆
- 方法区(JVM运行时数据区域)
- 类的元数据
- 方法的字节码
- 运行时常量池
- 静态变量+字符常量池都是在堆上
-
-
方法区和永久代
- 接口:方法区
- 类:原空间&永久代
- 元空间优势
- 不再受Java堆大小限制
- 默认按需自动扩展
-
Java对象的创建
- 类加载检查:new指令,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程
- 分配内存“:为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。分配方式有 “指针碰撞” 和 “空闲列表” 两种,选择哪种分配方式由 Java 堆是否规整决定,而 Java 堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定。
- 指针碰撞:堆内存规整(即没有内存碎片)的情况下。
- 空闲列表:堆内存不规整的情况下。
- 内存分配并发问题
- CAS+失败重试
- TLAB
- 初始化零值:保证了对象的实例字段在 Java 代码中可以不赋初始值就直接使用
- 设置对象头:虚拟机要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息。
- **执行init方法:**行 new 指令之后会接着执行
<init>方法,把对象按照程序员的意愿进行初始化,
-
对象内存布局
- 对象头:
- 标记字段
- hashcode
- gcn年龄分层
- 锁状态标志
- 线程持有的锁
- 偏向线程ID
- 偏向时间戳
- 类型指针:虚拟机通过这个指针来确定这个对象是哪个类的实例
- 标记字段
- 实例数据:
- 对齐填充:
- 对象头:
-
JVM垃圾回收
-
死亡对象判断方法
- 引用计数法
- 可达性分析算法
-
引用类型
-
强引用(StrongReference):强引用实际上就是程序代码中普遍存在的引用赋值
-
软引用(SoftReference):如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。
-
// 软引用 String str = new String("abc"); SoftReference<String> softReference = new SoftReference<String>(str);
-
-
弱引用(WeakReference):一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
-
String str = new String("abc");
WeakReference weakReference = new WeakReference<>(str); str = null; //str变成软引用,可以被收集
-
-
虚引用(PhantomReference):任何引用一样,在任何时候都可能被垃圾回收
-
String str = new String("abc"); ReferenceQueue queue = new ReferenceQueue(); // 创建虚引用,要求必须与一个引用队列关联 PhantomReference pr = new PhantomReference(str, queue);
-
-
-
废弃常量与废弃类
- 废弃常量:如果当前没有任何 String 对象引用该字符串常量的话,就说明常量 "abc" 就是废弃常量
- 废弃类
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的
ClassLoader已经被回收。
- 该类对应的
java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
-
垃圾收集算法
-
标记-清除算法
-
复制算法
-
标记-整理算法
-
-
CMS收集器是HotSpot虚拟机第一款真正意义上的并发器
-
初始标记: 短暂停顿,标记直接与 root 相连的对象(根对象);
并发标记: 同时开启 GC 和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以 GC 线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
重新标记: 重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
并发清除: 开启用户线程,同时 GC 线程开始对未标记的区域做清扫。
-
-
-
并行与并发:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
-
分代收集:虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但是还是保留了分代的概念。
-
空间整合:与 CMS 的“标记-清除”算法不同,G1 从整体来看是基于“标记-整理”算法实现的收集器;从局部上来看是基于“标记-复制”算法实现的。
-
可预测的停顿:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在垃圾收集上的时间不得超过 N 毫秒。
-
G1 收集器的运作
-
初始标记: 短暂停顿(Stop-The-World,STW),标记从 GC Roots 可直接引用的对象,即标记所有直接可达的活跃对象
并发标记:与应用并发运行,标记所有可达对象。 这一阶段可能持续较长时间,取决于堆的大小和对象的数量。
最终标记: 短暂停顿(STW),处理并发标记阶段结束后残留的少量未处理的引用变更。
筛选回收:根据标记结果,选择回收价值高的区域,复制存活对象到新区域,回收旧区域内存。这一阶段包含一个或多个停顿(STW),具体取决于回收的复杂度。
-
-
-
类文件结构详解
- 魔数
class文件版本号:次版本号+主版本号- 常量池:
- 访问标志
- 字段表集合
- 方法表集合
-
类加载过程
- 加载
- 通过全类名获取定义此类的二进制字节流。
- 将字节流所代表的静态存储结构转换为方法区的运行时数据结构。
- 在内存中生成一个代表该类的
Class对象,作为方法区这些数据的访问入口
- 验证
- 文件格式验证(Class 文件格式检查)
- 元数据验证(字节码语义检查)
- 字节码验证(程序语义检查)
- 符号引用验证(类的正确性检查)
- 准备
- 正式为类变量分配内存并设置类变量初始值的阶段
- 解析
- 是虚拟机将常量池内的符号引用替换为直接引用的过程
- 初始化
- 加载
-
类加载器
- 类加载器是一个负责加载类的对象,用于实现类加载过程中的加载这一步。
- 每个 Java 类都有一个引用指向加载它的
ClassLoader。 - 数组类不是通过
ClassLoader创建的(数组类没有对应的二进制字节流),是由 JVM 直接生成的。 - 懒汉模式and类加载器来说,相同二进制名称的类只会被加载一次。
- 三个重要的
ClassLoaderBootstrapClassLoader(启动类加载器):最顶层的加载类,由 C++实现,通常表示为 null,并且没有父级,主要用来加载 JDK 内部的核心类库(%JAVA_HOME%/lib目录下的rt.jar、resources.jar、charsets.jar等 jar 包和类)以及被-Xbootclasspath参数指定的路径下的所有类ExtensionClassLoader(扩展类加载器):主要负责加载%JRE_HOME%/lib/ext目录下的 jar 包和类以及被java.ext.dirs系统变量所指定的路径下的所有类。
AppClassLoader(应用程序类加载器):面向我们用户的加载器,负责加载当前应用 classpath 下的所有 jar 包和类
-
双亲委派制度
- 先看自己有没有加载过 → 让父加载器去加载 → 父亲也不行,自己再上
- 保证核心类的安全性
- 保证类的唯一性和一致性
- 上层是基础,下层是扩展
- 打破双亲委派
- 容器自带框架
- 热部署/插件机制
-
@Component与@bean
-
@Component:标在“类”上,让 Spring 在组件扫描时自动发现并注册这个类为一个 Bean。
-
@Bean:标在“方法”上,让 Spring 调用这个方法的返回值作为 Bean 注册到容器中,通常配合
@Configuration使用,属于显式声明 Bean。@Component public class MyService { // ... } @SpringBootApplication // 内部包含@ComponentScan public class Application { ... } @Configuration public class AppConfig { @Bean public DataSource dataSource() { // 可以写任意初始化逻辑 DruidDataSource ds = new DruidDataSource(); ds.setUrl("jdbc:mysql://..."); ds.setUsername("root"); ds.setPassword("123456"); return ds; } @Bean public MyService myService(DataSource dataSource) { return new MyService(dataSource); } }
@Component:- 类上
- :靠扫描包路径,把标注的类反射实例化;
- 你能控制源码、可以直接在类上加注解
@bean:- 方法上,方法返回值是 Bean
- Spring 调用配置类的方法,拿方法返回值注册
- 不能修改源码(第三方类)
- 构造过程复杂(需要读取配置文件、根据条件选择实现等);
- 想用“工厂方法”风格创建 Bean。
-
-
@Autowired和@Resource使用的比较多一些@Autowired- Spring 自有注解
- 默认按类型注入(byType)
- 支持的位置:构造器、字段、setter 方法、普通方法参数
@Qualifier指定具体 Bean 名称
@Resource- 默认按名称注入(byName),找不到再按类型
- 规范和实现主要面向字段 / setter,构造器注入并不常见,且语义不直观。
-
bean的作用域
- singleton: IoC 容器中只有唯一的 bean 实例。Spring 中的 bean 默认都是单例的,是对单例设计模式的应用。
- prototype
- request:一次 HTTP 请求都会产生一个新的 bean(请求 bean)
- session:每一次来自新 session 的 HTTP 请求都会产生一个新的 bean
- application/global-session:每个 Web 应用在启动时创建一个 Bean(应用 Bean),该 bean 仅在当前应用启动时间内有效。
- websocket:每一次 WebSocket 会话产生一个新的 bean。
-
为啥
@bean是无状态的?- singleton:单例模式,有状态的线程不安全
- 单例 Bean 不存放与具体请求/线程相关的可变状态,只做“无状态服务”。
- 纯函数类(只依赖入参和注入的依赖);
- 典型的有状态的bean
- 缓存组件 / 连接池 / 线程池
- 特定 scope 的 Bean
- 确有必要封装的状态机、上下文对象
-
Aware接口Aware接口能让 Bean 能拿到 Spring 容器资源- 都是
XxxAware,里面只有一个setXxx(...)方法 - 当 Spring 创建好 Bean 实例之后,会在合适的时间调用这些
setXxx方法,把对应的对象塞进去 - 目的:让 Bean 拿到“容器内部的上下文对象
- 属于“回调式注入”,而不是普通业务依赖注入
-
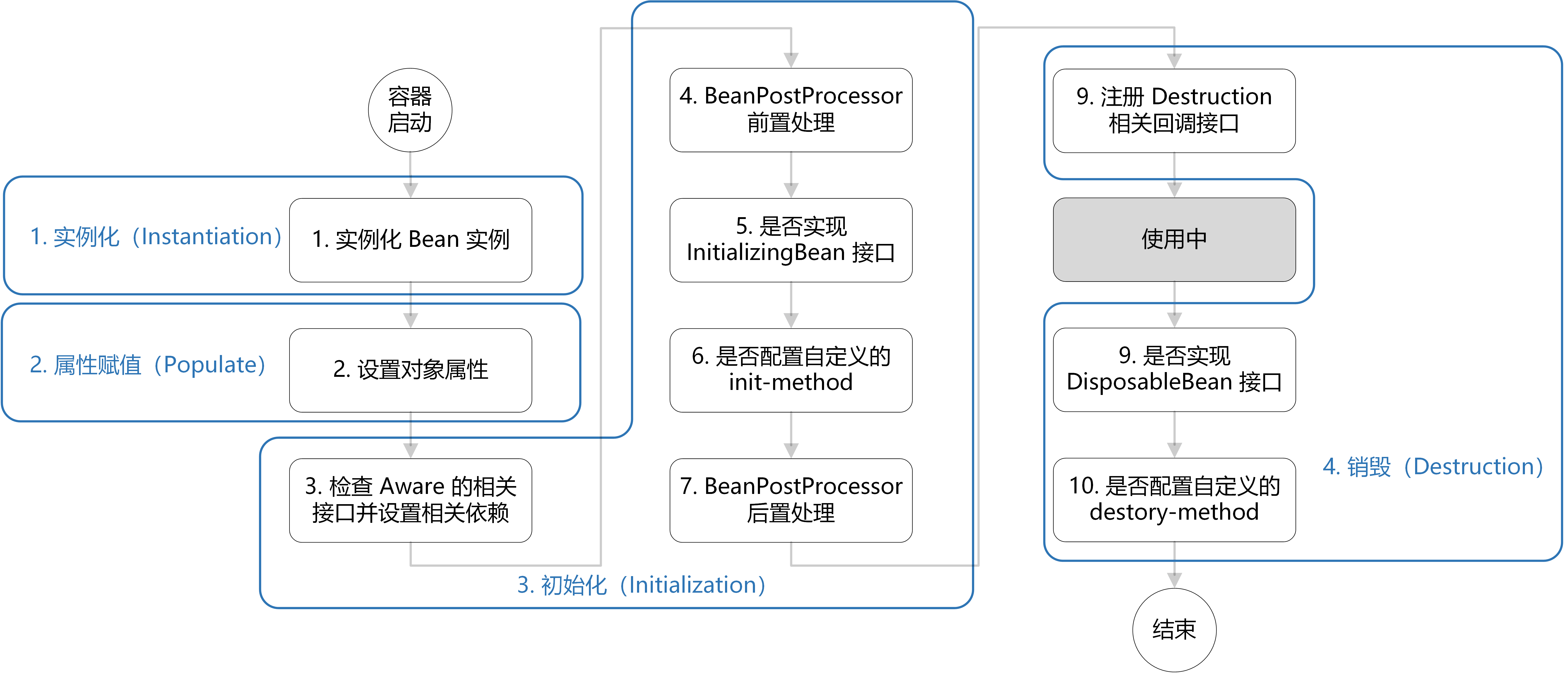
bean的生命周期
- 创建 Bean 的实例:Bean 容器首先会找到配置文件中的 Bean 定义,然后使用 Java 反射 API 来创建 Bean 的实例。
- Bean 属性赋值/填充:为 Bean 设置相关属性和依赖,例如
@Autowired等注解注入的对象、@Value注入的值、setter方法或构造函数注入依赖和值、@Resource注入的各种资源 - Bean 初始化:
- 如果 Bean 实现了
BeanNameAware接口,调用setBeanName()方法,传入 Bean 的名字。 - 如果 Bean 实现了
BeanFactoryAware接口,调用setBeanFactory()方法,传入BeanFactory对象的实例。 - 与上面的类似,如果实现了其他
*.Aware接口,就调用相应的方法。 - 如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessBeforeInitialization()方法 - 如果 Bean 实现了
InitializingBean接口,执行afterPropertiesSet()方法 - 如果 Bean 在配置文件中的定义包含
init-method属性,执行指定的方法。 - 如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessAfterInitialization()方法。
- 如果 Bean 实现了
- 销毁 Bean:销毁并不是说要立马把 Bean 给销毁掉,而是把 Bean 的销毁方法先记录下来,将来需要销毁 Bean 或者销毁容器的时候,就调用这些方法去释放 Bean 所持有的资源。
-
BeanPostProcessor 和 BeanFactoryPostProcessor 的区别
BeanFactoryPostProcessor- 处理的是 BeanDefinition 级别(“配方”);
- 发生在所有 Bean 实例化之前
- 典型作用:修改 BeanDefinition 的属性,比如占位符替换
BeanPostProcessor:- 处理的是 Bean 实例级别(“成品对象”);
- 发生在 Bean 实例化之后(并完成依赖注入);
- 典型作用:对象“二次加工”、代理包装、注解解释
-
属性赋值与初始化
-
属性赋值:对象的“成员变量”值是对的,但它还只是一个**“值都塞进去了的裸对象”**,Spring 还没给你那几个“回调机会”。
-
初始化:在 “属性全部注入完毕”之后,给你一个机会去做初始化逻辑,让 Bean 进入“可以正常工作”的状态。
-
校验依赖是否齐全、配置是否合理
-
根据注入的属性创建额外资源(连接池、线程池、缓存、内部状态等)
-
注册监听器、启动后台任务
-
打开与外部系统的连接(某些情况下会懒加载)
-
-
-
springMVC的核心组件
DispatcherServlet:核心的中央处理器,负责接收请求、分发,并给予客户端响应。HandlerMapping:处理器映射器,根据 URL 去匹配查找能处理的Handler,并会将请求涉及到的拦截器和Handler一起封装。HandlerAdapter:处理器适配器,根据HandlerMapping找到的Handler,适配执行对应的Handler;Handler:请求处理器,处理实际请求的处理器。ViewResolver:视图解析器,根据Handler返回的逻辑视图 / 视图,解析并渲染真正的视图,并传递给DispatcherServlet响应客户端
-
客户端(浏览器)发送请求,
DispatcherServlet拦截请求。 -
DispatcherServlet根据请求信息调用HandlerMapping。HandlerMapping根据 URL 去匹配查找能处理的Handler(也就是我们平常说的Controller控制器) ,并会将请求涉及到的拦截器和Handler一起封装。 -
DispatcherServlet调用HandlerAdapter适配器执行Handler。Handler完成对用户请求的处理后,会返回一个ModelAndView对象给DispatcherServlet,ModelAndView顾名思义,包含了数据模型以及相应的视图的信息。Model是返回的数据对象,View是个逻辑上的View。ViewResolver会根据逻辑View查找实际的View。DispaterServlet把返回的Model传给View(视图渲染)。- 把
View返回给请求者(浏览器)
- 前后端分离时,后端通常不再返回具体的视图,而是返回纯数据(通常是 JSON 格式),由前端负责渲染和展示。
View的部分在前后端分离的场景下往往不需要设置,Spring MVC 的控制器方法只需要返回数据,不再返回ModelAndView,而是直接返回数据,Spring 会自动将其转换为 JSON 格式。相应的,ViewResolver也将不再被使用
- 使用
@RestController注解代替传统的@Controller注解,这样所有方法默认会返回 JSON 格式的数据,而不是试图解析视图。
-
统一异常处理
-
@ControllerAdvice @ResponseBody public class GlobalExceptionHandler { @ExceptionHandler(BaseException.class) public ResponseEntity<?> handleAppException(BaseException ex, HttpServletRequest request) { //...... } @ExceptionHandler(value = ResourceNotFoundException.class) public ResponseEntity<ErrorReponse> handleResourceNotFoundException(ResourceNotFoundException ex, HttpServletRequest request) { //...... } } @RestControllerAdvice // 或 @ControllerAdvice + 返回 ModelAndView public class GlobalExceptionHandler { @ExceptionHandler(MyBizException.class) public ResponseEntity<String> handleBiz(MyBizException ex) { return ResponseEntity .status(HttpStatus.BAD_REQUEST) .body("业务异常:" + ex.getMessage()); } @ExceptionHandler(Exception.class) public ResponseEntity<String> handleAll(Exception ex) { // 兜底处理,避免异常直接暴露给前端 return ResponseEntity .status(HttpStatus.INTERNAL_SERVER_ERROR) .body("服务异常,请稍后重试"); } }
-

-
handler
- 鼠标点击事件的处理函数叫 **事件处理器(event handler)** - HTTP 请求对应的处理逻辑叫**请求处理器(request handler)**- 某种消息到达后由谁处理,这个谁就是 message handler
-
spring循环依赖问题
- 三级缓存
singletonObjects:一级缓存,存放完全初始化好的单例 Bean。earlySingletonObjects:二级缓存,存放还没完全初始化,但可以被依赖注入使用的“提前曝光”的 Bean 实例。singletonFactories:三级缓存,存放一个个ObjectFactory,用于创建“早期 Bean 引用”(尤其是 AOP 代理的场景)
@lazy解决循环依赖问题- Spring 不会立即创建
B,而是会注入一个B的代理对象。由于此时B仍未被真正初始化,A的初始化可以顺利完成。等
- 三级缓存
-
@Transactional(rollbackFor=Exception.class)
@Transactional注解默认回滚策略是只有在遇到RuntimeException(运行时异常) 或者Error时才会回滚事务- 受检异常是可预期的错误,可以通过业务逻辑来处理。
-
springbootstarters
- 一组“开箱即用的功能套餐依赖” + 配套自动配置,让你一句依赖就启用一整套功能,而不用自己手动列一堆 jar 和配置
- Maven自动配置触发入口
- 依赖聚合
- 自动配置触发入口
- 常见的
starter举例spring-boot-starter-webspring-boot-starter-webfluxspring-boot-starterspring-boot-starter-loggingspring-boot-starter-testspring-boot-starter-redis第三方的
- 典型结构
spring-boot-starter-xxx基本就是一个空壳POMxxx-spring-boot-autoconfigure- 里面放了各种
@Configuration+@ConditionalOnClass+@ConditionalOnMissingBean等; - 并通过:
- Spring Boot 2.x:
META-INF/spring.factories - Spring Boot 3.x:
META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports
- Spring Boot 2.x:
- 里面放了各种
- 引入 Starter → 把 auto-configure 模块拉进来 → Boot 扫描它 → 整个自动装配就运转了
-
介绍一下@springbootApplication注解
- 看作是@Configuration、 @EnableAutoConfiguration、@ComponentScan注解的集合。
@EnableAutoConfiguration:启用 SpringBoot 的自动配置机制@ComponentScan: 扫描被@Component (@Service,@Controller)注解的bean,注解默认会扫 描该类所在的包下所有的类。
@Configuration:允许在上下文中注册额外的bean 或导入其他配置类
- 看作是@Configuration、 @EnableAutoConfiguration、@ComponentScan注解的集合。
-
int i = 1; i = i++; System.out.println(i); // 结果输出1 int count = 0; for(int i = 0;i < 100;i++) { count = count++; } System.out.println("count = "+count); // 结果输出零
```
-
多态:程序中定义的引⽤变量所指向的具体类型和通过该引⽤变量发出的⽅法调⽤在编程时并不确定,⽽是在程序运⾏期间才确定,即⼀个引⽤变量到底会指向哪个类的实例对象,该引⽤变量发出的⽅法调⽤到底是哪个类中实现的⽅法,必须在由程序运⾏期间才能决定。
-
this:指向对象本身的一个指针
- 区分类成员变量和方法参数
- 调用当前类的另外一个构造器
- 把当权对象作为参数传出
-
final修饰不能被继承、重写、不可变**(这里的不可变指的是变量的引用不可变,不是引用指向的内容的不可变。)**
-
join():如果一个线程 A 执行了 thread.join()语句,其含义是:当前线程 A 等待 thread 线程终止之后才
从 thread.join()返回。
-
blockedVSwaiting
- BLOCKED = 因为抢不到锁而卡住
WAITING/TIMED_WAITING:专指“调用 wait/join/park/sleep 之类 API 进入的等待”
-
Threadlocal原理
- Thread 类有一个类型为 ThreadLocal.ThreadLocalMap 的实例变量 threadLocals,每个线程都有一个属于自己的 ThreadLocalMap。
- ThreadLocalMap 内部维护着 Entry 数组,每个 Entry 代表一个完整的对象,key 是 ThreadLocal 的弱引用,value 是 ThreadLocal 的泛型值。
- 每个线程在往 ThreadLocal 里设置值的时候,都是往自己的 ThreadLocalMap 里存,读也是以某个 ThreadLocal 作为引用,在自己的 map 里找对应的 key,从而实现了线程隔离。
- ThreadLocal 本身不存储值,它只是作为一个 key 来让线程往 ThreadLocalMap 里存取值
-
as-if-serial 保证的是单线程语义
-
synchronized的性能- 偏向锁:在无竞争的情况下,只是在 Mark Word 里存储当前线程指针,CAS 操作都不做。
- 轻量级锁:在没有多线程竞争时,相对重量级锁,减少操作系统互斥量带来的性能消耗。但是,如果存在锁竞争,除了互斥量本身开销,还额外有 CAS 操作的开销。
- 自旋锁:减少不必要的 CPU 上下文切换。在轻量级锁升级为重量级锁时,就使用了自旋加锁的方式
- 锁粗化:将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁。
- 锁消除:虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除
![synchronized 锁升级过程-来源参考[14]](https://cdn.jsdelivr.net/gh/thinkingme/thinkingme.github.io@master/images/sidebar/sanfene/javathread-37.png)
- 保证
i++结果正确- 使用原子类
- 使用JUC包中的锁
- 使用synchronized
- 原子类
- 核心原理:使用CAS
CountDownLatchawait()等待latch降为0;boolean await(long timeout, TimeUnit unit):等待 latch 降为 0,但是可以设置超时时间。比如有玩家超时未确认countDown():latch 数量减 1;
- `getCount()`:获取当前的 latch 数量。
CountDownLatch latch = new CountDownLatch(3);
// worker 线程
new Thread(() -> {
// do work...
latch.countDown(); // 完成一个任务
}).start();
// 主线程
latch.await(); // 等待所有countDown完成
// 继续执行-
CyclicBarrier-
一组线程在多个阶段反复相互等待,形成可重复使用的同步屏障。
CountDownLatch latch = new CountDownLatch(3); // worker 线程 new Thread(() -> { // do work... latch.countDown(); // 完成一个任务 }).start(); // 主线程 latch.await(); // 等待所有countDown完成 // 继续执行
-
-
CyclicBarrierVSCountDownLatchCyclicBarrier- CyclicBarrier 是可重用的,其中的线程会等待所有的线程完成任务。届时,屏障将被拆除,并可以选择性地做一些特定的动作。
- CyclicBarrier 面向的是线程数
- 在使用 CyclicBarrier 时,你必须在构造中指定参与协作的线程数,这些线程必须调用 await()方法
- CyclicBarrier 可以在所有的线程释放后重新使用
- 在 CyclicBarrier 中,如果某个线程遇到了中断、超时等问题时,则处于 await 的线程都会出现问题
CountDownLatch- CountDownLatch 是一次性的,不同的线程在同一个计数器上工作,直到计数器为 0.
- CountDownLatch 面向的是任务数
- 使用 CountDownLatch 时,则必须要指定任务数,至于这些任务由哪些线程完成无关紧要
- CountDownLatch 在计数器为 0 时不能再使用
- 在 CountDownLatch 中,如果某个线程出现问题,其他线程不受影响
-
-
acquire():获取 1 个许可,没有就阻塞。 -
acquire(int permits):获取多个许可。 -
tryAcquire():尝试获取许可,获取不到立刻返回false,不阻塞。 -
release()/release(int permits):归还许可,唤醒等待线程。-
import java.util.concurrent.Semaphore; public class SemaphoreExample { // 最多允许3个线程同时执行任务 private static final Semaphore semaphore = new Semaphore(3); public static void main(String[] args) { // 模拟10个并发请求 for (int i = 1; i <= 10; i++) { int taskId = i; new Thread(() -> doWork(taskId)).start(); } } private static void doWork(int taskId) { try { // 尝试获取许可 semaphore.acquire(); System.out.println("任务 " + taskId + " 获得许可,开始执行"); // 模拟业务处理 Thread.sleep(1000); System.out.println("任务 " + taskId + " 执行完成,释放许可"); } catch (InterruptedException e) { e.printStackTrace(); } finally { // 一定要在 finally 里释放许可 semaphore.release(); } } }
-
-
-
Exchanger<V> exchanger = new Exchanger<>(); V exchange(V x) // 一直等,直到有另一个线程来交换 V exchange(V x, long timeout, TimeUnit unit) // 限时等待 import java.util.concurrent.Exchanger; public class ExchangerDemo { public static void main(String[] args) { Exchanger<String> exchanger = new Exchanger<>(); Thread t1 = new Thread(() -> { String data = "来自线程1的数据"; System.out.println("T1 交换前:" + data); try { // 把自己的 data 交出去,换回对方的 data data = exchanger.exchange(data); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("T1 交换后:" + data); }); Thread t2 = new Thread(() -> { String data = "来自线程2的数据"; System.out.println("T2 交换前:" + data); try { data = exchanger.exchange(data); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("T2 交换后:" + data); }); t1.start(); t2.start(); } }
-
-
会,假设 JVM 虚拟机上,每一次 new 对象时,指针就会向右移动一个对象 size 的距离,一个线程正在给 A 对象分配内存,指针还没有来的及修改,另一个为 B 对象分配内存的线程,又引用了这个指针来分配内存,这就发生了抢占
-
采用 CAS 分配重试的方式来保证更新操作的原子性
-
每个线程在 Java 堆中预先分配一小块内存,也就是本地线程分配缓冲(Thread Local Allocation
Buffer,TLAB),要分配内存的线程,先在本地缓冲区中分配,只有本地缓冲区用完了,分配新的缓存区时才需要同步锁定
-
-
内存泄漏
- 静态集合的生命周期和 JVM 一致,所以静态集合引用的对象不能被释放。
- 单例模式
- 变量不合理的作用域
- hash 值发生变化
- ThreadLocal 使用不当
-
-
新生代的垃圾收集主要采用标记-复制算法,因为新生代的存活对象比较少,每次复制少量的存活对象效率比较高。
-
拟机将内存分为一块较大的 Eden 空间和两块较小的 Survivor 空间,每次分配内存只使用 Eden 和其中一块 Survivor。发生垃圾收集时,将 Eden 和 Survivor 中仍然存活的对象一次性复制到另外一块 Survivor 空间上,然后直接清理掉 Eden 和已用过的那块 Survivor 空间。默认 Eden 和 Survivor 的大小比例是 8∶1。
-
-
STW- 为了保证对象引用更新的正确性,必须暂停所有的用户线程,像这样的停顿,虚拟机设计者形象描述为
Stop The World。也简称为 STW。
- 为了保证对象引用更新的正确性,必须暂停所有的用户线程,像这样的停顿,虚拟机设计者形象描述为
-
CMS和G1的对比
cms- 早期主流的低停顿收集器,主要针对老年代。并发标记、并发清除来降低 STW(Stop-The-World)时间。不做常规的整理压缩,容易产生内存碎片。主要存在于 Java 8 时代。
g1- 为取代 CMS 而设计的区域化、压缩式、面向大堆的服务器端 GC自 Java 9 起成为默认 GC,适用于多核 + 大内存服务器。
-
垃圾收集器的选择?
- Serial :如果应用程序有一个很小的内存空间(大约 100 MB)亦或它在没有停顿时间要求的单线程处理器上运行。
- Parallel:如果优先考虑应用程序的峰值性能,并且没有时间要求要求,或者可以接受 1 秒或更长的停顿时间。
- CMS/G1:如果响应时间比吞吐量优先级高,或者垃圾收集暂停必须保持在大约 1 秒以内。
-
逃逸技术
- 栈上分配(Stack Allocation):如果对象被判定为“不逃逸”,编译器可以把它当成局部变量那样放在栈上或寄存器里,而不是放在堆中
- 标量替换(Scalar Replacement):如果一个小对象完全不逃逸,且访问模式很简单,编译器甚至可以不真正创建这个对象,而是把它的字段拆成几个局部变量。
- 锁消除(Lock Elimination):如果编译器发现加锁对象或者锁相关的临界区只在当前线程内可见,不会被别的线程访问,就可以安全地把这个锁去掉
-
fail-fast与fail-safe
- fail-fast
- 在用迭代器遍历一个集合对象时,如果线程 A 遍历过程中,线程 B 对集合对象的内容进行了修改(增加、删除、修改),则会抛出 Concurrent Modification Exception。
- 迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个
modCount变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用 hashNext()/next()遍历下一个元素之前,都会检测 modCount 变量是否为 expectedmodCount 值,是的话就返回遍历;否则抛出异常,终止遍历。
- fail-fast
- 采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历
- fail-fast
-
红黑树
- 是一种自平衡二叉查找树
- 保证查找、插入、删除的时间复杂度都是 O(log n)
- “颜色标记”+局部旋转来维持近似平衡
- 在插入 / 删除时,最多做常数次旋转,而不是像极端不平衡的 BST 那样退化成 O(n)
- 核心性质
- 每个节点要么是红色,要么是黑色
- 根节点是黑色
- 所有叶子节点(一般约定为
null/NIL节点)是黑色 - 红色节点的子节点必须是黑色(也就是:不会出现连续两个红色节点)。
- 从任意节点出发,到其所有叶子节点的每一条路径上,黑色节点的数量相同(黑高一致)
- 任意节点到叶子的最长路径长度 ≤ 最短路径长度的 2 倍
- 所以整棵树的高度 h ≈ O(log n)。
- 树在插入 / 删除后有点“倾斜”,高度也不会比 log₂(n+1) 高太多。这就保证了所有操作的复杂度上界。
- 是一种自平衡二叉查找树
-
hashmap的哈希扰动
-
static final int hash(Object key) { int h; // key的hashCode和key的hashCode右移16位做异或运算 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } // 这么设计是为了降低哈希碰撞的概率 // hash值与数组长度取余得到数组下标 // 为了快速,散列值和数组长度 - 1 做一个 "与&" 操作,位运算比取余 % 运算要快。 bucketIndex = indexFor(hash, table.length); static int indexFor(int h, int length) { return h & (length-1); }
-
-
为什么扰动函数能降低hash碰撞?
- 扰动函数降低的是“映射到同一桶的概率”,而不是让
hashCode()本身不碰撞。 - 扰动函数只影响“hash → index 的分布质量”,不能消除
hashCode()本身的碰撞
- 扰动函数降低的是“映射到同一桶的概率”,而不是让
-
为什么hashmap的容量是2的倍数?
- 下标计算可以用位运算代替取模
- 统一使用低 k 位,便于“理想均匀分布
- 扩容时迁移节点非常简单
-
初始化hashmap,传一个17的值
new hashmap<>?- 传的不是 2 的倍数时,HashMap 会向上寻找
离得最近的2的倍数,所以传入 17,但 HashMap 的实际容量是 32
- 传的不是 2 的倍数时,HashMap 会向上寻找
-
冲突方法
- 链地址法
- 开放地址法
- 再哈希法
- 建立公共溢出区
-
- 偏经验+工程实践 + 一点概率直觉,而不是某个精确数学公式。
- 在默认负载因子和正常 hash 分布下,一个桶里出现 8 个以上元素的概率本来就非常低,如果真出现,说明这个桶发生了严重冲突,这时用红黑树可以把局部查询复杂度从 O(k) 降到 O(log k)。
- 但如果阈值设太小,会让大量正常的小冲突桶也树化,增加内存和维护红黑树的开销,得不偿失。因此选择 8 作为树化的触发点,并且只有在 table 容量至少 64 时才允许树化,这是一种工程上权衡后的设计,而不是纯数学定理
-
hashMap线程不安全
- 多线程下扩容死循环。JDK1.7 中的 HashMap 使用头插法插入元素,在多线程的环境下,扩容的时候有可能导致环形链表的出现,形成死循环。因此,JDK1.8 使用尾插法插入元素,在扩容时会保持链表元素原本的顺序,不会出现环形链表的问题
- 多线程的 put 可能导致元素的丢失。多线程同时执行 put 操作,如果计算出来的索引位置是相同的,那会造成前一个 key 被后一个 key 覆盖,从而导致元素的丢失。此问题在 JDK 1.7 和 JDK 1.8 中都存在。
- put 和 get 并发时,可能导致 get 为 null。线程 1 执行 put 时,因为元素个数超出 threshold 而导致 rehash,线程 2 此时执行 get,有可能导致这个问题。这个问题在 JDK 1.7 和 JDK 1.8 中都存在
-
hashmap
/** * @Author 三分喜 * @Date 2021/11/21 * @Description 自己实现HashMap */ public class ThirdHashMap<K, V> { /** * 节点类 * * @param <K> * @param <V> */ class Node<K, V> { // 键 private K key; // 值 private V value; // 指向下一个节点 private Node<K, V> next; // 构造函数 public Node(K key, V value) { this.key = key; this.value = value; } public Node(K key, V value, Node<K, V> next) { this.key = key; this.value = value; this.next = next; } } // 默认容量 final int DEFAULT_CAPACITY = 16; // 负载因子 final float LOAD_FACTOR = 0.75f; // 实际存储的键值对数量 private int size; // 桶数组 private Node<K, V>[] buckets; // 无参构造,指定默认容量 public ThirdHashMap() { buckets = new Node[DEFAULT_CAPACITY]; size = 0; } // 有参构造,指定初始容量 public ThirdHashMap(int capacity) { buckets = new Node[capacity]; size = 0; } /** * 哈希函数,求索引 * * @param key * @param length * @return */ private int getIndex(K key, int length) { // 获取 hashCode int hashCode = key.hashCode(); // 计算索引 int index = hashCode % length; return Math.abs(index); } /** * put 方法 * * @param key * @param value */ public void put(K key, V value) { // 判断是否需要扩容 if (size >= buckets.length * LOAD_FACTOR) { resize(); } putVal(key, value, buckets); } /** * 真正负责插入的内部方法 * * @param key * @param value * @param table 当前使用的桶数组 */ private void putVal(K key, V value, Node<K, V>[] table) { // 计算索引 int index = getIndex(key, table.length); Node<K, V> node = table[index]; // 如果桶为空,直接插入 if (node == null) { table[index] = new Node<>(key, value); size++; return; } // 桶不为空,遍历链表 while (node != null) { // 判断 key 是否已存在(hashCode + equals) if (node.key.hashCode() == key.hashCode() && (node.key == key || node.key.equals(key))) { node.value = value; return; } node = node.next; } // key 不存在,头插法新增节点 Node<K, V> newNode = new Node<>(key, value, table[index]); table[index] = newNode; size++; } /** * 扩容 */ private void resize() { // 创建一个新数组,容量为原来的 2 倍 Node<K, V>[] newBuckets = new Node[buckets.length * 2]; // 重新散列 rehash(newBuckets); buckets = newBuckets; } /** * 重新散列 * * @param newBuckets 新的桶数组 */ private void rehash(Node<K, V>[] newBuckets) { // 遍历旧数组 for (int i = 0; i < buckets.length; i++) { if (buckets[i] == null) { continue; } Node<K, V> node = buckets[i]; // 遍历链表 while (node != null) { // 重新计算索引并插入到新数组中 putVal(node.key, node.value, newBuckets); node = node.next; } } } /** * get 方法,获取元素 * * @param key * @return */ public V get(K key) { // 计算索引 int index = getIndex(key, buckets.length); if (buckets[index] == null) { return null; } Node<K, V> node = buckets[index]; // 遍历链表 while (node != null) { if (node.key.hashCode() == key.hashCode() && (node.key == key || node.key.equals(key))) { return node.value; } node = node.next; } return null; } /** * 返回 HashMap 大小 * * @return */ public int size() { return size; } }
-
concurrenthashmap
- 单 table + CAS + 链表/红黑树
-
linkedhashmap怎么实现有序的?
- LinkedHashMap 之所以“有序”,是因为在 HashMap 的基础上,每个节点多了 before/after 指针,并用 head/tail 维护了一条串联所有节点的双向链表。构造时若
accessOrder=false,插入时在尾部链接形成“插入顺序”;若accessOrder=true,每次访问还会把节点移动到尾部形成“访问顺序”。所有迭代器都沿着这条链遍历,因此表现为有序。
- LinkedHashMap 之所以“有序”,是因为在 HashMap 的基础上,每个节点多了 before/after 指针,并用 head/tail 维护了一条串联所有节点的双向链表。构造时若
-
Spring 是一个轻量级、非入侵式的控制反转 (IoC) 和面向切面 (AOP) 的框架。
-
spring注解
-
@RequestBody:把 请求体中的内容(一般是 JSON、XML、表单等)反序列化成 Java 对象 -
@PostMapping("/users") public User createUser(@RequestBody UserCreateDTO dto) { // 请求体:{"name":"Tom","age":18} // dto 会自动被填充 ... }
-
@PathVariable -
@GetMapping("/users/{id}") public User getUser(@PathVariable("id") Long userId) { // 访问 /users/10 时,userId = 10 ... }
-
import org.springframework.web.bind.annotation.*; @RestController @RequestMapping("/demo") public class DemoController { @GetMapping("/query") public String query( @RequestParam("name") String name, // /demo/query?name=Tom @RequestParam(value = "age", required = false, defaultValue = "18") int age ) { return name + ":" + age; } @GetMapping("/path/{id}") public String path(@PathVariable("id") Long id) { // /demo/path/10 return "id=" + id; } @PostMapping("/body") public String body(@RequestBody UserDto dto) { // JSON 请求体 -> 对象 return dto.getName(); } @GetMapping("/header") public String header(@RequestHeader("User-Agent") String ua) { return "UA=" + ua; } @GetMapping("/cookie") public String cookie(@CookieValue(value = "SESSION", required = false) String sessionId) { return "SESSION=" + sessionId; } } class UserDto { private String name; // getter/setter 省略 }
-
import org.springframework.context.annotation.Configuration; import org.springframework.transaction.annotation.EnableTransactionManagement; import org.springframework.stereotype.Service; import org.springframework.transaction.annotation.Transactional; @Configuration @EnableTransactionManagement // 开启注解事务 public class TxConfig {} @Service public class AccountService { @Transactional // 方法在事务中执行 public void transfer(Long fromId, Long toId, int amount) { // 扣款 + 加款,发生运行时异常时回滚 } }
-
import org.springframework.context.annotation.Scope; import org.springframework.stereotype.Component; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; @Component @Scope("prototype") // 每次注入创建一个新实例 public class TempBean { @PostConstruct // Bean 初始化后调用 public void init() { System.out.println("TempBean init"); } @PreDestroy // 容器销毁前调用(单例 Bean 有效) public void destroy() { System.out.println("TempBean destroy"); } }
-
import org.springframework.context.annotation.*; @Configuration // 声明配置类 @ComponentScan("com.example.app") // 指定扫描包 @PropertySource("classpath:app.properties") // 额外加载配置文件 @Import(OtherConfig.class) // 导入其他配置类 public class AppConfig { @Bean // 注册一个 Bean 到容器 public String appName() { return "MyApp"; } } @Configuration class OtherConfig { @Bean public Integer version() { return 1; } }
-
-
spring中的
xxxxTemplate- 封装“固定流程+资源管理+处理异常”的工具类
- 模板方法模式+外观模式
- 获取/释放资源(连接、HTTP 客户端、通道等)
- 统一异常处理、转换成 Spring 自己的异常体系
- 底层细节(比如序列化、编码、线程安全)
@Repository
public class UserDao {
@Autowired
private JdbcTemplate jdbcTemplate;
public User findById(Long id) {
String sql = "SELECT id, name FROM user WHERE id = ?";
return jdbcTemplate.queryForObject(
sql,
new Object[]{id},
// 映射一行记录 -> User 对象(你只写这块)
(rs, rowNum) -> new User(rs.getLong("id"), rs.getString("name"))
);
}
}
@Service
public class RemoteService {
@Autowired
private RestTemplate restTemplate;
public UserDTO getUser(Long id) {
String url = "http://user-service/users/{id}";
return restTemplate.getForObject(url, UserDTO.class, id);
}
}
@Service
public class CacheService {
@Autowired
private StringRedisTemplate stringRedisTemplate;
public void saveToken(String userId, String token) {
stringRedisTemplate.opsForValue().set("token:" + userId, token);
}
public String getToken(String userId) {
return stringRedisTemplate.opsForValue().get("token:" + userId);
}
}
@Service
public class KafkaProducerService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void send(String topic, String msg) {
kafkaTemplate.send(topic, msg);
}
}-
spring中的实现机制
-
启动:加载 BeanDefinition
- 启动类上
@SpringBootApplication:包含@ComponentScan,开始扫描指定包 - 为每个类创建一个 BeanDefinition(描述这个 Bean 如何创建、作用域、依赖等的“元数据”
- 启动类上
-
Bean 的创建生命周期(单例)
- 实例化:通过构造方法反射创建对象实例
- 属性填充
- 根据 BeanDefinition,把需要注入的依赖找出来;
- 交给类似
AutowiredAnnotationBeanPostProcessor这种处理器; - 它通过反射给
@Autowired字段/构造方法/Setter 赋值。
- 调用各种 PostProcessor
BeanFactoryPostProcessor:在 Bean 创建前调整 BeanDefinition(例如解析@Configuration、@Bean等);BeanPostProcessor:在 Bean 创建前后做增强(例如创建 AOP 代理)
- 初始化回调
- 调用
InitializingBean.afterPropertiesSet()或@PostConstruct标注的方法
- 调用
- 放入单例缓存
- 放入
singletonObjects这样的 Map 中,供后续getBean()直接返回。
- 放入
-
@Autowired是怎样工作的AutowiredAnnotationBeanPostProcessor@Autowired不是“魔法”,就是 一个特殊的 BeanPostProcessor 在创建 Bean 时扫描注解并用反射赋值。
-
AOP 实现:基于代理的“方法拦截
-
springMvC处理流程
- 浏览器访问
/users/1。 DispatcherServlet拦截请求(在 web.xml / Spring Boot 自动配置中注册为前端控制器)- 调用
HandlerMapping:根据 URL 和 HTTP 方法找到对应的 HandlerMethod - 调用对应的
HandlerAdapter- 通过一系列
HandlerMethodArgumentResolver,把@RequestParam、@PathVariable、@RequestBody等注解的参数解析成方法参数值; - 反射调用 Controller 方法
- 得到返回值(对象、字符串、ModelAndView 等
- 通过一系列
- 返回值处理:
- 如果是对象且有
@ResponseBody或@RestController,交给HttpMessageConverter序列化为 JSON 等写入响应体; - 如果返回字符串视图名,交给
ViewResolver找到对应视图(JSP/Thymeleaf 等)渲染
- 如果是对象且有
- beans.properties
- BeanDefinition.java
- ResourceLoader.java
- BeanRegister.java
- BeanFactory.java:创建了 bean 注册器,完成了资源的加载。
userDao:cn.fighter3.bean.UserDao public class BeanDefinition { private String beanName; private Class beanClass; //省略getter、setter } public class ResourceLoader { public static Map<String, BeanDefinition> getResource() { Map<String, BeanDefinition> beanDefinitionMap = new HashMap<>(16); Properties properties = new Properties(); try { InputStream inputStream = ResourceLoader.class.getResourceAsStream("/beans.properties"); properties.load(inputStream); Iterator<String> it = properties.stringPropertyNames().iterator(); while (it.hasNext()) { String key = it.next(); String className = properties.getProperty(key); BeanDefinition beanDefinition = new BeanDefinition(); beanDefinition.setBeanName(key); Class clazz = Class.forName(className); beanDefinition.setBeanClass(clazz); beanDefinitionMap.put(key, beanDefinition); } inputStream.close(); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); } return beanDefinitionMap; } } public class BeanRegister { //单例Bean缓存 private Map<String, Object> singletonMap = new HashMap<>(32); /** * 获取单例Bean * * @param beanName bean名称 * @return */ public Object getSingletonBean(String beanName) { return singletonMap.get(beanName); } /** * 注册单例bean * * @param beanName * @param bean */ public void registerSingletonBean(String beanName, Object bean) { if (singletonMap.containsKey(beanName)) { return; } singletonMap.put(beanName, bean); } } public class BeanFactory { private Map<String, BeanDefinition> beanDefinitionMap = new HashMap<>(); private BeanRegister beanRegister; public BeanFactory() { //创建bean注册器 beanRegister = new BeanRegister(); //加载资源 this.beanDefinitionMap = new ResourceLoader().getResource(); } /** * 获取bean * * @param beanName bean名称 * @return */ public Object getBean(String beanName) { //从bean缓存中取 Object bean = beanRegister.getSingletonBean(beanName); if (bean != null) { return bean; } //根据bean定义,创建bean return createBean(beanDefinitionMap.get(beanName)); } /** * 创建Bean * * @param beanDefinition bean定义 * @return */ private Object createBean(BeanDefinition beanDefinition) { try { Object bean = beanDefinition.getBeanClass().newInstance(); //缓存bean beanRegister.registerSingletonBean(beanDefinition.getBeanName(), bean); return bean; } catch (InstantiationException | IllegalAccessException e) { e.printStackTrace(); } return null; } }
- 浏览器访问
-
-
beanfactory和applicationcontext
- beanfactory
- 默认是 懒加载:第一次
getBean()时才创建该 Bean。 - 很“省钱”,但很多 BeanPostProcessor 只有在真正创建 Bean 时才发挥作用。
- 默认是 懒加载:第一次
- applicationcontext
- 默认在
refresh()时就会把所有单例 Bean 提前创建好(除非显式标记 lazy-init) - 启动稍慢一点,但运行时性能更稳定,可以提前发现配置/依赖问题
- 默认在
- beanfactory
-
Spring 容器启动阶段会干什么吗?
-
准备容器与运行环境
- 创建
ApplicationContext实例(例如AnnotationConfigApplicationContext、SpringApplication内部创建的上下文 - 准备
Environment- 加载系统属性、环境变量;
- 组合
application.properties/application.yml等配置文件为PropertySource
- 准备资源加载器
ResourceLoader等,用来后续读配置文件、类路径资源。
- 创建
-
解析配置 & 扫描组件,生成 BeanDefinition
- 解析启动类上的注解(Spring Boot 的
@SpringBootApplication)和配置类上的: - 做组件扫描(Component Scan):
- 找到所有
@Component、@Service、@Repository、@Controller、@RestController等注解的类; - 为每个类生成一个
BeanDefinition,
- 找到所有
- 解析启动类上的注解(Spring Boot 的
-
执行 BeanFactoryPostProcessor:修改 Bean 定义
ConfigurationClassPostProcessorPropertySourcesPlaceholderConfigurer- 这一阶段实际上是给你一个“修改 Bean 配方”的机会,很多框架/Starter 利用这里干活。
-
注册 BeanPostProcessor:为后面的 Bean 创建做准备
AutowiredAnnotationBeanPostProcessor:处理@Autowired/@Value/@InjectCommonAnnotationBeanPostProcessor:处理@PostConstruct/@PreDestroy。- AOP 相关的
AnnotationAwareAspectJAutoProxyCreator: - 这些处理器不会控制“某个具体 Bean 何时创建”,但会在“创建 Bean 的前后”有机会插手做增强
- 把“钩子插件”全部装上,后面每个 Bean 过来的时候,这些插件都能帮他做事情(依赖注入、AOP 代理等)
-
初始化一些基础设施 Bean
- 国际化相关的
MessageSource - 应用事件广播器
ApplicationEventMulticaster - 环境、系统属性相关 Bean 等
- 国际化相关的
-
实例化非懒加载的单例 Bean
-
实例化
- 选合适的构造方法(可能带
@Autowired); - 通过反射 new 出对象。
- 选合适的构造方法(可能带
-
属性填充(依赖注入)
- 找到所有
@Autowired、@Resource、@Value注解的字段/方法/构造参数; - 从容器中查出对应依赖,注入进去(反射赋值
- 找到所有
-
Aware 回调
- 如果 Bean 实现了
BeanNameAware、BeanFactoryAware、ApplicationContextAware等接口,调用相应的 setter
- 如果 Bean 实现了
-
BeanPostProcessor 前置处理
- 调用所有注册的
BeanPostProcessor#postProcessBeforeInitialization; - AOP 就会在这里判断是否需要为该 Bean 创建代理。
- 调用所有注册的
-
始化方法
- 调用
InitializingBean.afterPropertiesSet(); - 调用
@PostConstruct标注的方法; - 调用配置的
init-method。
- 调用
-
BeanPostProcessor 后置处理
- 调用
postProcessAfterInitialization; - 如果需要 AOP 代理,这里返回的对象很可能已经是一个代理类实例。
- 调用
-
放入单例缓存
- 写入
singletonObjectsMap; - 以后
getBean()直接从这里拿。
- 写入
-
开始 ↓ [构造器实例化] ↓ [属性填充(依赖注入)] ↓ [Aware 回调(BeanNameAware / BeanFactoryAware ...)] ↓ [BeanPostProcessor.before 初始化前处理] ↓ [初始化: - InitializingBean.afterPropertiesSet() - 自定义 init 方法] ↓ [BeanPostProcessor.after 初始化后处理] ↓ [Bean 使用中] ↓ [销毁: - DisposableBean.destroy() - 自定义 destroy 方法] ↓ 结束
-
-
-
spring的依赖注入方式
- 按注入入口:
- 构造器注入(推荐)
- Setter 注入
- 字段注入(简单但不推荐作为首选)
- 按配置方式:
- XML 配置:
<constructor-arg>、<property>; - 注解方式:
@Autowired、@Qualifier、@Resource、@Inject等。
- XML 配置:
- 当前主流实践是:
- 在 Spring Boot 中优先使用构造器注入,字段注入尽量少用;
- 对可选依赖可以使用 Setter 注入。
- 按注入入口:
@Service
public class OrderService {
private final UserService userService;
private final PayService payService;
// 构造器注入
@Autowired // Spring 4.3 以后,只有一个构造器时可以省略
public OrderService(UserService userService,
PayService payService) {
this.userService = userService;
this.payService = payService;
}
}
@Service
public class NotifyService {
private SmsClient smsClient;
@Autowired // 通过 setter 注入
public void setSmsClient(SmsClient smsClient) {
this.smsClient = smsClient;
}
}
@Service
public class NotifyService {
private SmsClient smsClient;
@Autowired // 通过 setter 注入
public void setSmsClient(SmsClient smsClient) {
this.smsClient = smsClient;
}
}
@Service
public class UserService {
@Autowired
private UserRepository userRepository; // 字段注入
@Autowired
public UserService(LogService logService) { // 构造器注入
...
}
}
@Service
public class UserService {
@Autowired
private UserRepository userRepository; // 字段注入
@Autowired
public UserService(LogService logService) { // 构造器注入
...
}
}
import javax.inject.Inject;
@Service
public class UserService {
@Inject
private UserRepository userRepository;
}-
- AutowiredAnnotationBeanPostProcessor:在 Bean 的初始化阶段,会通过 Bean 后置处理器来进行一些前置和后置的处理。
- 实现@Autowired 的功能,也是通过后置处理器来完成的。这个后置处理器就是 AutowiredAnnotationBeanPostProcessor。
-
使用AOP
-
引入依赖
-
自定义一个注解
@Retention(RetentionPolicy.RUNTIME) @Target({ElementType.METHOD}) @Documented public @interface WebLog { }
-
配置aop切面
@Aspect @Component public class WebLogAspect { private final static Logger logger = LoggerFactory.getLogger(WebLogAspect.class); /** * 以自定义 @WebLog 注解为切点 **/ @Pointcut("@annotation(cn.fighter3.spring.aop_demo.WebLog)") public void webLog() {} /** * 在切点之前织入 */ @Before("webLog()") public void doBefore(JoinPoint joinPoint) throws Throwable { // 开始打印请求日志 ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes(); HttpServletRequest request = attributes.getRequest(); // 打印请求相关参数 logger.info("========================================== Start =========================================="); // 打印请求 url logger.info("URL : {}", request.getRequestURL().toString()); // 打印 Http method logger.info("HTTP Method : {}", request.getMethod()); // 打印调用 controller 的全路径以及执行方法 logger.info("Class Method : {}.{}", joinPoint.getSignature().getDeclaringTypeName(), joinPoint.getSignature().getName()); // 打印请求的 IP logger.info("IP : {}", request.getRemoteAddr()); // 打印请求入参 logger.info("Request Args : {}",new ObjectMapper().writeValueAsString(joinPoint.getArgs())); } /** * 在切点之后织入 * @throws Throwable */ @After("webLog()") public void doAfter() throws Throwable { // 结束后打个分隔线,方便查看 logger.info("=========================================== End ==========================================="); } /** * 环绕 */ @Around("webLog()") public Object doAround(ProceedingJoinPoint proceedingJoinPoint) throws Throwable { //开始时间 long startTime = System.currentTimeMillis(); Object result = proceedingJoinPoint.proceed(); // 打印出参 logger.info("Response Args : {}", new ObjectMapper().writeValueAsString(result)); // 执行耗时 logger.info("Time-Consuming : {} ms", System.currentTimeMillis() - startTime); return result; } } @GetMapping("/hello") @WebLog(desc = "这是一个欢迎接口") public String hello(String name){ return "Hello "+name; }
-
-
springAOP和AspectJAOP区别?
-
spring事务隔离等级
-
READ UNCOMMITTED未提交读✅ 脏读
✅ 不可重复读
✅ 幻读
-
READ COMMITTED提交读❌ 不再有脏读。
✅ 不可重复读
✅ 幻读:
-
REPEATABLE READ可重复读❌ 脏读
❌ 不可重复读
✅ 幻读(按标准 SQL 理解)
-
SERIALIZABLE可串行化❌ 脏读
❌ 不可重复读
❌ 幻读
-
三种典型并发问题
- 脏读(Dirty Read)
- 事务 A 读到了事务 B 还没提交的数据
- 如果 B 回滚了,A 相当于用了“不存在”的数据。
- 不可重复读(Non-repeatable Read)
- 同一个事务 A,在两次查询之间,另一个事务 B 修改并提交了这行数据。
- A 前后两次读同一行,结果不一样。
- 幻读(Phantom Read)
- 事务 A 按条件查询到一批记录。
- 过程中事务 B 插入或删除了满足条件的新行并提交。
- A 再次按同样条件查询,发现记录条数变了,仿佛“多/少”了几行。
- 脏读(Dirty Read)
-
-
springMVC的核心组件
- DispatcherServlet:前置控制器,是整个流程控制的核心,控制其他组件的执行,进行统一调度,降低组件之间的耦合性,相当于总指挥。
- Handler(controller):处理器,完成具体的业务逻辑,相当于 Servlet 或 Action。
- HandlerMapping:DispatcherServlet 接收到请求之后,通过 HandlerMapping 将不同的请求映射到不同的 Handler。
- HandlerInterceptor:处理器拦截器,是一个接口,如果需要完成一些拦截处理,可以实现该接口。
- HandlerExecutionChain:处理器执行链,包括两部分内容:Handler 和 HandlerInterceptor(系统会有一个默认的 HandlerInterceptor,如果需要额外设置拦截,可以添加拦截器)。
- HandlerAdapter:处理器适配器,Handler 执行业务方法之前,需要进行一系列的操作,包括表单数据的验证、数据类型的转换、将表单数据封装到 JavaBean 等,这些操作都是由 HandlerApater 来完成,开发者只需将注意力集中业务逻辑的处理上,DispatcherServlet 通过 HandlerAdapter 执行不同的 Handler。
- ModelAndView:装载了模型数据和视图信息,作为 Handler 的处理结果,返回给 DispatcherServlet。
- ViewResolver:视图解析器,DispatcheServlet 通过它将逻辑视图解析为物理视图,最终将渲染结果响应给客户端
-
restful处理流程
-
客户端向服务端发送一次请求,这个请求会先到前端控制器 DispatcherServlet
-
DispatcherServlet 接收到请求后会调用 HandlerMapping 处理器映射器。由此得知,该请求该由哪个 Controller 来处理
-
DispatcherServlet 调用 HandlerAdapter 处理器适配器,告诉处理器适配器应该要去执行哪个 Controller
-
Controller 被封装成了 ServletInvocableHandlerMethod,HandlerAdapter 处理器适配器去执行 invokeAndHandle 方法,完成对 Controller 的请求处理
-
HandlerAdapter 执行完对 Controller 的请求,会调用 HandlerMethodReturnValueHandler 去处理返回值,主要的过程:
5.1. 调用 RequestResponseBodyMethodProcessor,创建 ServletServerHttpResponse(Spring 对原生 ServerHttpResponse 的封装)实例
5.2.使用 HttpMessageConverter 的 write 方法,将返回值写入 ServletServerHttpResponse 的 OutputStream 输出流中
5.3.在写入的过程中,会使用 JsonGenerator(默认使用 Jackson 框架)对返回值进行 Json 序列化
-
执行完请求后,返回的 ModealAndView 为 null,ServletServerHttpResponse 里也已经写入了响应,所以不用关心 View 的处理
-
-
springboot的自动配置依赖
@SpringBootApplication是一个复合注解,包含了@EnableAutoConfigurationEnableAutoConfiguration只是一个简单的注解,自动装配核心功能的实现实际是通过AutoConfigurationImportSelector类utoConfigurationImportSelector实现了ImportSelector接口,这个接口的作用就是收集需要导入的配置类,配合@Import()就可以将相应的类导入到 Spring 容器中- 获取注入类的方法是 selectImports(),它实际调用的是
getAutoConfigurationEntry,这个方法是获取自动装配类的关键,主要流程可以分为这么几步:- 获取注解的属性,用于后面的排除
- 获取所有需要自动装配的配置类的路径:这一步是最关键的,从 META-INF/spring.factories 获取自动配置类的路径
- 去掉重复的配置类和需要排除的重复类,把需要自动加载的配置类的路径存储起来
-
自定义一个springbootsrater
-
编写一个业务逻辑
package com.example.mystarter; public class MyCustomService { public String sayHello() { return "Hello from MyCustomService!"; } }
-
编写一个自动配置类
package com.example.mystarter; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class MyCustomStarterAutoConfiguration { @Bean public MyCustomService myCustomService() { return new MyCustomService(); } }
-
创建springfactory配置文件
rg.springframework.boot.autoconfigure.EnableAutoConfiguration=\ com.example.mystarter.MyCustomStarterAutoConfiguration
-
-
redis
-
主流的微服务框架
- springcloud
- Spring Boot
- Netflix OSS
- Kubernetes + Docker
- Apache Kafka
- Docker + Spring Cloud
-
yaml使用注意事项
- 大小写敏感
- 数值前边必须有空格,作为分隔符
- 使用缩进表示层级关系,缩进时,不允许使用Tab键,只能用空格(idea中会自动将Tab转换为空格)
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
-
使用反向代理的原因
- 安全
- 灵活
- 负载均衡
-
令牌技术(JWT)
- 服务器集群环境下无法使用Session
- 令牌技术的优点
- 支持PC端、移动端
- 解决集群环境下的认证问题
- 减轻服务器的存储压力(无需在服务器端存储)
-
springboot自动依赖原理
-
@SpringBootApplication@SpringBootConfiguration@EnableAutoConfiguration@ComponentScan
-
@EnableAutoConfiguration(自动配置核心注解)-
使用
@Import注解,导入了实现ImportSelector接口的实现类。AutoConfigurationImportSelector类是ImportSelector接口的实现类。 -
AutoConfigurationImportSelector类中重写了ImportSelector接口的selectImports()方法: -
selectImports()方法底层调用getAutoConfigurationEntry()方法,获取可自动配置的配置类信息集合
-
getAutoConfigurationEntry()方法通过调用getCandidateConfigurations(annotationMetadata, attributes)方法获取在配置文件中配置的所有自动配置类的集合
-
getCandidateConfigurations方法的功能:- 获取所有基于
META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports文件中配置类的集合
- 获取所有基于
-
-
-
SPI的实现机制
-
注册中心的作用
- 数据分布式存储:集中的注册信息数据存储、读取和共享
- 服务注册:服务提供者上报服务信息到注册中心
- 服务发现:服务消费者从注册中心拉取服务信息
- 心跳检测:定期检查服务提供者的存活状态
- 服务注销:手动剔除节点、或者自动剔除失效节点
- 更多优化点:比如注册中心本身的容错、服务消费者缓存等。
-
mybatis-plus的常见注解@TableName:表名注解,标识实体类对应的表@TableId:主键注解,标识实体类中的主键字段AUTOASSIGN_ID:雪花算法MP会自动生成一个Long类型的唯一IDINPUTASSIGN_UUID:随机字符串主键
@TableField:普通字段注解- 数据库没有该字段:必写
@TableField(exist = false)。 - 名称对不上:必写
@TableField("字段名")。 - 想保护隐私:用
select = false。 - 想自动填时间:用
fill属性。
- 数据库没有该字段:必写
-
mybatis-plus中条件构造器QueryWrapper<User> wrapper = new QueryWrapper<User>() .select("id","username","info","balance") .like("username","o") .ge("blance",1000); List<User> users = userMapper.selectList(wrapper); LambdaQueryWrapper<User> wrapper = new LambdaQuery<>(); wrapper.eq(User::getUserName) .gt(User::getAge,18); QueryWrapper<User> queryWrapper = new QueryWrapper<>(); LambdaQueryWrapper<User> lambda = queryWrapper.lambda();
- lambdaQueryWrapper更好
- 编译器检查
- 无视字段转化
- IDE提示友好
-
IService
-
public interface IUserService extends IService<User> { // 拓展自定义方法 } @Service public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService { }
-
list<User> users = userService.lambdaQuery() .like(username != null, User::getUsername, username) .eq(status != null, User::getStatus, status) .ge(minBalance != null, User::getBalance, minBalance) .le(maxBalance != null, User::getBalance, maxBalance) .list(); int remainBalance = user.getBalance() - money; lambdaUpdate() .set(User::getBalance, remainBalance) // 更新余额 .set(remainBalance == 0, User::getStatus, 2) // 动态判断,是否更新status .eq(User::getId, id) .eq(User::getBalance, user.getBalance()) // 乐观锁 .update();
-
-
my-batis中的DB类
-
my-batis中的逻辑删除
- 缺点:数据越来越多查询比较费时
-
mybatis与mybatis-plus的常见功能
mybatis-plus- 自动CRUD
- 条件构造器wrapper
- 自动分页插件
pagination - 逻辑删除
logical Delete - 自动填充功能
- 代码生成器
- 序列性主键与分布式id
mybatis- 结果映射
- 动态SQL
- SQL与java语句的彻底解码
- 参数动态绑定与处理
- 混村机制
- 插件
- 事务管理与连接池
-
微服务之间的相互调用
- 微服务不能打包成jar包
- 微服务之间物理隔离,运行在不同的环境中,
- 内存不共享。
- A的内存中,访问的是A的环境,根本无法访问到真正运行中微服务B及其数据库
- B代码修改,所有依赖B的服务都要重新编译,微服务本身退化成一个巨大的单体应用,失去了独立部署的意义
-
openFeign的基本使用
// 1 引入依赖 // 2开启feign功能 @SpringBootApplication @EnableFeignClients // 开启 Feign public class OrderApplication { public static void main(String[] args) { SpringApplication.run(OrderApplication.class, args); } } // 3 定义feign客户端 // contextId是为了防止Bean名称冲突,value是目标服务在Nacos中注册的服务名 @FeignClient(value = "item-service") public interface ItemClient { // 这里要和目标服务Controller的路径、参数、返回值完全对应 @GetMapping("/items/{id}") ItemDTO queryItemById(@PathVariable("id") Long id); @PutMapping("/items/stock/deduct") void deductStock(@RequestBody List<OrderDetailDTO> items); } // 在业务中使用 @Service public class OrderService { @Autowired private ItemClient itemClient; // 注入定义的Feign接口 public void createOrder(Order order) { // 1. 远程调用商品服务,获取商品信息 ItemDTO item = itemClient.queryById(order.getItemId()); // 2. 远程调用商品服务,扣减库存 itemClient.deductStock(order.getDetails()); // 3. 保存本地订单... } }
-
@Enable系列注解总结- 缓存注解详解 (
@EnableCaching)
@Cacheable:查询时使用。先看缓存有没有,有就直接返回;没有就执行方法,并将结果存入缓存。@CachePut:更新时使用。无论缓存是否有值,都会执行方法,并将结果更新到缓存中。@CacheEvict:删除时使用。执行方法后,删除对应的缓存条目(防止脏数据)。@CacheConfig:类级别注解。用于统一设置当前类下所有缓存的名字
- 定时任务详解 (
@EnableScheduling)- 让你的程序具备“闹钟”功能,在指定时间自动执行某段逻辑。
- 主配置类开启: 加
@EnableScheduling。 - 方法标注: 使用
@Scheduled注解。
@EnableAsync:开启异步调用- 默认情况下,Spring 是同步执行的。如果 A 方法调用 B 方法,A 必须等 B 运行完。开启异步后,B 会在另一个线程中运行,A 可以立即继续往下走。
- 主配置类开启: 在启动类上加
@EnableAsync。 - 方法标注: 在需要异步执行的方法上加
@Async
@EnableDiscoveryClient:开启服务发现- 主配置类开启: 加
@EnableDiscoveryClient(Spring Cloud 高版本中,只要引入了 Nacos 依赖且配置了地址,不加此注解通常也能自动注册,但建议显式加上以增加可读性)。 - 配置文件(yml)
- 主配置类开启: 加
- ``
- 缓存注解详解 (
-
gateway中的是过滤器
- 响应式百年城:非阻塞的、异步的、传统的springmvc拦截器是阻塞的,无法在gateway的异步链条中使用
- 位置更靠前
- 全局鉴权、日志统计、协议转化、发负载均衡、流量限流通常使用过滤器
- 微服务具体的内部的一般使用拦截器
-
Feign 拦截器解决全链路透传 1. 痛点:当“订单服务”通过 Feign 调用“购物车服务”时,这属于服务间调用,原本存储在拦截器里的
ThreadLocal信息不会自动带到 Feign 发起的请求头中,导致下游服务获取不到用户信息。 2. 解决方案:实现feign.RequestInterceptor接口。 3. -
动态路由
-
在传统的静态映射中你,新增一个积分服务,需要手动修改网关的yml文件并重启网关
-
也不能使用上节课学习的配置热更新来实现路由更新
-
NACOS动态路由
-
创建路由配置
[ { "id": "user-service-route", "uri": "lb://user-service", "predicates": [ { "name": "Path", "args": { "pattern": "/user/**" } } ], "filters": [ { "name": "StripPrefix", "args": { "_genkey_0": "1" } } ] } ] -
编写动态路由监视器
@Component public class NacosDynamicRouteService implements ApplicationEventPublisherAware { @Autowired private RouteDefinitionWriter routeDefinitionWriter; private ApplicationEventPublisher publisher; @Override public void setApplicationEventPublisher(ApplicationEventPublisher publisher) { this.publisher = publisher; } // 关键方法:更新路由 public void updateRoutes(String configInfo) { try { // 1. 将 JSON 字符串解析为路由定义对象列表 List<RouteDefinition> definitions = JSON.parseArray(configInfo, RouteDefinition.class); // 2. 清空并更新路由(这里简化了逻辑,实际应根据 ID 增量更新) for (RouteDefinition definition : definitions) { routeDefinitionWriter.save(Mono.just(definition)).subscribe(); } // 3. 发布事件,通知网关容器刷新路由表 this.publisher.publishEvent(new RefreshRoutesEvent(this)); } catch (Exception e) { e.printStackTrace(); } } }
-
将这段监听逻辑放在网关启动类或者配置类中
// 假设在某个初始化方法中 configService.addListener(dataId, group, new Listener() { @Override public void receiveConfigInfo(String configInfo) { // 当 Nacos 配置变化时,调用上面的更新方法 nacosDynamicRouteService.updateRoutes(configInfo); } @Override public Executor getExecutor() { return null; } });
-
-
-
问题
- 业务健壮性问题
- 级联问题
- 跨服务问题
-
微服务保护
- 请求限流
- 线程隔离
- 服务熔断
- 编写服务降级逻辑
- 异常统计和熔断,
-
sentinel
-
限流
- QPS
-
线程隔离
- 并发线程数
-
服务熔断
- 编写降级逻辑
- 步骤一:在hm-api模块中给
ItemClient定义降级处理类,实现FallbackFactor
- 步骤一:在hm-api模块中给
package com.hmall.api.client.fallback; import com.hmall.api.client.ItemClient; import com.hmall.api.dto.ItemDTO; import com.hmall.api.dto.OrderDetailDTO; import com.hmall.common.exception.BizIllegalException; import com.hmall.common.utils.CollUtils; import lombok.extern.slf4j.Slf4j; import org.springframework.cloud.openfeign.FallbackFactory; import java.util.Collection; import java.util.List; @Slf4j public class ItemClientFallback implements FallbackFactory<ItemClient> { @Override public ItemClient create(Throwable cause) { return new ItemClient() { @Override public List<ItemDTO> queryItemByIds(Collection<Long> ids) { log.error("远程调用ItemClient#queryItemByIds方法出现异常,参数:{}", ids, cause); // 查询购物车允许失败,查询失败,返回空集合 return CollUtils.emptyList(); } @Override public void deductStock(List<OrderDetailDTO> items) { // 库存扣减业务需要触发事务回滚,查询失败,抛出异常 throw new BizIllegalException(cause); } }; } }
-
步骤二:在
hm-api模块中的com.hmall.api.config.DefaultFeignConfig类中将ItemClientFallback注册为一个Bean:public class DefaultFeignConfig{ @Bean public ItemClientFallback(){ return new clientFallback(); } }
- 步骤三:在
hm-api模块中的ItemClient接口中使用ItemClientFallbackFactory:
@FeignClient(value="item-service", configuration=DefaultFeignConfig.class, fallbackFactory=ItemClienntFallback.class) public interface ItemClient{ @GetMapping("/items") List<ItemoDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids); }
- 步骤三:在
-
服务熔断
- 编写降级逻辑
-
-
seata
-
@Service public class OrderService { @Autowired private ItemClient itemClient; // Feign客户端调用库存服务 @Autowired private OrderMapper orderMapper; // 只需要在业务入口开启全局事务 @GlobalTransactional(name = "create-order", rollbackFor = Exception.class) public void createOrder(OrderDTO orderDTO) { // 1. 本地操作:保存订单 orderMapper.insert(order); // 2. 远程操作:扣减库存(通过Feign) // 如果这里抛出异常,Seata会通知TC,进而回滚上面的orderMapper操作 itemClient.deductStock(orderDTO.getItemId(), orderDTO.getNum()); // 3. 远程操作:扣减余额... } }
-
XA 模式:追求“强一致性”
-
两阶段提交。第一阶段所有参与者执行 SQL 但不提交,锁定资源;第二阶段由事务管理器通知大家一起提交或回滚。
-
优点:强一致性,只要事务没结束,谁也改不了数据。
-
缺点:性能最差。因为长时间锁定数据库资源,并发高了系统会非常卡。
-
适用场景:对数据准确性要求极高、并发量不大的业务。
-
-
AT 模式:Seata 的“招牌”模式
-
一阶段本地事务直接提交,但 Seata 会自动记录 SQL 执行前后的快照(
undo_log)。如果失败,Seata 自动生成反向 SQL 来“抹掉”刚才的修改。 -
几乎没有代码侵入。你只需要加个
@GlobalTransactional注解。 -
缺点:存在短暂的数据不一致。但在大多数互联网业务(如你现在的商城项目)中完全够用。
-
-
-
同步通信的方式的缺点
- 拓展性差
- 性能下降
- 级联失败
-
异步调用的好处
- 耦合度更低
- 性能更好
- 业务扩展性强
- 故障隔离,避免级联失败
-
mq消息的可靠性
-
发送者可靠性
-
生产者重试机制
spring: rabbitmq: connection-timeout: 1s # 设置MQ的连接超时时间 template: retry: enabled: true # 开启超时重试机制 initial-interval: 1000ms # 失败后的初始等待时间 multiplier: 1 # 失败后下次的等待时长倍数,下次等待时长 = initial-interval * multiplier max-attempts: 3 # 最大重试次数
-
生产者确认机制
-
一旦交换机拿到了消息,生产者的第一阶段任务就完成了。如果消息是持久化的,MQ 会在消息落盘后才发出这个
ack。 -
nack(Negative-Acknowledge):消息没有到达交换机 -
Return Callback(退回):消息到了交换机,但没进队列spring: rabbitmq: publisher-confirm-type: correlated # 开启publisher confirm机制,并设置confirm类型 publisher-returns: true # 开启publisher return机制
package com.itheima.publisher.config; import lombok.AllArgsConstructor; import lombok.extern.slf4j.Slf4j; import org.springframework.amqp.core.ReturnedMessage; import org.springframework.amqp.rabbit.core.RabbitTemplate; import org.springframework.context.annotation.Configuration; import javax.annotation.PostConstruct; @Slf4j @AllArgsConstructor @Configuration public class MqConfig { private final RabbitTemplate rabbitTemplate; @PostConstruct public void init(){ // 以callback结尾的通常就是回调函数 rabbitTemplate.setReturnsCallback(new RabbitTemplate.ReturnsCallback() { @Override public void returnedMessage(ReturnedMessage returned) { log.error("触发return callback,"); log.debug("exchange: {}", returned.getExchange()); log.debug("routingKey: {}", returned.getRoutingKey()); log.debug("message: {}", returned.getMessage()); log.debug("replyCode: {}", returned.getReplyCode()); log.debug("replyText: {}", returned.getReplyText()); } }); } }
-
-
-
MQ的可靠性
- 数据持久化
- 交换机持久化
- 队列持久化
-
LazyQueue
-
Lazy Queue(惰性队列) 是专门为处理消息堆积和大数据量存储而设计的队列模式。
-
普通队列 (Default)优先放在内存,内存满了才往磁盘挤。
-
(Lazy Queue)直接放在磁盘,消费时才加载进内存。
@Bean public Queue lazyQueue(){ return QueueBuilder .durable("lazy.queue") // 开启持久化 .lazy() // 关键:开启懒惰模式 .build(); }
-
-
消费者可靠性
- none(自动确认):
- 逻辑:MQ 投递消息后立即自动 ACK,不管消费者死活。
- 缺点:消息安全性最低,容易丢数据。
- manual(手动确认):
- 逻辑:由程序员在代码中显式调用
channel.basicAck()。 - 优点:最灵活,可以根据复杂的业务逻辑决定何时 ACK。
- 逻辑:由程序员在代码中显式调用
- auto(Spring 自动确认 - 默认推荐):
- 逻辑:Spring 监听器利用 AOP 环绕通知。如果业务方法正常执行完,Spring 自动返回
ack;如果抛出异常,Spring 自动返回nack。 - 优点:兼顾了安全性与开发的便捷性。
- 逻辑:Spring 监听器利用 AOP 环绕通知。如果业务方法正常执行完,Spring 自动返回
- none(自动确认):
-
失败重试机制
-
当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者。如果消费者再次执行依然出错,消息会再次requeue到队列,再次投递,直到消息处理成功为止。
-
本地重试机制 (Local Retry)
- 当消费者(Consumer)出现异常时,SpringAMQP 默认会在本地(消费者进程内)尝试重新执行业务逻辑,而不是立即把消息扔回 MQ 导致死循环。
spring: rabbitmq: listener: simple: retry: enabled: true # 开启消费者失败重试 initial-interval: 1000ms # 初始失败等待时间为1秒 multiplier: 1 # 失败时间间隔的倍数(1表示固定1秒) max-attempts: 3 # 最大重试次数(包括第一次) stateless: true # 无状态重试,若为false则会保留事务上下文
-
失败后的消息处理策略 (MessageRecovery)
- RejectAndDontRequeueRecoverer(默认策略):
- 处理:直接拒绝消息,消息被丢弃。
- 适用:不重要的日志或可以丢失的数据。
- ImmediateRequeueMessageRecoverer:
- 处理:返回
nack并让消息重新入队。 - 风险:如果 Bug 不解决,消息会永远在 MQ 和消费者之间死循环,极其消耗性能。
- 处理:返回
- PublishConfirmedMqListenerContainerFactory (RepublishMessageRecoverer):
- 处理:将失败的消息投递到一个专门的 “错误交换机”(Error Exchange)。
- 适用:核心业务(如订单)。开发人员可以监控错误交换机绑定的队列,人工介入处理。
- RejectAndDontRequeueRecoverer(默认策略):
-
-
-
业务幂等性
-
唯一消息id
-
@Bean public MessageConverter messageConverter(){ // 1.定义消息转换器 Jackson2JsonMessageConverter jjmc = new Jackson2JsonMessageConverter(); // 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息 jjmc.setCreateMessageIds(true); return jjmc; }
-
-
业务状态判断
-
-
延迟消息
- 死信交换机
- RabbitMQ 原生支持的方案,利用消息的 TTL(生存时间) 和 死信交换机 来实现。
- 原理:
- 消息发送到一个没有消费者的“死信队列”,并设置 TTL(如 30 分钟)。
- 当消息在队列中超过 TTL 未被消费时,会变成“死信”。
- MQ 自动将死信投递到配置好的 死信交换机 (DLX),进而进入目标队列
- 死信交换机
- 收集那些因处理失败而被拒绝的消息
- 收集那些因队列满了而被拒绝的消息
- 收集因TTL(有效期)到期的消息
- 死信交换机
-
ELK
-
为了搜索而生的数据库
-
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
-
指令 作用 示例 _mapping结构定义:操作索引的字段类型、分词器等。 GET /heima/_mapping_doc文档操作:代表索引中的具体文档。 POST /heima/_doc/1_search搜索:执行查询请求。 GET /heima/_search_update局部更新:更新文档中的部分字段。 POST /heima/_update/1_cat简要查看:用紧凑的表格形式查看集群状态。 GET _cat/indices?v
-
-
AOP
-
横切关注点:日志记录
-
切面(切点+通知)
-
-
@Autowired和@Resource注解的区别 -
实例化的方式
- 构造器
- 工厂方法
- 构造器
-
factorybean和beanfactory的区别
-
spring解决单例的循环依赖问题,使用了三级缓存
-
springbootstarter的作用
-
springboot自动装配的过程