- Convolutional Neural Networks are very similar to ordinary Neural Networks,they are made up of neurons that have learnable weights and biases.Each neuron receives some inputs, performs a dot product and optionally follows it with a non-linearity. The whole network still expresses a single differentiable score function: from the raw image pixels on one end to class scores at the other. And they still have a loss function (e.g. SVM/Softmax) on the last (fully-connected) layer and all the tips/tricks developed for learning regular Neural Networks still apply.
- Regular Neural Nets don’t scale well to full images. In CIFAR-10, images are only of size 32x32x3 (32 wide, 32 high, 3 color channels), so a single fully-connected neuron in a first hidden layer of a regular Neural Network would have 32323 = 3072 weights. This amount still seems manageable, but clearly this fully-connected structure does not scale to larger images. For example, an image of more respectable size, e.g. 200x200x3, would lead to neurons that have 2002003 = 120,000 weights. Moreover, we would almost certainly want to have several such neurons, so the parameters would add up quickly! Clearly, this full connectivity is wasteful and the huge number of parameters would quickly lead to overfitting.
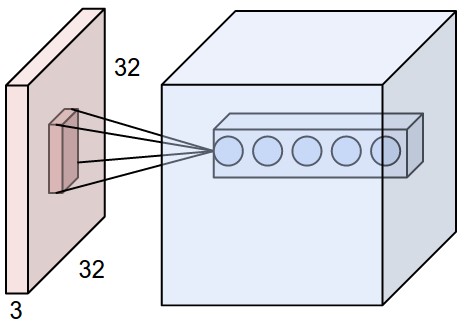
- 3D volumes of neurons. Convolutional Neural Networks take advantage of the fact that the input consists of images and they constrain the architecture in a more sensible way. In particular, unlike a regular Neural Network, the layers of a ConvNet have neurons arranged in 3 dimensions: width, height, depth.
-
When dealing with high-dimensional inputs such as images, as we saw above it is impractical to connect neurons to all neurons in the previous volume. Instead, we will connect each neuron to only a local region of the input volume
-
Images have localized information which means things that are closely present are closely related. We exploit this property to map images from local regions to next layer.
-
Parameter Sharing is the concept used to reduce the number of parameters in the model.
E.g If the input shape of the image is 227x227x3 and is convoluted with a filter of size 11x11x96.
The output size is 55x55x96
calculation :(227 - 11 + 2xP) / 4 + 1 = 55 #(stride = 4 and padding = 0)
-
we see that there are 555596 = 290,400 neurons in the first Conv Layer, and each has 11113 = 363 weights and 1 bias. Together, this adds up to 290400 * 364 = 105,705,600 parameters on the first layer of the ConvNet alone. Clearly, this number is very high.
-
If we assume same weights then the number of parameters will reduce to 11X11x3x96 = 34,848 unique weights, or 34,944 parameters (+96 biases)
!pip install numpy scipy scikit-learn pillow h5pyRequirement already satisfied: numpy in c:\users\welcome\anaconda3\lib\site-packages (1.16.5)
Requirement already satisfied: scipy in c:\users\welcome\anaconda3\lib\site-packages (1.3.1)
Requirement already satisfied: scikit-learn in c:\users\welcome\anaconda3\lib\site-packages (0.21.3)
Requirement already satisfied: pillow in c:\users\welcome\anaconda3\lib\site-packages (6.2.0)
Requirement already satisfied: h5py in c:\users\welcome\anaconda3\lib\site-packages (2.9.0)
Requirement already satisfied: joblib>=0.11 in c:\users\welcome\anaconda3\lib\site-packages (from scikit-learn) (0.13.2)
Requirement already satisfied: six in c:\users\welcome\anaconda3\lib\site-packages (from h5py) (1.12.0)
# numpy array has the shape (60000x28x28)
# Reshaping the numpy array into an image format
# image format is (60000x28x28x1) of float datatype and scales between [0,1]
def pre_process_images(x_train,y_train,x_test,y_test):
image_height,image_width = 28,28
x_train = x_train.reshape(x_train.shape[0], image_height, image_width, 1)
x_test = x_test.reshape(x_test.shape[0], image_height, image_width, 1)
input_shape = (image_height, image_width, 1)
no_classes = 10
# changing to float
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
#scaling to [0,1]
x_train /= 255
x_test /= 255
# category encoding
y_train = tf.keras.utils.to_categorical(y_train, no_classes)
y_test = tf.keras.utils.to_categorical(y_test, no_classes)
print("Pre_processing_done")
return x_train,y_train,x_test,y_testdef simple_cnn(input_shape):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(
filters=64,
kernel_size=(3, 3),
activation='relu',
input_shape=input_shape
))
model.add(tf.keras.layers.Conv2D(
filters=128,
kernel_size=(3, 3),
activation='relu'
))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(rate=0.3))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(units=1024, activation='relu'))
model.add(tf.keras.layers.Dropout(rate=0.3))
model.add(tf.keras.layers.Dense(units=no_classes, activation='softmax'))
model.compile(loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
return model
- The batch size can be selected based on the RAM available on your machine. The higher the batch size, the more RAM required. The impact of the batch size on the accuracy is minimal. The number of classes is equal to 10 here and will be different for different problems. The number of epochs determines how many times the training has to go through the full dataset. If the loss is reduced at the end of all epochs, it can be set to a high number. In a few cases, training longer could give better accuracy.
def train_model():
epochs = 2
batch_size = 64
input_shape = (28,28,1)
simple_cnn_model = simple_cnn(input_shape)
simple_cnn_model.fit(x_train, y_train, batch_size, epochs, (x_test, y_test))
train_loss, train_accuracy = simple_cnn_model.evaluate(
x_train, y_train, verbose=0)
print('Train data loss:', train_loss)
print('Train data accuracy:', train_accuracy)def test_model(x_test,y_test):
test_loss, test_accuracy = simple_cnn_model.evaluate(
x_test, y_test, verbose=0)
print('Test data loss:', test_loss)
print('Test data accuracy:', test_accuracy)#Let's train our cnn on fashion mnist
# loading the dataset
# using tf 2.0
# I didn't pip install tensorflow since I am using google collab (It's pre-installed)
from keras.datasets import fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
#x_train is a numpy array of shape (60,000,28,28)
#y_train is a numpy array of length (60,000)Using TensorFlow backend.
Downloading data from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 4us/step
Downloading data from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 2s 0us/step
Downloading data from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz
8192/5148 [===============================================] - 0s 0us/step
Downloading data from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 1s 0us/step
x_train,y_train,x_test,y_test = pre_process_images(x_train,y_train,x_test,y_test)Pre_processing_done
train_model()Train on 60000 samples
Epoch 1/2
Epoch 2/2
Train data loss: 0.15943638891180356
Train data accuracy: 0.9422333
test_model(x_test,y_test)Test data loss: 4.849679325866699
Test data accuracy: 0.0562
#bring data from kaggle
!pip install kaggle!pip install --upgrade kaggleRequirement already up-to-date: kaggle in /usr/local/lib/python3.6/dist-packages (1.5.6)
Requirement already satisfied, skipping upgrade: urllib3<1.25,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from kaggle) (1.24.3)
Requirement already satisfied, skipping upgrade: certifi in /usr/local/lib/python3.6/dist-packages (from kaggle) (2019.11.28)
Requirement already satisfied, skipping upgrade: python-dateutil in /usr/local/lib/python3.6/dist-packages (from kaggle) (2.8.1)
Requirement already satisfied, skipping upgrade: six>=1.10 in /usr/local/lib/python3.6/dist-packages (from kaggle) (1.12.0)
Requirement already satisfied, skipping upgrade: requests in /usr/local/lib/python3.6/dist-packages (from kaggle) (2.21.0)
Requirement already satisfied, skipping upgrade: tqdm in /usr/local/lib/python3.6/dist-packages (from kaggle) (4.38.0)
Requirement already satisfied, skipping upgrade: python-slugify in /usr/local/lib/python3.6/dist-packages (from kaggle) (4.0.0)
Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests->kaggle) (2.8)
Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests->kaggle) (3.0.4)
Requirement already satisfied, skipping upgrade: text-unidecode>=1.3 in /usr/local/lib/python3.6/dist-packages (from python-slugify->kaggle) (1.3)
from google.colab import files
uploaded = files.upload()
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn])))
# Then move kaggle.json into the folder where the API expects to find it.
!mkdir -p ~/.kaggle/ && mv kaggle.json ~/.kaggle/ && chmod 600 ~/.kaggle/kaggle.jsonSaving kaggle.json to kaggle.json
User uploaded file "kaggle.json" with length 69 bytes
Dont' forget to join the competition or click on I understand button in kaggle before downlaoding the dataset
!kaggle competitions download -c dogs-vs-catsWarning: Looks like you're using an outdated API Version, please consider updating (server 1.5.6 / client 1.5.4)
Downloading test1.zip to /content
95% 257M/271M [00:02<00:00, 97.2MB/s]
100% 271M/271M [00:02<00:00, 117MB/s]
Downloading sampleSubmission.csv to /content
0% 0.00/86.8k [00:00<?, ?B/s]
100% 86.8k/86.8k [00:00<00:00, 86.2MB/s]
Downloading train.zip to /content
97% 527M/543M [00:04<00:00, 138MB/s]
100% 543M/543M [00:05<00:00, 110MB/s]
!dirsample_data sampleSubmission.csv test1.zip train.zip
!unzip train.zip
!unzip test1.zip- We will be using Data generator class from keras to read data from the disk and it only loads data in batches so memory efficient too
- One important note here is that generatore class expects your folder structure to be in a certain way data should be present in subfolders of individual class e.g train/dog , train/cat ,test/dog, test/cat
- Hence, we will write copy_files() function to take images from train folder and create subfolders of classes and place images accordlingly
import os
import shutil
work_dir = '/content' # give your correct directory
image_names = sorted(os.listdir(os.path.join(work_dir, 'train')))
def copy_files(prefix_str, range_start, range_end, target_dir):
image_paths = [os.path.join(work_dir, 'train', prefix_str + '.' + str(i) + '.jpg')
for i in range(range_start, range_end)]
dest_dir = os.path.join(work_dir, 'new_data', target_dir, prefix_str)
os.makedirs(dest_dir)
for image_path in image_paths:
shutil.copy(image_path, dest_dir)
copy_files('dog', 0, 1000, 'train')
copy_files('cat', 0, 1000, 'train')
copy_files('dog', 1000, 1400, 'test')
copy_files('cat', 1000, 1400, 'test')from IPython.display import Image
Image("/content/new_data/train/cat/cat.1.jpg")
#Benchmarking with simple CNN
import os
work_dir = "/content/data"
image_height, image_width = 150, 150
train_dir = os.path.join(work_dir,'train')
test_dir = os.path.join(work_dir, 'test')
no_classes = 2
no_validation = 800
epochs = 2
batch_size = 5
no_train = 2000
no_test = 800
input_shape = (image_height, image_width, 3)
epoch_steps = no_train // batch_size
test_steps = no_test // batch_sizeimport tensorflow as tf
generator_train = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)
generator_test = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)
train_images = generator_train.flow_from_directory(
train_dir,
batch_size=batch_size,
target_size=(image_width, image_height))
test_images = generator_test.flow_from_directory(
test_dir,
batch_size=batch_size,
target_size=(image_width, image_height))
The default version of TensorFlow in Colab will soon switch to TensorFlow 2.x.
We recommend you upgrade now
or ensure your notebook will continue to use TensorFlow 1.x via the %tensorflow_version 1.x magic:
more info.
Found 2000 images belonging to 2 classes.
Found 800 images belonging to 2 classes.
def simple_cnn(input_shape):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(
filters=64,
kernel_size=(3, 3),
activation='relu',
input_shape=input_shape
))
model.add(tf.keras.layers.Conv2D(
filters=128,
kernel_size=(3, 3),
activation='relu'
))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(rate=0.3))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(units=1024, activation='relu'))
model.add(tf.keras.layers.Dropout(rate=0.3))
model.add(tf.keras.layers.Dense(units=no_classes, activation='softmax'))
model.compile(loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
return model
simple_cnn_model = simple_cnn(input_shape)
simple_cnn_model.fit_generator(
train_images,
steps_per_epoch=epoch_steps,
epochs=epochs,
validation_data=test_images,
validation_steps=test_steps)WARNING:tensorflow:From /tensorflow-1.15.0/python3.6/tensorflow_core/python/ops/resource_variable_ops.py:1630: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.
Instructions for updating:
If using Keras pass *_constraint arguments to layers.
Epoch 1/2
399/400 [============================>.] - ETA: 3s - loss: 0.8801 - acc: 0.4902Epoch 1/2
400/400 [==============================] - 1300s 3s/step - loss: 0.8796 - acc: 0.4905 - val_loss: 0.6932 - val_acc: 0.4988
Epoch 2/2
399/400 [============================>.] - ETA: 3s - loss: 0.6996 - acc: 0.5218Epoch 1/2
400/400 [==============================] - 1272s 3s/step - loss: 0.6996 - acc: 0.5215 - val_loss: 0.7028 - val_acc: 0.4963
<tensorflow.python.keras.callbacks.History at 0x7f6cfe820400>
#Let's try with bigger batch size
work_dir = "/content/data"
image_height, image_width = 150, 150
train_dir = os.path.join(work_dir,'train')
test_dir = os.path.join(work_dir, 'test')
no_classes = 2
no_validation = 800
epochs = 2
batch_size = 200
no_train = 2000
no_test = 800
input_shape = (image_height, image_width, 3)
epoch_steps = no_train // batch_size
test_steps = no_test // batch_size
#***************************************************
import tensorflow as tf
generator_train = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)
generator_test = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)
train_images = generator_train.flow_from_directory(
train_dir,
batch_size=batch_size,
target_size=(image_width, image_height))
test_images = generator_test.flow_from_directory(
test_dir,
batch_size=batch_size,
target_size=(image_width, image_height))
#**************************************************
simple_cnn_model.fit_generator(
train_images,
steps_per_epoch=epoch_steps,
epochs=epochs,
validation_data=test_images,
validation_steps=test_steps)Found 2000 images belonging to 2 classes.
Found 800 images belonging to 2 classes.
Epoch 1/2
9/10 [==========================>...] - ETA: 7s - loss: 0.4996 - acc: 0.7261 Epoch 1/2
10/10 [==============================] - 83s 8s/step - loss: 0.4972 - acc: 0.7285 - val_loss: 0.9140 - val_acc: 0.5550
Epoch 2/2
9/10 [==========================>...] - ETA: 7s - loss: 0.4316 - acc: 0.7789 Epoch 1/2
10/10 [==============================] - 81s 8s/step - loss: 0.4308 - acc: 0.7800 - val_loss: 0.9768 - val_acc: 0.5512
<tensorflow.python.keras.callbacks.History at 0x7f6cfe8fa518>
-
Data augmentation gives ways to increase the size of the dataset. Data augmentation introduces noise during training, producing robustness in the model to various inputs. This technique is useful in scenarios when the dataset is small and can be combined and used with other techniques.
-
There are various ways to augment the images as described as follows:
- Flipping: The image is mirrored or flipped in a horizontal or vertical direction
- Random Cropping: Random portions are cropped, hence the model can deal with occlusions
- Shearing: The images are deformed to affect the shape of the objects
- Zooming: Zoomed portions of images are trained to deal with varying scales of images
- Rotation: The objects are rotated to deal with various degrees of change in objects
- Whitening: The whitening is done by a Principal Component Analysis that preserves only the important data
- Normalization: Normalizes the pixels by standardizing the mean and variance
- Channel shifting: The color channels are shifted to make the model
#Data Augmentation is one of the technique to improve dataset size let's see if data augmentation helps.
generator_train = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1. / 255,
horizontal_flip=True,
zoom_range=0.3,
shear_range=0.3,)
generator_test = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)
#*************************************************
train_images = generator_train.flow_from_directory(
train_dir,
batch_size=batch_size,
target_size=(image_width, image_height))
test_images = generator_test.flow_from_directory(
test_dir,
batch_size=batch_size,
target_size=(image_width, image_height))
#**************************************************
simple_cnn_model.fit_generator(
train_images,
steps_per_epoch=epoch_steps,
epochs=epochs,
validation_data=test_images,
validation_steps=test_steps)Found 2000 images belonging to 2 classes.
Found 800 images belonging to 2 classes.
Epoch 1/2
9/10 [==========================>...] - ETA: 7s - loss: 0.7855 - acc: 0.5411 Epoch 1/2
10/10 [==============================] - 83s 8s/step - loss: 0.7759 - acc: 0.5440 - val_loss: 0.7241 - val_acc: 0.5562
Epoch 2/2
9/10 [==========================>...] - ETA: 7s - loss: 0.6967 - acc: 0.5250 Epoch 1/2
10/10 [==============================] - 80s 8s/step - loss: 0.6965 - acc: 0.5220 - val_loss: 0.7061 - val_acc: 0.5312
<tensorflow.python.keras.callbacks.History at 0x7f6cfe7a32b0>
- Trained on 3 different bacth sizes : 10 ,100, 200 and the best val_accuracy achieved is 55% which is not great. May be we can improve this by adding more data or by making more complex network.
- We tried with data augmentation to see if there is any improvement but since we are using very less data we either need more complicated network or more data.
- But let's say we don't have much data and no knowledge on making more complex networks. Transfer learning comes to rescue.
- Transfer learning is the process of learning from a pre-trained model that was trained on a larger dataset.
- Training a model with random initialization often takes time and energy to get the result.
- Initializing the model with a pre-trained model gives faster convergence, saving time and energy.
- These models that are pre-trained are often trained with carefully chosen hyperparameters.
- Either the several layers of the pre-trained model can be used without any modification, or can be bit trained to adapt to the changes.

- pass training and testing data to vgg network and extract the output and store is as bottle neck features
- Use these bottle neck features as input and train a FCNN

import numpy as np
import os
import tensorflow as tf
work_dir = '/content/new_data'
image_height, image_width = 150, 150
train_dir = os.path.join(work_dir, 'train')
test_dir = os.path.join(work_dir, 'test')
no_classes = 2
no_validation = 800
epochs = 50
batch_size = 50
no_train = 2000
no_test = 800
input_shape = (image_height, image_width, 3)
epoch_steps = no_train // batch_size
test_steps = no_test // batch_size
generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)
model = tf.keras.applications.VGG16(include_top=False)
train_images = generator.flow_from_directory(
train_dir,
batch_size=batch_size,
target_size=(image_width, image_height),
class_mode=None,
shuffle=False
)
train_bottleneck_features = model.predict_generator(train_images, epoch_steps)
print(len(train_bottleneck_features))
test_images = generator.flow_from_directory(
test_dir,
batch_size=batch_size,
target_size=(image_width, image_height),
class_mode=None,
shuffle=False
)
test_bottleneck_features = model.predict_generator(test_images, test_steps)
#print(test_bottleneck_features)
train_labels = np.array([0] * int(no_train / 2) + [1] * int(no_train / 2))
test_labels = np.array([0] * int(no_test / 2) + [1] * int(no_test / 2))
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=train_bottleneck_features.shape[1:]))
model.add(tf.keras.layers.Dense(1024, activation='relu'))
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(
train_bottleneck_features,
train_labels,
batch_size=batch_size,
epochs=epochs,
validation_data=(test_bottleneck_features, test_labels))
model.save_weights("/content/top_model.h5")
print("Saved model to disk")Found 2000 images belonging to 2 classes.
2000
Found 800 images belonging to 2 classes.
WARNING:tensorflow:From /tensorflow-1.15.0/python3.6/tensorflow_core/python/ops/nn_impl.py:183: where (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
Train on 2000 samples, validate on 800 samples
Epoch 1/50
2000/2000 [==============================] - 2s 777us/sample - loss: 1.8688 - acc: 0.7005 - val_loss: 0.4713 - val_acc: 0.8037
Epoch 2/50
2000/2000 [==============================] - 1s 563us/sample - loss: 0.5174 - acc: 0.8075 - val_loss: 0.2918 - val_acc: 0.8825
Epoch 3/50
2000/2000 [==============================] - 1s 575us/sample - loss: 0.3794 - acc: 0.8410 - val_loss: 0.8285 - val_acc: 0.7188
Epoch 4/50
2000/2000 [==============================] - 1s 542us/sample - loss: 0.3394 - acc: 0.8525 - val_loss: 0.2436 - val_acc: 0.9013
Epoch 5/50
2000/2000 [==============================] - 1s 529us/sample - loss: 0.2541 - acc: 0.8980 - val_loss: 0.3642 - val_acc: 0.8587
Epoch 6/50
2000/2000 [==============================] - 1s 549us/sample - loss: 0.2611 - acc: 0.8950 - val_loss: 0.2880 - val_acc: 0.8838
Epoch 7/50
2000/2000 [==============================] - 1s 560us/sample - loss: 0.2244 - acc: 0.9080 - val_loss: 0.5131 - val_acc: 0.8225
Epoch 8/50
2000/2000 [==============================] - 1s 562us/sample - loss: 0.1790 - acc: 0.9235 - val_loss: 1.0005 - val_acc: 0.7375
Epoch 9/50
2000/2000 [==============================] - 1s 546us/sample - loss: 0.1682 - acc: 0.9315 - val_loss: 0.3694 - val_acc: 0.8700
Epoch 10/50
2000/2000 [==============================] - 1s 555us/sample - loss: 0.1218 - acc: 0.9535 - val_loss: 0.3155 - val_acc: 0.8950
Epoch 11/50
2000/2000 [==============================] - 1s 554us/sample - loss: 0.1460 - acc: 0.9470 - val_loss: 2.2722 - val_acc: 0.6750
Epoch 12/50
2000/2000 [==============================] - 1s 540us/sample - loss: 0.1176 - acc: 0.9620 - val_loss: 0.3803 - val_acc: 0.8838
Epoch 13/50
2000/2000 [==============================] - 1s 554us/sample - loss: 0.1037 - acc: 0.9655 - val_loss: 0.3105 - val_acc: 0.9038
Epoch 14/50
2000/2000 [==============================] - 1s 536us/sample - loss: 0.1479 - acc: 0.9625 - val_loss: 0.3166 - val_acc: 0.9100
Epoch 15/50
2000/2000 [==============================] - 1s 539us/sample - loss: 0.0881 - acc: 0.9745 - val_loss: 1.6726 - val_acc: 0.7450
Epoch 16/50
2000/2000 [==============================] - 1s 542us/sample - loss: 0.0957 - acc: 0.9765 - val_loss: 0.4126 - val_acc: 0.8913
Epoch 17/50
2000/2000 [==============================] - 1s 559us/sample - loss: 0.0624 - acc: 0.9835 - val_loss: 0.3352 - val_acc: 0.9013
Epoch 18/50
2000/2000 [==============================] - 1s 560us/sample - loss: 0.0449 - acc: 0.9815 - val_loss: 0.3566 - val_acc: 0.9062
Epoch 19/50
2000/2000 [==============================] - 1s 540us/sample - loss: 0.0487 - acc: 0.9840 - val_loss: 0.4171 - val_acc: 0.9038
Epoch 20/50
2000/2000 [==============================] - 1s 540us/sample - loss: 0.0949 - acc: 0.9805 - val_loss: 0.4179 - val_acc: 0.9075
Epoch 21/50
2000/2000 [==============================] - 1s 537us/sample - loss: 0.0552 - acc: 0.9865 - val_loss: 0.4399 - val_acc: 0.8988
Epoch 22/50
2000/2000 [==============================] - 1s 613us/sample - loss: 0.0046 - acc: 0.9990 - val_loss: 0.5215 - val_acc: 0.8988
Epoch 23/50
2000/2000 [==============================] - 1s 607us/sample - loss: 0.1005 - acc: 0.9800 - val_loss: 0.4700 - val_acc: 0.9025
Epoch 24/50
2000/2000 [==============================] - 1s 652us/sample - loss: 0.1025 - acc: 0.9810 - val_loss: 0.4607 - val_acc: 0.9025
Epoch 25/50
2000/2000 [==============================] - 1s 627us/sample - loss: 0.0016 - acc: 1.0000 - val_loss: 0.5077 - val_acc: 0.8975
Epoch 26/50
2000/2000 [==============================] - 1s 620us/sample - loss: 0.1122 - acc: 0.9840 - val_loss: 0.4889 - val_acc: 0.9025
Epoch 27/50
2000/2000 [==============================] - 1s 633us/sample - loss: 0.0023 - acc: 0.9995 - val_loss: 0.5971 - val_acc: 0.8988
Epoch 28/50
2000/2000 [==============================] - 1s 637us/sample - loss: 0.0757 - acc: 0.9900 - val_loss: 0.5099 - val_acc: 0.8988
Epoch 29/50
2000/2000 [==============================] - 1s 633us/sample - loss: 5.9677e-04 - acc: 1.0000 - val_loss: 0.5452 - val_acc: 0.9000
Epoch 30/50
2000/2000 [==============================] - 1s 606us/sample - loss: 0.1020 - acc: 0.9860 - val_loss: 0.5175 - val_acc: 0.9025
Epoch 31/50
2000/2000 [==============================] - 1s 594us/sample - loss: 4.3621e-04 - acc: 1.0000 - val_loss: 0.6256 - val_acc: 0.8963
Epoch 32/50
2000/2000 [==============================] - 1s 614us/sample - loss: 0.1032 - acc: 0.9835 - val_loss: 0.6199 - val_acc: 0.9038
Epoch 33/50
2000/2000 [==============================] - 1s 560us/sample - loss: 4.0788e-04 - acc: 1.0000 - val_loss: 0.6061 - val_acc: 0.9062
Epoch 34/50
2000/2000 [==============================] - 1s 578us/sample - loss: 0.0863 - acc: 0.9885 - val_loss: 0.5856 - val_acc: 0.9062
Epoch 35/50
2000/2000 [==============================] - 1s 584us/sample - loss: 4.1337e-04 - acc: 1.0000 - val_loss: 0.6075 - val_acc: 0.8963
Epoch 36/50
2000/2000 [==============================] - 1s 578us/sample - loss: 2.2670e-04 - acc: 1.0000 - val_loss: 0.6253 - val_acc: 0.9025
Epoch 37/50
2000/2000 [==============================] - 1s 566us/sample - loss: 0.0890 - acc: 0.9895 - val_loss: 0.6521 - val_acc: 0.9038
Epoch 38/50
2000/2000 [==============================] - 1s 589us/sample - loss: 1.2631e-04 - acc: 1.0000 - val_loss: 0.7181 - val_acc: 0.8963
Epoch 39/50
2000/2000 [==============================] - 1s 580us/sample - loss: 6.9977e-05 - acc: 1.0000 - val_loss: 0.6852 - val_acc: 0.9062
Epoch 40/50
2000/2000 [==============================] - 1s 541us/sample - loss: 0.0849 - acc: 0.9900 - val_loss: 0.6413 - val_acc: 0.9000
Epoch 41/50
2000/2000 [==============================] - 1s 533us/sample - loss: 7.5679e-04 - acc: 1.0000 - val_loss: 0.7081 - val_acc: 0.8963
Epoch 42/50
2000/2000 [==============================] - 1s 545us/sample - loss: 0.1462 - acc: 0.9835 - val_loss: 0.7195 - val_acc: 0.8963
Epoch 43/50
2000/2000 [==============================] - 1s 541us/sample - loss: 1.2459e-04 - acc: 1.0000 - val_loss: 0.7058 - val_acc: 0.9038
Epoch 44/50
2000/2000 [==============================] - 1s 537us/sample - loss: 0.1146 - acc: 0.9860 - val_loss: 0.7085 - val_acc: 0.9000
Epoch 45/50
2000/2000 [==============================] - 1s 544us/sample - loss: 1.6712e-04 - acc: 1.0000 - val_loss: 0.7145 - val_acc: 0.9050
Epoch 46/50
2000/2000 [==============================] - 1s 546us/sample - loss: 1.5932e-04 - acc: 1.0000 - val_loss: 0.7316 - val_acc: 0.9075
Epoch 47/50
2000/2000 [==============================] - 1s 561us/sample - loss: 0.1841 - acc: 0.9800 - val_loss: 0.8702 - val_acc: 0.8813
Epoch 48/50
2000/2000 [==============================] - 1s 555us/sample - loss: 3.0629e-04 - acc: 1.0000 - val_loss: 0.6504 - val_acc: 0.9100
Epoch 49/50
2000/2000 [==============================] - 1s 554us/sample - loss: 1.0161e-04 - acc: 1.0000 - val_loss: 0.6648 - val_acc: 0.9150
Epoch 50/50
2000/2000 [==============================] - 1s 543us/sample - loss: 1.6524e-05 - acc: 1.0000 - val_loss: 0.7623 - val_acc: 0.9000
Saved model to disk
- It was giving more than 90% accuracy caompared with our base model accuracy it is very good.
- Method use previous is suitable if you have small dataset but the catch is it may lead to overfitting.
Method 2 : Combine vgg model with fully connected network and train only the fc layers freezing the previous layers of the entire network.
import tensorflow as tf
input_tensor = tf.keras.layers.Input(shape=(150,150,3))
prev_model = tf.keras.applications.VGG16(weights='imagenet', include_top=False,input_tensor=input_tensor)
print('Model loaded.')
prev_model.summary()Model loaded.
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 150, 150, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
# build a classifier model to put on top of the convolutional model
top_model = tf.keras.models.Sequential()
top_model.add(tf.keras.layers.Flatten(input_shape = prev_model.output_shape[1:]))
top_model.add(tf.keras.layers.Dense(1024, activation='relu'))
top_model.add(tf.keras.layers.Dropout(0.3))
top_model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
top_model.load_weights('/content/top_model.h5')
top_model.summary()
top_model.layers
len(top_model.layers)Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_2 (Flatten) (None, 8192) 0
_________________________________________________________________
dense_4 (Dense) (None, 1024) 8389632
_________________________________________________________________
dropout_2 (Dropout) (None, 1024) 0
_________________________________________________________________
dense_5 (Dense) (None, 1) 1025
=================================================================
Total params: 8,390,657
Trainable params: 8,390,657
Non-trainable params: 0
_________________________________________________________________
4
#concatenating vgg16 with our custom fcnn
new_model = tf.keras.models.Sequential()
for l in prev_model.layers:
new_model.add(l)
new_model.add(top_model)
print(new_model.layers)
new_model.summary()
print(len(new_model.layers))[<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fe0c60fc1d0>, <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fe0c5fdec50>, <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7fe0c600e0b8>, <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fe0c4794ba8>, <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fe0c479ca90>, <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7fe0c47ad0f0>, <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fe0c47ad128>, <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fe0c47babe0>, <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fe0c47cd240>, <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7fe0c4759860>, <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fe0c4759898>, <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fe0c476d3c8>, <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fe0c47779e8>, <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7fe0c478c048>, <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fe0c478c080>, <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fe0c4719b70>, <tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fe0c472b1d0>, <tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7fe0c4738828>, <tensorflow.python.keras.engine.sequential.Sequential object at 0x7fe0c3b28048>]
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
_________________________________________________________________
sequential_3 (Sequential) (None, 1) 8390657
=================================================================
Total params: 23,105,345
Trainable params: 23,105,345
Non-trainable params: 0
_________________________________________________________________
19
#idea here is to train the last convolutional block and customm fcnn
# set the first 25 layers (up to the last conv block)
# to non-trainable (weights will not be updated)
for layer in new_model.layers[:14]:
layer.trainable = False
# compile the model with a SGD/momentum optimizer
# and a very slow learning rate.
new_model.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
#setting some parameters
work_dir = '/content/new_data'
img_height, img_width = 150, 150
train_dir = os.path.join(work_dir, 'train')
test_dir = os.path.join(work_dir, 'test')
no_classes = 2
no_validation = 800
epochs = 50
batch_size = 50
no_train = 2000
no_test = 800
input_shape = (img_height, img_width, 3)
epoch_steps = no_train // batch_size
test_steps = no_test // batch_size
#train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)
# prepare data augmentation configuration
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary')
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary')
# fine-tune the model
new_model.fit_generator(
train_generator,
steps_per_epoch=epoch_steps,
epochs=epochs,
validation_data= test_generator,
validation_steps=test_steps) Found 2000 images belonging to 2 classes.
Found 800 images belonging to 2 classes.
Epoch 1/50
39/40 [============================>.] - ETA: 0s - loss: 5.2537 - acc: 0.4990Epoch 1/50
40/40 [==============================] - 49s 1s/step - loss: 5.1392 - acc: 0.5020 - val_loss: 0.6928 - val_acc: 0.5200
Epoch 2/50
39/40 [============================>.] - ETA: 0s - loss: 0.6837 - acc: 0.5518Epoch 1/50
40/40 [==============================] - 47s 1s/step - loss: 0.6837 - acc: 0.5510 - val_loss: 0.6769 - val_acc: 0.5800
Epoch 3/50
39/40 [============================>.] - ETA: 0s - loss: 0.6711 - acc: 0.5903Epoch 1/50
40/40 [==============================] - 48s 1s/step - loss: 0.6704 - acc: 0.5920 - val_loss: 0.6619 - val_acc: 0.6300
Epoch 4/50
39/40 [============================>.] - ETA: 0s - loss: 0.6526 - acc: 0.6205Epoch 1/50
40/40 [==============================] - 48s 1s/step - loss: 0.6515 - acc: 0.6220 - val_loss: 0.6414 - val_acc: 0.6700
Epoch 5/50
39/40 [============================>.] - ETA: 0s - loss: 0.6403 - acc: 0.6492Epoch 1/50
40/40 [==============================] - 48s 1s/step - loss: 0.6402 - acc: 0.6495 - val_loss: 0.6210 - val_acc: 0.7088
Epoch 6/50
39/40 [============================>.] - ETA: 0s - loss: 0.6216 - acc: 0.6733Epoch 1/50
40/40 [==============================] - 48s 1s/step - loss: 0.6215 - acc: 0.6745 - val_loss: 0.5996 - val_acc: 0.7437
Epoch 7/50
39/40 [============================>.] - ETA: 0s - loss: 0.6053 - acc: 0.6949Epoch 1/50
40/40 [==============================] - 48s 1s/step - loss: 0.6045 - acc: 0.6940 - val_loss: 0.5792 - val_acc: 0.7325
Epoch 8/50
39/40 [============================>.] - ETA: 0s - loss: 0.5849 - acc: 0.7123Epoch 1/50
40/40 [==============================] - 47s 1s/step - loss: 0.5862 - acc: 0.7115 - val_loss: 0.5448 - val_acc: 0.7825
Epoch 9/50
39/40 [============================>.] - ETA: 0s - loss: 0.5629 - acc: 0.7256Epoch 1/50
40/40 [==============================] - 48s 1s/step - loss: 0.5621 - acc: 0.7260 - val_loss: 0.5164 - val_acc: 0.8012
Epoch 10/50
39/40 [============================>.] - ETA: 0s - loss: 0.5349 - acc: 0.7559Epoch 1/50
40/40 [==============================] - 48s 1s/step - loss: 0.5347 - acc: 0.7555 - val_loss: 0.4860 - val_acc: 0.8325
Epoch 11/50
39/40 [============================>.] - ETA: 0s - loss: 0.5019 - acc: 0.7738Epoch 1/50
40/40 [==============================] - 48s 1s/step - loss: 0.5011 - acc: 0.7750 - val_loss: 0.4477 - val_acc: 0.8350
Epoch 12/50
39/40 [============================>.] - ETA: 0s - loss: 0.4826 - acc: 0.7841Epoch 1/50
40/40 [==============================] - 48s 1s/step - loss: 0.4799 - acc: 0.7865 - val_loss: 0.4188 - val_acc: 0.8388
Epoch 13/50
39/40 [============================>.] - ETA: 0s - loss: 0.4506 - acc: 0.8056Epoch 1/50
40/40 [==============================] - 48s 1s/step - loss: 0.4504 - acc: 0.8050 - val_loss: 0.3870 - val_acc: 0.8525
Epoch 14/50
39/40 [============================>.] - ETA: 0s - loss: 0.4394 - acc: 0.8036Epoch 1/50
40/40 [==============================] - 48s 1s/step - loss: 0.4382 - acc: 0.8050 - val_loss: 0.3626 - val_acc: 0.8650
Epoch 15/50
39/40 [============================>.] - ETA: 0s - loss: 0.4100 - acc: 0.8215Epoch 1/50
40/40 [==============================] - 48s 1s/step - loss: 0.4095 - acc: 0.8215 - val_loss: 0.3384 - val_acc: 0.8700
Epoch 16/50
39/40 [============================>.] - ETA: 0s - loss: 0.3775 - acc: 0.8308Epoch 1/50
40/40 [==============================] - 48s 1s/step - loss: 0.3771 - acc: 0.8325 - val_loss: 0.3173 - val_acc: 0.8750
Epoch 17/50
39/40 [============================>.] - ETA: 0s - loss: 0.3669 - acc: 0.8492Epoch 1/50
40/40 [==============================] - 52s 1s/step - loss: 0.3694 - acc: 0.8485 - val_loss: 0.3446 - val_acc: 0.8512
Epoch 18/50
39/40 [============================>.] - ETA: 1s - loss: 0.3532 - acc: 0.8446Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.3520 - acc: 0.8455 - val_loss: 0.2921 - val_acc: 0.8825
Epoch 19/50
39/40 [============================>.] - ETA: 1s - loss: 0.3218 - acc: 0.8656Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.3227 - acc: 0.8655 - val_loss: 0.2735 - val_acc: 0.8925
Epoch 20/50
39/40 [============================>.] - ETA: 1s - loss: 0.3095 - acc: 0.8692Epoch 1/50
40/40 [==============================] - 55s 1s/step - loss: 0.3086 - acc: 0.8695 - val_loss: 0.2602 - val_acc: 0.8938
Epoch 21/50
39/40 [============================>.] - ETA: 1s - loss: 0.3015 - acc: 0.8703Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.3041 - acc: 0.8695 - val_loss: 0.2513 - val_acc: 0.8950
Epoch 22/50
39/40 [============================>.] - ETA: 1s - loss: 0.2952 - acc: 0.8692Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.2919 - acc: 0.8715 - val_loss: 0.2445 - val_acc: 0.9038
Epoch 23/50
39/40 [============================>.] - ETA: 1s - loss: 0.2959 - acc: 0.8795Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.2964 - acc: 0.8785 - val_loss: 0.2733 - val_acc: 0.8838
Epoch 24/50
39/40 [============================>.] - ETA: 1s - loss: 0.2775 - acc: 0.8872Epoch 1/50
40/40 [==============================] - 53s 1s/step - loss: 0.2780 - acc: 0.8865 - val_loss: 0.2452 - val_acc: 0.8963
Epoch 25/50
39/40 [============================>.] - ETA: 1s - loss: 0.2804 - acc: 0.8733Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.2796 - acc: 0.8755 - val_loss: 0.2435 - val_acc: 0.8950
Epoch 26/50
39/40 [============================>.] - ETA: 1s - loss: 0.2705 - acc: 0.8846Epoch 1/50
40/40 [==============================] - 53s 1s/step - loss: 0.2708 - acc: 0.8840 - val_loss: 0.2288 - val_acc: 0.9050
Epoch 27/50
39/40 [============================>.] - ETA: 1s - loss: 0.2504 - acc: 0.8974Epoch 1/50
40/40 [==============================] - 55s 1s/step - loss: 0.2518 - acc: 0.8955 - val_loss: 0.2360 - val_acc: 0.9075
Epoch 28/50
39/40 [============================>.] - ETA: 1s - loss: 0.2677 - acc: 0.8928Epoch 1/50
40/40 [==============================] - 55s 1s/step - loss: 0.2660 - acc: 0.8930 - val_loss: 0.2312 - val_acc: 0.9062
Epoch 29/50
39/40 [============================>.] - ETA: 1s - loss: 0.2491 - acc: 0.8985Epoch 1/50
40/40 [==============================] - 53s 1s/step - loss: 0.2473 - acc: 0.8995 - val_loss: 0.2353 - val_acc: 0.9000
Epoch 30/50
39/40 [============================>.] - ETA: 1s - loss: 0.2439 - acc: 0.8933Epoch 1/50
40/40 [==============================] - 55s 1s/step - loss: 0.2428 - acc: 0.8945 - val_loss: 0.2185 - val_acc: 0.9050
Epoch 31/50
39/40 [============================>.] - ETA: 1s - loss: 0.2446 - acc: 0.8949Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.2452 - acc: 0.8950 - val_loss: 0.2114 - val_acc: 0.9087
Epoch 32/50
39/40 [============================>.] - ETA: 1s - loss: 0.2354 - acc: 0.9041Epoch 1/50
40/40 [==============================] - 55s 1s/step - loss: 0.2373 - acc: 0.9035 - val_loss: 0.2612 - val_acc: 0.8900
Epoch 33/50
39/40 [============================>.] - ETA: 1s - loss: 0.2366 - acc: 0.9021Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.2354 - acc: 0.9030 - val_loss: 0.2396 - val_acc: 0.8988
Epoch 34/50
39/40 [============================>.] - ETA: 1s - loss: 0.2298 - acc: 0.9108Epoch 1/50
40/40 [==============================] - 55s 1s/step - loss: 0.2296 - acc: 0.9100 - val_loss: 0.2214 - val_acc: 0.9075
Epoch 35/50
39/40 [============================>.] - ETA: 1s - loss: 0.2046 - acc: 0.9236Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.2063 - acc: 0.9235 - val_loss: 0.2280 - val_acc: 0.9075
Epoch 36/50
39/40 [============================>.] - ETA: 1s - loss: 0.2243 - acc: 0.9026Epoch 1/50
40/40 [==============================] - 53s 1s/step - loss: 0.2254 - acc: 0.9030 - val_loss: 0.2043 - val_acc: 0.9162
Epoch 37/50
39/40 [============================>.] - ETA: 1s - loss: 0.2147 - acc: 0.9149Epoch 1/50
40/40 [==============================] - 53s 1s/step - loss: 0.2166 - acc: 0.9140 - val_loss: 0.2209 - val_acc: 0.9075
Epoch 38/50
39/40 [============================>.] - ETA: 1s - loss: 0.2039 - acc: 0.9200Epoch 1/50
40/40 [==============================] - 53s 1s/step - loss: 0.2046 - acc: 0.9195 - val_loss: 0.2039 - val_acc: 0.9187
Epoch 39/50
39/40 [============================>.] - ETA: 1s - loss: 0.1956 - acc: 0.9303Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.1961 - acc: 0.9300 - val_loss: 0.2028 - val_acc: 0.9175
Epoch 40/50
39/40 [============================>.] - ETA: 1s - loss: 0.2001 - acc: 0.9133Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.2003 - acc: 0.9130 - val_loss: 0.2182 - val_acc: 0.9100
Epoch 41/50
39/40 [============================>.] - ETA: 1s - loss: 0.2002 - acc: 0.9174Epoch 1/50
40/40 [==============================] - 55s 1s/step - loss: 0.2022 - acc: 0.9165 - val_loss: 0.2042 - val_acc: 0.9137
Epoch 42/50
39/40 [============================>.] - ETA: 1s - loss: 0.2038 - acc: 0.9133Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.2056 - acc: 0.9125 - val_loss: 0.1984 - val_acc: 0.9100
Epoch 43/50
39/40 [============================>.] - ETA: 1s - loss: 0.1927 - acc: 0.9205Epoch 1/50
40/40 [==============================] - 55s 1s/step - loss: 0.1944 - acc: 0.9200 - val_loss: 0.2045 - val_acc: 0.9175
Epoch 44/50
39/40 [============================>.] - ETA: 1s - loss: 0.1840 - acc: 0.9282Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.1832 - acc: 0.9290 - val_loss: 0.1975 - val_acc: 0.9150
Epoch 45/50
39/40 [============================>.] - ETA: 1s - loss: 0.1725 - acc: 0.9323Epoch 1/50
40/40 [==============================] - 55s 1s/step - loss: 0.1750 - acc: 0.9315 - val_loss: 0.2061 - val_acc: 0.9137
Epoch 46/50
39/40 [============================>.] - ETA: 1s - loss: 0.1860 - acc: 0.9215Epoch 1/50
40/40 [==============================] - 54s 1s/step - loss: 0.1848 - acc: 0.9220 - val_loss: 0.1954 - val_acc: 0.9175
Epoch 47/50
39/40 [============================>.] - ETA: 1s - loss: 0.1839 - acc: 0.9226Epoch 1/50
40/40 [==============================] - 53s 1s/step - loss: 0.1821 - acc: 0.9230 - val_loss: 0.2129 - val_acc: 0.9137
Epoch 48/50
39/40 [============================>.] - ETA: 1s - loss: 0.1706 - acc: 0.9318Epoch 1/50
40/40 [==============================] - 55s 1s/step - loss: 0.1712 - acc: 0.9315 - val_loss: 0.1956 - val_acc: 0.9162
Epoch 49/50
39/40 [============================>.] - ETA: 1s - loss: 0.1757 - acc: 0.9308Epoch 1/50
40/40 [==============================] - 55s 1s/step - loss: 0.1783 - acc: 0.9295 - val_loss: 0.1890 - val_acc: 0.9162
Epoch 50/50
39/40 [============================>.] - ETA: 1s - loss: 0.1622 - acc: 0.9395Epoch 1/50
40/40 [==============================] - 55s 1s/step - loss: 0.1627 - acc: 0.9395 - val_loss: 0.2017 - val_acc: 0.9187
<tensorflow.python.keras.callbacks.History at 0x7fe0c36f2ba8>
- As we can see the validation accuracy improved a bit by using this method of training.
- This approach works better when the given problem is very different from the images that the model is trained upon
| Data Size | Similar Dataset | Different Dataset |
|---|---|---|
| Smaller data | Fine-tune the output layers | Fine-tune the deeper layer |
| Bigger data | Fine-tune the whole model | Train from scratch |