Improve performance of class variables #2259
Conversation
… reading from the object
Co-authored-by: Tom Stuart <tom.stuart@shopify.com>
There was a problem hiding this comment.
This looks great in general, thank you for optimizing class variables.
One trade-off of using a DynamicObject for this is if new class variables are later added on in some class, we might get some Shape polymorphism, while a given access site would always access the same variable and name. OTOH, that doesn't seem so common for class variables, because class variables are often initialized in the module body, and rarely added later on to an existing class.
Another possibility here might be to have a Map<String name, ClassVariableStorage storage> (and ClassVariableStorage would be a class with a single volatile field value), and then look that one up once, and then directly read/write the storage object (similar to GlobalVariables/GlobalVariableStorage but simpler as there are no hooks).
That would require caching on the Module instance though (which is making things for Engine caching/AST sharing more complicated), while the current approach seems to not need it.
Using a DynamicObject also loses the volatile behavior of class variables, which is described in the proposal for a Ruby memory model. I'm not sure how important it is, but it seems unfortunate and potentially problematic to lose that.
We could restore that by storing an AtomicReference instead of directly the value in the DynamicObject. I think we should do that.
| this.classVariables, | ||
| key, | ||
| DynamicObjectLibrary.getUncached().getOrDefault(fromFields.classVariables, key, null)); | ||
| } |
There was a problem hiding this comment.
@woess Isn't there a more direct way to do a (shallow) copy of a DynamicObject?
There used to be DynamicObject#copy, but I see nothing similar in DynamicObjectLibrary.
src/main/java/org/truffleruby/language/objects/classvariables/ClassVariableStorage.java
Show resolved
Hide resolved
src/main/java/org/truffleruby/language/objects/classvariables/ClassVariableStorage.java
Outdated
Show resolved
Hide resolved
src/main/java/org/truffleruby/language/objects/classvariables/LookupClassVariableNode.java
Outdated
Show resolved
Hide resolved
...ain/java/org/truffleruby/language/objects/classvariables/LookupClassVariableStorageNode.java
Show resolved
Hide resolved
src/main/java/org/truffleruby/language/objects/classvariables/SetClassVariableNode.java
Outdated
Show resolved
Hide resolved
...rg/truffleruby/language/objects/classvariables/ResolveTargetModuleForClassVariablesNode.java
Show resolved
Hide resolved
db8e6f8 to
4648df1
Compare
I thought about that but if we wanted to avoid boxing we'd have to re-invent some of what
Is there a barrier we can insert after writes or around reads to get volatile back? |
c118208 to
63152d8
Compare
63152d8 to
ff467bd
Compare
Good point.
This might be useful: And we have a mapping of Unsafe fences here: However, I'm not sure modelling volatile accesses with fences is quite correct (e.g., https://shipilev.net/blog/2016/close-encounters-of-jmm-kind/#myth-barriers-are-sane). But probably our best option in this case to still avoid boxing. |
|
The object model uses |
Yes, there is
If the DynamicObject is never allocated then it doesn't matter, nothing else can access those fields anyway. |
|
Graal canonicalises the |
src/main/java/org/truffleruby/core/module/ModuleOperations.java
Outdated
Show resolved
Hide resolved
|
We have another issue: class variables might be mutated/accessed concurrently. We should synchronize writes, whenever the RubyModule is shared. We also need write barriers like it's done in ModuleOperations#setClassVariable. PropagateSharingNode can be used for that conveniently on the fast path. And all write accesses need to either use |
PullRequest: truffleruby/2424
|
Summing up after @eregon's fixes for synchronisation. Reading class variables is still fine - it gets a barrier but these only stop multiple reads collapsing and so in our example they don't even change the machine code. Writing class variables does add a lot of extra work for the synchronisation. Seems ok as it goes away in the single-threaded case.
;Comment 64: [stack overflow check]
;Comment 64: VERIFIED_ENTRY
0x1296e8560: mov dword ptr [rsp - 0x14000], eax
0x1296e8567: sub rsp, 0x28
;Comment 75: block B0 null
;Comment 75: 0 [rsi|QWORD[.], rdx|QWORD[.], rbp|QWORD] = LABEL numbPhis: 0 align: false label: ?
;Comment 75: 2 stack:16|QWORD = MOVE rbp|QWORD moveKind: QWORD
;Comment 75: FRAME_COMPLETE
0x1296e856b: mov qword ptr [rsp + 0x20], rbp
;Comment 80: 4 [stack:32|QWORD] = HOTSPOTLOCKSTACK frameMapBuilder: org.graalvm.compiler.lir.amd64.AMD64FrameMapBuilder@29318860 slotKind: QWORD
;Comment 80: 6 r11|QWORD[.] = HOTSPOTLOADOBJECTCONSTANT input: Object[ClassVariableStorage@1603407373]
;Comment 80: {Object[ClassVariableStorage@1603407373]}
0x1296e8570: movabs r11, 0x616e938a0
0x1296e857a: nop word ptr [rax + rax]
;Comment 96: 8 CMPCONSTBRANCH [r11|QWORD[.] + 12] trueDestinationProbability: 1.0 condition: = trueDestination: B0 -> B1 falseDestination: B0 -> B52 y: -559030611 size: DWORD inlinedY: NarrowOop[ShapeBasic@1296236027]
;Comment 96: {NarrowOop[ShapeBasic@1296236027]}
0x1296e8580: cmp dword ptr [r11 + 0xc], 0xc2da979a
0x1296e8588: jne 0x1296e88d5
;Comment 110: block B1 null
;Comment 110: 10 [] = LABEL numbPhis: 0 align: false label: ?
;Comment 110: 12 rax|DWORD[.] = MOV [rdx|QWORD[.] + 44] size: DWORD
0x1296e858e: mov eax, dword ptr [rdx + 0x2c]
;Comment 113: 14 CMPCONSTBRANCH [rax|DWORD[.] * 8 + 12] trueDestinationProbability: 1.0 condition: = trueDestination: B1 -> B2 falseDestination: B1 -> B51 y: 14 size: DWORD inlinedY: null
0x1296e8591: cmp dword ptr [rax*8 + 0xc], 0xe
0x1296e8599: jne 0x1296e8926
;Comment 127: block B2 null
;Comment 127: 16 [] = LABEL numbPhis: 0 align: false label: ?
;Comment 127: 18 rsi|DWORD[.] = MOV [rdx|QWORD[.] + 16] size: DWORD
0x1296e859f: mov esi, dword ptr [rdx + 0x10]
;Comment 130: 20 r10|DWORD[.] = MOV [rdx|QWORD[.] + 20] size: DWORD
0x1296e85a2: mov r10d, dword ptr [rdx + 0x14]
;Comment 134: 22 rbp|DWORD[.] = MOV [rdx|QWORD[.] + 24] size: DWORD
0x1296e85a6: mov ebp, dword ptr [rdx + 0x18]
;Comment 137: 24 r8|DWORD[.] = MOV [rdx|QWORD[.] + 28] size: DWORD
0x1296e85a9: mov r8d, dword ptr [rdx + 0x1c]
;Comment 141: 26 r9|DWORD[.] = MOV [rdx|QWORD[.] + 32] size: DWORD
0x1296e85ad: mov r9d, dword ptr [rdx + 0x20]
;Comment 145: 28 rcx|DWORD[.] = MOV [rdx|QWORD[.] + 36] size: DWORD
0x1296e85b1: mov ecx, dword ptr [rdx + 0x24]
;Comment 148: 30 rdx|DWORD[.] = MOV [rdx|QWORD[.] + 40] size: DWORD
0x1296e85b4: mov edx, dword ptr [rdx + 0x28]
;Comment 151: 32 rbx|QWORD = MOV [r11|QWORD[.]] size: QWORD
0x1296e85b7: mov rbx, qword ptr [r11]
;Comment 154: 34 rdi|QWORD = STACKLEA stack:32|QWORD
0x1296e85ba: lea rdi, [rsp + 0x10]
;Comment 159: 36 r13|QWORD = HOTSPOTLOADMETASPACECONSTANT input: meta{HotSpotType<Lorg/truffleruby/language/objects/classvariables/ClassVariableStorage;, resolved>}
;Comment 159: {meta{HotSpotType<Lorg/truffleruby/language/objects/classvariables/ClassVariableStorage;, resolved>}}
0x1296e85bf: movabs r13, 0x8402c8720
;Comment 169: 38 r13|QWORD = MOV [r13|QWORD + 184] size: QWORD
0x1296e85c9: mov r13, qword ptr [r13 + 0xb8]
;Comment 176: 40 r14|QWORD = OR (x: r15|QWORD, y: r13|QWORD) size: QWORD
0x1296e85d0: mov r14, r15
0x1296e85d3: or r14, r13
;Comment 182: 42 stack:40|QWORD = MOVE r13|QWORD moveKind: QWORD
0x1296e85d6: mov qword ptr [rsp + 8], r13
;Comment 187: 44 r13|QWORD = XOR (x: r14|QWORD, y: rbx|QWORD) size: QWORD
0x1296e85db: mov r13, r14
0x1296e85de: xor r13, rbx
;Comment 193: 46 rsi|QWORD[.] = UNCOMPRESSPOINTER (input: rsi|DWORD[.], ~baseRegister: r12|ILLEGAL) nonNull: false lirKindTool: org.graalvm.compiler.hotspot.amd64.AMD64HotSpotLIRKindTool@27106c4d encoding: base: 0 shift: 3
0x1296e85e1: shl rsi, 3
;Comment 197: 48 r10|QWORD[.] = UNCOMPRESSPOINTER (input: r10|DWORD[.], ~baseRegister: r12|ILLEGAL) nonNull: false lirKindTool: org.graalvm.compiler.hotspot.amd64.AMD64HotSpotLIRKindTool@27106c4d encoding: base: 0 shift: 3
0x1296e85e5: shl r10, 3
;Comment 201: 50 rbp|QWORD[.] = UNCOMPRESSPOINTER (input: rbp|DWORD[.], ~baseRegister: r12|ILLEGAL) nonNull: false lirKindTool: org.graalvm.compiler.hotspot.amd64.AMD64HotSpotLIRKindTool@27106c4d encoding: base: 0 shift: 3
0x1296e85e9: shl rbp, 3
;Comment 205: 52 r8|QWORD[.] = UNCOMPRESSPOINTER (input: r8|DWORD[.], ~baseRegister: r12|ILLEGAL) nonNull: false lirKindTool: org.graalvm.compiler.hotspot.amd64.AMD64HotSpotLIRKindTool@27106c4d encoding: base: 0 shift: 3
0x1296e85ed: shl r8, 3
;Comment 209: 54 r9|QWORD[.] = UNCOMPRESSPOINTER (input: r9|DWORD[.], ~baseRegister: r12|ILLEGAL) nonNull: false lirKindTool: org.graalvm.compiler.hotspot.amd64.AMD64HotSpotLIRKindTool@27106c4d encoding: base: 0 shift: 3
0x1296e85f1: shl r9, 3
;Comment 213: 56 rcx|QWORD[.] = UNCOMPRESSPOINTER (input: rcx|DWORD[.], ~baseRegister: r12|ILLEGAL) nonNull: false lirKindTool: org.graalvm.compiler.hotspot.amd64.AMD64HotSpotLIRKindTool@27106c4d encoding: base: 0 shift: 3
0x1296e85f5: shl rcx, 3
;Comment 217: 58 rdx|QWORD[.] = UNCOMPRESSPOINTER (input: rdx|DWORD[.], ~baseRegister: r12|ILLEGAL) nonNull: false lirKindTool: org.graalvm.compiler.hotspot.amd64.AMD64HotSpotLIRKindTool@27106c4d encoding: base: 0 shift: 3
0x1296e85f9: shl rdx, 3
;Comment 221: 60 rax|QWORD[.] = UNCOMPRESSPOINTER (input: rax|DWORD[.], ~baseRegister: r12|ILLEGAL) nonNull: false lirKindTool: org.graalvm.compiler.hotspot.amd64.AMD64HotSpotLIRKindTool@27106c4d encoding: base: 0 shift: 3
0x1296e85fd: shl rax, 3
;Comment 225: 62 TESTCONSTBRANCH r13|QWORD trueDestinationProbability: 0.99 condition: = trueDestination: B2 -> B28 falseDestination: B2 -> B4 y: -121 size: QWORD
0x1296e8601: test r13, -0x79
0x1296e8608: jne 0x1296e86b4
;Comment 238: block B28 null
;Comment 238: 294 [] = LABEL numbPhis: 0 align: false label: ?
;Comment 238: 296 CMPCONSTBRANCH [r11|QWORD[.] + 12] trueDestinationProbability: 1.0 condition: = trueDestination: B28 -> B29 falseDestination: B28 -> B50 y: -559030611 size: DWORD inlinedY: NarrowOop[ShapeBasic@1296236027]
;Comment 238: {NarrowOop[ShapeBasic@1296236027]}
0x1296e860e: cmp dword ptr [r11 + 0xc], 0xc2da979a
0x1296e8616: jne 0x1296e88f3
;Comment 252: block B29 null
;Comment 252: 298 [] = LABEL numbPhis: 0 align: false label: ?
;Comment 252: 300 MOV [r11|QWORD[.] + 24] y: 14 size: QWORD
0x1296e861c: mov qword ptr [r11 + 0x18], 0xe
;Comment 260: 302 r10|QWORD = MOV [r11|QWORD[.]] size: QWORD
0x1296e8624: mov r10, qword ptr [r11]
;Comment 263: 304 rax|QWORD = AND r10|QWORD y: 7 size: QWORD
0x1296e8627: mov rax, r10
0x1296e862a: and rax, 7
;Comment 270: 306 r8|QWORD[.] = HOTSPOTLOADOBJECTCONSTANT input: Object[14]
;Comment 270: {Object[14]}
0x1296e862e: movabs r8, 0x7bfb4a8d8
0x1296e8638: nop dword ptr [rax + rax]
;Comment 288: 308 CMPCONSTBRANCH rax|QWORD trueDestinationProbability: 0.9 condition: = trueDestination: B29 -> B30 falseDestination: B29 -> B31 y: 5 size: QWORD inlinedY: null
0x1296e8640: cmp rax, 5
0x1296e8644: jne 0x1296e8663
;Comment 298: block B30 null
;Comment 298: 310 [] = LABEL numbPhis: 0 align: false label: ?
;Comment 298: 312 rax|QWORD[.] = MOVE r8|QWORD[.] moveKind: QWORD
0x1296e864a: mov rax, r8
;Comment 301: 314 RETURN (savedRbp: stack:16|QWORD, value: rax|QWORD[.]) isStub: false requiresReservedStackAccessCheck: false thread: r15 scratchForSafepointOnReturn: rcx config: org.graalvm.compiler.hotspot.GraalHotSpotVMConfig@31053be4
0x1296e864d: mov rbp, qword ptr [rsp + 0x20]
0x1296e8652: add rsp, 0x28
0x1296e8656: mov rcx, qword ptr [r15 + 0x108]
;Comment 317: POLL_RETURN_FAR
0x1296e865d: test dword ptr [rcx], eax
0x1296e865f: vzeroupper
0x1296e8662: ret |
|
FYI since I am also looking into this... The JRuby instance variable numbers are greatly skewed in the original benchmark since we do not (yet) inline through the proc.call from BIPS. With the loop moved into the benchmark and run on an equivalent JIT (Graal JIT on Java 15 in this case) the numbers look quite different: JRuby: vs MRI: vs TruffleRuby: Using BIPS as in the original benchmark (very small bodies of code, iteration outside of the block) skews this comparison tremendously, since TR optimizes the outer loop along with the benchmark bodies and the other impls do not. Of course the class var numbers on JRuby do not change substantially with the modified benchmark, but we do no optimization of class variables yet. |
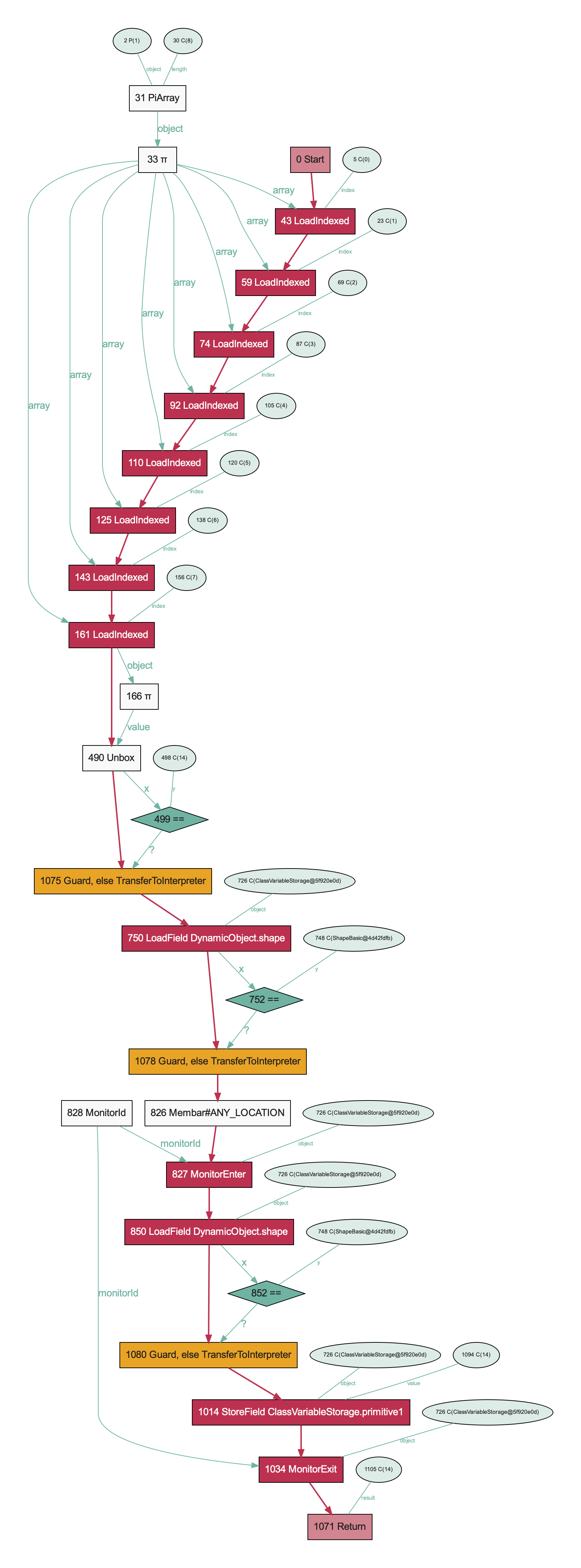
Someone asked me how TruffleRuby optimised class variables. I went to check and was surprised to find it completely unoptimised. By pulling out a few fast-paths from the code behind boundaries and switching the data structure used to store the class variables I've managed to significantly improve performance for a few common cases.
Before:
After:
Difference:
Compared to MRI:
Compared to JRuby:
What have I done?
What does it look like?
For example, a simple class variable read in an instance method.
This ends up as this graph. The class variable storage object can be turned into a constant, coming from the method's lexical scope at the point it was defined. We can then read the shape of the class variable storage and check it against an expected shape using an identity comparison. If that fails, we deoptimise. We can then cache the location within the storage of the class variable, so that becomes nothing more than a field read.
So a class variable read from an instance method of the class defining the class variable can be as simple as:
What else could we do:
If we find interesting cases not covered by these fast paths, such as particular patterns of using class variables from superclasses or extended modules, we can probably add those for up to a couple of levels of indirection fairly easily.
Benchmark: