-
Notifications
You must be signed in to change notification settings - Fork 829
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
11 changed files
with
2,765 additions
and
21 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,29 @@ | ||
| # Screen Parsing with OmniParser and OpenVINO | ||
|
|
||
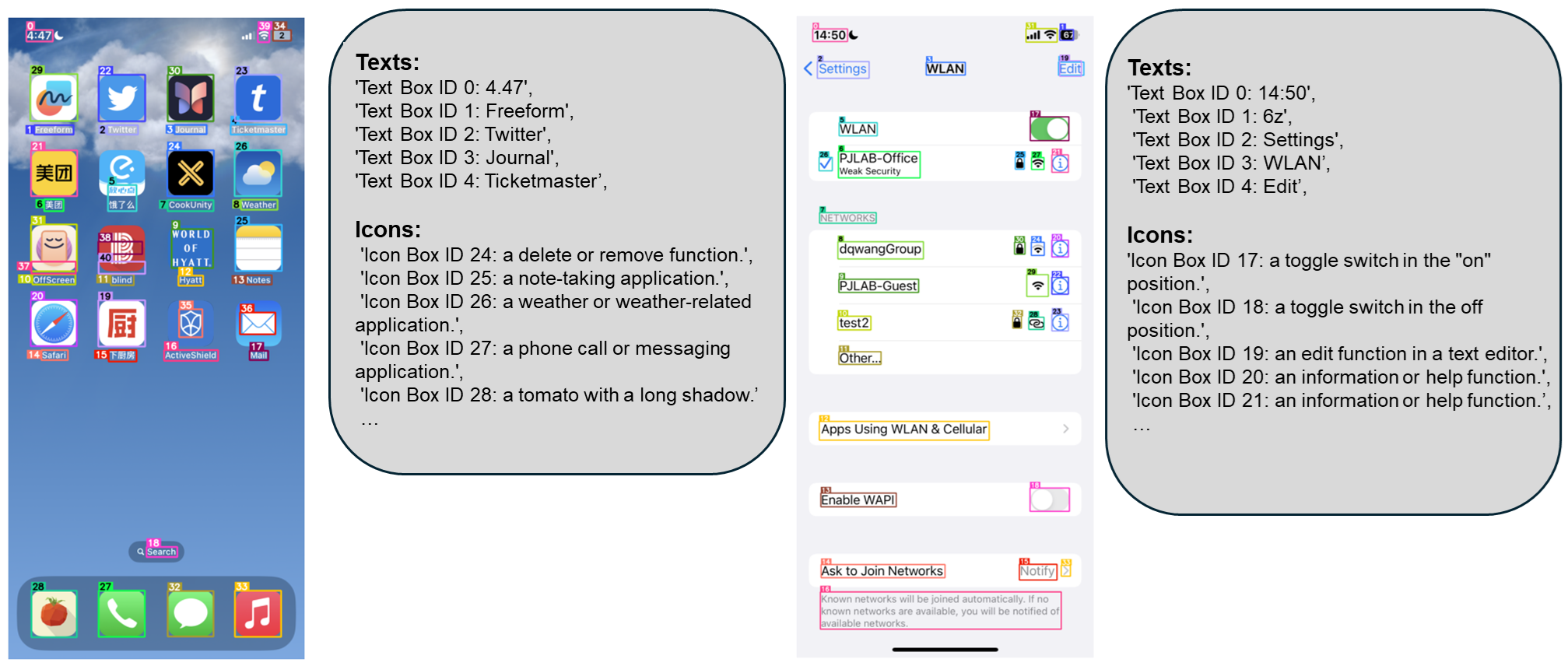
| Recent breakthrough in Visual Language Processing and Large Language models made significant strides in understanding and interacting with the world through text and images. However, accurately parsing and understanding complex graphical user interfaces (GUIs) remains a significant challenge. | ||
| [OmniParser](https://microsoft.github.io/OmniParser/) is a comprehensive method for parsing user interface screenshots into structured and easy-to-understand elements. This enables more accurate and efficient interaction with GUIs, empowering AI agents to perform tasks across various platforms and applications. | ||
|
|
||
|  | ||
|
|
||
| More details about model can be found in [Microsoft blog post](https://www.microsoft.com/en-us/research/articles/omniparser-for-pure-vision-based-gui-agent/), [paper](https://arxiv.org/pdf/2408.00203), [original repo](https://github.com/microsoft/OmniParser) and [model card](https://huggingface.co/microsoft/OmniParser). | ||
|
|
||
| In this tutorial we consider how to run OmniParser using OpenVINO. | ||
|
|
||
| # Notebook contents | ||
| The tutorial consists from following steps: | ||
|
|
||
| - Install requirements | ||
| - Convert model | ||
| - Run OpenVINO model inference | ||
| - Launch Interactive demo | ||
|
|
||
| In this demonstration, you'll try to run OmniParser for recognition of UI elements on screenshots. | ||
|
|
||
|
|
||
| ## Installation instructions | ||
| This is a self-contained example that relies solely on its own code.</br> | ||
| We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. | ||
| For details, please refer to [Installation Guide](../../README.md). | ||
|
|
||
| <img referrerpolicy="no-referrer-when-downgrade" src="https://static.scarf.sh/a.png?x-pxid=5b5a4db0-7875-4bfb-bdbd-01698b5b1a77&file=notebooks/florence2/README.md" /> | ||
| <img referrerpolicy="no-referrer-when-downgrade" src="https://static.scarf.sh/a.png?x-pxid=5b5a4db0-7875-4bfb-bdbd-01698b5b1a77&file=notebooks/omniparser/README.md" /> |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,50 @@ | ||
| from pathlib import Path | ||
| import requests | ||
| from PIL import Image | ||
| import gradio as gr | ||
|
|
||
| MARKDOWN = """ | ||
| # OpenVINO OmniParser for Pure Vision Based General GUI Agent 🔥 | ||
| OmniParser is a screen parsing tool to convert general GUI screen to structured elements. | ||
| """ | ||
|
|
||
| example_images = [ | ||
| ("https://github.com/microsoft/OmniParser/blob/master/imgs/windows_home.png?raw=true", "examples/windows_home.png"), | ||
| ("https://github.com/microsoft/OmniParser/blob/master/imgs/logo.png?raw=true", "examples/logo.png"), | ||
| ("https://github.com/microsoft/OmniParser/blob/master/imgs/windows_multitab.png?raw=true", "examples/multitab.png"), | ||
| ] | ||
|
|
||
|
|
||
| def make_demo(process_fn): | ||
| examples_dir = Path("examples") | ||
| examples_dir.mkdir(exist_ok=True, parents=True) | ||
| for url, filename in example_images: | ||
| if not Path(filename).exists(): | ||
| image = Image.open(requests.get(url, stream=True).raw) | ||
| image.save(filename) | ||
|
|
||
| with gr.Blocks() as demo: | ||
| gr.Markdown(MARKDOWN) | ||
| with gr.Row(): | ||
| with gr.Column(): | ||
| image_input_component = gr.Image(type="filepath", label="Upload image") | ||
| # set the threshold for removing the bounding boxes with low confidence, default is 0.05 | ||
| box_threshold_component = gr.Slider(label="Box Threshold", minimum=0.01, maximum=1.0, step=0.01, value=0.05) | ||
| # set the threshold for removing the bounding boxes with large overlap, default is 0.1 | ||
| iou_threshold_component = gr.Slider(label="IOU Threshold", minimum=0.01, maximum=1.0, step=0.01, value=0.1) | ||
| imgsz_component = gr.Slider(label="Icon Detect Image Size", minimum=640, maximum=1920, step=32, value=640) | ||
| submit_button_component = gr.Button(value="Submit", variant="primary") | ||
| with gr.Column(): | ||
| image_output_component = gr.Image(type="pil", label="Image Output") | ||
| text_output_component = gr.Textbox(label="Parsed screen elements", placeholder="Text Output") | ||
| gr.Examples( | ||
| examples=list(Path("examples").glob("*.png")), | ||
| inputs=[image_input_component], | ||
| label="Try examples", | ||
| ) | ||
| submit_button_component.click( | ||
| fn=process_fn, | ||
| inputs=[image_input_component, box_threshold_component, iou_threshold_component, imgsz_component], | ||
| outputs=[image_output_component, text_output_component], | ||
| ) | ||
| return demo |
Oops, something went wrong.