btl/vader performance regression (that can be observed on fat nodes) #8603
Description
Following the discussion on the ML related to a performance regression between Open MPI 3.1.1 and 4.1.0,
here are my findings:
The performance regression can be observed on fat nodes with the fftw builtin benchmark and the following command line
mpirun --map-by core --rank-by core --bind-to core --mca pml ob1 --mca btl vader,self ./mpi-bench -opatient -r1000 -s icf1000000
git bisect pointed me to 7c8a1fb437
I ran this on a quad socket intel node with 18 cores per socket.
At 112 cores, the degradation is over 15%
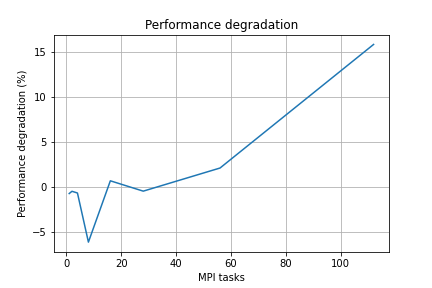
If I read the commit message between the lines, the workaround that is needed for gcc < 6 was applied on all x86_64 based on the assumption it does not introduce any performance penalty.
The data above show otherwise, so we might want to improve this, for example by only applying the workaround for gcc < 6, or by not applying it for gcc >= 6 (depending on how we want to treat non GNU compilers)
@hjelmn could you please comment on this issue?