{kind=link}
Ce repository fournit une implémentation du papier : Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. Ce code est une adapatation de l'implémentation open-source proposée par l'utilisateur hengyuan-yu.
Le code de ce repository peut être directement utilisé sur ce colab. Le fichier ipynb correspondant est accessible ici.
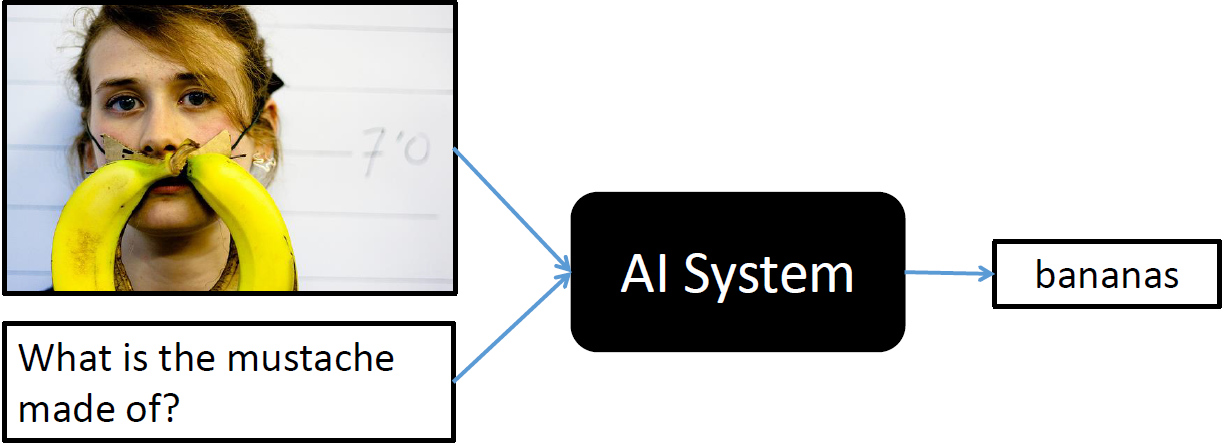
Le Visual Question Answering (VQA) est une discipline informatique où la machine doit répondre à une question formée en langage naturel (et non pas en mots-clés) à propos d'une scène visuelle. L'entrée du modèle est donc une question et une image, la sortie est une classe qui correspond a un mot ou un groupe de mots (i.e. il existe la classe "pomme" et la classe "feu rouge").
Python3.6
torch 1.1.0
torchvision 0.2.2
Pillow 6.0.0
tqdm
Dézipper data.zip dans le dossier data
| GPU | CPU | RAM | |
|---|---|---|---|
| Training | 10h | - | 50 Go |
| Prediction | 6s | - | 1Mo |
Premièrement, télécharger les images MSCOCO train2014 et val2014 et placer les dossiers dézippés dans "data".
Ensuite, on peut lancer un nouvel entrainement avec la commande suivante :
python main.py
L'entrainement s'arrête automatiquement après 5 epochs sans amélioration. Le meilleur checkpoint sera stocké dans le dossier "ckpt".
L'évaluation est possibile avec la commande suivante. Le fichier pré-entrainé est fourni dans ce repository.
python main.py --eval True --ckpt ckpt/model_0.5590.pth
La sortie devrait être:
loading dictionary from data/dictionary.pkl
Loading data/val_resnet_layer3.pkl
eval score: 55.90 (92.66)
Ce qui signifie une précision de bonne réponse à 56%. Plus en détail, voici les sous-scores:
| Yes/No | Number | Other | Overall |
|---|---|---|---|
| 76.6% | 36.2% | 49.5% | 55.90% |
Il faut noter que les mauvaises réponses ne sont pas forcément médiocres ou absurdes. Répondre fille au lieu de femme n'est pas correct mais n'est pas trop mauvais, selon l'utilisation qu'on veut faire du modèle.
Il est possible d'utiliser le modèle sur ses propres données. Voici la commande a utiliser avec le fichier example.jpg fourni dans ce repository:
python main.py --inference True \
--ckpt ckpt/model_0.5590.pth \
--image example.jpg \
--question "What is the man holding ?"

La sortie est :
loading dictionary from data/dictionary.pkl
Question: What is the man holding ?
Answer: banana
D'autres exemples :
loading dictionary from data/dictionary.pkl
Question: What is the color of the man's hair ?
Answer: brown
loading dictionary from data/dictionary.pkl
Question: Is the man handsome and smart ?
Answer: yes