For Huawei Certified ICT Associate Competition 2021 AI Track - Indonesia (UKPetra) October 29th 2021
Second Place - 95% Accuracy

- Rebar Counting Computer Vision using Faster RCNN with ResNet-50 Pretrained Backbone
- Table of Contents
- Team Members (UKPetra)
- Prerequisites
- Datasets
- Code Breakdown
- PyTorch and Pycocotools Installation and Initialization
- Downloading Train and Test Datasets
- Downloading and Extracting PyTorch Vision API Coco Helpers
- Previewing the Dataset
- Creating PyTorch Dataset Class for Rebar Dataset
- Creating Faster RCNN Object Detection Model with Pretrained ResNet50 Backbone
- Loading the Dataset and Applying Data Augmentation
- Creating the Optimizer and Learning Rate Scheduler
- Training the Model
- Loading the Best Model State and Previewing the Model Detection
- Results
-
Dr. Ing. Indar Sugiarto, S.T., M.Sc. (Mentor)
-
Nicholas Sebastian Veron
-
Vincent Darmawan
-
Yoshua Kaleb Purwanto
- Python >= 3.6
- Pillow
- Numpy
- Request
- Matplotlib
- Open CV - Python
- Pycocotools API 2.0.4
- PyTorch Vision API 0.6.0
- PyTorch 1.4.0 with torchvision 0.5.0
- CUDA & cudatoolkit 9.2 (optional)
First, we install PyTorch 1.4.0 with torchvision 0.5.0 to the current python kernel (assuming numpy, pillow, request, matplotlib, and cv2 are already installed).
# import pytorch ver 1.4.0 and pycocotools
%pip install torch==1.4.0 torchvision==0.5.0 -f https://download.pytorch.org/whl/torch_stable.html
%pip install pycocotools
import torch
import torchvision
import pycocotools.cocoeval
if torch.__version__.count("1.4.0") == 0:
print("This code uses pytorch 1.4.0!")
assert False
DEVICE = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')This part of code ensures that it has the correct version of PyTorch, otherwise it will stop the program.
if torch.__version__.count("1.4.0") == 0:
print("This code uses pytorch 1.4.0!")
assert FalseThen it checks if CUDA is available or not, if CUDA is not available then CPU will be used as processing device.
DEVICE = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')Next, we download "Rebar Count" training and test datasets from Huawei Cloud Bucket, extracts it, and deletes it to clear up storage space.
# download training and test data
import os
import requests
import zipfile
import shutil
if not os.path.exists('./rebar_count_datasets'):
print('Downloading code and datasets...')
url = 'https://cnnorth4-modelhub-datasets-obsfs-sfnua.obs.cn-north-4.myhuaweicloud.com/content/c2c1853f-d6a6-4c9d-ac0e-203d4c304c88/NkxX5K/dataset/rebar_count_datasets.zip'
r = requests.get(url, allow_redirects=True)
open('./rebar_count_datasets.zip', 'wb').write(r.content)
with zipfile.ZipFile('./rebar_count_datasets.zip', 'r') as zip_ref:
zip_ref.extractall('./')
if os.path.exists('./v0.6.0.zip'):
os.remove('./v0.6.0.zip')
if os.path.exists('./rebar_count_datasets'):
print('Download code and datasets success')
else:
print('Download code and datasets failed, please check the download url is valid or not.')
else:
print('./rebar_count_datasets already exists')It will check if the datasets already exists so that it does not waste time and bandwidth downloading the same datasets again.
if not os.path.exists('./rebar_count_datasets'):
•••
else:
print('./rebar_count_datasets already exists')We chose to use os, shutil, request, and zipfile other than os.system("wget, rm, unzip, cp, etc..") (or the ! prefix in jupyter notebook) so that the code can run regardless of the operating system. Using os.system("...") (or the ! prefix in jupyter notebook) will limit our code to run only on linux based systems.
url = 'https://cnnorth4-modelhub-datasets-obsfs-sfnua.obs.cn-north-4.myhuaweicloud.com/content/c2c1853f-d6a6-4c9d-ac0e-203d4c304c88/NkxX5K/dataset/rebar_count_datasets.zip'
r = requests.get(url, allow_redirects=True)
open('./rebar_count_datasets.zip', 'wb').write(r.content)
with zipfile.ZipFile('./rebar_count_datasets.zip', 'r') as zip_ref:
zip_ref.extractall('./')
if os.path.exists('./v0.6.0.zip'):
os.remove('./v0.6.0.zip')Next, we download PyTorch Vision API Coco Helpers for training coco-type datasets, it has custom transforms and useful utilities to help training coco-type datasets. We specifically chose version 0.6.0 because it is the version that works with torchvision 0.5.0.
url = 'https://github.com/pytorch/vision/archive/refs/tags/v0.6.0.zip'
r = requests.get(url, allow_redirects=True)
open('./v0.6.0.zip', 'wb').write(r.content)
with zipfile.ZipFile('./v0.6.0.zip', 'r') as zip_ref:
zip_ref.extractall('./')
if os.path.exists('./v0.6.0.zip'):
os.remove('./v0.6.0.zip')
shutil.copyfile("./vision-0.6.0/references/detection/utils.py", "./utils.py")
shutil.copyfile("./vision-0.6.0/references/detection/transforms.py", "./transforms.py")
shutil.copyfile("./vision-0.6.0/references/detection/coco_eval.py", "./coco_eval.py")
shutil.copyfile("./vision-0.6.0/references/detection/engine.py", "./engine.py")
shutil.copyfile("./vision-0.6.0/references/detection/coco_utils.py", "./coco_utils.py")
import transforms as T
def get_transform(train):
transforms = []
transforms.append(T.ToTensor())
if train:
transforms.append(T.RandomHorizontalFlip(0.5))
return T.Compose(transforms)After extracting and moving the files into appropriate folder, we make a function to help with coco-type dataset data augmentation.
import transforms as T
def get_transform(train):
transforms = []
transforms.append(T.ToTensor())
if train:
transforms.append(T.RandomHorizontalFlip(0.5))
return T.Compose(transforms)
Next, we preview the dataset by loading the picture and drawing a rectangle on where the dataset thinks there is a rebar, and display it using matplotplib pyplot.
# inspecting dataset
import xml.etree.ElementTree as ET
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import cv2
def read_xml(xml_path):
tree = ET.parse(xml_path)
root = tree.getroot()
boxes = []
labels = []
for element in root.findall('object'):
label = element.find('name').text
if label == 'steel':
bndbox = element.find('bndbox')
xmin = bndbox.find('xmin').text
ymin = bndbox.find('ymin').text
xmax = bndbox.find('xmax').text
ymax = bndbox.find('ymax').text
boxes.append([xmin, ymin, xmax, ymax])
labels.append(label)
return np.array(boxes, dtype=np.float64), labels
train_img_dir = './rebar_count_datasets/VOC2007/JPEGImages'
train_xml_dir = './rebar_count_datasets/VOC2007/Annotations'
files = os.listdir(train_img_dir)
files.sort()
for index, file_name in enumerate(files[:2]):
img_path = os.path.join(train_img_dir, file_name)
xml_path = os.path.join(train_xml_dir, file_name.split('.jpg')[0]+'.xml')
boxes, labels = read_xml(xml_path)
img = Image.open(img_path)
resize_scale = 2048.0 / max(img.size)
img = img.resize((int(img.size[0] * resize_scale), int(img.size[1] * resize_scale)))
boxes *= resize_scale
plt.figure(figsize=(img.size[0]/100.0, img.size[1]/100.0))
plt.subplot(2,1,1)
plt.imshow(img)
img = img.convert('RGB')
img = np.array(img)
img = img.copy()
for box in boxes:
xmin, ymin, xmax, ymax = box.astype(np.int)
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), (0, 255, 0), thickness=3)
plt.subplot(2,1,2)
plt.imshow(img)
plt.show()We also created a function that reads the bounding box for each rebar in a picture from an .xml file using python xml module, then return a tuple of numpy array of [xmin, ymin, xmax, ymax] and the bounding box label (in this case it is only steel).
def read_xml(xml_path):
tree = ET.parse(xml_path)
root = tree.getroot()
boxes = []
labels = []
for element in root.findall('object'):
label = element.find('name').text
if label == 'steel':
bndbox = element.find('bndbox')
xmin = bndbox.find('xmin').text
ymin = bndbox.find('ymin').text
xmax = bndbox.find('xmax').text
ymax = bndbox.find('ymax').text
boxes.append([xmin, ymin, xmax, ymax])
labels.append(label)
return np.array(boxes, dtype=np.float64), labelsNext we created class inherited from PyTorch Dataset class called RebarDataset to allow data to loaded using PyTorch DataLoader, it simplifies the training and test process by grouping all bounding boxes and the picture together.
# creating pytorch dataset for rebar
class RebarDataset(torch.utils.data.Dataset):
def __init__(self, root, transforms=None):
self.root = root
self.transforms = transforms
self.imgs = list(sorted(os.listdir(os.path.join(root, "JPEGImages"))))
if ".ipynb_checkpoints" in self.imgs:
self.imgs.remove(".ipynb_checkpoints")
def __getitem__(self, idx):
img_path = os.path.join(self.root, "JPEGImages", self.imgs[idx])
box_path = os.path.join(self.root, "Annotations", self.imgs[idx].split(".")[0]+'.xml')
img = Image.open(img_path).convert("RGB")
boxes,_ = read_xml(box_path)
boxes = torch.as_tensor(boxes, dtype=torch.float32 , device = DEVICE)
labels = torch.ones((len(boxes),), dtype=torch.int64 , device = DEVICE)
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
iscrowd = torch.zeros((len(boxes),), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = torch.tensor([idx], device = DEVICE)
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.imgs)When an instance of RebarDataset is created, it stores the root of the folder and the transformations that will be applied, it also looks for all images in "JPEGImages" folder and stores it in a list.
def __init__(self, root, transforms=None):
self.root = root
self.transforms = transforms
self.imgs = list(sorted(os.listdir(os.path.join(root, "JPEGImages"))))
if ".ipynb_checkpoints" in self.imgs:
self.imgs.remove(".ipynb_checkpoints")Then when the __getitem__ operator ( [] ) is called, it loads the image and the corresponding bounding box data, stores it in a dictionary, and returns a tuple of image and dictionary of image details (bounding boxes, labels, imageid, and area). "Iscrowd" will be ignored and defaults to bunch of zeros.
def __getitem__(self, idx):
img_path = os.path.join(self.root, "JPEGImages", self.imgs[idx])
box_path = os.path.join(self.root, "Annotations", self.imgs[idx].split(".")[0]+'.xml')
img = Image.open(img_path).convert("RGB")
boxes,_ = read_xml(box_path)
boxes = torch.as_tensor(boxes, dtype=torch.float32 , device = DEVICE)
labels = torch.ones((len(boxes),), dtype=torch.int64 , device = DEVICE)
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
iscrowd = torch.zeros((len(boxes),), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = torch.tensor([idx], device = DEVICE)
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, targetNext, we created a pretrained Faster RCNN model from torchvision models module and set some parameters.
# load faster rcnn model pretrained with resnet50 backbone
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(
pretrained=True,
progress=True,
)
num_classes = 2 # 1 rebar + background
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
model.roi_heads.detections_per_img=500 # max object detection
pycocotools.cocoeval.Params.setDetParams.maxDets = [5, 50, 500]
model.to(DEVICE)The number of classes is set to 2 because we are trying to differentiate between background (no rebar) and a rebar. Then we set the model's predictor to the built in FastRCNNPredictor from torchvision models module with the amount of in features of the FastRCNN ResNet50 and number of class of 2.
num_classes = 2 # 1 rebar + background
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes) After that we set the detection parameters for the model and pycocotools cocoeval to 5 big detections, 50 medium detections and 500 small detections respectively. We set the small detections to 500 because the rebar cross section that we are trying to detect is pretty small compared to the whole image.
model.roi_heads.detections_per_img=500 # max object detection
pycocotools.cocoeval.Params.setDetParams.maxDets = [5, 50, 500]Then we move the model to the GPU (if available).
model.to(DEVICE)Next step, we load the dataset and the augmentation functon that we made before, splits the dataset to train and test datasets, and then we created a PyTorch DataLoader instance for each datasets.
# load dataset and split the dataset
train_dataset = RebarDataset("./rebar_count_datasets/VOC2007/",get_transform(True))
test_dataset = RebarDataset("./rebar_count_datasets/VOC2007/",get_transform(False))
indices = torch.randperm(len(train_dataset)).tolist()
# 80 - 20 split
train_dataset = torch.utils.data.Subset(train_dataset, indices[:-50]) #200
test_dataset = torch.utils.data.Subset(test_dataset, indices[-50:]) #50
# create data loaders
import utils
train_data_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=2, shuffle=True,
collate_fn=utils.collate_fn)
test_data_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=1, shuffle=False,
collate_fn=utils.collate_fn)We enabled the augmentation functon on the training dataset, but not on the test dataset.
train_dataset = RebarDataset("./rebar_count_datasets/VOC2007/",get_transform(True))
test_dataset = RebarDataset("./rebar_count_datasets/VOC2007/",get_transform(False))We used PyTorch randperm function to generate a list of indices that we use to split the dataset to 80%-20% (train-test) using Pytorch Data Utility Subset function.
indices = torch.randperm(len(train_dataset)).tolist()
# 80 - 20 split
train_dataset = torch.utils.data.Subset(train_dataset, indices[:-50]) #200
test_dataset = torch.utils.data.Subset(test_dataset, indices[-50:]) #50We created a PyTorch DataLoader instance for each datasets. We enabled shuffling for the training data and we used a batch size of 2 for training data and 1 for test data. Small batch size is used to minimize the amount of epoch required for training. Collate function from the PyTorch Vision API Coco Helpers utils module is used as the collate function of the DataLoader.
import utils
train_data_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=2, shuffle=True,
collate_fn=utils.collate_fn)
test_data_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=1, shuffle=False,
collate_fn=utils.collate_fn)Next, we used Adam and StepLR from PyTorch optimizer module as the optimizer and the learning rate scheduler. We set the initial learning rate to 3x10-4 and every iteration the learning rate will be reduced by the factor of 0.06.
# create optimizer and learning rate scheduler
from torch.optim.lr_scheduler import StepLR
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.Adam(params, lr=3e-4)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=1,
gamma=0.06)Next we trained the model that we created before with the train and test datasets that we had processed using the helper functions from PyTorch Vision API engine module and the optimizer and the learning rate scheduler we created before. Then we save the model for each epoch to "./model" folder.
# train the model and save every epoch
from engine import train_one_epoch,evaluate
if os.path.exists("./model"):
shutil.rmtree("./model")
os.makedirs("./model")
num_epochs = 4
model.to(DEVICE)
for epoch in range(num_epochs):
# train for one epoch, printing every 10 iterations
train_one_epoch(model, optimizer, train_data_loader, DEVICE, epoch, print_freq=10)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
evaluate(model, test_data_loader, device=DEVICE)
path = os.path.join("./model", f'model_{epoch}.pth')
torch.save(model.cpu().state_dict(), path) # saving model
# moving model to GPU for further training
model.to(DEVICE)We first removed the previous "./model" folder if available, and then created an new one. We set the number of epoch to 4 and moved the model to GPU (if available).
if os.path.exists("./model"):
shutil.rmtree("./model")
os.makedirs("./model")
num_epochs = 4
model.to(DEVICE)Then for each epoch it trains the model using PyTorch Vision API engine module train_one_epoch function, steps the learning rate scheduler and evaluates the model using PyTorch Vision API engine module evaluate function.
# train for one epoch, printing every 10 iterations
train_one_epoch(model, optimizer, train_data_loader, DEVICE, epoch, print_freq=10)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
evaluate(model, test_data_loader, device=DEVICE)To save a model to a file, PyTorch requires the model to be moved to the CPU first, so it moves the model to the CPU, saves the model using PyTorch save function and then moves the model back to GPU (if available).
path = os.path.join("./model", f'model_{epoch}.pth')
torch.save(model.cpu().state_dict(), path) # saving model
# moving model to GPU for further training
model.to(DEVICE)Finally, we loaded the last saved model, and tested our model and displayed the results.
# load last epoch
import torch
if torch.__version__.count("1.4.0") == 0:
print("This code uses pytorch 1.4.0!")
assert False
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
import os
from PIL import Image, ImageDraw
import numpy
import matplotlib.pyplot as plt
import cv2
import random
DEVICE = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
num_classes = 2 # 1 rebar + background
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(
pretrained=True,
progress=True,
)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
model.roi_heads.detections_per_img=500 # max object detection
model.to(DEVICE)
trained_models = os.listdir('./model')
latest_epoch = -1
for model_name in trained_models:
if not model_name.endswith('pth'):
continue
epoch = float(model_name.split('_')[1].split('.pth')[0])
if epoch > latest_epoch:
latest_epoch = epoch
best_model_name = model_name
best_model_path = os.path.join('./model', best_model_name)
print('Loading model from', best_model_path)
model.load_state_dict(torch.load(best_model_path))
model.eval()
test_img_dir = r'./rebar_count_datasets/test_dataset'
files = os.listdir(test_img_dir)
random.shuffle(files)
if ".ipynb_checkpoints" in files:
files.remove(".ipynb_checkpoints")
for i, file_name in enumerate(files[:15]):
image_src = Image.open(os.path.join(test_img_dir, file_name)).convert("RGB")
img_tensor = torchvision.transforms.ToTensor()(image_src)
img_tensor
with torch.no_grad():
result_dict = model([img_tensor.to(DEVICE)])
bbox = result_dict[0]["boxes"].cpu().numpy()
scrs = result_dict[0]["scores"].cpu().numpy()
image_draw = numpy.array(image_src.copy())
rebar_count = 0
for bbox,scr in zip(bbox,scrs):
if len(bbox) > 0:
if scr > 0.65:
pt = bbox
cv2.circle(image_draw, (int((pt[0] + pt[2]) * 0.5), int((pt[1] + pt[3]) * 0.5)), int((pt[2] - pt[0]) * 0.5 * 0.6), (255, 0, 0), -1)
rebar_count += 1
cv2.putText(image_draw, 'rebar_count: %d' % rebar_count, (25, 50), cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 255, 0), 3)
plt.figure(i, figsize=(30, 20))
plt.imshow(image_draw)
plt.show()We created the test model with same configuration as the training model.
num_classes = 2 # 1 rebar + background
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(
pretrained=True,
progress=True,
)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
model.roi_heads.detections_per_img=500 # max object detection
model.to(DEVICE)We iterated for each file in "./model" folder that ends with ".pth" and searched for the model with the largest epoch.
trained_models = os.listdir('./model')
latest_epoch = -1
for model_name in trained_models:
if not model_name.endswith('pth'):
continue
epoch = float(model_name.split('_')[1].split('.pth')[0])
if epoch > latest_epoch:
latest_epoch = epoch
best_model_name = model_name
best_model_path = os.path.join('./model', best_model_name)
print('Loading model from', best_model_path)We load the model weights to the test model and set the model to evaluation mode to prevent changes of the model weights.
model.load_state_dict(torch.load(best_model_path))
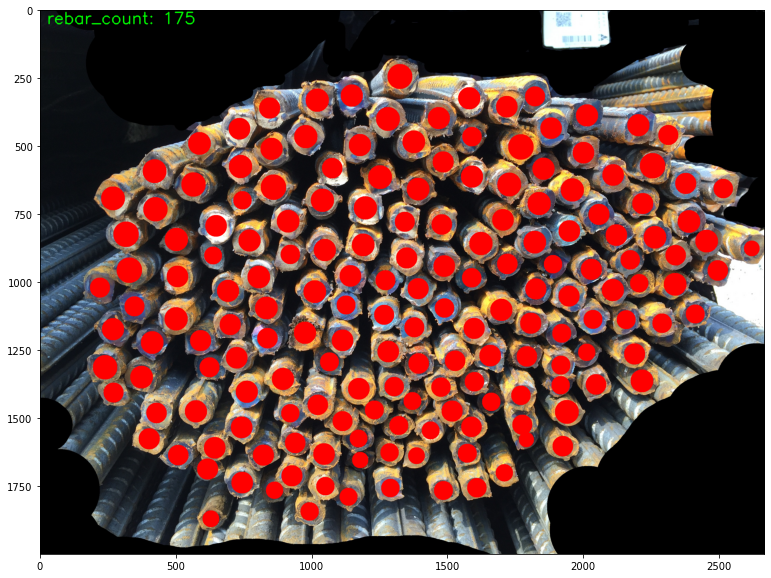
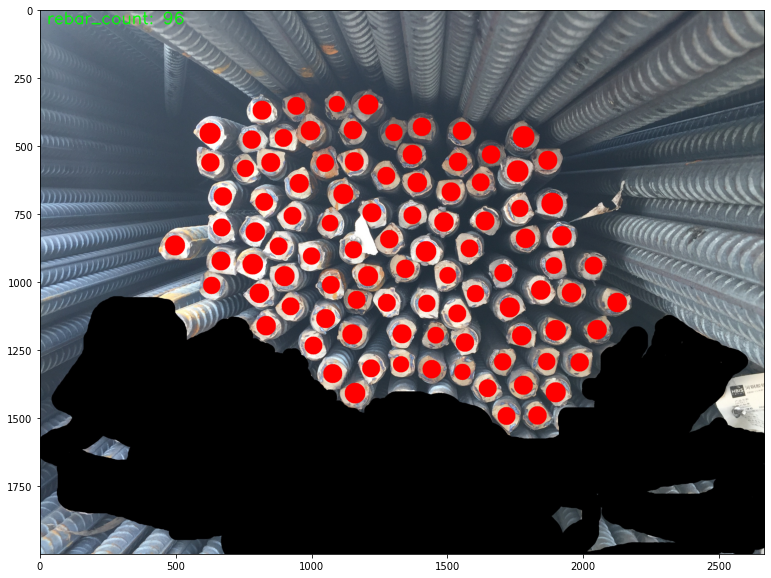
model.eval()We then tested the model on some rebar images that the model has not seen. Moved the output to CPU, converted it from tensor to bounding boxes, added dots for each boxes to the images, and displayed the images using matplotplib pyplot.
test_img_dir = r'./rebar_count_datasets/test_dataset'
files = os.listdir(test_img_dir)
random.shuffle(files)
if ".ipynb_checkpoints" in files:
files.remove(".ipynb_checkpoints")
for i, file_name in enumerate(files[:15]):
image_src = Image.open(os.path.join(test_img_dir, file_name)).convert("RGB")
img_tensor = torchvision.transforms.ToTensor()(image_src)
img_tensor
with torch.no_grad():
result_dict = model([img_tensor.to(DEVICE)])
bbox = result_dict[0]["boxes"].cpu().numpy()
scrs = result_dict[0]["scores"].cpu().numpy()
image_draw = numpy.array(image_src.copy())
rebar_count = 0
for bbox,scr in zip(bbox,scrs):
if len(bbox) > 0:
if scr > 0.65:
pt = bbox
cv2.circle(image_draw, (int((pt[0] + pt[2]) * 0.5), int((pt[1] + pt[3]) * 0.5)), int((pt[2] - pt[0]) * 0.5 * 0.6), (255, 0, 0), -1)
rebar_count += 1
cv2.putText(image_draw, 'rebar_count: %d' % rebar_count, (25, 50), cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 255, 0), 3)
plt.figure(i, figsize=(30, 20))
plt.imshow(image_draw)
plt.show()Here are screenshots of some of the results.