中文对联AI
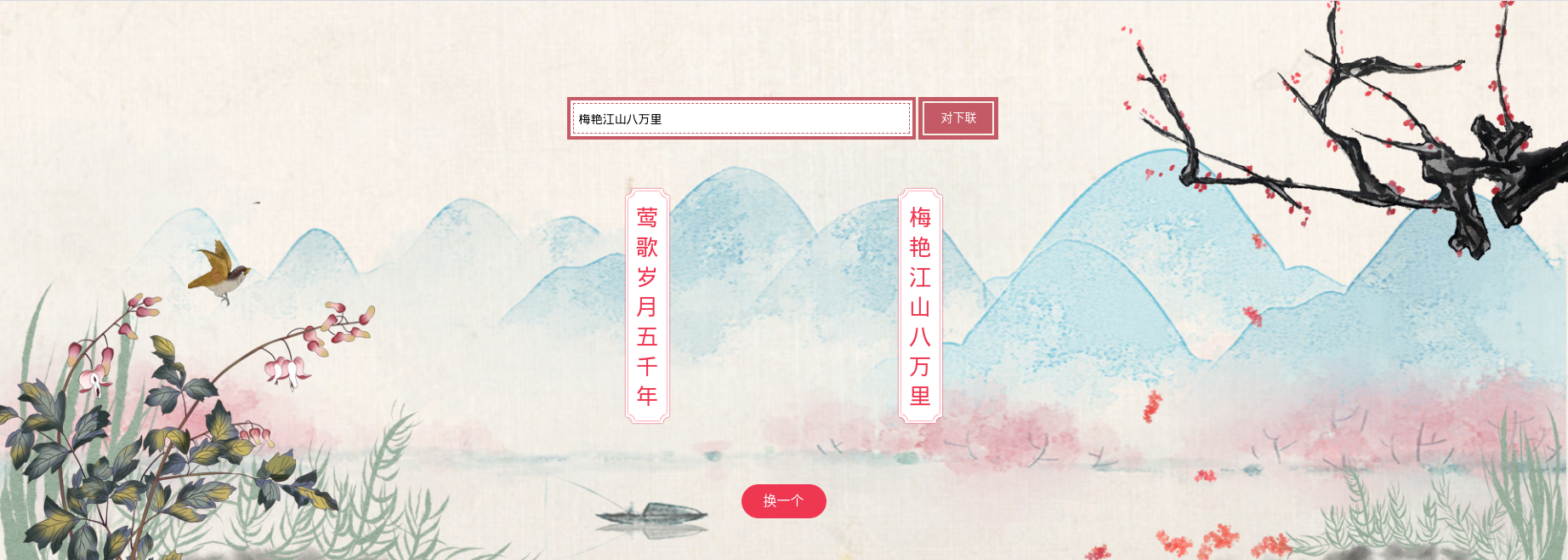
可以访问 https://couplet.neoql.me 查看Demo
- 模型采用CNN+GRU+Attention1
- 训练数据采用wb14123/couplet-dataset
注1: 由于对联上下联字字对应的特点,Attention的设计借鉴了Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context中提出的Relative Positional Encodings. 使模型更易学习到上下文对应位置之间的信息。
CentOS 7.7
Python 3.7.4
PyTorch 1.3.1
| 上联 | 原下联 | AI生成下联 |
|---|---|---|
| 竹报平安岁 | 燕歌祥瑞春 | 梅开富贵春 |
| 百族歌同庆 | 九州喜共荣 | 九州庆共和 |
| 松翠柏青山秀美 | 俗淳风正国昌隆 | 莺歌燕舞柳婀娜 |
| 鹤寿延年霞普照 | 天庭红柏彩云间 | 兰亭毓秀水长流 |
| 金猪献瑞,繁花似锦春常在 | 玉犬呈祥,硕果丰盈福永存 | 玉兔迎春,瑞雪如茵景更新 |
| 节序偏惊,临窗腊尽山河秀 | 情怀不觉,入户春来草木芳 | 春风不度,入户花开日月新 |
| 日月同辉,德行天下春争早 | 城乡一体,富甲东方梦画圆 | 风云际会,情暖人间福自高 |
| 多娇江山脱素呈红,春花烂熳 | 伟大祖国布新除旧,岁月峥嵘 | 广阔天地生辉焕彩,瑞气氤氲 |
| 华夏山河归一统 | 神州日月照千秋 | |
| 爆竹一声除旧 | 梅花万朵迎春 |
注: 上表中下联使用beam search生成,
beam size设置为16
将项目根目录加入PYTHONPATH
export PYTHONPATH=$PYTHONPATH:./安装依赖
pip install -r requirements.txt准备数据集
dataset
├── dev # 开发集
│ ├── in.txt # 上联
│ └── out.txt # 下联
└── train # 训练集
├── in.txt # 上联
└── out.txt # 下联
将dataset目录放在根目录下,数据集为文本文件,每行一句。每个字以空格隔开。
python scripts/build_vocab.py \
dataset/train/in.txt dataset/train/out.txt \
dataset/dev/in.txt dataset/dev/out.txt \
--add-cn-punctuations \
--unused-tokens=10 \
--output-file=experiment/vocab.txt参数说明:
- 匿名参数:用于生成词表的文件列表
--add-cn-punctuations:预先添加中文标点(可不设置, 默认为False)--unused-tokens: 添加未启用token(可不设置,默认为0)--output-file: 设置词表的输出文件
注:该脚本在添加字符时会自动将英文标点转为中文标点
python scripts/train_seq2seq.py \
--vocab_file=experiment/vocab.txt \
--hidden_size=1000 \
--rnn_layers=2 \
--cnn_kernel_size=3 \
--dropout_p=0.1 \
--train_set_dir=dataset/train \
--dev_set_dir=dataset/dev \
--save_dir=experiment/checkpoints \
--logging_dir=experiment/log \
--learning_rate=0.001 \
--num_epochs=50 \
--batch_size=128 \
--max_grad_norm=5参数说明:
--vocab_file: 设置词表文件--hidden_size: 隐层维度--rnn_layers: RNN(GRU)层数--cnn_kernel_size: CNN卷积核大小--dropout_p: dropout层置0概率--train_set_dir: 训练集所在目录--dev_set_dir: 开发集所在目录--save_dir: 模型保存路径--logging_dir: tensorboard的Summary输出路径--learning_rate: 学习率--num_epochs: epoch数量--batch_size: 批处理数量--max_grad_norm: 梯度裁减,最大norm值
STEP=XXX
python scripts/demo.py \
--model=experiment/checkpoints/checkpoint_$STEP \
--vocab_file=experiment/vocab.txt 参数说明:
--model: 模型检查点目录--vocab_file: 设置词表文件
特别致谢wb14123所提供的数据集
MIT, read more here.