forked from geekxh/hello-algorithm
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request geekxh#62 from geekxh/feature/0726
Feature/0726
- Loading branch information
Showing
1,257 changed files
with
8,511 additions
and
724 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,32 @@ | ||
| ##### [点击下载本项目全部内容 提取码:【8f8b】 包括:1、我写的图解算法题典 2、千本开源电子书 3、百张思维导图 4、BAT/TMD 大厂面经 (如果链接失效,上方扫码回复即可)](https://www.geekxh.com/github_click.html?6072) | ||
|
|
||
| #### 本项目还包括 I(支持下载): | ||
|
|
||
| > 千本开源电子书覆盖了你在IT行业发展可以用到的大部分资料,百张思维导图按照专题对各类计算机知识进行了整合。**由于文件过大,建议通过下方扫码,回复【999】获取** | ||
| - 📚 [一千本开源电子书](https://github.com/geekxh/hello-algorithm/tree/master/%E6%B8%85%E6%99%B0%E7%89%88%E7%94%B5%E5%AD%90%E4%B9%A61000%E6%9C%AC) | ||
| - 🐒 [百张思维导图集锦](https://github.com/geekxh/hello-algorithm/tree/master/%E8%B6%85%E6%B8%85%E6%80%9D%E7%BB%B4%E5%AF%BC%E5%9B%BE100%E5%BC%A0) | ||
|
|
||
| #### 本项目还包括 II(支持下载): | ||
|
|
||
| > 大厂面经汇总覆盖了阿里、京东、华为、字节、滴滴、百度、美团、腾讯 等公司的面试题,按照 公司/专题 两个维度对面试题进行了整合。**由于文件过大,建议通过下方扫码,回复【面经】获取。** | ||
| <br/> | ||
| <div align="center"> | ||
| <a href="https://www.geekxh.com/readme/04.png" style="box-shadow: rgb(210, 210, 210) 0em 0em 0.5em 0px; font-size: 17px;"><img src="https://www.geekxh.com/readme/04.png" width="200px"></a> | ||
| </div> | ||
| <br/> | ||
|
|
||
| ### 使用指南 | ||
|
|
||
| 1、因为本教程完全免费,但现在被一些不良商家拿去卖钱,<b> 所以我需要你先帮我点一个 star </b>,助力原创,防止更多人上当受骗,也顺便支持我一下。 | ||
|
|
||
| 2、算法训练包括三部分:① 算法知识基础 ② 图解算法题典 ③ 算法知识扩展 | ||
|
|
||
| 3、如果是以面试为目的,可以直接对第二部分进行学习。如果基础薄弱,建议从第一部分进行学习。第三部分为专题学习,包含大部分算法资料。 | ||
|
|
||
| 4、对于其中题目有疑惑,可以加入我们的<b>万人刷题群</b>,群里可内推 BAT。扫上面那只熊,回复【进群】即可。 | ||
|
|
||
| 5、当然,也许你就想加我的私人微信: [个人名片](https://www.geekxh.com/contact.jpeg) | ||
|
|
||
| PS:该项目包括了你在 IT 行业发展可以用到的绝大部分资料。但我希望大家不要当收藏党,找到适合自己的才重要。 |
Large diffs are not rendered by default.
Oops, something went wrong.
Binary file not shown.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,99 @@ | ||
| # 双向链表 | ||
|
|
||
| 在计算机科学中, 一个 **双向链表(doubly linked list)** 是由一组称为节点的顺序链接记录组成的链接数据结构。每个节点包含两个字段,称为链接,它们是对节点序列中上一个节点和下一个节点的引用。开始节点和结束节点的上一个链接和下一个链接分别指向某种终止节点,通常是前哨节点或null,以方便遍历列表。如果只有一个前哨节点,则列表通过前哨节点循环链接。它可以被概念化为两个由相同数据项组成的单链表,但顺序相反。 | ||
|
|
||
|  | ||
|
|
||
| 两个节点链接允许在任一方向上遍历列表。 | ||
|
|
||
| 在双向链表中进行添加或者删除节点时,需做的链接更改要比单向链表复杂得多。这种操作在单向链表中更简单高效,因为不需要关注一个节点(除第一个和最后一个节点以外的节点)的两个链接,而只需要关注一个链接即可。 | ||
|
|
||
|
|
||
|
|
||
| ## 基础操作的伪代码 | ||
|
|
||
| ### 插入 | ||
|
|
||
| ```text | ||
| Add(value) | ||
| Pre: value is the value to add to the list | ||
| Post: value has been placed at the tail of the list | ||
| n ← node(value) | ||
| if head = ø | ||
| head ← n | ||
| tail ← n | ||
| else | ||
| n.previous ← tail | ||
| tail.next ← n | ||
| tail ← n | ||
| end if | ||
| end Add | ||
| ``` | ||
|
|
||
| ### 删除 | ||
|
|
||
| ```text | ||
| Remove(head, value) | ||
| Pre: head is the head node in the list | ||
| value is the value to remove from the list | ||
| Post: value is removed from the list, true; otherwise false | ||
| if head = ø | ||
| return false | ||
| end if | ||
| if value = head.value | ||
| if head = tail | ||
| head ← ø | ||
| tail ← ø | ||
| else | ||
| head ← head.next | ||
| head.previous ← ø | ||
| end if | ||
| return true | ||
| end if | ||
| n ← head.next | ||
| while n = ø and value !== n.value | ||
| n ← n.next | ||
| end while | ||
| if n = tail | ||
| tail ← tail.previous | ||
| tail.next ← ø | ||
| return true | ||
| else if n = ø | ||
| n.previous.next ← n.next | ||
| n.next.previous ← n.previous | ||
| return true | ||
| end if | ||
| return false | ||
| end Remove | ||
| ``` | ||
|
|
||
| ### 反向遍历 | ||
|
|
||
| ```text | ||
| ReverseTraversal(tail) | ||
| Pre: tail is the node of the list to traverse | ||
| Post: the list has been traversed in reverse order | ||
| n ← tail | ||
| while n = ø | ||
| yield n.value | ||
| n ← n.previous | ||
| end while | ||
| end Reverse Traversal | ||
| ``` | ||
|
|
||
| ## 复杂度 | ||
|
|
||
| ## 时间复杂度 | ||
|
|
||
| | Access | Search | Insertion | Deletion | | ||
| | :-------: | :-------: | :-------: | :-------: | | ||
| | O(n) | O(n) | O(1) | O(1) | | ||
|
|
||
| ### 空间复杂度 | ||
|
|
||
| O(n) | ||
|
|
||
| ## 参考 | ||
|
|
||
| - [Wikipedia](https://en.wikipedia.org/wiki/Doubly_linked_list) | ||
| - [YouTube](https://www.youtube.com/watch?v=JdQeNxWCguQ&t=7s&index=72&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,22 @@ | ||
| # 图 | ||
|
|
||
| 在计算机科学中, **图(graph)** 是一种抽象数据类型, | ||
| 旨在实现数学中的无向图和有向图概念,特别是图论领域。 | ||
|
|
||
| 一个图数据结构是一个(由有限个或者可变数量的)顶点/节点/点和边构成的有限集。 | ||
|
|
||
| 如果顶点对之间是无序的,称为无序图,否则称为有序图; | ||
|
|
||
| 如果顶点对之间的边是没有方向的,称为无向图,否则称为有向图; | ||
|
|
||
| 如果顶点对之间的边是有权重的,该图可称为加权图。 | ||
|
|
||
|
|
||
|
|
||
| 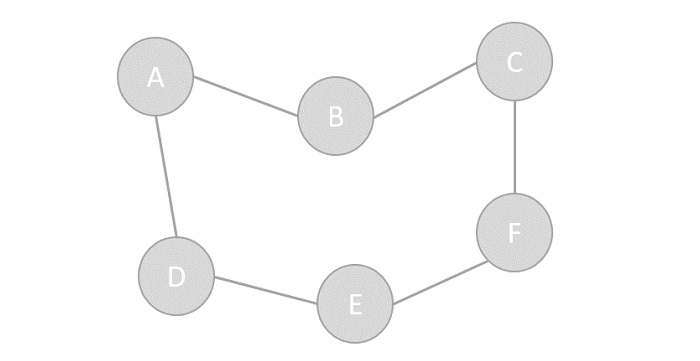 | ||
|
|
||
| ## 参考 | ||
|
|
||
| - [Wikipedia](https://en.wikipedia.org/wiki/Graph_(abstract_data_type)) | ||
| - [Introduction to Graphs on YouTube](https://www.youtube.com/watch?v=gXgEDyodOJU&index=9&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8) | ||
| - [Graphs representation on YouTube](https://www.youtube.com/watch?v=k1wraWzqtvQ&index=10&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,21 @@ | ||
| # 哈希表 | ||
|
|
||
| 在计算中, 一个 **哈希表(hash table 或hash map)** 是一种实现 *关联数组(associative array)* | ||
| 的抽象数据;类型, 该结构可以将 *键映射到值*。 | ||
|
|
||
| 哈希表使用 *哈希函数/散列函数* 来计算一个值在数组或桶(buckets)中或槽(slots)中对应的索引,可使用该索引找到所需的值。 | ||
|
|
||
| 理想情况下,散列函数将为每个键分配给一个唯一的桶(bucket),但是大多数哈希表设计采用不完美的散列函数,这可能会导致"哈希冲突(hash collisions)",也就是散列函数为多个键(key)生成了相同的索引,这种碰撞必须 | ||
| 以某种方式进行处理。 | ||
|
|
||
|
|
||
|  | ||
|
|
||
| 通过单独的链接解决哈希冲突 | ||
|
|
||
|  | ||
|
|
||
| ## 参考 | ||
|
|
||
| - [Wikipedia](https://en.wikipedia.org/wiki/Hash_table) | ||
| - [YouTube](https://www.youtube.com/watch?v=shs0KM3wKv8&index=4&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,19 @@ | ||
| # 堆 (数据结构) | ||
|
|
||
| 在计算机科学中, 一个 **堆(heap)** 是一种特殊的基于树的数据结构,它满足下面描述的堆属性。 | ||
|
|
||
| 在一个 *最小堆(min heap)* 中, 如果 `P` 是 `C` 的一个父级节点, 那么 `P` 的key(或value)应小于或等于 `C` 的对应值. | ||
|
|
||
| 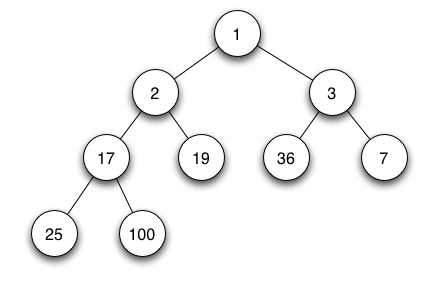 | ||
|
|
||
| 在一个 *最大堆(max heap)* 中, `P` 的key(或value)大于 `C` 的对应值。 | ||
|
|
||
|  | ||
|
|
||
|
|
||
| 在堆“顶部”的没有父级节点的节点,被称之为根节点。 | ||
|
|
||
| ## 参考 | ||
|
|
||
| - [Wikipedia](https://en.wikipedia.org/wiki/Heap_(data_structure)) | ||
| - [YouTube](https://www.youtube.com/watch?v=t0Cq6tVNRBA&index=5&t=0s&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,147 @@ | ||
| # 链表 | ||
|
|
||
| 在计算机科学中, 一个 **链表** 是数据元素的线性集合, 元素的线性顺序不是由它们在内存中的物理位置给出的。 相反, 每个元素指向下一个元素。它是由一组节点组成的数据结构,这些节点一起,表示序列。 | ||
|
|
||
| 在最简单的形式下,每个节点由数据和到序列中下一个节点的引用(换句话说,链接)组成。这种结构允许在迭代期间有效地从序列中的任何位置插入或删除元素。 | ||
|
|
||
| 更复杂的变体添加额外的链接,允许有效地插入或删除任意元素引用。链表的一个缺点是访问时间是线性的(而且难以管道化)。 | ||
|
|
||
| 更快的访问,如随机访问,是不可行的。与链表相比,数组具有更好的缓存位置。 | ||
|
|
||
|  | ||
|
|
||
| ## 基本操作的伪代码 | ||
|
|
||
| ### 插入 | ||
|
|
||
| ```text | ||
| Add(value) | ||
| Pre: value is the value to add to the list | ||
| Post: value has been placed at the tail of the list | ||
| n ← node(value) | ||
| if head = ø | ||
| head ← n | ||
| tail ← n | ||
| else | ||
| tail.next ← n | ||
| tail ← n | ||
| end if | ||
| end Add | ||
| ``` | ||
|
|
||
| ``` | ||
| Prepend(value) | ||
| Pre: value is the value to add to the list | ||
| Post: value has been placed at the head of the list | ||
| n ← node(value) | ||
| n.next ← head | ||
| head ← n | ||
| if tail = ø | ||
| tail ← n | ||
| end | ||
| end Prepend | ||
| ``` | ||
|
|
||
| ### 搜索 | ||
|
|
||
| ```text | ||
| Contains(head, value) | ||
| Pre: head is the head node in the list | ||
| value is the value to search for | ||
| Post: the item is either in the linked list, true; otherwise false | ||
| n ← head | ||
| while n != ø and n.value != value | ||
| n ← n.next | ||
| end while | ||
| if n = ø | ||
| return false | ||
| end if | ||
| return true | ||
| end Contains | ||
| ``` | ||
|
|
||
| ### 删除 | ||
|
|
||
| ```text | ||
| Remove(head, value) | ||
| Pre: head is the head node in the list | ||
| value is the value to remove from the list | ||
| Post: value is removed from the list, true, otherwise false | ||
| if head = ø | ||
| return false | ||
| end if | ||
| n ← head | ||
| if n.value = value | ||
| if head = tail | ||
| head ← ø | ||
| tail ← ø | ||
| else | ||
| head ← head.next | ||
| end if | ||
| return true | ||
| end if | ||
| while n.next != ø and n.next.value != value | ||
| n ← n.next | ||
| end while | ||
| if n.next != ø | ||
| if n.next = tail | ||
| tail ← n | ||
| end if | ||
| n.next ← n.next.next | ||
| return true | ||
| end if | ||
| return false | ||
| end Remove | ||
| ``` | ||
|
|
||
| ### 遍历 | ||
|
|
||
| ```text | ||
| Traverse(head) | ||
| Pre: head is the head node in the list | ||
| Post: the items in the list have been traversed | ||
| n ← head | ||
| while n != ø | ||
| yield n.value | ||
| n ← n.next | ||
| end while | ||
| end Traverse | ||
| ``` | ||
|
|
||
| ### 反向遍历 | ||
|
|
||
| ```text | ||
| ReverseTraversal(head, tail) | ||
| Pre: head and tail belong to the same list | ||
| Post: the items in the list have been traversed in reverse order | ||
| if tail != ø | ||
| curr ← tail | ||
| while curr != head | ||
| prev ← head | ||
| while prev.next != curr | ||
| prev ← prev.next | ||
| end while | ||
| yield curr.value | ||
| curr ← prev | ||
| end while | ||
| yield curr.value | ||
| end if | ||
| end ReverseTraversal | ||
| ``` | ||
|
|
||
| ## 复杂度 | ||
|
|
||
| ### 时间复杂度 | ||
|
|
||
| | Access | Search | Insertion | Deletion | | ||
| | :-------: | :-------: | :-------: | :-------: | | ||
| | O(n) | O(n) | O(1) | O(1) | | ||
|
|
||
| ### 空间复杂度 | ||
|
|
||
| O(n) | ||
|
|
||
| ## 参考 | ||
|
|
||
| - [Wikipedia](https://en.wikipedia.org/wiki/Linked_list) | ||
| - [YouTube](https://www.youtube.com/watch?v=njTh_OwMljA&index=2&t=1s&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,15 @@ | ||
| # 优先队列 | ||
|
|
||
| 在计算机科学中, **优先级队列(priority queue)** 是一种抽象数据类型, 它类似于常规的队列或栈, 但每个元素都有与之关联的“优先级”。 | ||
|
|
||
| 在优先队列中, 低优先级的元素之前前面应该是高优先级的元素。 如果两个元素具有相同的优先级, 则根据它们在队列中的顺序是它们的出现顺序即可。 | ||
|
|
||
| 优先队列虽通常用堆来实现,但它在概念上与堆不同。优先队列是一个抽象概念,就像“列表”或“图”这样的抽象概念一样; | ||
|
|
||
| 正如列表可以用链表或数组实现一样,优先队列可以用堆或各种其他方法实现,例如无序数组。 | ||
|
|
||
|
|
||
| ## 参考 | ||
|
|
||
| - [Wikipedia](https://en.wikipedia.org/wiki/Priority_queue) | ||
| - [YouTube](https://www.youtube.com/watch?v=wptevk0bshY&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8&index=6) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,15 @@ | ||
| # 队列 | ||
|
|
||
| 在计算机科学中, 一个 **队列(queue)** 是一种特殊类型的抽象数据类型或集合。集合中的实体按顺序保存。 | ||
|
|
||
| 队列基本操作有两种:入队和出队。从队列的后端位置添加实体,称为入队;从队列的前端位置移除实体,称为出队。 | ||
|
|
||
|
|
||
| 队列中元素先进先出 FIFO (first in, first out)的示意 | ||
|
|
||
|  | ||
|
|
||
| ## 参考 | ||
|
|
||
| - [Wikipedia](https://en.wikipedia.org/wiki/Queue_(abstract_data_type)) | ||
| - [YouTube](https://www.youtube.com/watch?v=wjI1WNcIntg&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8&index=3&) |
Oops, something went wrong.