spi_bcm2835situation
- Uses/implements:
- makes use of the new SPI-Framework which results in smaller code-size
- interrupt handler
- misses LoSSI/9Bit transfers
- implements as per "BCM2834 ARM Peripherals" this includes
- recommendations for filling FIFOs (16bytes then 12) as per 10.6.2/Page 158
- recommendations for CLK to be a power of 2 - as per 10.5 CLK-Register/Page 156
- limited to 2/3 SPI devices - no arbitrary GPIO as CS support
- Bugs:
- Inverted CS does not work correctly if there are 2 or more devices
these have the "gpio-timing-instrumentation" enabled and were run on a RPI2 similar/worse pattern happen on a RPI1
Note also that there are channels:
- 4 - CAN_INT - the CAN interrupt signaling a message has arrived
- 5 - D24 - work_run - inside the work-tasklet (potentially sleeping)
- 8 - D23 - trans_wait - waiting on completion inside of transmit code
- 9 - D22 - spi_int - inside the SPI interrupt
- 10 - D18 - mcp-int - inside the interrupt handler of the mcp2515
- 11 - D17 - mcpcompl - inside one of the mcp2515 completion routines
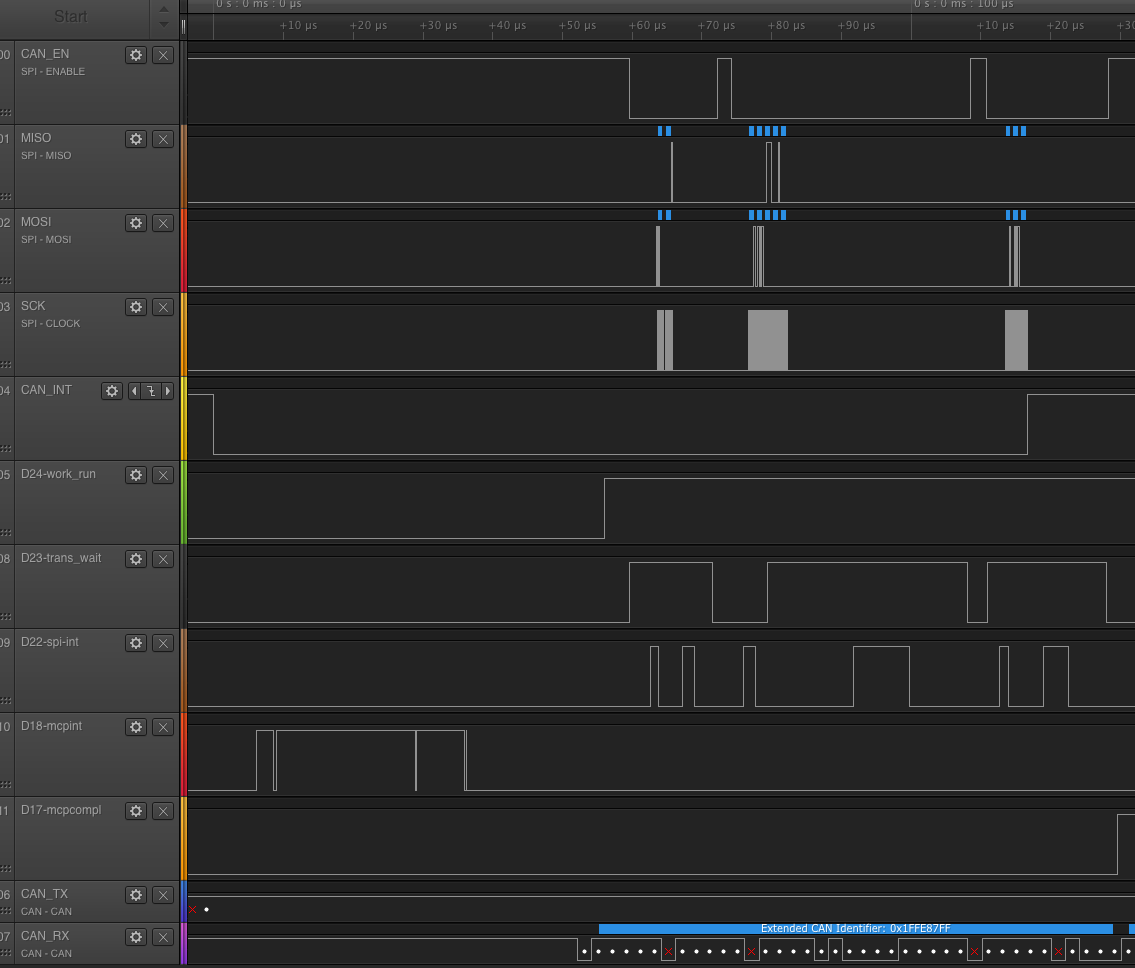
Measurements:
- time between CAN-interrupt down and inside CAN interrupt handler: 8.36us
- time between first SPI message scheduled and the transmit_one running: 27.014us
- time from transmit_one-start to CS-down: 3.6us
- time from CS-Down to Spi-interrupt: 5.4us
- time from CS-Down to first bit transferred: 6.12us
- time taken to transfer the 2 bytes: 2.12us
- time from last bit sent to spi_interrupt: 6.48us
- time from last bit sent to workqueue woken up: 29.32us
- time from workqueue woken to CS-up: 1.96us
- time from CS-down to CS-up: 39.56us
- time from Workqueue woken to mcp-completion code called: 6us (after 2 more transmits) (note that the example shows that the workqueue is still running while the completion code runs on a different CPU!)
Issues observed:
- Transfers take 10x as long as necessary (for a 2 byte transfer)
- there is lots of jitter on the interrupts and scheduling of tasks (indicating also that there are possibly a lot of cache-misses happening)
- 3us are typically between CS down and the first byte getting sent
- this is mostly due to the fact that the interrupt handler takes so long to start and push data into the fifo
- also we see lots of WAIT for completions (in the case of multiple transfers for a single transfer like write X then read Y)
Summary:
- scheduling of tasks is a major breaking-point (wakeups)
- also the scheduling interrupt-latencies are quite high
- for a single "simple" transfer we have:
- 2 interrupts (fill in initially and draining in the end)
- 3 task switches:
- scheduling process (IRQ or other) to queued thread (transmit_one)
- sleeping and waiting for Completion inside transmit_one
- wakeing the transmit_one thread for further processing
- often the completion code will wake up another kernel thread (especially when using the syncronous spi interfaces)
- we can remove one interrupt from the equation by filling the FIFO before enabling interrupts
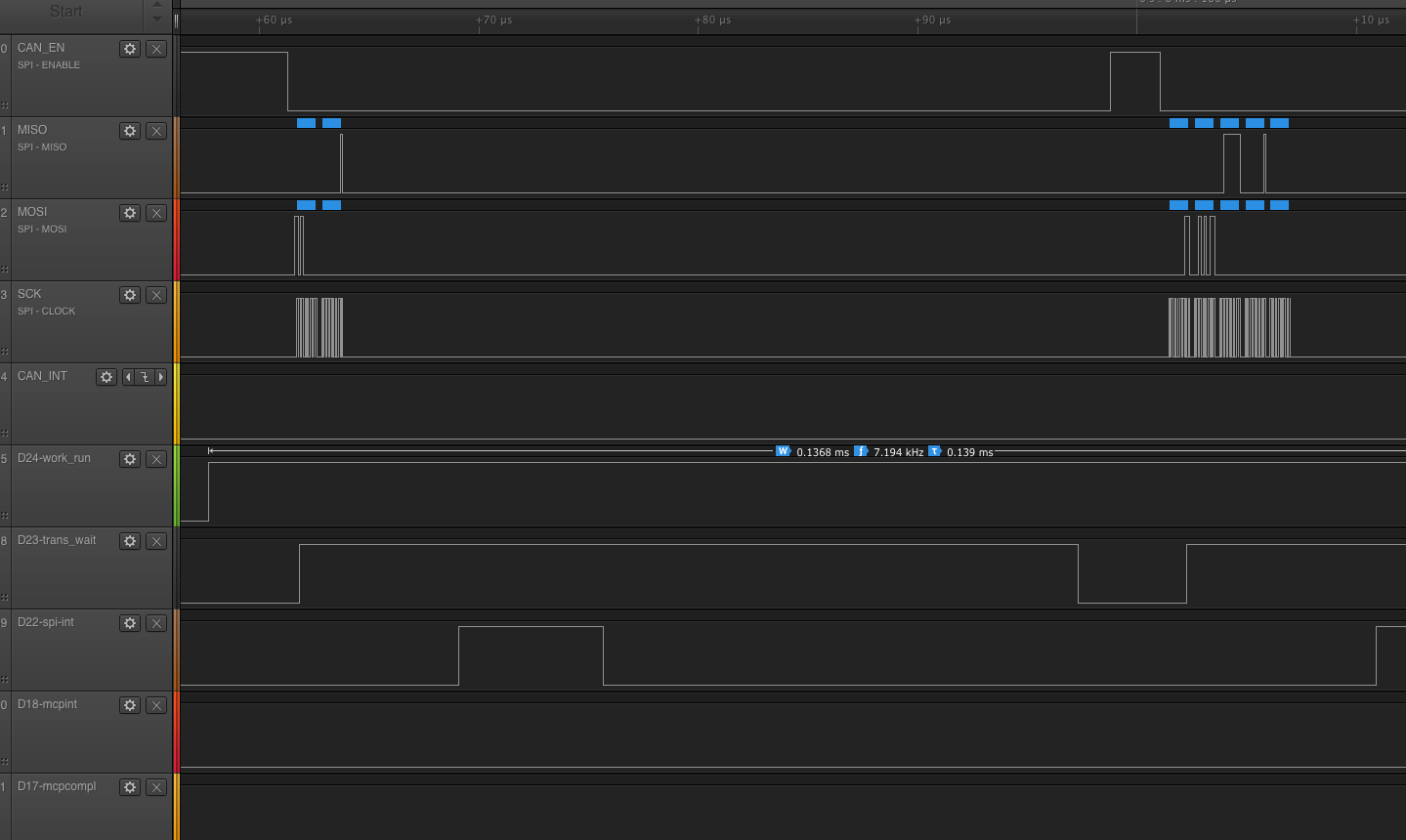
Measurements:
- time between CAN-interrupt down and inside CAN interrupt handler: 8.96us
- time between first SPI message scheduled and the transmit_one running: 27.64us
- time from transmit_one-start to CS-down: 3.6us
- time from CS-Down to first bit transferred: 0.4us
- time taken to transfer the 2 bytes: 2.12us
- time from last bit sent to spi_interrupt: 5.28us
- time from last bit sent to workqueue woken up: 28.24us
- time from workqueue woken to CS-up: 1.48us
- time from CS-down to CS-up: 37.52us
- time from Workqueue woken to mcp-completion code called: 5.6us (after 2 more transmits) (note that the example shows (again) that the workqueue is still running while the completion code runs on a different CPU!)
Issues observed:
- the "starting" gap has been minimized and we have one interrupt less to handle
- but it still leaves us with:
- lots of latencies if we transfer more bytes
- Interrupt-handler waking up the completion and the workqueue resuming its work
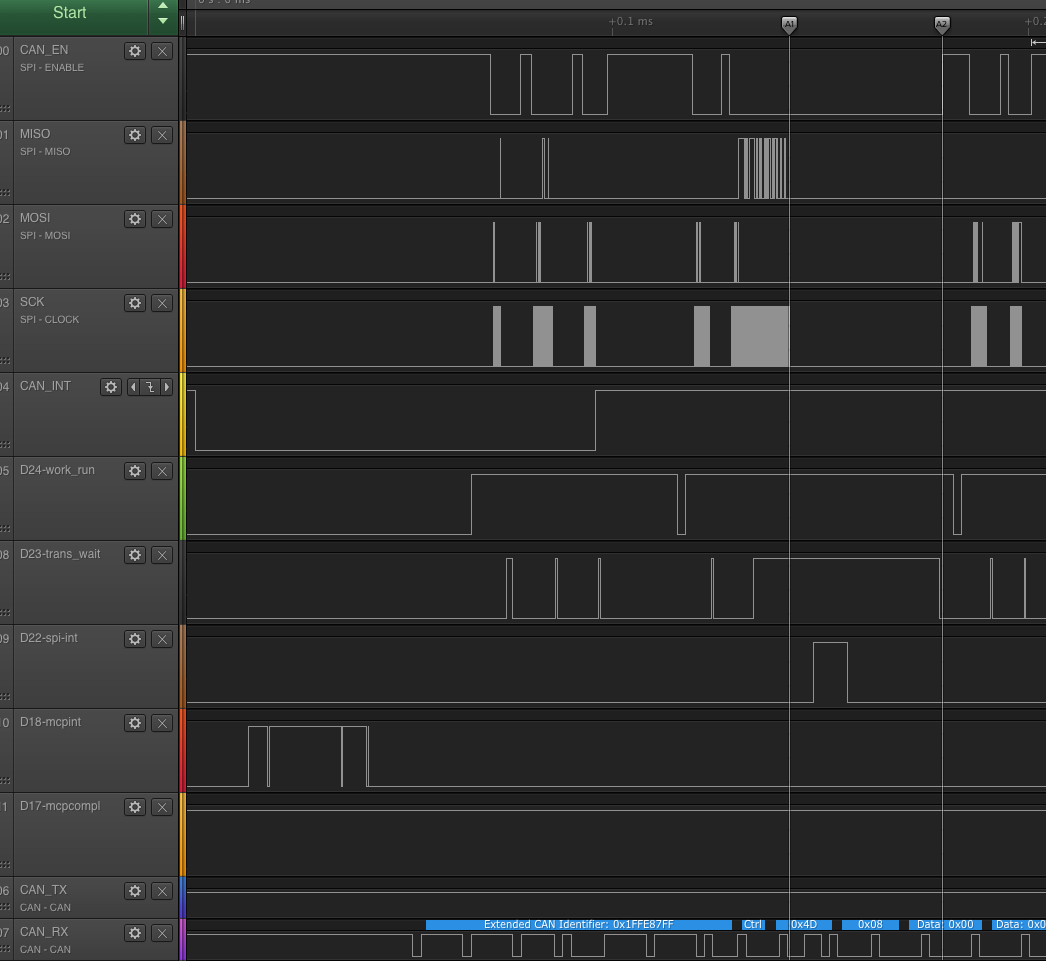
Measurements:
- time between CAN-interrupt down and inside CAN interrupt handler: 12.68us
- time between first SPI message scheduled and the transmit_one running: 31.16us
- time from transmit_one-start to CS-down: 4.6us
- time from CS-Down to first bit transferred: 0.76us
- time taken to transfer the 2 bytes: 1.76us (includes the multiple of 2 clock-divider)
- time from last bit sent to spi_interrupt: Not applicable (except for transfer>10us:)
- time from last bit sent to workqueue woken up: Not applicable (except for transfer>10us:)
- time from workqueue woken to CS-up: Not applicable (except for transfer>10us:)
- time from CS-down to CS-up: 7.2us
- time from CS-up woken to mcp-completion code called: 4.68us (after 2 more transmits) (note that it is NOT shown in the image shared due to a probe being connected to the wrong pin)
- total time for the whole transfer (interrupt to last can_callback finishes): 215us
- first CS-down to last CS-up (3 messages with 7 transfers): 95.0us
Issues observed:
- we have totally minimized the scheduling overhead
- we see higher CPU utilization on the spi-workqueue thread than befor
- note that this shows now more of those hidden CPU cycles, as the Interrupt invocation times are NEVER accounted for in system statistics and interrupt invocation time (from last bit transmitted to exit of spi-interrupt handler) is about 10.24 us, so that is time that a cpu is working, but it shows up in none of the performance counters!
- the total time is now within acceptable means
- there is still the fact that one of the spi-transfers is triggering an interrupt, which introduces a delay of about 31us that is wasted time.
- by comparison the time where we essentially release the CPU for other threads is 8.64us (from wait start till interrupt triggering after the last bit transferred)
- so we can argue for a longer delay that is acceptable for polling.
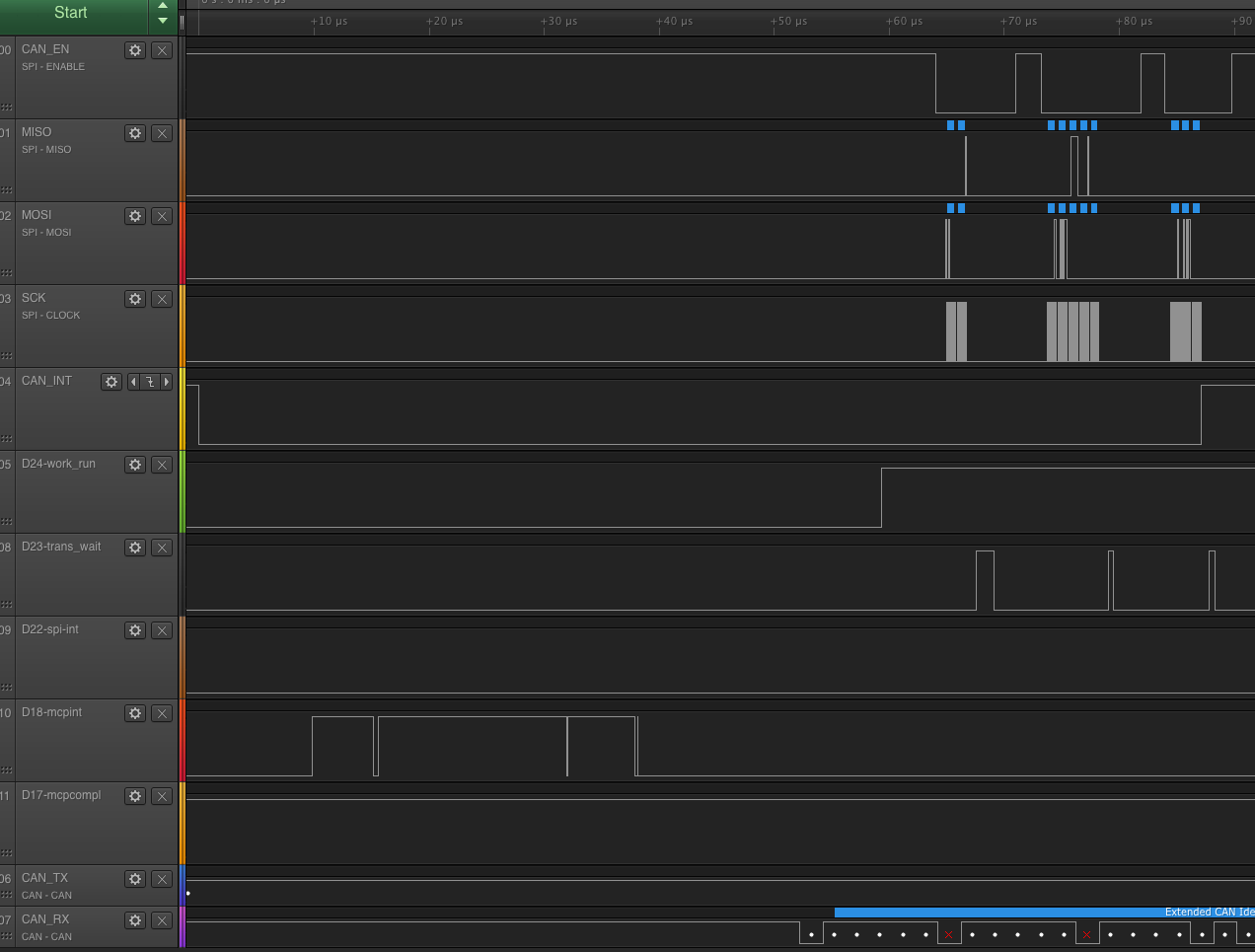
Measurements:
- total time for the whole transfer (interrupt to last can_callback finishes): 161.8us
- first CS-down to last CS-up (3 messages with 7 transfers): 81.8us
Issues observed:
- none - for this use-case the situation is almost perfect.
- the only thing that may bring down CPU utilization would be:
- spi-optimize to reduce on the SPI-message parsing
- dma-driven SPI (together with spi-optimize)
Note that with the above polling code this will NOT show, so we would have to reduce the polling time to 0!!!