I've been trying to learn the Vietnamese language for awhile now, and I wanted to build a tool which let me practice phrases that I want to try to speak to others. One downside to existing language learning tools is that they focus on singular words associated to concepts to build the skill foundation. For example, you might learn 10 colors, and then those colors associated to objects or people. While this is likely a great way for some to learn, I get bored and give up because I don't want to wait to ask "how someone is" or "what someone is doing".
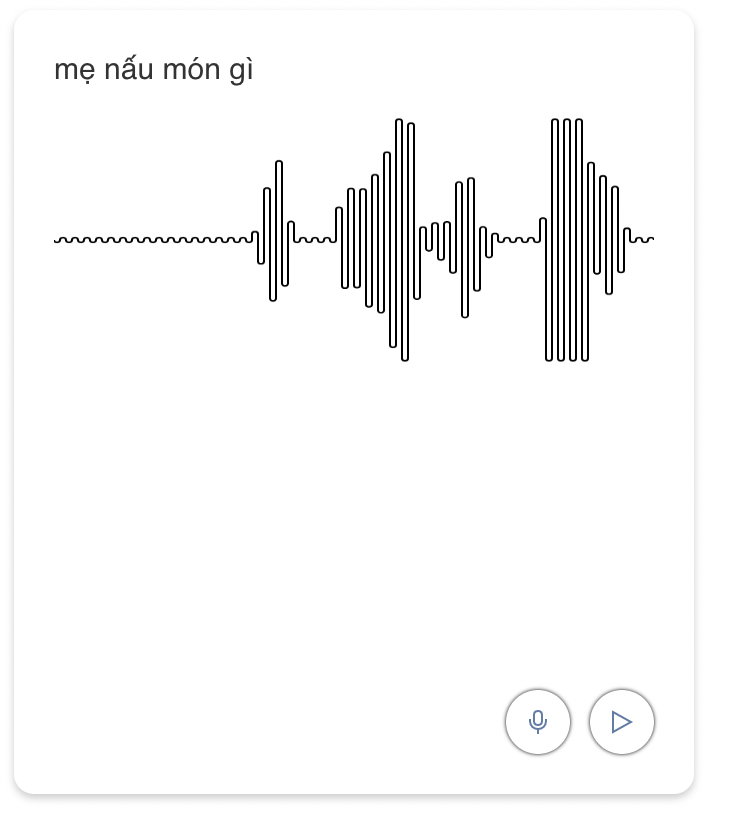
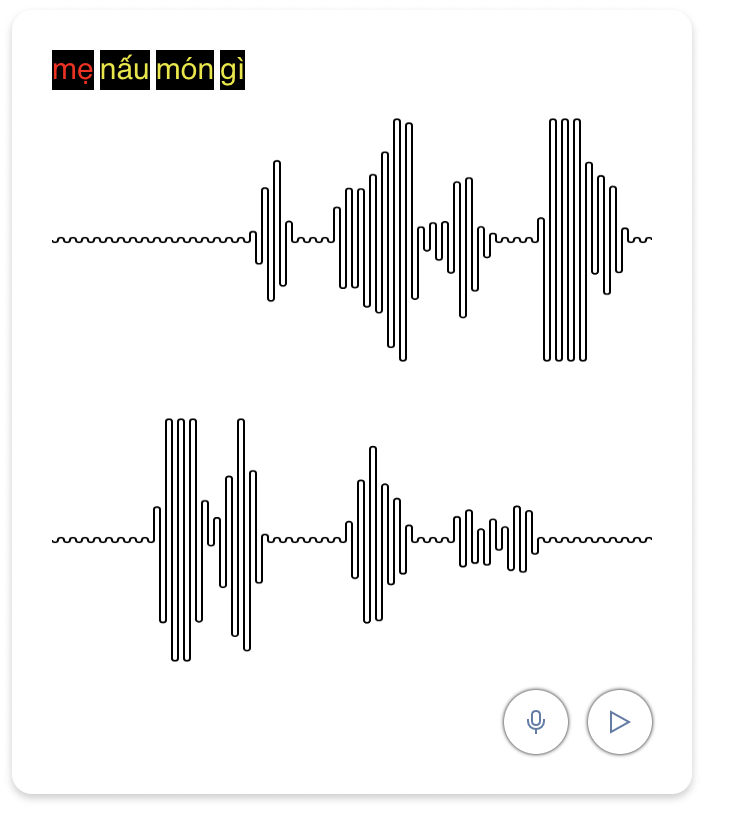
At a high level, this lets a user create a list of phrases they want to practice. Each phrase is translated into a sound file, which can be played back by the user. The user can then record themselves speaking the phrase. The recorded audio is compared to the original audio, and a each word is scored relative to how close it was to the original sound. The user is also presented a visual waveform to compare with.
The text is translated to speech using the https://github.com/NTT123/vietTTS deep learning library. We convert the base64 audio string into an AudioContext, and then into waveform data. The user's audio is recorded using the MediaRecorder API to capture microphone audio (after prompted for permission), then also converted an AudioContext -> waveform data. The waveform data is split into chunks equal to the number of words, and then compared using a Fast Fourier Transform algorithm implementation.
This implementation works "well enough" for my purposes. If I continue to work on this, here is what I will improve:
TODO
- Waveform chunking should be based on the duration of the word, rather than a division of word count in a phrase. Words don't often have the same amount of spoken time.
- The FFT implementation works, but I'm concerned that it isn't giving a consistent result, especially with the first word spoken.
- This implementation assumes a single microphone is connected, which can provide weird results. Add a microphone selector.
License: Creative Commons v4
Add a phrase
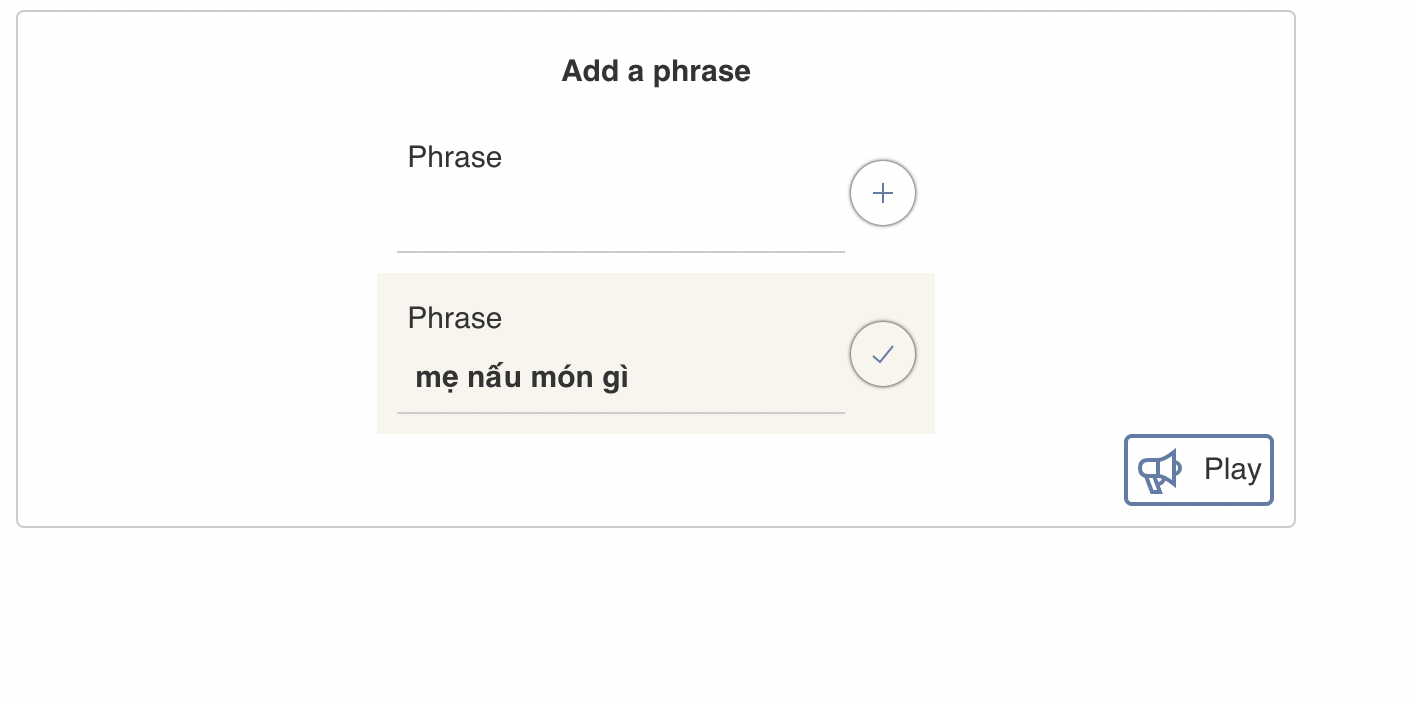
Play phrase
Record phrase and compare
- Clone the repository
- Install dependencies --
yarn install - Start the react app --
yarn start