SpringBoot入门爬虫项目实战
个人博客:https://www.xmlvhy.com,Java技术交流,技术分享以及经验总结和资源分享。欢迎来访~
本项目作为SpringBoot入门实战项目,主要实现异步任务定时爬取百思不得姐数据,并将数据解析入库,提供给前端页面展示。前端采用LayUI相关组件,界面算美观。项目代码没有过度封装(注释详细)。对于刚入门SpringBoot的童鞋,上手这个实战项目还是不错的哈~~ 另外,项目还整合了第三方授权登录(QQ和微信),感兴趣的也可以看看。
- 数据库:Mysql
- 技术组合:SpringBoot、SpringMvc、Mybatis、PageHelper、Thymeleaf
- 前端框架:Layui
- Lombok、okHttp、jwt、gson序列化与反序列化、ognl(对象图导航,简化json对象解析)
- 其它:QQ登录、微信扫码登录
- IDEA 2018.3.5
- Maven 3
- JDK8
- Mysql 5.7+
- Win10 64位系统
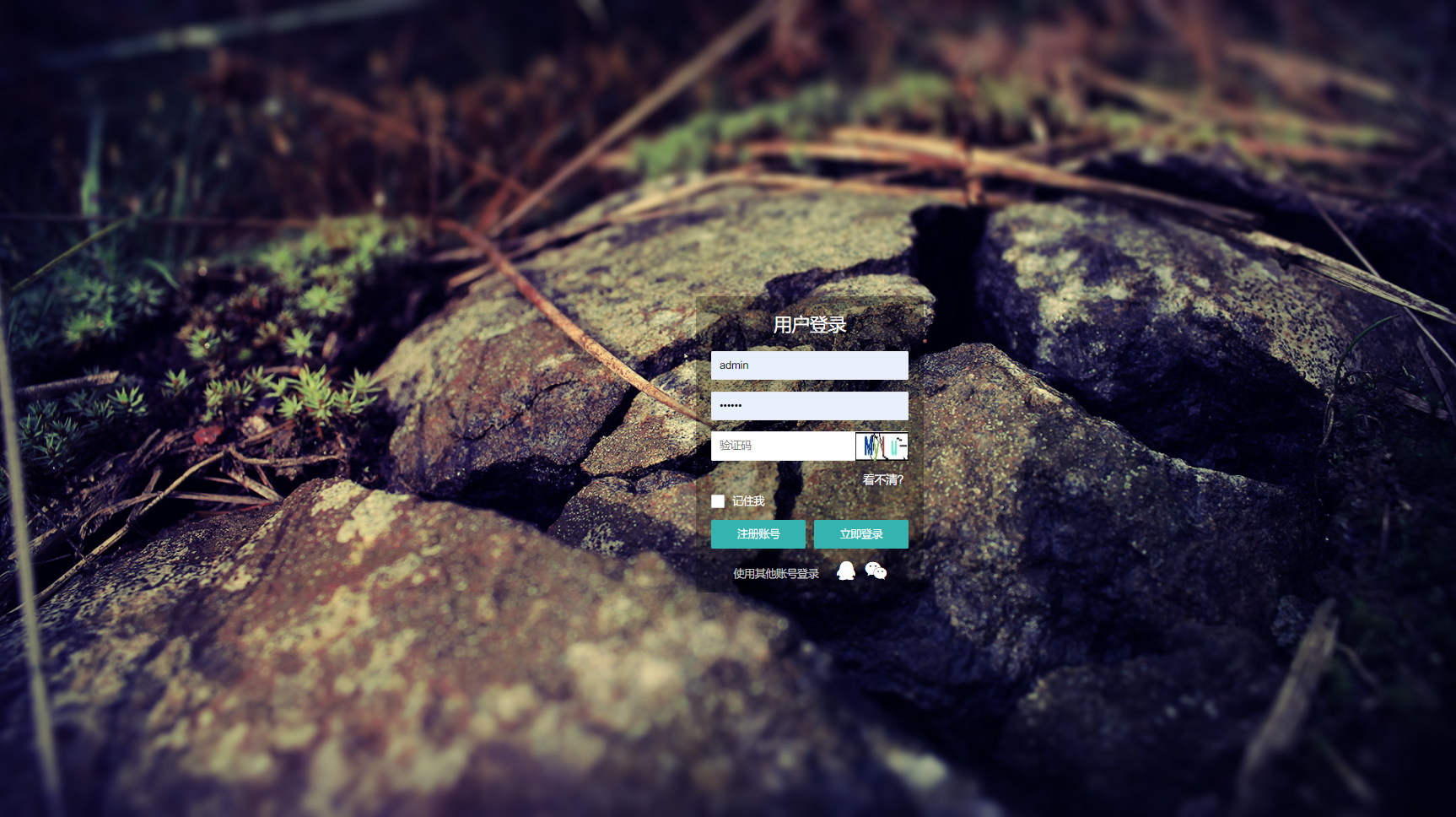
- 注册登录页,管理页面,包括查询、删除、浏览
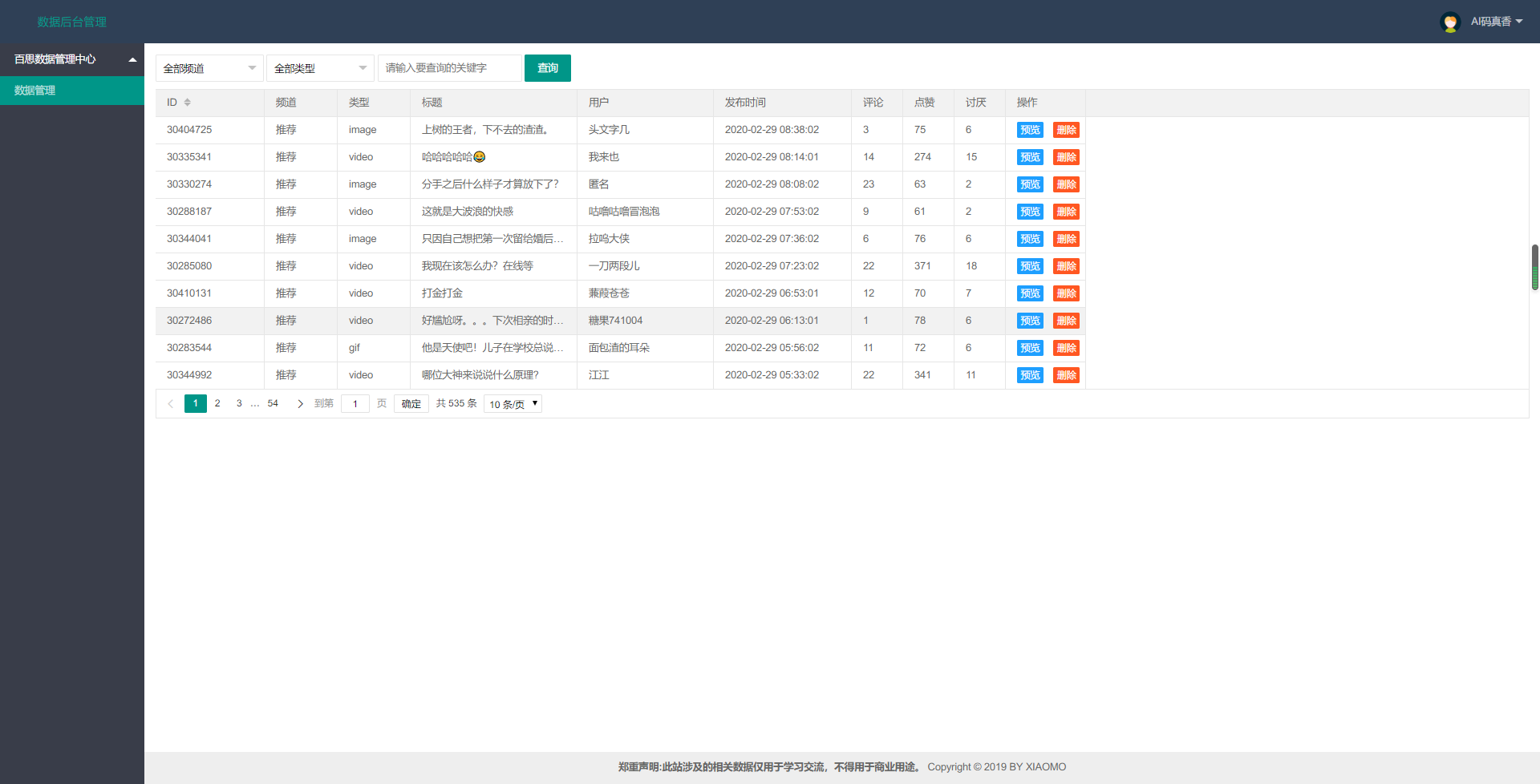
- 预览页面,基本上将解析的数据,如视频、图片、动态图、文字都展示出来



#####五、启动
- main 方法运行
1. 主配置文件:application.properties,可以选择生效的配置文件(dev,pro),先导入数据库脚本,然后配置你本地数据库的账户密码
2. 其它配置:config.properties,这个文件主要配置QQ、微信授权登录相关。若使用,需要修改为你相关的信息
3. com.xmlvhy.crawler.CrawlerBsbdjApplication:主函数入口,点击运行
4. 访问:http://localhost:8081/crawler
5. 账户密码:admin/123456
tips:项目中使用了lombok插件,IDE得装lombok插件
备注:
- 项目中用的接口,使用Charles 抓包工具抓取分析获取,接口可能会出现用不了的情况,需要自己抓取分析。但是至今,这几个接口还是可以正常爬取内容的。
- crawler-nodata.sql,数据库脚本是没有任何数据的,因为当前本地数据有几百M大小就不上传了,需要的前往我的 个人博客 留言,打包发给您!
本项目涉及到的内容以及数据仅供学习交流使用,不得用以其它非法用途!!!