


)

LexicalRichness is a small Python module to compute textual lexical richness (aka lexical diversity) measures.
Lexical richness refers to the range and variety of vocabulary deployed in a text by a speaker/writer (McCarthy and Jarvis 2007) . Lexical richness is used interchangeably with lexical diversity, lexical variation, lexical density, and vocabulary richness and is measured by a wide variety of indices. Uses include (but not limited to) measuring writing quality, vocabulary knowledge (Šišková 2012) , speaker competence, and socioeconomic status (McCarthy and Jarvis 2007).
Table of Contents
Install using PIP
pip install lexicalrichnessIf you encounter,
ModuleNotFoundError: No module named 'textblob'install textblob:
pip install textblobNote: This error should only exist for versions <= v0.1.3. Fixed in
v0.1.4 by David Lesieur and Christophe Bedetti.
Install from Conda-Forge
LexicalRichness is now also available on conda-forge. If you have are using the Anaconda or Miniconda distribution, you can create a conda environment and install the package from conda.
conda create -n lex
conda activate lex
conda install -c conda-forge lexicalrichnessNote: If you get the error CommandNotFoundError: Your shell has not been properly configured to use 'conda activate' with conda activate lex in Bash either try
conda activate bashin the Anaconda Prompt and then retryconda activate lexin Bash- or just try
source activate lexin Bash
Install manually using Git and GitHub
git clone https://github.com/LSYS/LexicalRichness.git
cd LexicalRichness
pip install .Run from the cloud
Try the package on the cloud (without setting anything up on your local machine) by clicking the icon here:
>>> from lexicalrichness import LexicalRichness
# text example
>>> text = """Measure of textual lexical diversity, computed as the mean length of sequential words in
a text that maintains a minimum threshold TTR score.
Iterates over words until TTR scores falls below a threshold, then increase factor
counter by 1 and start over. McCarthy and Jarvis (2010, pg. 385) recommends a factor
threshold in the range of [0.660, 0.750].
(McCarthy 2005, McCarthy and Jarvis 2010)"""
# instantiate new text object (use the tokenizer=blobber argument to use the textblob tokenizer)
>>> lex = LexicalRichness(text)
# Return word count.
>>> lex.words
57
# Return (unique) word count.
>>> lex.terms
39
# Return type-token ratio (TTR) of text.
>>> lex.ttr
0.6842105263157895
# Return root type-token ratio (RTTR) of text.
>>> lex.rttr
5.165676192553671
# Return corrected type-token ratio (CTTR) of text.
>>> lex.cttr
3.6526846651686067
# Return mean segmental type-token ratio (MSTTR).
>>> lex.msttr(segment_window=25)
0.88
# Return moving average type-token ratio (MATTR).
>>> lex.mattr(window_size=25)
0.8351515151515151
# Return Measure of Textual Lexical Diversity (MTLD).
>>> lex.mtld(threshold=0.72)
46.79226361031519
# Return hypergeometric distribution diversity (HD-D) measure.
>>> lex.hdd(draws=42)
0.7468703323966486
# Return Herdan's lexical diversity measure.
>>> lex.Herdan
0.9061378160786574
# Return Summer's lexical diversity measure.
>>> lex.Summer
0.9294460323356605
# Return Dugast's lexical diversity measure.
>>> lex.Dugast
43.074336212149774
# Return Maas's lexical diversity measure.
>>> lex.Maas
0.023215679867353005LexicalRichness comes packaged with minimal preprocessing + tokenization for a quick start.
But for intermediate users, you likely have your preferred nlp_pipeline:
# Your preferred preprocessing + tokenization pipeline
def nlp_pipeline(text):
...
return list_of_tokensUse LexicalRichness with your own nlp_pipeline:
# Initiate new LexicalRichness object with your preprocessing pipeline as input
lex = LexicalRichness(text, preprocesser=None, tokenizer=nlp_pipeline)
# Compute lexical richness
mtld = lex.mtld()Or use LexicalRichness at the end of your pipeline and input the list_of_tokens with preprocesser=None and tokenizer=None:
# Preprocess the text
list_of_tokens = nlp_pipeline(text)
# Initiate new LexicalRichness object with your list of tokens as input
lex = LexicalRichness(list_of_tokens, preprocesser=None, tokenizer=None)
# Compute lexical richness
mtld = lex.mtld()Here's a minimal example using lexicalrichness with a Pandas dataframe with a column containing text:
def mtld(text):
lex = LexicalRichness(text)
return lex.mtld()
df['mtld'] = df['text'].apply(mtld)wordlist |
list of words |
words |
number of words (w) |
terms |
number of unique terms (t) |
preprocessor |
preprocessor used |
tokenizer |
tokenizer used |
ttr |
type-token ratio computed as t / w (Chotlos 1944, Templin 1957) |
rttr |
root TTR computed as t / sqrt(w) (Guiraud 1954, 1960) |
cttr |
corrected TTR computed as t / sqrt(2w) (Carrol 1964) |
Herdan |
log(t) / log(w) (Herdan 1960, 1964) |
Summer |
log(log(t)) / log(log(w)) Summer (1966) |
Dugast |
(log(w) ** 2) / (log(w) - log(t) Dugast (1978) |
Maas |
(log(w) - log(t)) / (log(w) ** 2) Maas (1972) |
msttr |
Mean segmental TTR (Johnson 1944) |
mattr |
Moving average TTR (Covington 2007, Covington and McFall 2010) |
mtld |
Measure of Lexical Diversity (McCarthy 2005, McCarthy and Jarvis 2010) |
hdd |
HD-D (McCarthy and Jarvis 2007) |
Assessing method docstrings
>>> import inspect
# docstring for hdd (HD-D)
>>> print(inspect.getdoc(LexicalRichness.hdd))
Hypergeometric distribution diversity (HD-D) score.
For each term (t) in the text, compute the probabiltiy (p) of getting at least one appearance
of t with a random draw of size n < N (text size). The contribution of t to the final HD-D
score is p * (1/n). The final HD-D score thus sums over p * (1/n) with p computed for
each term t. Described in McCarthy and Javis 2007, p.g. 465-466.
(McCarthy and Jarvis 2007)
Parameters
__________
draws: int
Number of random draws in the hypergeometric distribution (default=42).
Returns
_______
floatAlternatively, just do
>>> print(lex.hdd.__doc__)
Hypergeometric distribution diversity (HD-D) score.
For each term (t) in the text, compute the probabiltiy (p) of getting at least one appearance
of t with a random draw of size n < N (text size). The contribution of t to the final HD-D
score is p * (1/n). The final HD-D score thus sums over p * (1/n) with p computed for
each term t. Described in McCarthy and Javis 2007, p.g. 465-466.
(McCarthy and Jarvis 2007)
Parameters
----------
draws: int
Number of random draws in the hypergeometric distribution (default=42).
Returns
-------
floatFor now, refer to the study below for algorithmic details:
Shen, Lucas (2021). Measuring political media using text data. (https://www.lucasshen.com/research/media.pdf)
Click here for citation metadata
@techreport{accuracybias, title={Measuring Political Media Slant Using Text Data}, author={Shen, Lucas}, url={https://www.lucasshen.com/research/media.pdf} }
[1] SENTiVENT used the metrics that LexicalRichness provides to estimate the classification difficulty of annotated categories in their corpus (Jacobs & Hoste 2020). The metrics show which categories will be more difficult for modeling approaches that rely on linguistic inputs because greater lexical diversity means greater data scarcity and more need for generalization. (h/t Gilles Jacobs)
Jacobs, Gilles, and Véronique Hoste. "SENTiVENT: enabling supervised information extraction of company-specific events in economic and financial news." Language Resources and Evaluation (2021): 1-33.
Click here for citation metadata
@article{jacobs2021sentivent, title={SENTiVENT: enabling supervised information extraction of company-specific events in economic and financial news}, author={Jacobs, Gilles and Hoste, V{\'e}ronique}, journal={Language Resources and Evaluation}, pages={1--33}, year={2021}, publisher={Springer} }
- [2] Measuring political media using text data. This chapter of my thesis investigates whether political media bias manifests by coverage accuracy. As covaraites, I use characteristics of the text data (political speech and news article transcripts). One of the ways speeches can be characterized is via lexical richness.
Shen, Lucas (2021). Measuring political media using text data [Click for metadata]
@techreport{accuracybias, title={Measuring Political Media Slant Using Text Data}, author={Shen, Lucas}, url={https://www.lucasshen.com/research/media.pdf} }
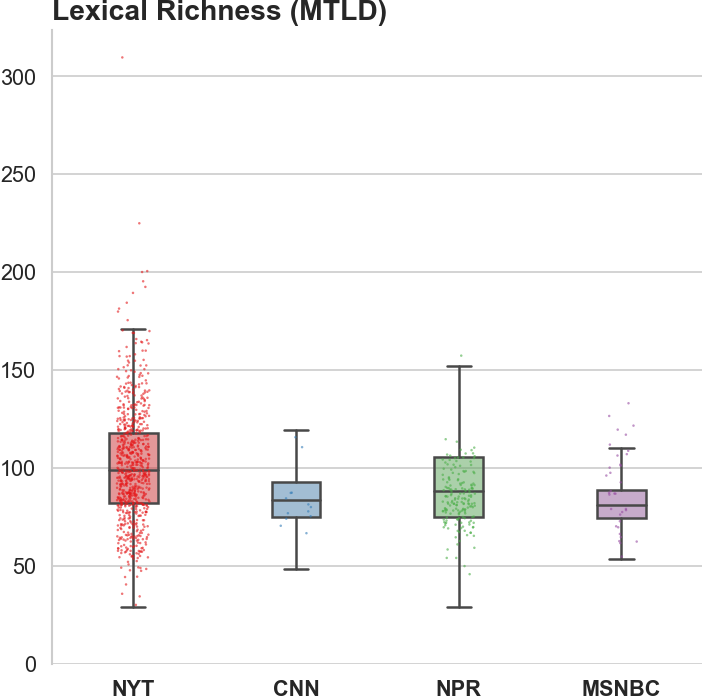
[3] Unreadable News: How Readable is American News? This study characterizes modern news by readability and lexical richness. Focusing on the NYT, they find increasing readability and lexical richness, suggesting that NYT feels competition from alternative sources to be accessible while maintaining its key demographic of college-educated Americans.
NYT's lexical superiority?
[4] German is more complicated than English This study analyses a small sample of English books and compares them to their German translation. Within the sample, it can be observed that the German translations tend to be shorter in length, but contain more unique terms than their English counterparts. LexicalRichness was used to generate the statistics modeled within the study.
Words vs Terms in Each Book

Source: (https://github.com/g-hurst/Comparing-Properties-of-German-and-English-Books)

Author
Contributors
Contributions are welcome, and they are greatly appreciated! Every little bit helps, and credit will always be given. See here for how to contribute to this project. See here for Contributor Code of Conduct.
If you have used this codebase and wish to cite it, please cite as below.
Codebase:
@misc{lex,
author = {Shen, Lucas},
doi = {10.5281/zenodo.6607007},
license = {MIT license},
title = {{LexicalRichness: A small module to compute textual lexical richness}},
url = {https://github.com/LSYS/lexicalrichness},
year = {2022}
}Documentation on formulations and algorithms:
@misc{accuracybias,
title={Measuring Political Media Slant Using Text Data},
author={Shen, Lucas},
url={https://www.lucasshen.com/research/media.pdf}
}The package is released under the MIT License.