{kind=link}
پروژهی تحلیل احساسات متون فارسی با استفاده از روشهای ساده و قابل فهم بدون نیاز به شبکههای عصبی به کمک custom classifier & naive bayes.
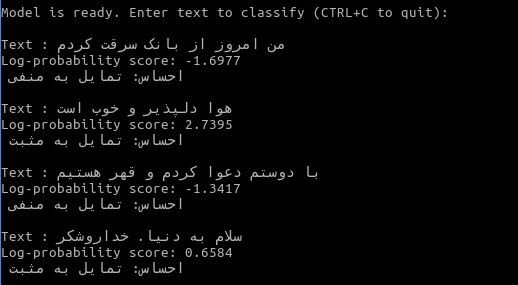
این پروژه امکان آموزش مدل، ذخیرهسازی، تست و پیشبینی دستی احساسات متنهای فارسی را فراهم میکند. و جهت آموزش کافیه نمونه داده دستی وارد کنید!
این ریپو یک پروژه آزمایشی و ساده بوده و در آینده با بهره گیری از ساختار های شبکه عصبی عمیق به درک واقعی تر و دقیق تر نسبت به تشخیص عوافط از متون فارسی خواهم پرداخت.
persian-sentiment-nlp/ │
├── config.py # تنظیمات پروژه (مسیرها، دستهبندیها و مقادیر ثابت)
├── tokenizer.py # توکنایزر اختصاصی برای پردازش متن فارسی
├── stemmer.py # استمر اختصاصی برای حذف پیشوند/پسوند کلمات فارسی
├── preprocessing.py # آمادهسازی دیتاست و استخراج ویژگیها
├── trainer.py # کد آموزش مدل
├── main.py # فایل اجرایی اصلی پروژه
├── manipulate/ # شامل فایلهای پیشوند، پسوند، استاپورد، اعداد و علائم نگارشی
└── dataset/ # دیتاست توییتهای فارسی (فرمت CSV)
ابتدا باید کتابخانههای زیر را نصب کنید:
pip install numpy pandas tqdm scikit-learnمن از نمونه دیتاست توییت های فارسی در قالب csv ، از آدرس کگل زیر استفاده کردم که لیست کلاس داده های موجود بدین شرحه:
https://www.kaggle.com/datasets/behdadkarimi/persian-tweets-emotional-dataset
| شماره کلاس | اسم فارسی کلاس | اسم انگلیسی کلاس |
|---|---|---|
| 0 | ناراحت | Sad |
| 1 | ترس | Fear |
| 2 | شگفت زده | Surprise |
| 3 | منزجر | Disgust |
| 4 | عصبانیت | Anger |
| 5 | ترکیبی | Joy |
مسیر ها و مقادیر مد نظر و کلاس بندی های شخصی خودتونو در فایل config قرار بدید و با دستور زیر مدل خودتونو آموزش بدید.
python3 main.py۱ - پیشپردازش حرفهای متنهای فارسی
۲ - توکنایزر و استمر اختصاصی بدون وابستگی به NLTK
۳ - آموزش مدل احساس با NumPy
۴ - ذخیره و لود وزنهای مدل
۵ - پیشبینی احساسات به صورت real-time
۶ - قابل توسعه برای استفاده از مدلهای پیشرفتهتر (LSTM, BERT و...)
اگر قصد دارید صرفا به صورت باینری مدل تشخیص عواطف داشته باشید، توصیه میکنم از برنج Naive-Bayes موجود در همین ریپو استفاده کنید که فرایند آموزش را به صورت آماری و با دقت و سرعت بهبود یافته انجام میهد.