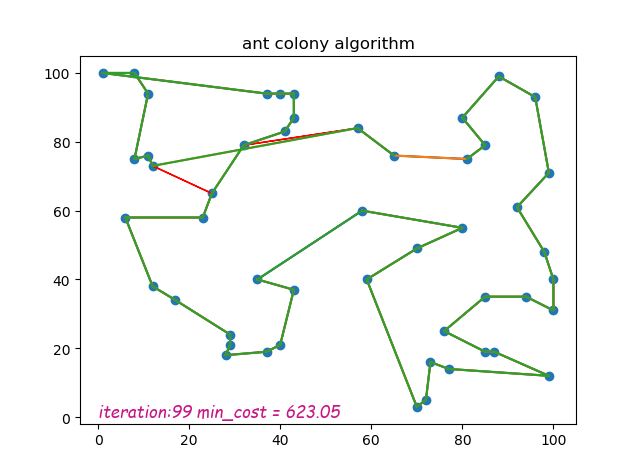
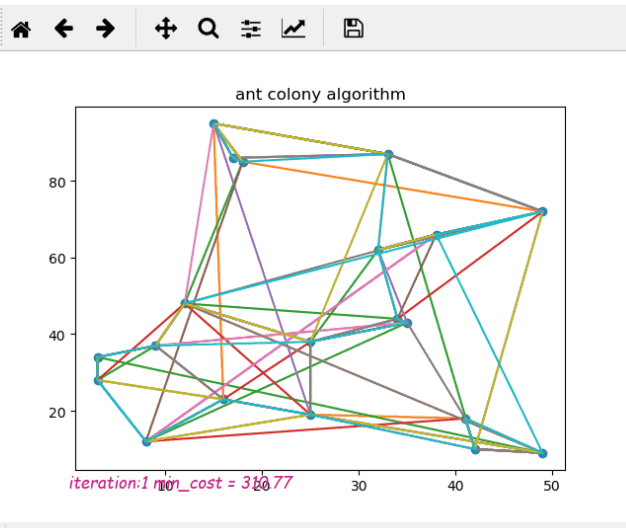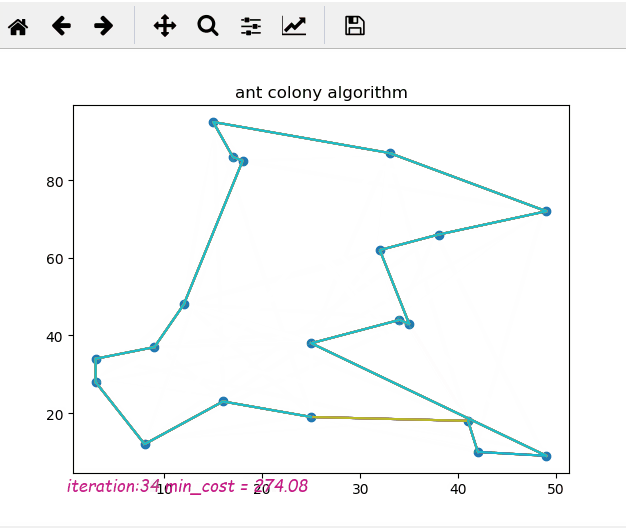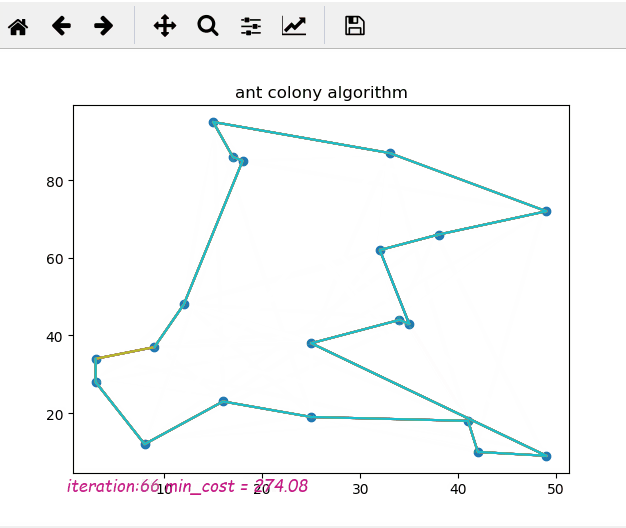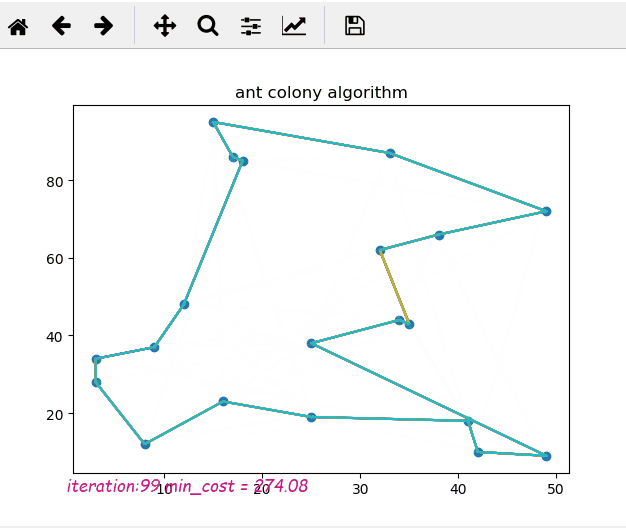
这是蚁群算法的python实现,使用matplotlib显示运行算法时的动态变化
pip install -r requirements.txt| result | dynamic |
|---|---|
 |
 |
-
直接运行
python main.py
-
使用您自己的数据
如果您想使用自己的数据,请创建一个新的示例文件(例如
data.txt)并使用python main.py --test {FILENAME} # python main.py --test ./data/example-1.txt
注意您的数据应该是二维 {X,Y} 如下所示
28 16 5 34 28 3 19 48 17 30 23 1 ...
您可以在 data 中找到一些测试文件示例
-
复现实验结果 : 使用随机数种子
代码运行结束之后会得到本次运行使用的随机数种子,如果您想复现实现结果请添加使用
-s {SEED}重新运行python main.py -s {SEED} #python main.py --test ./data/example-1.txt -s 9438
该算法中有许多相关参数,您可以使用默认参数运行或根据需要更改它。但是在某些情况下更改参数可能会改进算法,或者表现更差
python main.py --ant 20 --points 50 --rho 0.2 --max_x 1000 --max_y 1000-
ant:蚂蚁的数量 -
points:点数 -
generation:迭代次数 -
alpha:信息素的相对重要性 -
beta:启发式信息的相对重要性 -
rho:信息素残留系数 -
q:信息素强度 -
strategy:信息素更新策略。- 0 - 蚁周
- 1 - 蚁量
- 2 - 蚁密
-
min_x,max_x,min_y,max_y生成的点值的范围(x,y)
每次运行都会创建一个记录文件./temp.txt,如果你想再次使用这个数据,你应该把它移动到./data/并重命名为./data/example-x.txt然后使用--test导入此文件
每次运行的结果将保存为 ./result.png。
如果最终的图片看起来很疯狂或有多条线,这意味着它在迭代结束时没有收敛到局部最优解。所以你需要改变你的参数选择,比如增加rho或减少q等等
正如博客所说,蚁群算法在解决小规模TSP问题上几乎没有用处,稍等一下就能找到最优解时间。但是,如果问题规模很大,蚁群算法的性能会非常低甚至卡顿。所以可以改进,比如精英蚂蚁系统
如果您发现任何错误或改进建议,请留下您的建议