用golang实现一个用户互动系统,支持评论、关注、投票等操作
-
发布评论:支持无限盖楼回复。
-
读取评论:按照时间、热度排序;显示评论数、楼中楼等。
-
删除评论:用户删除、UP主删除等。
-
评论互动:点赞、点踩、举报等。
-
管理评论:置顶、精选、后台运营管理(搜索、删除、审核等)。todo
评论一般还包括一些更高阶的基础功能:
-
评论富文本展示:例如表情、@、分享链接、图片等。todo
-
评论标签:例如UP主点赞、UP主回复、好友点赞等。todo
-
评论装扮:一般用于凸显发评人的身份等。todo
-
热评管理:结合AI和人工,为用户营造更好的评论区氛围。todo

Service:comment-service
服务层,专注在评论功能的 API 实现上,比如发布、读取、删除等,关注在稳定性、可用性上,这样让上游可以灵活组织逻辑,后续需要把基础能力和业务能力剥离。这一层专注于处理数据本身。
Job:comment-job
用于读取消息队列的数据实现写操作,消息队列的最大用途是削峰处理。当写入请求非常大的时候,通过异步消息队列处理写请求。
Cache-Aside 模式,先读取缓存,再读取存储。
早期 cache rebuild 是做到服务里的,对于重建逻辑,一般会使用 read ahead 的思路。即预读,用户访问了第一页,很有可能访问第二页,所以缓存会超前加载,避免频繁 cache miss。
当缓存抖动,特别容易引起集群 thundering herd现象(线程惊群效应),大量的请求会触发 cache rebuild,大量往 MySQL获取数据,并且回填到 Redis中。因为使用了预加载,容易导致服务 OOM。
所以再到回源的逻辑里,改为使用消息队列来进行逻辑异步化,对于当前请求只返回 MySQL 中部分数据即止,然后发送异步消息,处理 cache miss的数据和预读的数据到 Redis。
写的瓶颈往往就来自于存储层。对于写的设计上,我们认为刚发布的评论有极短的延迟(通常小于几 ms)对用户可见是可接受的,把对存储的直接冲击下放到消息队列,按照消息反压的思路,即如果存储延迟升高,消费能力就下降,自然消息容易堆积,系统始终以最大化方式消费。
评论的写接口使用中间件进行流量削峰处理的主要原因包括以下几点:
- 保护后端服务:评论写入接口可能会受到突发的高并发请求,如果没有流量削峰处理,可能会导致后端服务不稳定甚至崩溃。通过中间件进行流量削峰处理,可以保护后端服务免受突发高负载的影响。
- 平滑流量:流量削峰处理可以帮助平滑处理突发的高并发请求,避免突然的请求激增对系统造成冲击,保持系统稳定运行。
- 提高系统可用性:通过中间件进行流量削峰处理,可以有效控制系统的负载,降低系统崩溃的风险,从而提高系统的可用性和稳定性。
- 优化资源利用:流量削峰处理可以帮助优化资源利用,避免资源被瞬时的高并发请求占用,提高系统整体的资源利用率。
content_index 索引表
comment_index:索引表
记录评论的索引
同样记录对应的主题,方便后续查询
通过 pid 记录是否是根评论以及子评论的上级
floor 记录评论层级,也需要更新主题表中的楼层数

comment_content 评论内容表
comment_content:评论内容表
记录核心评论的内容,避免检索的时候内容过多导致效率低。

UserComment
UserComment:用户评论相关表
查看用户发表评论数量,以及收评数量

数据写入:事务更新 comment_index,comment_content 二张表。content 属于非强制需要一致性考虑的。可以先写入 content,之后事务更新其他表。即便 content 先成功,后续失败仅仅存在一条 ghost 数据。
数据读取:基于 resource_id 在 comment_index 表找到评论列表, WHERE pid= 0 ORDER BY floor_count。之后根据 comment_index 的 id 字段获取出 comment_content 的评论内容。对于二级的子楼层, WHERE pid IN (id...)。
todo
针对QPS大的服务与接口,可以采取以下措施来有效缓解热点事件带来的读写压力增加:
-
缓存技术:使用缓存技术可以降低数据库访问压力,提高接口响应速度。通过将热点数据缓存在内存中,可以减少对数据库的频繁访问,特别是针对读多写少的场景4。
-
分布式缓存:采用分布式缓存可以将数据分布到多台服务器上,提高了系统整体的读取性能和并发能力。常见的分布式缓存包括Redis、Memcached等。
-
本地缓存:对于一些热点数据,可以考虑使用本地缓存技术,将数据缓存在应用服务器的内存中,减少对分布式缓存或数据库的访问4。
-
缓存预热:在系统启动或者更新热点数据时,可以进行缓存预热,将热点数据加载到缓存中,避免在系统运行过程中突然的读写压力增加4。
-
读写分离:针对读多写少的场景,可以考虑使用读写分离技术,将读请求和写请求分发到不同的数据库实例上,从而提高系统整体的读取性能1。
-
限流与熔断:对于热点事件,可以通过限流和熔断等手段来控制请求的并发量,避免突发的请求对系统造成过大的压力1。
综上所述,通过合理运用缓存技术、读写分离、限流与熔断等手段,可以有效缓解热点事件带来的读写压力增加,提高系统的稳定性和性能。
对于热门的主题,如果存在缓存穿透(缓存中没有数据,请求穿透了缓存,直接打到数据库)的情况,会导致大量的同进程、跨进程的数据回源到存储层,可能会引起存储过载的情况,如何只交给同进程内,一个人去做加载存储。
使用归并回源的思路:
同进程只交给一个请求去获取 mysql 数据,然后批量返回。同时这个 lease owner 投递一个 kafka 消息,做 index cache 的 recovery 操作。这样可以大大减少 mysql 的压力,以及大量穿透导致的密集写 kafka 的问题。
更进一步的,后续连续的请求,仍然可能会短时 cache miss ,我们可以在进程内设置了一个 short-lived flag,标记最近有一个请求投递了 cache rebuild 的消息,直接 drop。
可以看到,这里说明的都是单进程下的解决思路。那么在多进程下,能否使用分布式锁来解决。理论上可以,但是实际操作起来,容易将这个简单问题复杂化,不推荐使用分布式锁。(PS:redis 作者不推荐使用 redis 实现分布式锁。)
多进程下,也是一样的思想,多个进程会发送多个消息到消息队列中,消费端获取消息的时候,通过单飞的思路,同样处理。
热点分为写热点和读热点。
写操作一般会通过MQ削峰,当大量的请求都集中在 MQ 中,不仅仅会影响当前服务,还可能导致下游服务出现异常。这种情况下,可以再进行解耦,增加上游服务的吞吐,将下游服务解耦,不依赖同一个同步逻辑。
流量热点是因为突然热门的主题,被高频次的访问,因为底层的 cache 设计,一般是按照主题 key 进行一致性 hash 来进行分片,但是热点 key 一定命中某一个节点,这时 remote cache 可能会变成瓶颈。因此做 cache 升级 local cache 是有必要的,一般使用单进程自适应发现热点的思路,附加一个短时的 ttl local cache,可以在进程内吞掉大量的读请求。
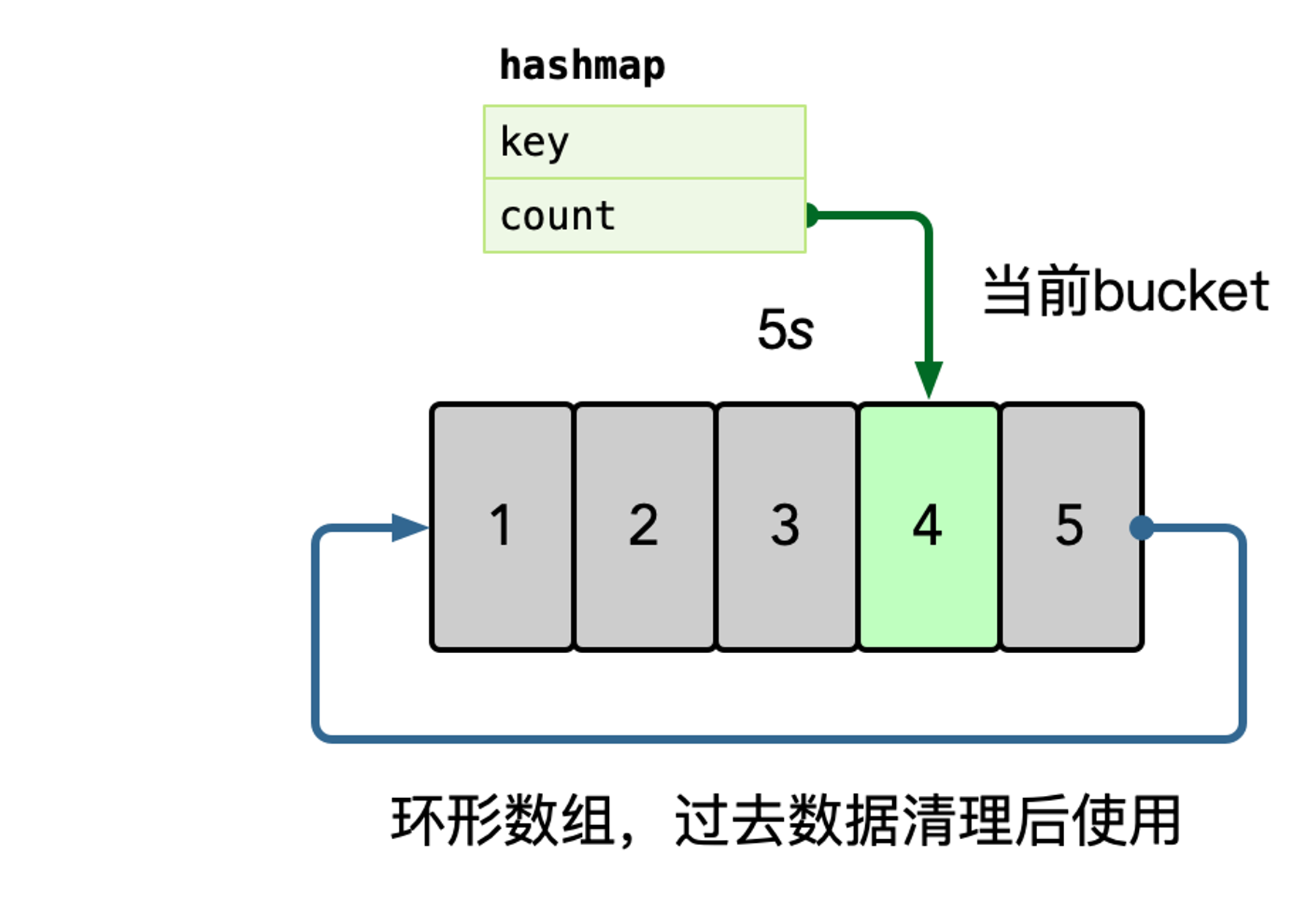
在内存中使用 hashmap 统计每个 key 的访问频次,这里可以使用滑动窗口(左角标和右角标一起移动,统计区间内部的数据量)统计,即每个窗口中,维护一个 hashmap,之后统计所有未过去的 bucket,汇总所有 key 的数据。
之后使用小顶堆计算 TopK 的数据,自动进行热点识别。
GET /v1/comment/list
- 查询根评论:使用
resource_id和pid = 0在comment_index表中查询根评论,按照floor_count排序。同时,根据每条根评论的id从comment_content表中获取评论内容。 - 查询子评论:对于每条根评论,使用其
id在comment_index表中查询对应的子评论,按照floor_count排序。同样,根据每条子评论的id从comment_content表中获取评论内容。 - 实现分页:对于根评论和每条根评论的子评论分别进行分页处理,以限制单个请求返回的评论数量,避免数据库过载。
- 缓存处理:使用分布式缓存(如Redis)缓存结果,以减少数据库负载,处理高流量。
- 数据库索引:在
resource_id、pid和floor_count上建立数据库索引,以加速查询。 - 读取负载分发:实现数据库读取负载分发,使用读取副本来处理大流量情况下的查询请求。
- 负载均衡:使用负载均衡器将传入的请求分发到应用程序的多个实例,以提高系统整体性能和可用性。
针对二级评论的展示,通常会在前端界面上以嵌套列表的形式展示。在后端接口实现上,可以通过递归查询的方式来获取每条根评论下的所有子评论,并将其组织成树状结构返回给前端。例如,对于每条根评论,在查询完根评论后,再递归查询其下的所有子评论,并将其作为根评论的子节点返回给前端。这样前端就可以利用这样的数据结构来展示出清晰的嵌套列表形式。通过以上实现逻辑和性能考虑,可以保证在大流量情况下系统具有良好的性能和可用性,并且能够满足用户对于展示二级评论等更复杂场景的需求。
- 递归查询:后端可以通过递归查询的方式来处理无限盖楼的评论,即每个评论记录除了主体内容外,还记录
parent_id,parent_id为0则为主体评论。这样可以构建出一个树状结构的数据模型,前端可以递归地展示每层楼中的评论 - 前端展示:前端可以使用递归组件或者循环嵌套的方式来展示无限层级的评论,确保用户可以清晰地看到每条评论的上下文关系。
- 评论计数:在返回的评论数据中包含每条评论的回复数量,这样用户可以直观地看到每条评论下有多少回复
- 实时更新:评论数应该实时更新,以反映最新的评论状态。这可能需要后端在添加或删除评论时更新相关计数,并通过缓存或其他机制来优化性能。
- 楼中楼数据结构:后端需要提供楼中楼(即评论的评论)的数据结构,前端可以在每条评论下展示其子评论
- 分页和加载更多:对于评论数较多的情况,可以实现分页或“加载更多”的功能,以便用户可以按需加载更多的评论,而不是一次性加载所有评论,这有助于提高页面加载速度和用户体验。
-
缓存策略
:对于频繁访问的评论,可以使用缓存来减少数据库的查询次数,特别是对于热门评论或者根评论4。
-
异步加载:对于楼中楼的评论,可以采用异步加载的方式,即当用户点击某个评论查看回复时,再去加载这些回复,而不是一开始就加载所有数据。
- 折叠和展开:提供折叠和展开评论的功能,特别是对于深层次的楼中楼评论,用户可以选择只查看顶层评论或展开查看详细的对话。
- 高亮显示:对于用户参与的评论,可以高亮显示,让用户快速找到自己的评论和回复。
POST /v1/comment/add
- 接收新评论数据,包括
resource_id、pid(如果是回复的话)、评论内容等。 - 首先将评论内容写入
comment_content表。 - 在事务中更新
comment_index表,如果是根评论则pid为0,否则设置为父评论的id,并更新对应主题的楼层数。 - 更新
UserComment表,增加用户的评论数量。 - 使用消息队列处理写入操作,以应对高并发情况。
- 使用事务确保数据一致性,同时减少数据库锁的时间。
- 异步写入操作,通过消息队列如Kafka来缓冲高峰期的写入请求,避免直接压力到数据库。
- 对
comment_index和comment_content表进行适当的索引优化,以加快写入和查询速度。
GET /v1/comment/detail/:id
- 根据评论的
id查询comment_index表获取评论索引信息。 - 使用索引信息中的
id查询comment_content表获取评论内容。 - 如果评论是子评论(
pid不为0),则还需要查询父评论的内容。 - 可以考虑将评论内容缓存到Redis等缓存系统中,以提高读取速度。
- 对
comment_index的id字段和pid字段建立索引,以便快速检索。 - 使用缓存减少对数据库的直接访问,特别是对于频繁访问的评论详情。
- 对于热点数据(如频繁访问的评论),可以使用CDN或其他缓存策略来进一步提高响应速度。
这些接口的设计考虑到了高并发下的性能和可用性,通过使用事务、消息队列和缓存等技术来确保系统的稳定性和响应速度。
DELETE /v1/comment/delete/:id
- 验证请求者权限,确保用户具有删除该评论的权限(用户删除自己的评论或UP主删除评论)。
- 根据评论的
id删除comment_content表中的评论内容。 - 在事务中删除
comment_index表中对应的索引信息,并更新相关楼层计数。 - 如果删除的是根评论,需要递归删除所有子评论。
- 更新
UserComment表,减少用户的评论数量。
- 使用事务确保删除操作的数据一致性。
- 递归删除可能会影响性能,需要优化递归逻辑,可能的话采用批量删除。
- 使用消息队列异步处理删除操作,减少对数据库的即时压力。
POST /v1/comment/interact
{
"comment_id": "12345",
"user_id": "67890",
"action": "like" // Or "dislike", "report"
}- 根据
action参数,对评论执行相应的互动操作(点赞、点踩或举报)。 - 更新
comment_interaction表,记录用户的互动行为。 - 点赞或点踩操作还需更新评论的点赞数或点踩数。
- 举报操作需要通知后台管理系统进行审核。
- 对
comment_interaction表使用适当的索引以优化查询和更新速度。 - 互动计数更新可以使用缓存和批量写入数据库的策略来优化性能。
- 举报操作可以使用消息队列异步处理,避免阻塞用户操作。
POST /v1/comment/pin/:id
- 验证请求者权限,确保UP主或管理员具有置顶评论的权限。
- 更新
comment_index表,将特定评论设为置顶状态,并记录置顶时间。 - 置顶操作可能需要更新其他已置顶评论的状态,确保置顶规则(如只允许一个置顶评论)。
- 对置顶操作使用事务确保数据一致性。
- 置顶评论的索引需要优先级排序,以便快速检索。
- 可以对置顶评论使用缓存,以便快速访问。
POST /v1/comment/highlight/:id
- 验证请求者权限,确保UP主或管理员具有精选评论的权限。
- 在
comment_index表中更新特定评论的精选状态。 - 精选评论可能需要特别的展示逻辑和标签。
- 使用事务确保数据一致性。
- 对精选评论进行索引和缓存,以提高访问速度。
- 精选评论的展示可能会增加查询复杂度,需要优化查询逻辑。
通过这些接口,用户可以轻松地添加、删除、互动和管理评论。为了确保系统的扩展性和高性能,建议使用微服务架构,将评论系统作为独立的服务来构建和维护。这样可以在不影响其他系统模块的情况下,独立地扩展和优化评论系统。
8.1B站评论系统架构设计
8.7架构设计之评论系统