[Support] Vendor rpmalloc in-tree and use it for the Windows 64-bit release #91862
Conversation
|
@llvm/pr-subscribers-platform-windows @llvm/pr-subscribers-llvm-support Author: Alexandre Ganea (aganea) ChangesContextWe have a longstanding performance issue on Windows, where to this day, the default heap allocator is still lockfull. With the number of cores increasing, building and using LLVM with the default Windows heap allocator is sub-optimal. Notably, the ThinLTO link times with LLD are extremely long, and increase proportionally with the number of cores in the machine. In a6a37a2, I introduced the ability build LLVM with several popular lock-free allocators. Downstream users however have to build their own toolchain with this option, and building an optimal toolchain is a bit tedious and long. Additionally, LLVM is now integrated into Visual Studio, which AFAIK re-distributes the vanilla LLVM binaries/installer. The point being that many users are impacted and might not be aware of this problem, or are unable to build a more optimal version of the toolchain. The symptom before this PR is that most of the CPU times goes to the kernel (darker blue) when linking with ThinLTO:
With this PR, most time is spent in user space (light blue):
On higher core count machines, before this PR, the CPU usage becomes pretty much flat because of contention: <img width="549" alt="VM_176_windows_heap" src="https://github.com/llvm/llvm-project/assets/37383324/f27d5800-ee02-496d-a4e7-88177e0727f0"> With this PR, similarily most CPU time is now used: <img width="549" alt="VM_176_with_rpmalloc" src="https://github.com/llvm/llvm-project/assets/37383324/7d4785dd-94a7-4f06-9b16-aaa4e2e505c8"> Changes in this PRThe avenue I've taken here is to vendor/re-licence rpmalloc in-tree, and use it when building the Windows 64-bit release. Given the permissive rpmalloc licence, prior discussions with the LLVM foundation and @lattner suggested this vendoring. Rpmalloc's author (@mjansson) kindly agreed to donate the code to LLVM (please do correct me if I misinterpreted our past communications). I've chosen rpmalloc because it's small and gives the best value overall. The source code is only 4 .c files. Rpmalloc is statically replacing the weak CRT alloc symbols at link time, and has no dynamic patching like mimalloc. As an alternative, there were several unsuccessfull attempts made by Russell Gallop to use SCUDO in the past, please see thread in https://reviews.llvm.org/D86694. I've added a new cmake flag PerformanceThe most obvious test is profling a ThinLTO linking step with LLD. I've used a Clang compilation as a testbed, ie. I've profiled the linking step with no LTO cache, with Powershell, such as: Timings:
This also improves the overall performance when building with Clang. I've profiled a regular compilation of clang, ie: This saves approx. 30 sec when building Clang from scratch on the Threadripper PRO 3975WX: Patch is 220.05 KiB, truncated to 20.00 KiB below, full version: https://github.com/llvm/llvm-project/pull/91862.diff 11 Files Affected:
diff --git a/llvm/CMakeLists.txt b/llvm/CMakeLists.txt
index c06e661573ed4..4f20f8dbb1849 100644
--- a/llvm/CMakeLists.txt
+++ b/llvm/CMakeLists.txt
@@ -733,7 +733,24 @@ if( WIN32 AND NOT CYGWIN )
endif()
set(LLVM_NATIVE_TOOL_DIR "" CACHE PATH "Path to a directory containing prebuilt matching native tools (such as llvm-tblgen)")
-set(LLVM_INTEGRATED_CRT_ALLOC "" CACHE PATH "Replace the Windows CRT allocator with any of {rpmalloc|mimalloc|snmalloc}. Only works with CMAKE_MSVC_RUNTIME_LIBRARY=MultiThreaded.")
+set(LLVM_ENABLE_RPMALLOC "" CACHE BOOL "Replace the CRT allocator with rpmalloc.")
+if(LLVM_ENABLE_RPMALLOC)
+ if(NOT (CMAKE_SYSTEM_NAME MATCHES "Windows|Linux"))
+ message(FATAL_ERROR "LLVM_ENABLE_RPMALLOC is only supported on Windows and Linux.")
+ endif()
+ if(LLVM_USE_SANITIZER)
+ message(FATAL_ERROR "LLVM_ENABLE_RPMALLOC cannot be used along with LLVM_USE_SANITIZER!")
+ endif()
+ if(WIN32 AND CMAKE_BUILD_TYPE AND uppercase_CMAKE_BUILD_TYPE STREQUAL "DEBUG")
+ message(FATAL_ERROR "The Debug target isn't supported along with LLVM_ENABLE_RPMALLOC!")
+ endif()
+
+ # Override the C runtime allocator with the in-tree rpmalloc
+ set(LLVM_INTEGRATED_CRT_ALLOC "${CMAKE_CURRENT_SOURCE_DIR}/lib/Support")
+ set(CMAKE_MSVC_RUNTIME_LIBRARY "MultiThreaded")
+endif()
+
+set(LLVM_INTEGRATED_CRT_ALLOC "${LLVM_INTEGRATED_CRT_ALLOC}" CACHE PATH "Replace the Windows CRT allocator with any of {rpmalloc|mimalloc|snmalloc}. Only works with CMAKE_MSVC_RUNTIME_LIBRARY=MultiThreaded.")
if(LLVM_INTEGRATED_CRT_ALLOC)
if(NOT WIN32)
message(FATAL_ERROR "LLVM_INTEGRATED_CRT_ALLOC is only supported on Windows.")
diff --git a/llvm/docs/CMake.rst b/llvm/docs/CMake.rst
index 41ef5f40c6cf6..0b65e06d1d7b3 100644
--- a/llvm/docs/CMake.rst
+++ b/llvm/docs/CMake.rst
@@ -712,6 +712,16 @@ enabled sub-projects. Nearly all of these variable names begin with
This flag needs to be used along with the static CRT, ie. if building the
Release target, add -DCMAKE_MSVC_RUNTIME_LIBRARY=MultiThreaded.
+ Note that rpmalloc is also supported natively in-tree, for example:
+
+ .. code-block:: console
+
+ $ D:\llvm-project> cmake ... -DLLVM_ENABLE_RPMALLOC=ON
+
+**LLVM_ENABLE_RPMALLOC**:BOOL
+ Similar to LLVM_INTEGRATED_CRT_ALLOC, embeds the in-tree rpmalloc into the
+ host toolchain as a C runtime allocator. Requires linking with the static CRT,
+ if building the Release target, with: -DLLVM_USE_CRT_RELEASE=MT.
**LLVM_LINK_LLVM_DYLIB**:BOOL
If enabled, tools will be linked with the libLLVM shared library. Defaults
diff --git a/llvm/docs/ReleaseNotes.rst b/llvm/docs/ReleaseNotes.rst
index 59c0d4dd2376d..35910e20b3fff 100644
--- a/llvm/docs/ReleaseNotes.rst
+++ b/llvm/docs/ReleaseNotes.rst
@@ -62,6 +62,9 @@ Changes to LLVM infrastructure
Changes to building LLVM
------------------------
+* LLVM now supports rpmalloc in-tree, as a replacement C allocator for hosted
+ toolchains.
+
Changes to TableGen
-------------------
diff --git a/llvm/lib/Support/CMakeLists.txt b/llvm/lib/Support/CMakeLists.txt
index 03e888958a071..a7ba8aba25950 100644
--- a/llvm/lib/Support/CMakeLists.txt
+++ b/llvm/lib/Support/CMakeLists.txt
@@ -103,9 +103,10 @@ if(LLVM_INTEGRATED_CRT_ALLOC)
message(FATAL_ERROR "Cannot find the path to `git clone` for the CRT allocator! (${LLVM_INTEGRATED_CRT_ALLOC}). Currently, rpmalloc, snmalloc and mimalloc are supported.")
endif()
- if(LLVM_INTEGRATED_CRT_ALLOC MATCHES "rpmalloc$")
+ if((LLVM_INTEGRATED_CRT_ALLOC MATCHES "rpmalloc$") OR LLVM_ENABLE_RPMALLOC)
add_compile_definitions(ENABLE_OVERRIDE ENABLE_PRELOAD)
set(ALLOCATOR_FILES "${LLVM_INTEGRATED_CRT_ALLOC}/rpmalloc/rpmalloc.c")
+ set(delayload_flags "${delayload_flags} -INCLUDE:malloc")
elseif(LLVM_INTEGRATED_CRT_ALLOC MATCHES "snmalloc$")
set(ALLOCATOR_FILES "${LLVM_INTEGRATED_CRT_ALLOC}/src/snmalloc/override/new.cc")
set(system_libs ${system_libs} "mincore.lib" "-INCLUDE:malloc")
diff --git a/llvm/lib/Support/rpmalloc/CACHE.md b/llvm/lib/Support/rpmalloc/CACHE.md
new file mode 100644
index 0000000000000..052320baf5327
--- /dev/null
+++ b/llvm/lib/Support/rpmalloc/CACHE.md
@@ -0,0 +1,19 @@
+# Thread caches
+rpmalloc has a thread cache of free memory blocks which can be used in allocations without interfering with other threads or going to system to map more memory, as well as a global cache shared by all threads to let spans of memory pages flow between threads. Configuring the size of these caches can be crucial to obtaining good performance while minimizing memory overhead blowup. Below is a simple case study using the benchmark tool to compare different thread cache configurations for rpmalloc.
+
+The rpmalloc thread cache is configured to be unlimited, performance oriented as meaning default values, size oriented where both thread cache and global cache is reduced significantly, or disabled where both thread and global caches are disabled and completely free pages are directly unmapped.
+
+The benchmark is configured to run threads allocating 150000 blocks distributed in the `[16, 16000]` bytes range with a linear falloff probability. It runs 1000 loops, and every iteration 75000 blocks (50%) are freed and allocated in a scattered pattern. There are no cross thread allocations/deallocations. Parameters: `benchmark n 0 0 0 1000 150000 75000 16 16000`. The benchmarks are run on an Ubuntu 16.10 machine with 8 cores (4 physical, HT) and 12GiB RAM.
+
+The benchmark also includes results for the standard library malloc implementation as a reference for comparison with the nocache setting.
+
+![Ubuntu 16.10 random [16, 16000] bytes, 8 cores](https://docs.google.com/spreadsheets/d/1NWNuar1z0uPCB5iVS_Cs6hSo2xPkTmZf0KsgWS_Fb_4/pubchart?oid=387883204&format=image)
+![Ubuntu 16.10 random [16, 16000] bytes, 8 cores](https://docs.google.com/spreadsheets/d/1NWNuar1z0uPCB5iVS_Cs6hSo2xPkTmZf0KsgWS_Fb_4/pubchart?oid=1644710241&format=image)
+
+For single threaded case the unlimited cache and performance oriented cache settings have identical performance and memory overhead, indicating that the memory pages fit in the combined thread and global cache. As number of threads increase to 2-4 threads, the performance settings have slightly higher performance which can seem odd at first, but can be explained by low contention on the global cache where some memory pages can flow between threads without stalling, reducing the overall number of calls to map new memory pages (also indicated by the slightly lower memory overhead).
+
+As threads increase even more to 5-10 threads, the increased contention and eventual limit of global cache cause the unlimited setting to gain a slight advantage in performance. As expected the memory overhead remains constant for unlimited caches, while going down for performance setting when number of threads increases.
+
+The size oriented setting maintain good performance compared to the standard library while reducing the memory overhead compared to the performance setting with a decent amount.
+
+The nocache setting still outperforms the reference standard library allocator for workloads up to 6 threads while maintaining a near zero memory overhead, which is even slightly lower than the standard library. For use case scenarios where number of allocation of each size class is lower the overhead in rpmalloc from the 64KiB span size will of course increase.
diff --git a/llvm/lib/Support/rpmalloc/README.md b/llvm/lib/Support/rpmalloc/README.md
new file mode 100644
index 0000000000000..5fba25ebc8095
--- /dev/null
+++ b/llvm/lib/Support/rpmalloc/README.md
@@ -0,0 +1,173 @@
+# rpmalloc - General Purpose Memory Allocator
+This library provides a public domain cross platform lock free thread caching 16-byte aligned memory allocator implemented in C. The latest source code is always available at https://github.com/mjansson/rpmalloc
+
+Created by Mattias Jansson ([@maniccoder](https://twitter.com/maniccoder)) - Discord server for discussions at https://discord.gg/M8BwTQrt6c
+
+Platforms currently supported:
+
+- Windows
+- MacOS
+- iOS
+- Linux
+- Android
+- Haiku
+
+The code should be easily portable to any platform with atomic operations and an mmap-style virtual memory management API. The API used to map/unmap memory pages can be configured in runtime to a custom implementation and mapping granularity/size.
+
+This library is put in the public domain; you can redistribute it and/or modify it without any restrictions. Or, if you choose, you can use it under the MIT license.
+
+# Performance
+We believe rpmalloc is faster than most popular memory allocators like tcmalloc, hoard, ptmalloc3 and others without causing extra allocated memory overhead in the thread caches compared to these allocators. We also believe the implementation to be easier to read and modify compared to these allocators, as it is a single source file of ~3000 lines of C code. All allocations have a natural 16-byte alignment.
+
+Contained in a parallel repository is a benchmark utility that performs interleaved unaligned allocations and deallocations (both in-thread and cross-thread) in multiple threads. It measures number of memory operations performed per CPU second, as well as memory overhead by comparing the virtual memory mapped with the number of bytes requested in allocation calls. The setup of number of thread, cross-thread deallocation rate and allocation size limits is configured by command line arguments.
+
+https://github.com/mjansson/rpmalloc-benchmark
+
+Below is an example performance comparison chart of rpmalloc and other popular allocator implementations, with default configurations used.
+
+![Ubuntu 16.10, random [16, 8000] bytes, 8 cores](https://docs.google.com/spreadsheets/d/1NWNuar1z0uPCB5iVS_Cs6hSo2xPkTmZf0KsgWS_Fb_4/pubchart?oid=301017877&format=image)
+
+The benchmark producing these numbers were run on an Ubuntu 16.10 machine with 8 logical cores (4 physical, HT). The actual numbers are not to be interpreted as absolute performance figures, but rather as relative comparisons between the different allocators. For additional benchmark results, see the [BENCHMARKS](BENCHMARKS.md) file.
+
+Configuration of the thread and global caches can be important depending on your use pattern. See [CACHE](CACHE.md) for a case study and some comments/guidelines.
+
+# Required functions
+
+Before calling any other function in the API, you __MUST__ call the initialization function, either __rpmalloc_initialize__ or __rpmalloc_initialize_config__, or you will get undefined behaviour when calling other rpmalloc entry point.
+
+Before terminating your use of the allocator, you __SHOULD__ call __rpmalloc_finalize__ in order to release caches and unmap virtual memory, as well as prepare the allocator for global scope cleanup at process exit or dynamic library unload depending on your use case.
+
+# Using
+The easiest way to use the library is simply adding __rpmalloc.[h|c]__ to your project and compile them along with your sources. This contains only the rpmalloc specific entry points and does not provide internal hooks to process and/or thread creation at the moment. You are required to call these functions from your own code in order to initialize and finalize the allocator in your process and threads:
+
+__rpmalloc_initialize__ : Call at process start to initialize the allocator
+
+__rpmalloc_initialize_config__ : Optional entry point to call at process start to initialize the allocator with a custom memory mapping backend, memory page size and mapping granularity.
+
+__rpmalloc_finalize__: Call at process exit to finalize the allocator
+
+__rpmalloc_thread_initialize__: Call at each thread start to initialize the thread local data for the allocator
+
+__rpmalloc_thread_finalize__: Call at each thread exit to finalize and release thread cache back to global cache
+
+__rpmalloc_config__: Get the current runtime configuration of the allocator
+
+Then simply use the __rpmalloc__/__rpfree__ and the other malloc style replacement functions. Remember all allocations are 16-byte aligned, so no need to call the explicit rpmemalign/rpaligned_alloc/rpposix_memalign functions unless you need greater alignment, they are simply wrappers to make it easier to replace in existing code.
+
+If you wish to override the standard library malloc family of functions and have automatic initialization/finalization of process and threads, define __ENABLE_OVERRIDE__ to non-zero which will include the `malloc.c` file in compilation of __rpmalloc.c__. The list of libc entry points replaced may not be complete, use libc replacement only as a convenience for testing the library on an existing code base, not a final solution.
+
+For explicit first class heaps, see the __rpmalloc_heap_*__ API under [first class heaps](#first-class-heaps) section, requiring __RPMALLOC_FIRST_CLASS_HEAPS__ tp be defined to 1.
+
+# Building
+To compile as a static library run the configure python script which generates a Ninja build script, then build using ninja. The ninja build produces two static libraries, one named `rpmalloc` and one named `rpmallocwrap`, where the latter includes the libc entry point overrides.
+
+The configure + ninja build also produces two shared object/dynamic libraries. The `rpmallocwrap` shared library can be used with LD_PRELOAD/DYLD_INSERT_LIBRARIES to inject in a preexisting binary, replacing any malloc/free family of function calls. This is only implemented for Linux and macOS targets. The list of libc entry points replaced may not be complete, use preloading as a convenience for testing the library on an existing binary, not a final solution. The dynamic library also provides automatic init/fini of process and threads for all platforms.
+
+The latest stable release is available in the master branch. For latest development code, use the develop branch.
+
+# Cache configuration options
+Free memory pages are cached both per thread and in a global cache for all threads. The size of the thread caches is determined by an adaptive scheme where each cache is limited by a percentage of the maximum allocation count of the corresponding size class. The size of the global caches is determined by a multiple of the maximum of all thread caches. The factors controlling the cache sizes can be set by editing the individual defines in the `rpmalloc.c` source file for fine tuned control.
+
+__ENABLE_UNLIMITED_CACHE__: By default defined to 0, set to 1 to make all caches infinite, i.e never release spans to global cache unless thread finishes and never unmap memory pages back to the OS. Highest performance but largest memory overhead.
+
+__ENABLE_UNLIMITED_GLOBAL_CACHE__: By default defined to 0, set to 1 to make global caches infinite, i.e never unmap memory pages back to the OS.
+
+__ENABLE_UNLIMITED_THREAD_CACHE__: By default defined to 0, set to 1 to make thread caches infinite, i.e never release spans to global cache unless thread finishes.
+
+__ENABLE_GLOBAL_CACHE__: By default defined to 1, enables the global cache shared between all threads. Set to 0 to disable the global cache and directly unmap pages evicted from the thread cache.
+
+__ENABLE_THREAD_CACHE__: By default defined to 1, enables the per-thread cache. Set to 0 to disable the thread cache and directly unmap pages no longer in use (also disables the global cache).
+
+__ENABLE_ADAPTIVE_THREAD_CACHE__: Introduces a simple heuristics in the thread cache size, keeping 25% of the high water mark for each span count class.
+
+# Other configuration options
+Detailed statistics are available if __ENABLE_STATISTICS__ is defined to 1 (default is 0, or disabled), either on compile command line or by setting the value in `rpmalloc.c`. This will cause a slight overhead in runtime to collect statistics for each memory operation, and will also add 4 bytes overhead per allocation to track sizes.
+
+Integer safety checks on all calls are enabled if __ENABLE_VALIDATE_ARGS__ is defined to 1 (default is 0, or disabled), either on compile command line or by setting the value in `rpmalloc.c`. If enabled, size arguments to the global entry points are verified not to cause integer overflows in calculations.
+
+Asserts are enabled if __ENABLE_ASSERTS__ is defined to 1 (default is 0, or disabled), either on compile command line or by setting the value in `rpmalloc.c`.
+
+To include __malloc.c__ in compilation and provide overrides of standard library malloc entry points define __ENABLE_OVERRIDE__ to 1. To enable automatic initialization of finalization of process and threads in order to preload the library into executables using standard library malloc, define __ENABLE_PRELOAD__ to 1.
+
+To enable the runtime configurable memory page and span sizes, define __RPMALLOC_CONFIGURABLE__ to 1. By default, memory page size is determined by system APIs and memory span size is set to 64KiB.
+
+To enable support for first class heaps, define __RPMALLOC_FIRST_CLASS_HEAPS__ to 1. By default, the first class heap API is disabled.
+
+# Huge pages
+The allocator has support for huge/large pages on Windows, Linux and MacOS. To enable it, pass a non-zero value in the config value `enable_huge_pages` when initializing the allocator with `rpmalloc_initialize_config`. If the system does not support huge pages it will be automatically disabled. You can query the status by looking at `enable_huge_pages` in the config returned from a call to `rpmalloc_config` after initialization is done.
+
+# Quick overview
+The allocator is similar in spirit to tcmalloc from the [Google Performance Toolkit](https://github.com/gperftools/gperftools). It uses separate heaps for each thread and partitions memory blocks according to a preconfigured set of size classes, up to 2MiB. Larger blocks are mapped and unmapped directly. Allocations for different size classes will be served from different set of memory pages, each "span" of pages is dedicated to one size class. Spans of pages can flow between threads when the thread cache overflows and are released to a global cache, or when the thread ends. Unlike tcmalloc, single blocks do not flow between threads, only entire spans of pages.
+
+# Implementation details
+The allocator is based on a fixed but configurable page alignment (defaults to 64KiB) and 16 byte block alignment, where all runs of memory pages (spans) are mapped to this alignment boundary. On Windows this is automatically guaranteed up to 64KiB by the VirtualAlloc granularity, and on mmap systems it is achieved by oversizing the mapping and aligning the returned virtual memory address to the required boundaries. By aligning to a fixed size the free operation can locate the header of the memory span without having to do a table lookup (as tcmalloc does) by simply masking out the low bits of the address (for 64KiB this would be the low 16 bits).
+
+Memory blocks are divided into three categories. For 64KiB span size/alignment the small blocks are [16, 1024] bytes, medium blocks (1024, 32256] bytes, and large blocks (32256, 2097120] bytes. The three categories are further divided in size classes. If the span size is changed, the small block classes remain but medium blocks go from (1024, span size] bytes.
+
+Small blocks have a size class granularity of 16 bytes each in 64 buckets. Medium blocks have a granularity of 512 bytes, 61 buckets (default). Large blocks have the same granularity as the configured span size (default 64KiB). All allocations are fitted to these size class boundaries (an allocation of 36 bytes will allocate a block of 48 bytes). Each small and medium size class has an associated span (meaning a contiguous set of memory pages) configuration describing how many pages the size class will allocate each time the cache is empty and a new allocation is requested.
+
+Spans for small and medium blocks are cached in four levels to avoid calls to map/unmap memory pages. The first level is a per thread single active span for each size class. The second level is a per thread list of partially free spans for each size class. The third level is a per thread list of free spans. The fourth level is a global list of free spans.
+
+Each span for a small and medium size class keeps track of how many blocks are allocated/free, as well as a list of which blocks that are free for allocation. To...
[truncated]
|


|
✅ With the latest revision this PR passed the C/C++ code formatter. |
|
@mjansson, as the original author of much of this code can you please confirm on this thread that you are consenting to it being contributed under the LLVM licensing terms? The current licensing terms are documented in the developer policy here: https://github.com/llvm/llvm-project/blob/main/llvm/docs/DeveloperPolicy.rst#copyright-license-and-patents. At the moment this requires all code to be licensed under both the new Apache w/ LLVM license and the legacy NCSA license. There is a plan to only require the new license in the future (see: https://discourse.llvm.org/t/relicensing-next-step-dropping-requirement-to-contribute-also-under-the-legacy-license/78351), but for now all code contributed must be available under either license. Thank you! |
|
As author of rpmalloc I consent to it being contributed under the LLVM licensing terms, both the new Apache w/ LLVM license and the legacy NCSA license. |
|
Sounds great to me. Getting this into the windows packages without having to jump through hoops will be very nice (and I look forward to removing the hoop jumping we do in Chromium's clang build script). I assume this is picking up the latest rpmalloc release (1.4.5)? We should document somewhere what exact version is being used. Is there a plan for keeping llvm's rpmalloc copy up-to-date? Do we want to keep the general |
I've upgraded to 1.4.5 and added the version number information in README.md
I would assume after the initial commit, upgrades would be as regular contributions?
I would keep it for now for testing other allocators. I still find mimalloc being a very good contender and I hope it'll be eventually integrated into Windows through the application manifest maybe. Also, it'd be good if someone with SCUDO experience would make it work with |
If we keep it around - maybe we need to update the documentation to point out that using RPMALLOC is the most supported way and that this option is only for testing other allocators? Seems like we want people to use the vendored version of rpmalloc most of the time. |
I've updated the |
|
Just for reference, latest MSVC 17.9.7 is litteraly twice as slow to build LLVM, as compared to this current PR: Some of the LLVM source files seem to be hitting a quadratic behavior somewhere in MSVC: https://developercommunity.visualstudio.com/t/ON2-in-SparseBitVectorBase-when-com/10657991 |
|
Gentle ping! What do you all think the way forward is with this patch? Is anything else to be done here? Does this need wider adoption from the community? (as in a RFC) |
|
I think that the legal aspects have been resolved right? At that point, we should consider getting this into the tree so that others can easily play with it. I know that I am interested in exploring this as an alternative memory allocator for the Swift compiler as well. |
|
Yeah. I think we should merge it, it's off by default so it won't affect people. |
|
I think there are still some unresolved comments from my review, but I'm all for getting this merged. |
@zmodem Could you please point me specifically to which comments were unresolved? I think I’ve answered here: #91862 (comment) |
There was a problem hiding this comment.
I think there are still some unresolved comments from my review, but I'm all for getting this merged.
@zmodem Could you please point me specifically to which comments were unresolved? I think I’ve answered here: #91862 (comment)
Sorry, my fault. It seems my comments were still "pending" :(
|
Many thanks to everyone for making this happen! I'll give it a few more days in case there're more comments. |
…elease (llvm#91862) ### Context We have a longstanding performance issue on Windows, where to this day, the default heap allocator is still lockfull. With the number of cores increasing, building and using LLVM with the default Windows heap allocator is sub-optimal. Notably, the ThinLTO link times with LLD are extremely long, and increase proportionally with the number of cores in the machine. In llvm@a6a37a2, I introduced the ability build LLVM with several popular lock-free allocators. Downstream users however have to build their own toolchain with this option, and building an optimal toolchain is a bit tedious and long. Additionally, LLVM is now integrated into Visual Studio, which AFAIK re-distributes the vanilla LLVM binaries/installer. The point being that many users are impacted and might not be aware of this problem, or are unable to build a more optimal version of the toolchain. The symptom before this PR is that most of the CPU time goes to the kernel (darker blue) when linking with ThinLTO: 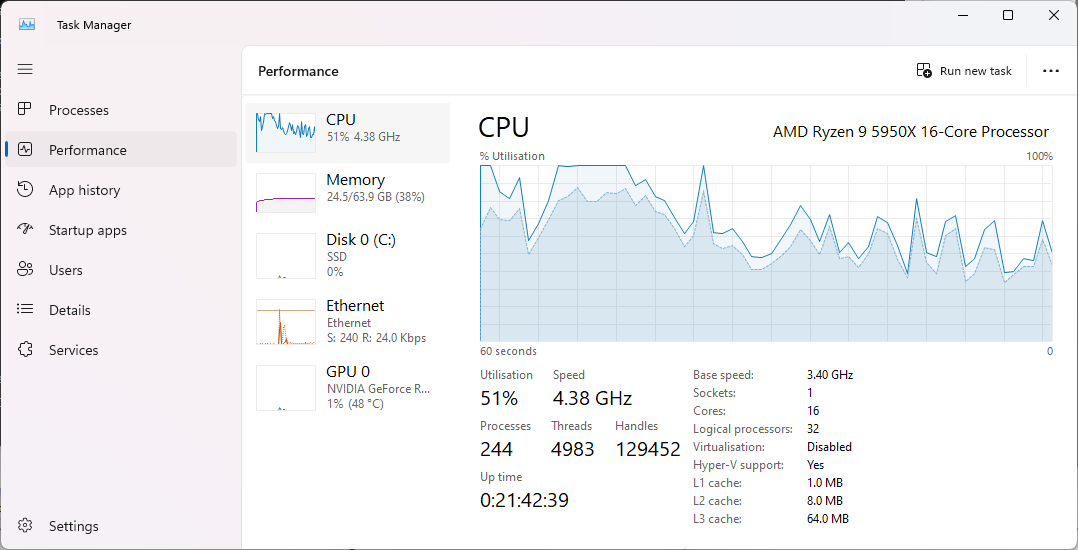 With this PR, most time is spent in user space (light blue):  On higher core count machines, before this PR, the CPU usage becomes pretty much flat because of contention: <img width="549" alt="VM_176_windows_heap" src="https://github.com/llvm/llvm-project/assets/37383324/f27d5800-ee02-496d-a4e7-88177e0727f0"> With this PR, similarily most CPU time is now used: <img width="549" alt="VM_176_with_rpmalloc" src="https://github.com/llvm/llvm-project/assets/37383324/7d4785dd-94a7-4f06-9b16-aaa4e2e505c8"> ### Changes in this PR The avenue I've taken here is to vendor/re-licence rpmalloc in-tree, and use it when building the Windows 64-bit release. Given the permissive rpmalloc licence, prior discussions with the LLVM foundation and @lattner suggested this vendoring. Rpmalloc's author (@mjansson) kindly agreed to ~~donate~~ re-licence the rpmalloc code in LLVM (please do correct me if I misinterpreted our past communications). I've chosen rpmalloc because it's small and gives the best value overall. The source code is only 4 .c files. Rpmalloc is statically replacing the weak CRT alloc symbols at link time, and has no dynamic patching like mimalloc. As an alternative, there were several unsuccessfull attempts made by Russell Gallop to use SCUDO in the past, please see thread in https://reviews.llvm.org/D86694. If later someone comes up with a PR of similar performance that uses SCUDO, we could then delete this vendored rpmalloc folder. I've added a new cmake flag `LLVM_ENABLE_RPMALLOC` which essentialy sets `LLVM_INTEGRATED_CRT_ALLOC` to the in-tree rpmalloc source. ### Performance The most obvious test is profling a ThinLTO linking step with LLD. I've used a Clang compilation as a testbed, ie. ``` set OPTS=/GS- /D_ITERATOR_DEBUG_LEVEL=0 -Xclang -O3 -fstrict-aliasing -march=native -flto=thin -fwhole-program-vtables -fuse-ld=lld cmake -G Ninja %ROOT%/llvm -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_ASSERTIONS=TRUE -DLLVM_ENABLE_PROJECTS="clang" -DLLVM_ENABLE_PDB=ON -DLLVM_OPTIMIZED_TABLEGEN=ON -DCMAKE_C_COMPILER=clang-cl.exe -DCMAKE_CXX_COMPILER=clang-cl.exe -DCMAKE_LINKER=lld-link.exe -DLLVM_ENABLE_LLD=ON -DCMAKE_CXX_FLAGS="%OPTS%" -DCMAKE_C_FLAGS="%OPTS%" -DLLVM_ENABLE_LTO=THIN ``` I've profiled the linking step with no LTO cache, with Powershell, such as: ``` Measure-Command { lld-link /nologo @CMakeFiles\clang.rsp /out:bin\clang.exe /implib:lib\clang.lib /pdb:bin\clang.pdb /version:0.0 /machine:x64 /STACK:10000000 /DEBUG /OPT:REF /OPT:ICF /INCREMENTAL:NO /subsystem:console /MANIFEST:EMBED,ID=1 }` ``` Timings: | Machine | Allocator | Time to link | |--------|--------|--------| | 16c/32t AMD Ryzen 9 5950X | Windows Heap | 10 min 38 sec | | | **Rpmalloc** | **4 min 11 sec** | | 32c/64t AMD Ryzen Threadripper PRO 3975WX | Windows Heap | 23 min 29 sec | | | **Rpmalloc** | **2 min 11 sec** | | | **Rpmalloc + /threads:64** | **1 min 50 sec** | | 176 vCPU (2 socket) Intel Xeon Platinium 8481C (fixed clock 2.7 GHz) | Windows Heap | 43 min 40 sec | | | **Rpmalloc** | **1 min 45 sec** | This also improves the overall performance when building with clang-cl. I've profiled a regular compilation of clang itself, ie: ``` set OPTS=/GS- /D_ITERATOR_DEBUG_LEVEL=0 /arch:AVX -fuse-ld=lld cmake -G Ninja %ROOT%/llvm -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_ASSERTIONS=TRUE -DLLVM_ENABLE_PROJECTS="clang;lld" -DLLVM_ENABLE_PDB=ON -DLLVM_OPTIMIZED_TABLEGEN=ON -DCMAKE_C_COMPILER=clang-cl.exe -DCMAKE_CXX_COMPILER=clang-cl.exe -DCMAKE_LINKER=lld-link.exe -DLLVM_ENABLE_LLD=ON -DCMAKE_CXX_FLAGS="%OPTS%" -DCMAKE_C_FLAGS="%OPTS%" ``` This saves approx. 30 sec when building on the Threadripper PRO 3975WX: ``` (default Windows Heap) C:\src\git\llvm-project>hyperfine -r 5 -p "make_llvm.bat stage1_test2" "ninja clang -C stage1_test2" Benchmark 1: ninja clang -C stage1_test2 Time (mean ± σ): 392.716 s ± 3.830 s [User: 17734.025 s, System: 1078.674 s] Range (min … max): 390.127 s … 399.449 s 5 runs (rpmalloc) C:\src\git\llvm-project>hyperfine -r 5 -p "make_llvm.bat stage1_test2" "ninja clang -C stage1_test2" Benchmark 1: ninja clang -C stage1_test2 Time (mean ± σ): 360.824 s ± 1.162 s [User: 15148.637 s, System: 905.175 s] Range (min … max): 359.208 s … 362.288 s 5 runs ```
| set(LLVM_ENABLE_RPMALLOC "" CACHE BOOL "Replace the CRT allocator with rpmalloc.") | ||
| if(LLVM_ENABLE_RPMALLOC) | ||
| if(NOT (CMAKE_SYSTEM_NAME MATCHES "Windows|Linux")) | ||
| message(FATAL_ERROR "LLVM_ENABLE_RPMALLOC is only supported on Windows and Linux.") |
There was a problem hiding this comment.
Only supported on Windows, surely? Since it relies on LLVM_INTEGRATED_CRT_ALLOC which is only supported on Windows (see line 767 below).
| @@ -163,6 +163,7 @@ set common_cmake_flags=^ | |||
| -DCLANG_ENABLE_LIBXML2=OFF ^ | |||
| -DCMAKE_C_FLAGS="%common_compiler_flags%" ^ | |||
| -DCMAKE_CXX_FLAGS="%common_compiler_flags%" ^ | |||
| -DLLVM_ENABLE_RPMALLOC=ON ^ | |||
There was a problem hiding this comment.
I didn't catch this at the time, but this enables the use of rpmalloc also for 32-bit x86, which doesn't work. See #106969
) because that doesn't work (results in `LINK : error LNK2001: unresolved external symbol malloc`). Based on the title of #91862 it was only intended for use in 64-bit builds.
…#106969) because that doesn't work (results in `LINK : error LNK2001: unresolved external symbol malloc`). Based on the title of llvm#91862 it was only intended for use in 64-bit builds. (cherry picked from commit ef26afc)
…#106969) because that doesn't work (results in `LINK : error LNK2001: unresolved external symbol malloc`). Based on the title of llvm#91862 it was only intended for use in 64-bit builds. (cherry picked from commit ef26afc)
|
Hi @aganea, just to check my understanding LLVM_ENABLE_RPMALLOC will replace default allocator used on Windows build and will not only help with ThinLTO but also with compilation speed? |
|
@stefan-il Please see discussion in https://reviews.llvm.org/D101427 especially last comment by @MaskRay. We could encode those linker flags for ease of use perhaps, when LLVM_ENABLE_RPMALLOC is used, if someone wants to do it. |
Context
We have a longstanding performance issue on Windows, where to this day, the default heap allocator is still lockfull. With the number of cores increasing, building and using LLVM with the default Windows heap allocator is sub-optimal. Notably, the ThinLTO link times with LLD are extremely long, and increase proportionally with the number of cores in the machine.
In a6a37a2, I introduced the ability build LLVM with several popular lock-free allocators. Downstream users however have to build their own toolchain with this option, and building an optimal toolchain is a bit tedious and long. Additionally, LLVM is now integrated into Visual Studio, which AFAIK re-distributes the vanilla LLVM binaries/installer. The point being that many users are impacted and might not be aware of this problem, or are unable to build a more optimal version of the toolchain.
The symptom before this PR is that most of the CPU time goes to the kernel (darker blue) when linking with ThinLTO:
With this PR, most time is spent in user space (light blue):
On higher core count machines, before this PR, the CPU usage becomes pretty much flat because of contention:
With this PR, similarily most CPU time is now used:
Changes in this PR
The avenue I've taken here is to vendor/re-licence rpmalloc in-tree, and use it when building the Windows 64-bit release. Given the permissive rpmalloc licence, prior discussions with the LLVM foundation and @lattner suggested this vendoring. Rpmalloc's author (@mjansson) kindly agreed to
donatere-licence the rpmalloc code in LLVM (please do correct me if I misinterpreted our past communications).I've chosen rpmalloc because it's small and gives the best value overall. The source code is only 4 .c files. Rpmalloc is statically replacing the weak CRT alloc symbols at link time, and has no dynamic patching like mimalloc. As an alternative, there were several unsuccessfull attempts made by Russell Gallop to use SCUDO in the past, please see thread in https://reviews.llvm.org/D86694. If later someone comes up with a PR of similar performance that uses SCUDO, we could then delete this vendored rpmalloc folder.
I've added a new cmake flag
LLVM_ENABLE_RPMALLOCwhich essentialy setsLLVM_INTEGRATED_CRT_ALLOCto the in-tree rpmalloc source.Performance
The most obvious test is profling a ThinLTO linking step with LLD. I've used a Clang compilation as a testbed, ie.
I've profiled the linking step with no LTO cache, with Powershell, such as:
Timings:
This also improves the overall performance when building with clang-cl. I've profiled a regular compilation of clang itself, ie:
This saves approx. 30 sec when building on the Threadripper PRO 3975WX: