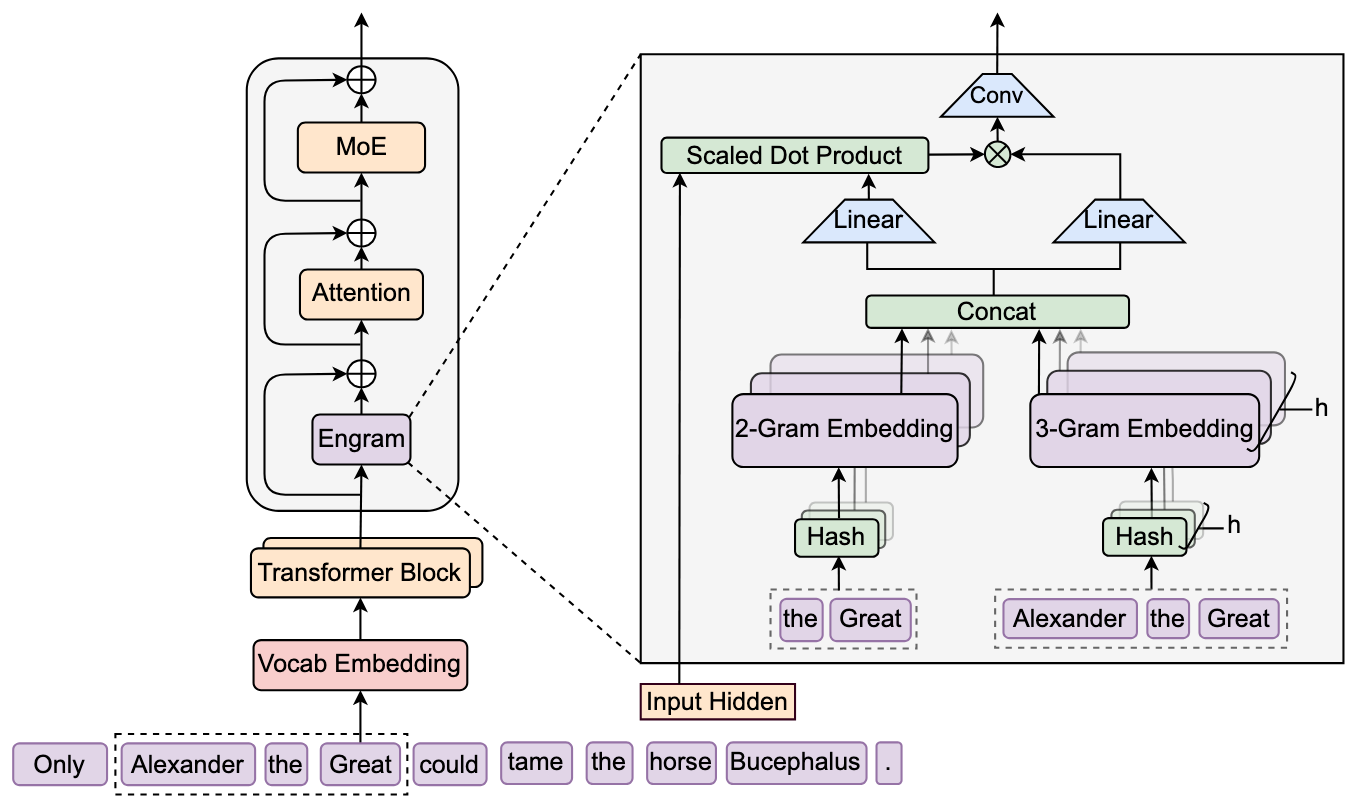
This repository contains the unofficial implementation for the paper: Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models.
from engram import EngramConfig, EngramTokenizer, EngramModule
from transformers import AutoTokenizer
hf_tokenizer = AutoTokenizer.from_pretrained("gpt2")
k = 5 # Knowledge scaling
config = EngramConfig(
hidden_size=1024,
engram_vocab_size=len(hf_tokenizer),
max_ngram_size=3,
engram_table_size=[len(hf_tokenizer) * k, len(hf_tokenizer) * k],
n_embed_per_ngram=512,
n_head_per_ngram=8,
hc_mult=1, # 1 for Dense model, 4 for DeepSeek-V3
pad_id=hf_tokenizer.pad_token,
seed=42,
use_offload=False,
# offload_cache_lines=1024
)
layer_ids = [1, 5] # gpt2 has 12 layers, we use layer[1] and layer[5] for testing
engram_tokenizer = EngramTokenizer(config, hf_tokenizer, layer_ids=layer_ids)
vocab_sizes_1 = engram_tokenizer.vocab_distributions[layer_ids[0]]
engram_1 = EngramModule(config, vocab_sizes_1)
vocab_sizes_6 = engram_tokenizer.vocab_distributions[layer_ids[1]]
engram_6 = EngramModule(config, vocab_sizes_6)demo with GPT data flow
class Block(nn.Module):
def __init__(self, cfg, layer_id: int):
super().__init__()
# ...
self.engram = None
if cfg.engram and layer_id in cfg.engram.layer_ids:
self.engram = EngramModule(
config=cfg.engram.cfg,
layer_vocab_sizes=cfg.engram.tokenizer.vocab_distributions[layer_id],
)
def forward(self, hs, hi):
if self.engram and hi is not None:
hs = self.engram(hs, hi) + hs
hs = hs + self.attn(self.ln1(hs))
hs = hs + self.mlp(self.ln2(hs))
return hs
class GPT(nn.Module):
def forward(self, idx: "torch.Tensor", targets=None):
x = self.wte(idx)
for layer_id, block in enumerate(self.transformer.h):
hash_idx = None
if layer_id in self.cfg.engram.layer_ids:
hash_idx = self.cfg.engram.tokenizer.compress_and_hash(idx, layer_id)
hash_idx = torch.tensor(hash_idx).to(device=x.device)
x = block(x, hash_idx)
# ...Estimating the optimal K value for pre-trained model
from engram import EngramConfig, EngramTokenizer, EngramModule
from transformers import AutoTokenizer, AutoConfig, AutoModel
hf_tokenizer = AutoTokenizer.from_pretrained("gpt2")
hf_config = AutoConfig.from_pretrained("gpt2")
hf_model = AutoModel.from_pretrained("gpt2")
layer_ids = [1, hf_config.num_hidden_layers // 2]
hidden_size = 1024
n_embed_per_ngram = 512
n_head_per_ngram = 8
hc_mult = 1
max_ngram_size = 3
kernel_size = 4
model_params = sum(p.numel() for p in hf_model.parameters())
target_params = model_params / 3 # 80% -> FFN | 20% -> engram
num_layers = len(layer_ids)
vocab_size = len(hf_tokenizer)
num_orders = max_ngram_size - 1 # 2 orders: 2-gram, 3-gram
# Input dim = (orders * heads) * (embed_dim / heads) = orders * n_embed_per_ngram
engram_input_dim = num_orders * n_embed_per_ngram
# Params for: Value Proj + Key Projs (Linear layers connect to hidden_size)
proj_params = (engram_input_dim * hidden_size) + \
(hc_mult * engram_input_dim * hidden_size)
# Params for: Conv1d + RMSNorms (Approximate)
conv_params = (hidden_size * hc_mult) * kernel_size
misc_params = proj_params + conv_params
total_fixed_params = misc_params * num_layers
memory_budget = target_params - total_fixed_params
# Memory Params = Layers * [ (Orders * Vocab * k) * (n_embed / n_head) ]
# Solve for k:
embed_dim_per_head = n_embed_per_ngram // n_head_per_ngram
param_cost_per_k = num_layers * num_orders * vocab_size * embed_dim_per_head
if memory_budget > 0:
k = int(memory_budget / param_cost_per_k)
else:
k = 1
k = max(1, k)
print(f"Optimal k: {k}")
# -----------------
config = EngramConfig(
hidden_size=hidden_size,
engram_vocab_size=vocab_size,
engram_table_size=[vocab_size * k] * num_orders,
max_ngram_size=max_ngram_size,
n_embed_per_ngram=n_embed_per_ngram,
n_head_per_ngram=n_head_per_ngram,
hc_mult=hc_mult,
pad_id=hf_tokenizer.pad_token,
kernel_size=kernel_size,
seed=42,
)
engram_tokenizer = EngramTokenizer(config, hf_tokenizer, layer_ids=layer_ids)WIP