Este repositorio contiene el código fuente para generar un modelo predictivo del precio de la soja, utilizado en la competencia Meta-Data Matba-Rofex 2019. También se pueden reproducir los resultados enviados a la competencia.
Instalar lo necesario con:
pip3 install --user -r requirements.txtY correr el script con:
python3 main.pyEl resultado final aparecerá en la carpeta "results/". Las gráficas de este informe se pueden reproducir con:
python3 plot_results.pyAclaración: Dado el poco tiempo que se pudo destinar, este README es a fines de documentar la propuesta y no es exaustivo. El código puede tomarse como ejemplo (cumple la función) pero no es recomendable para usar como referencia. El modelo se entrenó en GPU; para correr en cpu, se puede cambiar "device=cuda" por "device=cpu" en el archivo "config". Los resultados pueden variar un poco con este cambio pero deberían ser similares, aunque demoran mucho más tiempo.
Se utilizó como entrada un conjunto simple de datos a partir del mercado de futuros de Matba Rofex (más información en el link a la competencia). Por una cuestión de tiempo no se exploraron los conjuntos de datos alternativos. Se filtraon las columnas que eran constantes en el tiempo. Para agregar información de estacionalidad se separaron a partir de la fecha del timestamp el día de la semana, mes y año. La extracción de información más compleja se dejo para la etapa del modelo.
Se propuso un modelo basado en aprendizaje profundo para generar predicciones en el tiempo, resumido en la Figura 1. Para más detalles, los hiperparámetros estan detallados en "soja_net.py". Estos hyperparámetros son el resultado de un diseño inicial, basado en experiencias previas con otros datos temporales, y un ajuste fino en función de los resultados obtenidos en particiones de optimización.
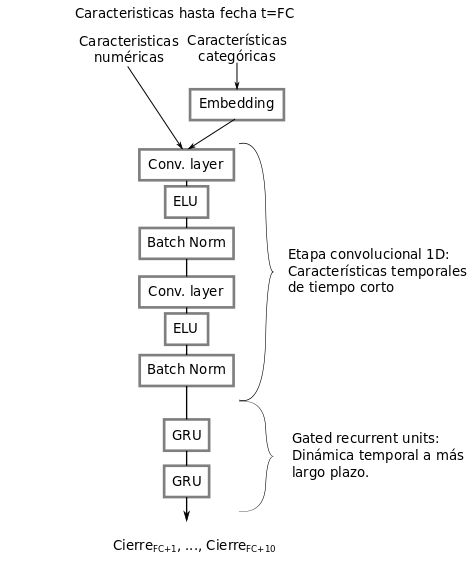
Figura 1: Esquema básico de la arquitectura de aprendizaje profundo utilizada.
El método de entrenamiento/validación también es simple pero mostró ser robusto para la predición de datos futuros. Dado que la serie temporal a predecir es una única fuente, se genearon particiones aleatorias en el tiempo para entrenar y evaluar el modelo. Se generaron puntos de evaluación aleatorios en el tiempo con una longitud de secuencia fija. Para controlar el MSE del modelo se tomaron las 10 fechas siguientes a la fecha de evaluación. Además se utilizó como valor de test la secuencia final de los datos disponibles, menos 10 fechas que son las utilizadas como test. En la Figura 2 se puede ver la evolución media y dispersión para diez modelos. Cada modelo fue entrenado con los mismos datos pero generando diferentes secuencias aleatorias.
Finalmente, para generar las predicciones se utilizaron todos los datos hasta la fecha de ciere (FC) 27/09/2019, y a partir de esto se generaron diez predicciones entre el 30/09 y el 11/10.
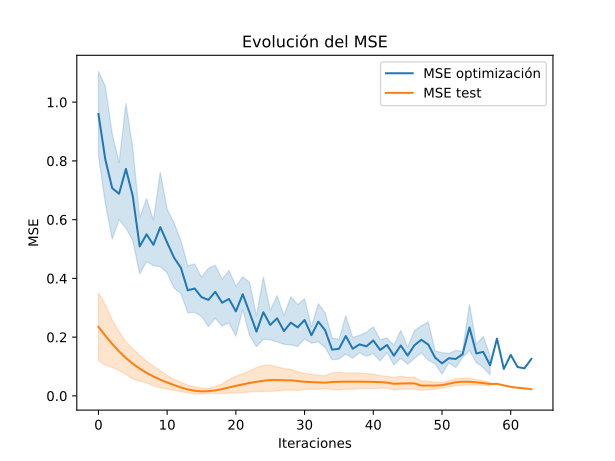
Figura 2: Evolución del MSE en optimización y test para diferentes experimentos.
La competencia constaba de tres objetivos. El primer objetivo consiste en predecir la serie de retornos simples a partir del valor al cierre de la tonelada de soja en los siguientes 10 días habiles a partir de la FC. En la Figura 3 se puede observar el valor al cierre una vez pasado el 11/10, obtenidos del centro de datos del Matba, junto a la predicción promedio y la diferencia entre cuartiles 25 y 75 de los modelos generados. Lógicamente, Se puede ver como las predicciones más cercanas tienen el menor error, incluso prediciendo la subida repentina del valor en la primera fecha. Tambien se puede ver que la varianza es mayor en las fechas donde el precio oscila más, alrededor del 02/10 y del 11/10, mientras que se reduce cuando los valores son constantes, aunque el error medio es mas alto.
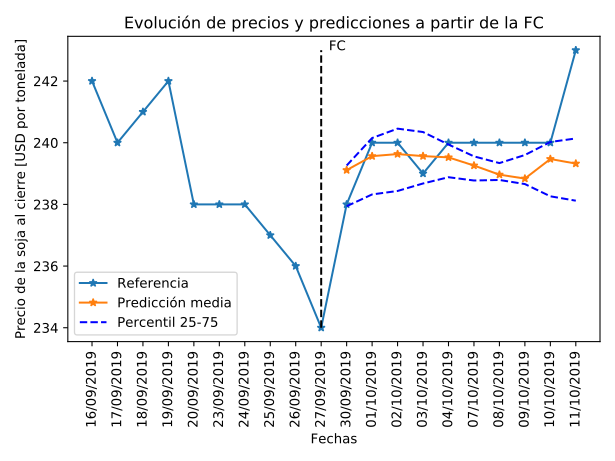
Figura 3: Comparación de la predicción del modelo propuesto respecto a los valores de cierre observados en el mercado. FC es la fecha hasta la cual se tienen datos a la hora de entrenar los modelos.
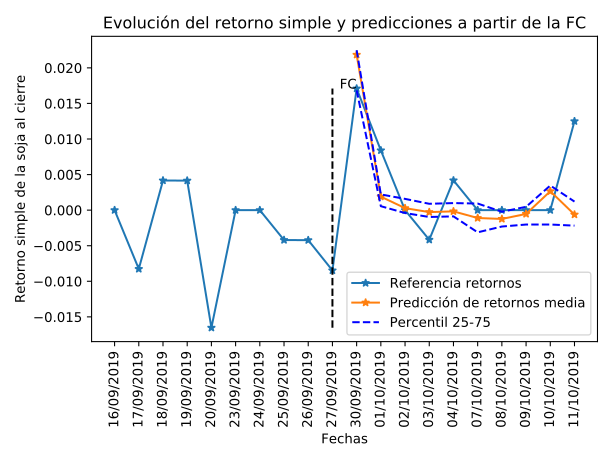
Figura 4: Predicción del retorno a partir de FC.
El segundo objetivo fue lograr una buena predicción en la fecha final del 11/10. Es intesante notar en este caso como el valor sube súbitamente, de forma similar a la fecha siguiente a FC. En este caso se observa que la varianza de los modelos aumenta y el modelo tiene al inicio una cierta tendencia a la alza en la fecha anterior, pero la predicción final queda lejos del valor real del mercado. Sería interesante realizar otros estudios para determinar la significancia de los errores de las predicciones en diferentes casos.
El tercer objetivo era ajustar los 10 valores antes de FC y los 10 valores siguientes, un total de 20 fechas. Como las fechas antes de FC son los datos provistos, y este modelo se utilzo solo para predecir y no para modelar (algo que en general no es posible en modelos tipo caja negra), se utilizaron los datos dados para la generación de los resultados por que no serían válidas para este objetivo. Aún así, esto no invalida los dos objetivos anteriores, dado que no se cuenta con ninguna información futura para generar las predicciones a partir de FC.
El modelo fue entrenado hasta la fecha FC sobre datos realistas y con el objetivo de predicción a fechas futuras, lo que resultó en un ejercicio interesante y pocas veces visto, en el cual ningun participante ni organizador tiene información de la particion de test. Se logró un modelo que, aún a partir de una serie de valores simples, logra el mejor ajuste del error medio para dos semanas posteriores a la fecha de predicción en la competencia (objetivo 1). Sería interesante comparar los modelos que obtuvieron mejores resultados en la fecha final, y evaluar qué información les permite predecir la subida súbita de esa fecha. Por otro lado, desde mi desconocimiento en finanzas, veo interesante discutir el uso del MSE en un sistema real en el cual una respuesta promedio "planchada" puede obtener un mejor MSE que una predicción menos conservadora, pero posiblemente obtenga los menores rindes si se utiliza para sugerir una inversión. Tal vez otras medidas de error puedan aportar valor a diferentes estrategias de riesgo de inversión.